基于公众偏好大数据分析的重大突发事件应急决策方案动态调整方法
2020-09-27徐选华刘尚龙陈晓红
徐选华, 刘尚龙, 陈晓红
(中南大学 商学院,湖南 长沙410083)
0 引言
重大突发事件具有随机性、快速扩散性、衍生性、传导变异性、高破坏性和高时间压力等特征,事件一旦发生,亿万网民会迅速聚集起来并参与其中,涉及的决策环境具有高复杂性和动态性。因此,这种应急决策是一种复杂大数据环境下的高风险性决策。在重大突发事件中,必须要处理数以百计的各种突发状况,它主要包括准备、响应和恢复三个阶段,任何阶段中的信息对于最终决策都至关重要[1]。
在国外,近年来在危机管理应用上比较新颖的是使用“分众”——公众参与的方式来进行应急决策,不同学者从不同角度分析了公众在社交媒体上发布的信息对突发事件产生的影响。Liu S B[2]研究表明,公众在照片分享网站Flickr生成和传播的信息在突发事件中发挥着重要作用;Vieweg S[3]通过对北美突发事件中公众产生的Twitter信息进行分析,发现在事件期间产生的Twitter信息能够提高公众的应急意识,帮助政府采取相应的应急方案。在2010年“海地”地震应急决策中,美国政府首次采用社交媒体技术作为主要的知识共享机制,为将来的灾害和应急管理提供信息支持[4]。Terpstra T等[5]通过对Pukkelpop音乐节舞台坍塌事件发生前后公众发布的推文数量进行分析,发现推文的增长速度可以反映突发事件的紧急程度。在国内,关于公众使用社交媒体参与决策也进行了一些研究。侯俊丽等[6]以7·23温州动车事故为例,研究了微博传播对公众参与政府政策制定的影响;袁靖华等[7]认为政府机构可以利用社交媒体找到恰当处置突发事件传播的具体可行路径,从而提高政府利用社交媒体应对突发事件的应急传播能力与信息处置能力。现有的研究主要是对突发事件发生后的社交媒体数据进行舆情分析和事后灾情分析,而没有真正与应急决策相结合。
然而,现有重大突发事件应急决策方法的相关研究主要有基于数理模型的决策方法、基于知识推理的决策方法、基于仿真的决策方法以及基于数据的决策方法[8]。大量的基于数据的决策方法研究成果表明[9~11],与决策相关的公众媒体数据在决策分析中具有特殊价值,而对这些大数据进行分析通常能够发现常规分析方法所无法发现的规律。在重大突发事件发生时,社交媒体信息是事件的重要信息来源,人们通常会在社交媒体上记录他们所面临的尤其是令人震惊的情况并表达自己的意见和感受,在事件发生期间,这些信息对于应急决策专家来说很有价值,因为他们可以利用这些信息来不断更新对事件现场状况的认识,同时这些信息对识别与事件相关的子事件来说也特别重要。基于此,通过对公众在社交媒体上所发布的偏好大数据信息进行分析可以检测出与事件相关的子事件,并给应急决策专家提供重要参考。由于大数据环境下突发事件的情景是动态演变的,在突发事件应急决策中,需要考虑应急决策方案随事件情景的演变进行适当调整。因此,在应急方案的实施过程中,应急决策专家需要根据不断更新的数据信息及时对应急方案进行调整,才能保证最佳的应急处置效果,从而更好的应对突发事件[12,13]。
1 方法原理
1.1 问题描述
海恩法则指出,每一起严重事件的背后,必然有29次轻微事件和300起未遂先兆以及1000起事件隐患。由此可见,在一次重大突发事件的背后,通常由多次不同的子事件组成,不同的子事件会产生不同的风险。随着子事件的动态演变,需要对突发事件发展演变的不同阶段的不同子事件制定相应的应急决策方案。在这种多阶段多事件应急决策过程中,由于不同子事件在不同决策阶段会有不同的决策目标,所对应各阶段的应急决策方案也不同。因此,面对复杂多变的决策情景,将面临多阶段多事件的应急决策方案选择问题。
如何在高时间压力下,利用与重大突发事件相关的第一现场人(社会公众)在社交媒体上发布与事件相关的偏好大数据信息,提出关键词累加权重方法获得与事件相关的关键词群,还提出一种基于公众偏好大数据分析的两阶段聚类算法将一个复杂多变的事件划分成多个相互独立的子事件,并得出每个子事件的客观风险级别,然后结合专家经验判断,综合得出每个子事件的风险级别,进而选择与风险级别相对应的方案。然而,由于数据是实时更新的,子事件及其风险级别也在不断更新,因此本研究还考虑在t时刻所采取方案的基础上,如何在(t+Δt)时刻,决策专家根据社会公众(含现场救援人员)实时反馈的大数据信息来对突发事件在t′(t<t+Δt<t′)时刻的各种状况进行判断,如果判断当前应急方案不能应对t′时刻的状况,则需要调整相应的方案,从而更好的应对突发事件[14]。
1.2 关键词累加权重方法和基于公众偏好大数据分析的两阶段聚类算法
关键词累加权重方法是为了确定关键词群,通过利用关键词群进行检索所获得的数据可作为本研究的数据来源,方法如下:
首先查询历史相关事件,成立一个由K个代表性公众组成的事件关键词提取小组Ω={h1,h2,…,h K},该小组由了解类似事件的公众博主(包括媒体记者、知名博主、自媒体评论员等具有影响力、代表性的博主)组成。就特定的突发事件,小组成员通过取并集共提出R个关键词,并对关键词A1,A2,…,AR进行重要性程度评价,所得的评价值为xkr,k=1,2,…,K;r=1,2,…,R,评价矩阵X如下所示:

xkr表示小组成员hk对关键词Ar的评价值。
公众小组的成员权重W=(v1,v2,…,vK)由公式(1)计算得出,其中Bk表示小组成员hk近一年来在社交媒体上所发布的具有影响力即点赞、评论、转发均超过500的原创消息数量。

然后采用公式(2)得出第r个关键词的综合评价值gr,为了方便起见,令g1≥g2≥…≥g R,G=(g1,g2,…,g R)。
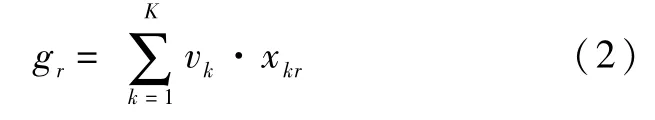
最后,为了提高了信息检索和数据挖掘的速度,同时也获得足够多的数据量,从g1开始选取关键词,当选取的关键词的综合评价值之和超过总综合评价值一半时,则不再选取关键词(既保证所选取的关键词都是综合评价值较高的关键词,又保证了数据挖掘的质量和数量,提高了数据挖掘的效率),如公式(3)所示,其中Z表示最终的关键词数量。
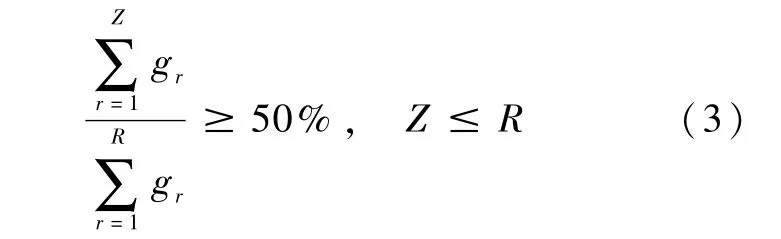
通过与长沙爱杰信息科技有限公司合作,使用该公司自主研发的智能化(采集任务)作业分发系统对Z个关键词进行数据挖掘,将获取的大量公众偏好数据(包含地理数据)作为本研究的数据来源。
基于公众偏好大数据分析的两阶段聚类算法步骤如下:
第一步,文本预处理。将公众在社交媒体上发布的文本等原始信息进行去停用词、重复词、低频词、分词等预处理。
第二步,将预处理后的文本向量化。利用空间向量模型VSM(vector space model)[15]将预处理后的文本信息向量化,向量中的每个元素由特征项及其在文本中的权重组成,特征项及其在文中的权重与公众偏好有关,公众偏好的不同会导致了生成向量的特征项及其权重大小的不同,特征项出现次数越多,权重 越 大。特 征 项 权 重 用TF-IDF[16,17]方 法计算,如公式(4)所示。
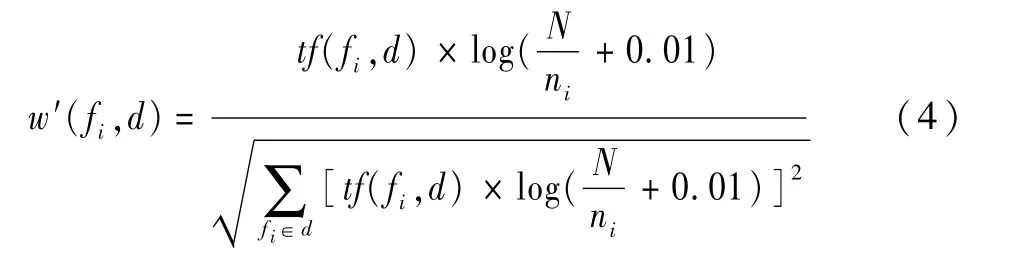
其中,w′(fi,d)为特征项fi在文本d中的权重;tf(fi,d)为特征项fi在文本d中的词频;N为关键词群搜索所得的文本总数;ni为文本总数中出现特征项fi的文本数,那么第j条文本d j的向量化表示为:d j=(),其中fji为第j条文本的第i个特征项为特征项权重,q表示向量中特征项的个数。
第三步,对第二步中的偏好向量进行两阶段聚类分析。
第一阶段聚类:聚类既含有GPS地理信息,又含有文本信息的向量。运用SOM[18~24](自组织映射)算法对同时含有地理位置和文本数据的向量进行聚类,得出不同类别以及每个类别相对应的质心,一个类别代表一个子事件,假设事件通过SOM算法聚类分解出来的子事件都是独立的,用H向量表示子事件的质心。
第二阶段聚类:使用余弦相似度[25]公式将只含有文本信息的向量分配到第一阶段聚类所生成的类别中,即将向量分配到与子事件质心H相似度最大的类别中,如公式(5)所示。
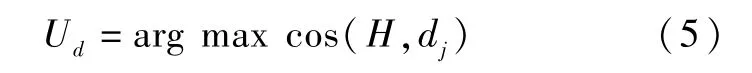
第四步,采用公式(5)对实时更新的数据进行再分配。由于在社交媒体生成的数据公众参与度极高,实时性非常强,能够在第一时间反映突发事件的状况和发展态势。因此,每隔一段时间,就采用公式(5)将公众实时更新的数据分配到相应的类别中,算法的具体流程如图1所示,其中虚线表示实时更新的数据再分配过程。
由于重大突发事件是一个庞大的系统,为了反映系统中区域的差异性,有必要进行区划,目前区划方法多种多样[26,27]。文中通过收集第一现场人(社会公众)使用社交媒体发布的信息,采用基于公众偏好大数据分析的两阶段聚类算法对突发事件进行子事件划分,获得多个相互独立的子事件。
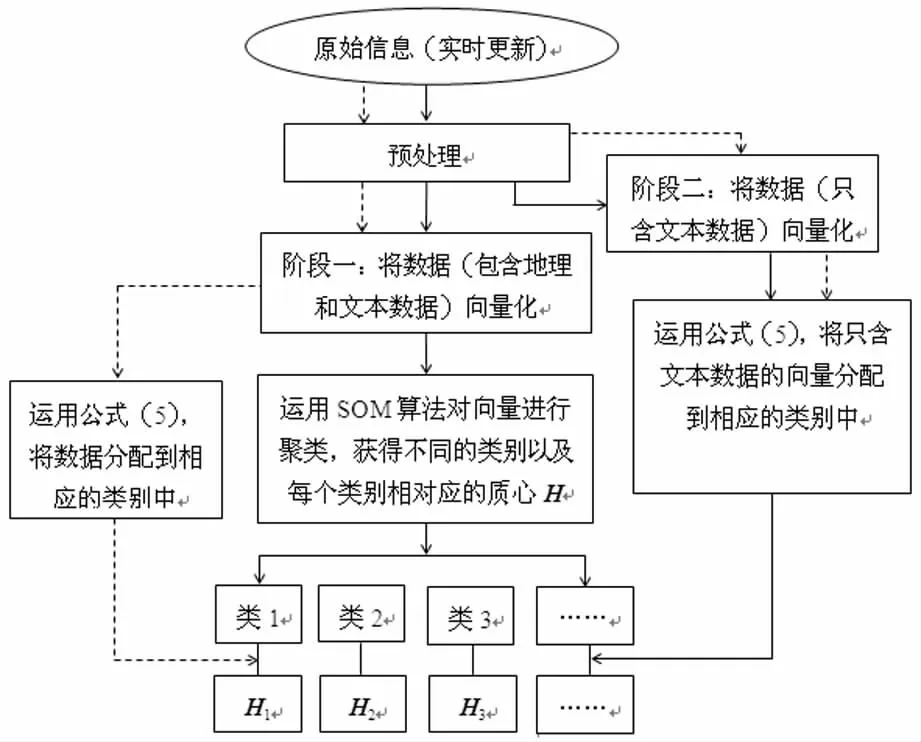
图1 基于公众偏好大数据分析的两阶段聚类算法
1.3 子事件风险级别确定
现有的事件风险级别确定方法大多是根据事件所造成的影响和严重程度进行事后评估,或者通过专家经验给出[28~30]。考虑到突发事件的时间压力大,本研究根据社交媒体上的大数据信息来确定事件风险级别,不对传统的风险级别确定方法进行探讨和描述,仅与利用社交媒体数据来确定风险级别的研究进行对比。Pohl D等[31]通过赋予公众在社交媒体上发布信息的标题、描述和标签不同的权重来确定不同信息的重要性,从而确定事件风险级别。Terpstra T等[5]利用网友在Pukkelpop事件中发布推特消息数量的多少来确定事件风险大小。姜艳萍等[32]对突发事件风险级别的确定是根据现场人员的初步描述主观给出,具有非专业性和主观性的不足。基于以上不足,本文提出特征项权重之和方法来获得事件的客观风险级别,并结合专家对事件的经验判断综合得出事件的风险级别。
采用1.2中基于公众偏好大数据分析的两阶段聚类算法对重大突发事件进行分类,假设在t时刻,获得的类别数量不再变化,共得到nt个独立的子事件O={O1,O2,…,Ont}。以第u个子事件Ou为例,其风险级别确定步骤如下:
第一步,设在t时刻中第u个子事件Ou所含文本条数为,子事件Ou中第j条文本的特征项权重之和为,其中1≤u≤nt。第二步,对子事件Ou中全部文本中所含特征项权重进行求和得:
第三步,由于子事件特征项权重之和越大,代表该子事件的风险也越大,因此用Wu′可客观得出子事件Ou的风险级别大小。每个子事件所含文本的特征项权重之和分别为:W1′、W2′、…由公式(6)可得每个子事件的客观风险级别大小为:S1=(,…,),其中0≤、…、≤1。
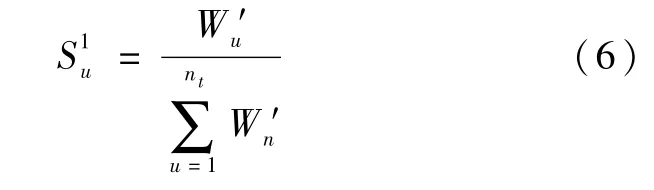
第四步,应对不同的重大突发事件,应急决策专家需采用不同的风险评估方法,从而得出每个子事件的主观风险级别。以本文研究的台风事件为例,专家采用综合风险等级评估方法[33],根据自己的主观经验判断,对台风子事件中各个指标的风险值进行综合评价,再加权平均得到不同指标下不同子事件的风险值,然后采用距标准差赋值法对不同风险等级台风造成的各项指标的风险进行综合[34],最后参考李开忠[27]的赋值标准得到各个指标风险标准值,对其进行求和归一化处理后得到台风子事件的主观风险级别:S2=()。
第五步,将以上第三步和第四步所得的风险级别进行综合,用S=(S1,S2,…,Snt)表示综合风险级别,则S=λ1S1+λ2S2,其中λ1为客观风险级别系数、λ2为主观风险级别系数,其中0≤λ1、λ2≤1,且λ1+λ2=1。λ1和λ2是由每个决策专家根据重大突发事件的发生情况,以专家对事件风险级别判断的确定程度和需要公众偏好大数据进行辅助决策的程度给出的,然后取所有决策专家的平均值得出λ1和λ2。当λ1>0.5时(即客观风险级别系数大于主观风险级别系数),综合风险级别以公众偏好大数据信息得出的客观风险级别为主,以专家经验判断得出的主观风险级别为辅;当λ2>0.5时(即主观风险级别系数大于客观风险级别系数),综合风险级别以专家经验判断得出的主观风险级别为主,以公众偏好大数据信息得出的客观风险级别为辅。
1.4 子事件应急决策方案动态调整
由于应急决策是根据突发事件的情景演变而进行多阶段不确定性决策的动态过程,其需要解决的问题通常是无序的和突变的,须根据事件现场情况进行动态调整[35]。
由1.3可得子事件的综合风险级别为:S=(S1,S2,…,Snt)。Su1和Su2分别表示子事件的第u1个风险级别和第u2个风险级别,当u1<u2时,Su1<Su2。随着子事件的演变,会出现新的风险级别与之对应,设一共有m种不同的风险级别S1、S2、…、Sm和m种不同的应对方案P1、P2、…、Pm,即每种风险级别都有应急方案与之对应。设t时刻应急方案集合为:P={P1,P2,…,Pnt}(nt≤m),其中Pu是针对子事件风险级别为Su的应急决策方案;C=(c1,c2,…,cnt)表示应急方案的启动成本向量,其中cu为方案Pu的启动成本,并且当u1<u2时,cu1<cu2,除此之外,随着子事件的演变,会出现新的风险,风险发生的概率以及造成的损失程度同样会发生变化,为了更加科学合理的对t′时刻子事件的风险级别进行确定,需要专家每隔Δt时间根据(t+Δt)时刻社会公众(含现场救援人员)实时反馈的大数据信息给出子事件在t′时刻风险级别的概率,如果判断正在执行的应急方案无法控制t′时刻子事件的情景,则需要调整应急方案,否则不调整,突发事件风险级别的判断情况如图2所示。

图2 t时刻和(t+Δt)时刻对t′时刻突发事件风险级别的判断情况
虚线表示在t时刻专家根据最初的数据判断子事件在t′时刻处于各风险级别的概率,实线表示(t+Δt)时刻专家根据实时更新的大数据信息判断子事件在t′时刻处于各风险级别的概率。显然(t+Δt)时刻对子事件在t′时刻的风险级别判断比t时刻更加科学合理。
设F为专家根据(t+Δt)时刻更新的大数据信息给出各子事件在t′时刻的风险级别概率矩阵,其中nt+Δt为(t+Δt)时刻子事件数。
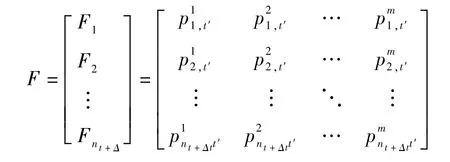
除了需要考虑每个方案的启动成本之外,还需要考虑应急决策方案的调整成本,即已采取方案调整为新方案所需要的成本,用调整成本向量C′表示。调整成本向量的确定与已采取方案和新方案之间的相关性有关,而这种相关性的确定是看调整前后两种方案中具体措施是否有相同的部分。如果有,则方案相关;反之,则方案不相关。子事件应急方案之间的相关性体现了方案之间相互转换的难易程度,因此对不同子事件进行方案调整时,需要对不同时刻方案之间的相关性进行分析,从而更准确地给出应急决策方案的调整成本,更科学合理的选择调整方案。应急决策专家给出每个子事件调整方案的成本向量,子事件Ou′(下文中对处置效果、应对损失的描述均是以子事件Ou′为例)的调整方案成本向量为(ct′,1,ct′,2,…,ct′,m),其中ct′,z表示子事件Ou′在(t+Δt)时刻,将t时刻所采取的方案调整为Pz所需的调整成本。
1.4.1 子事件调整方案的处置效果
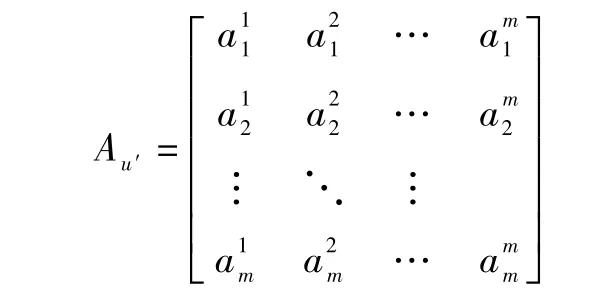
设Au′=()m×m为子事件Ou′在(t+Δt)时刻采取的不同调整方案应对不同风险级别的处置效果矩阵。
当z1≥z2时(即Sz1≥Sz2),az2z1=1,表明调整方案Pz1能够完全控制和应对风险级别为Sz2的子事件并达到预期效果;
当z1<z2时(即Sz1<Sz2)<1,表明方案Pz1应对风险级别为Sz2的子事件不能达到预期效果,且Sz1与Sz2相差越大就越小,表明方案Pz1对风险级别为Sz2的子事件处置效果越差;反之,Sz1与Sz2相差越小就越大,表明方案Pz1对风险级别为Sz2的子事件处置效果越好。
1.4.2 子事件调整方案的应对损失
设Eu′=(为子事件Ou′在(t+Δt)时刻采取的不同调整方案应对不同风险级别的损失矩阵。

当z1=z2时(即Sz1=Sz2),=0;当z1≠z2时(即Sz1≠Sz2),>0。当z1>z2时(即Sz1>Sz2),表示由于出动了过多的救援力量,在人力、物力、财力等方面存在浪费而导致的“过剩损失”,此时=cz1+ct′,z1-cz2;当z1<z2时(即Sz1<Sz2),则表示由于救援力量不足,拖延救援时间造成事故现场损失扩大的“时间损失”,损失矩阵的值由专家根据以往相似事件主观给出。
1.4.3 子事件决策方案的动态调整
令w1、w2、w3分别表示子事件调整方案的处理效果、调整成本和应对损失权重,0≤w1、w2、w3≤1,且w1+w2+w3=1,使用应急决策方法对(t+Δt)时刻的调整方案进行评价,并选出期望值最大的调整方案。
首先将子事件Ou′在(t+Δt)时刻方案调整成本向量(ct′,1,ct′,2,…,ct′,m)进行规范化,为了方便,还记为Cu′′=(ct′,1’,ct′,2′,…,ct′,m′),将损失矩阵Eu′=(规划化为(,其中:

其 中maxct′,z′为 调 整 成 本 向 量Cu′中 的 最 大 值,mixct′,z′为调整成本向量Cu′中的最小值,max为损失矩阵Eu′中第z1行 中 的 最 大 值,为 损 失 矩 阵Eu′中第z1行中的最小值。采用极差标准化方法能够直接将成本向量和损失矩阵这两个负指标规划成正指标。
设Yu′=(为子事件Ou′在(t+Δt)时刻采取的不同调整方案应对不同风险级别的综合效率评价矩阵。


由风险级别概率矩阵F可知,(t+Δt)时刻判断子事件Ou′在t′时刻的风险级别概率Fu=。因此,(t+Δt)时刻调整方案Pz1的期望值为:

当求 得Vu′,z*1≥Vu′,z1时,子 事 件Ou′的 最 佳 调 整方案为Pz*1,其中为定值且1≤≤m。同理,可求得其他子事件在(t+Δt)时刻的最佳调整方案,最后可得整个重大突发事件的调整总方案P*={P1*,P2*,…,Pnt+Δ*t}。
2 案例分析
以2016年9月15日发生在福建沿海一带的超强台风“莫兰蒂”为本研究的重大突发事件案例。凌晨3时05分,“莫兰蒂”台风在厦门翔安登陆,中心附近最大风力为15级,登陆点实测最大瞬间时风力达17级,这是2016年以来的最强台风,也是1949年以来登陆闽南的最强台风。截止17日8时,台风导致福建、浙江两省110个县304.32万人受灾,因灾死亡28人、失踪15人,农作物受灾84.19千公顷,转移群众80.13万人,直接经济损失210.73亿元。由于“莫兰蒂”台风具有快速扩散性、高破坏性和高时间压力等特性,国家减灾委、民政部积极启动国家救灾应急响应系统,并开始讨论相应的应急方案选择问题。
第一步,采用关键词累加权重方法确定数据挖掘的关键词群,方法如下:
(1)为了全面了解台风的受灾情况,应急决策部门在台风预警时成立了由9个代表性公众组成的事件关键词提取小组Ω={h1,h2,…,h9},小组成员通过查询历史台风事件,共选取了18个关键词作为14号强台风“莫兰蒂”的搜索词,分别为:台风、莫兰蒂、14号、风暴、强降雨、狂风、暴雨、风雨交加、飓风、巨浪、海啸、吹倒、淹没、洪水、冲毁、海水倒灌、房屋倒塌、损坏,用A1、A2、…、A18表示。
(2)小组成员对这18个关键词进行重要性程度打分(0~10分),所得评分表如下表1所示。小组成员的权重由近一年他们在新浪微博所发布的具有影响力的原创消息数获得。通过统计,9位小组成员近一年发布的点赞、评论、转发都超过500的原创消息数为:B=(124,108,386,158,349,148,326,243,98)。由公式(1)可得小组成员权重W=(0.064,0.056,0.199,0.081,0.180,0.076,0.168,0.125,0.051)。

表1 公众小组成员对关键词重要性程度评分表
采用公式(2)得出综合评价值gr,可得:G=(9.743,8.673,8.255,7.729,7.396,7.222,6.788,5.498,5.202,4.976,4.219,4.008,3.743,3.611,3.384,3.331,3.094,2.897),由公式(3)可得:

因此,可以认为使用“台风”、“狂风”、“暴雨”、“莫兰蒂”、“洪水”、“淹没”、“冲毁”关键词群进行数据挖掘,能够高效准确获得本研究所需数据量。
通过与长沙爱杰信息科技有限公司合作,将关键词群输入到该公司自主研发的智能化(采集任务)作业分发表系统中,围绕“台风”、“狂风”、“暴雨”、“莫兰蒂”、“洪水”、“淹没”、“冲毁”这七个关键词对2016年9月15日凌晨0点0分至2016年9月17日上午10点0分期间微博用户所发布的信息进行挖掘采集,并对所采集的245329条信息进行分析得出整个事件演变趋势,事件趋势图如图3所示。
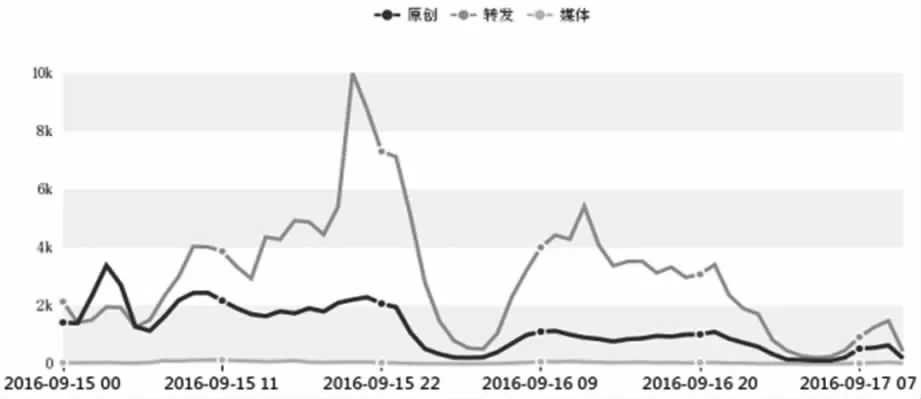
图3 “莫兰蒂”台风事件的趋势图
由图3可知,整个事件的爆发点是2016年9月15日凌晨3点,原创类型的微博数较为突出,与事件真正发生的时间基本吻合,这也从另一方面说明了新浪微博上的原创消息在重大突发事件发生时具有使用价值。
“莫兰蒂”台风事件发生后,来自全国各地的微博用户发布了与该事件相关的原创微博。对微博用户的地理位置进行分析,可以获得微博用户地理位置的分布情况,如图4所示。

图4 与“莫兰蒂”台风事件相关的微博用户地理位置分布
由图4可知,90%以上与台风有关的信息都来自福建省,为了降低数据噪声,往后分析以福建省为研究对象,仅对福建省内社会公众发布的原创微博进行聚类分析,以获得更精确的结果。
(3)以2016年9月15日凌晨3点为初始点,以小时为单位,令t=1h,t′=2h,采用基于公众偏好大数据分析的两阶段聚类算法对微博数据进行处理,得到第1h内(9月15日凌晨3点至凌晨4点)台风子事件及其风险分布情况,因数据量较大,维度较高,将维度降至5000维后“莫兰蒂”台风子事件及其风险分布情况如图5所示。

图5 “莫兰蒂”台风1h内台风子事件及其风险分布情况
同时,计算出1h内每个子事件的质心H,由于质心有5000维,在此省略表示。由图5可知,图中共有4种不同的颜色区域,分别为红色、橙色、黄色和蓝色,受台风事件影响依次递减,相应的风险也依次递减,不同颜色代表不同子事件,分布在福建省内不同区域。
将图5与福建省的地图进行对比分析,可以大致在地图上标注台风发生1h内对福建省产生影响的区域分布情况,如图6所示。

图6 “莫兰蒂”台风1h内对福建省产生影响的区域分布情况
由图6易知,厦门、泉州、莆田、福州等地受台风影响较其他地方严重。
第二步,确定台风子事件的风险级别。
(1)利用2.3中的方法可得S1=(0.341,0.301,0.194,0.163);依次代表图5中红、橙、黄、蓝区域子事件的客观风险级别。
(2)采用综合风险等级评估方法[33],对台风子事件中各个指标的风险值进行综合评价,再对所有专家的评价值进行加权平均计算,得到每个指标下不同子事件的风险值,然后计算每个子事件不同等级台风各个指标的标准差,如下式(11)所示。

上式中,σs′u为台风子事件Ou前一小时S′等级台风各个指标风险值的标准差,xs′u为台风子事件Ou在S′等级台风各个指标的风险值,¯xs′为S′等级台风各个指标风险的平均值,n1为1h内的子事件数。
计算子事件风险值距标准差的倍数:
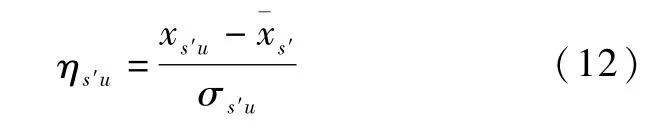
上式中,ηs′u为第u个子事件S′等级台风各个指标的风险值距标准差的差值。为了给不同强度等级台风子事件的标准差进行赋值,参考李开忠[27]的赋值标准,如表2所示。
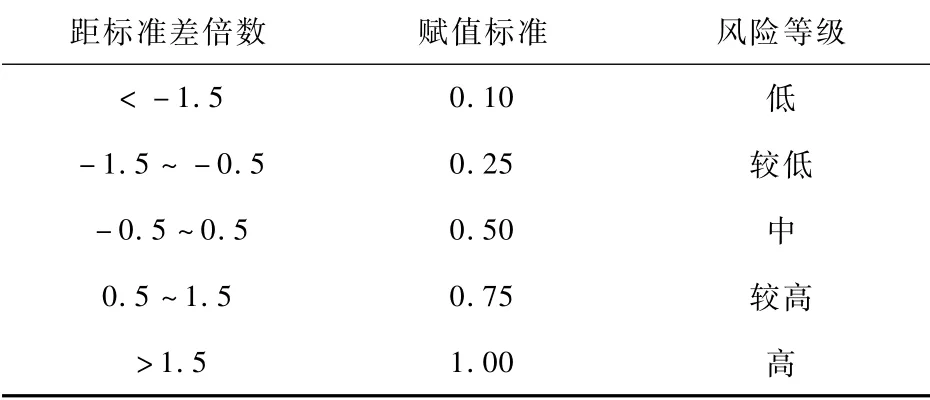
表2 不同强度台风风险等级划分
由第一步可知,在台风灾害发生1h后,福建省所受台风影响可划分成4个不同的区域,通过各地气象局监测得到的台风强度大小,并结合专家经验给出在8种不同指标下(农作物受灾面积、农作物绝收面积、受灾人口、死亡人口、受伤人口、紧急安置人口、倒塌房屋、直接经济损失)台风子事件可能的风险值,采用公式(11)、(12)计算得出每个台风子事件在8种指标下的风险等级,并对照表2中的赋值标准,将4个子事件的各个指标风险标准值进行求和归一化可得:S2=(0.4,0.3,0.2,0.1)。
(3)最后,采用公式S=λ1S1+λ2S2对风险级别进行综合,取所有专家的客观风险级别系数平均值λ1=0.3、主观风险级别系数平均值λ2=0.7,得出综合风险级别为:S=(0.382,0.300,0.198,0.119)。
第三步,对子事件的应急决策方案进行动态调整。
(1)由于台风应急响应从高到低依次分为Ⅰ、Ⅱ、Ⅲ、Ⅳ四级,并且每个台风子事件根据其风险级别都有相应的方案与之对应,因此与红、橙、黄、蓝区域的子事件相对应的应急方案分别为P1、P2、P3、P4。
应急决策专家根据(1h+Δt)时刻社会公众(含现场救援人员)实时反馈的大数据信息给出台风子事件在第2h时刻风险级别的概率矩阵F,其中Δt∈(0,1h)。

考虑第2h时刻台风子事件调整方案之间的相关性,即方案之间调整的难易程度,以红色区域(子事件O1)为例,专家给出其调整向量成本向量(0,0.3,0.6,0.8)。
最后,应急决策专家给出每个子事件调整方案的处置效果、调整成本以及应对损失这三个因素的决策权重分别为:w1=0.55、w2=0.20、w3=0.25。首先对红色区域(子事件O1)给出相应的应急决策方案动态调整过程,子事件O1的处置效果矩阵和损失矩阵分别为:

采用公式(7)和(8)将调整成本向量C1′=(0,0.3,0.6,0.8),规范化为C1′=(1,0.625,0.25,0),将损失矩阵E1规范化为E1′可得:

采用公式(9)计算可得子事件O1的综合效率评价矩阵Y1为:
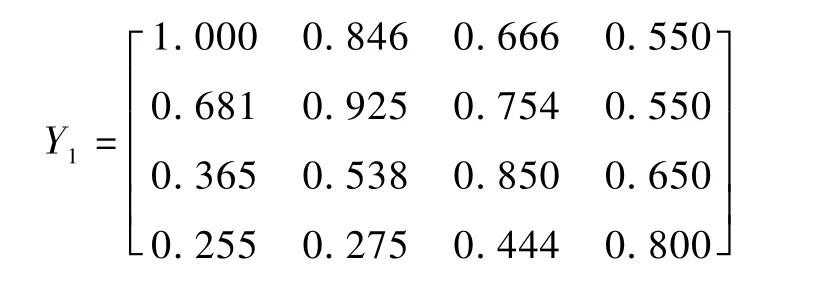
由风险级别概率矩阵F可知F1=(0.5,0.3,0.15,0.05),采用公式(10)可得台风子事件O1在第2h时刻的调整方案Pz1的期望向量V1,z1=(0.772,0.795,0.709,0.578)。由V1,z1易 知,在 第2h时刻台风子事件O1的调整方案为P2,即Pz*1=P2。
同理,采用公式(9)可得台风子事件O2、O3、O4的综合效率评价矩阵Y2、Y3、Y4分别为:


由风险级别概率矩阵F可知F2=(0.3,0.4,0.2,0.1)、F3=(0.1,0.3,0.45,0.15)、F4=(0.05,0.25,0.5,0.2)。
采用公式(10)计算可得台风子事件O2、O3、O4在第2h时刻调整方案的期望向量分别为:V2,z2=(0.571,0.834,0.786,0.590)、V3,z3=(0.307,0587,0.892,0.750)、V4,z4=(0.254,0.508,0.815,0.850),即Pz*2=P2、Pz*3=P3、Pz*4=P2。
最后可得整个重大突发事件在第2h时刻的最佳调整总方案P*={P2,P2,P3,P4},即除了子事件O1需要在第2h时刻将方案调整为P2外,其它子事件的方案不需再调整,可使得总体方案执行效果达到最佳,对台风事件的控制效果最好。
为了验证第2h时刻所采取调整方案的科学性,假设子事件数量不再变化,采用1.2中的聚类算法对数据进行更新处理,得到“莫兰蒂”台风在2h内各子事件及其风险分布情况,如图7所示。

图7 “莫兰蒂”台风2h内各子事件及其风险分布情况
由图7可知,红色区域(新子事件O1)在向上方移动,原子事件O1区域的风险级别开始降低,因此需要将以前的方案P1调整为P2,从而使应对整个事件的效果达到最佳。新的子事件O1开始向北方(浙江地区)移动且由于红色区域在变少,风险级别也在降低。也就是说,“莫兰蒂”台风在厦门翔安登陆,然后再慢慢向北方移动,同时每个子事件的风险级别也在变化。由此可见,对公众在微博等社交媒体上发布的实时消息数据进行聚类分析,可以实时准确的获得福建省内受台风影响的区域分布情况以及每个区域的风险大小,从而辅助应急决策专家采取有针对性的应对措施。
3 结论
本文针对在重大突发事件应急过程中如何根据与事件相关的公众偏好大数据信息来对事件进行划分以及确定事件风险级别等问题,提出了一种基于公众偏好大数据分析的两阶段聚类算法。运用该算法将一个复杂多变的事件划分成多个相互独立的子事件,并得出每个子事件的客观风险级别,再结合专家根据实时更新的大数据信息做出的经验判断,综合得出每个子事件的风险级别。除此之外,在其他学者研究的基础上,给出了子事件应急方案的动态调整方法,分析了动态方案调整的整个过程,扩展了动态调整方案的适用性。最后,以重大突发事件“莫兰蒂”台风为实际应用背景,通过对台风事件现场的社会公众在微博上发布的原创消息进行聚类分析,将复杂的台风事件划分成4个相互独立分布的台风子事件,并对相应的应急决策方案动态调整进行了深入的研究,给出了相应的调整结果。用“莫兰蒂”台风案例说明了公众偏好大数据信息对识别重大突发事件的子事件具有重大意义。同时,这些信息也能够辅助决策专家采取有针对性的应对方案,对决策结果产生深远影响。使用文中的聚类算法得出福建省受台风影响区域的分布情况与气象局事后评估分析所得出的结果具有一致性,也验证了方法的适用性。此外,本文提出的基于公众偏好大数据分析的两阶段聚类算法所适用的重大突发事件,主要是那些影响范围大、受公众关注强烈且生成了大量社交媒体信息或专家无法仅凭自己的主观经验判断而需要公众信息辅助判断的重大突发事件。
文中也存在一些不足之处,比如对子事件主观风险级别系数和客观风险级别系数的确定比较主观,没有考虑事件分解成子事件后它们之间的相互联系,而假定子事件之间是独立的;其次,基于大数据的决策分析也存在局限性,大量的数据虽然能够检测知识的关联性,但它却无法告诉决策者哪种相关性是有意义的,它无法解析事物的本质因果关系;除此之外,数据噪声的大小和公众参与人数的多少会影响子事件的客观风险级别的确定,从而影响最终的方案调整。以上不足之处是今后进一步研究的方向。
