基于LightGBM的催化重整装置产品预测及操作优化相关性分析
2020-09-27刘禹含曹萃文
刘禹含,曹萃文
(华东理工大学 化工过程先进控制和优化技术教育部重点实验室,上海 200237)
催化重整工艺是非常重要的石油加工工艺,用于生产高辛烷值汽油或芳香烃等,同时该工艺副产的大量氢气是加氢工艺最重要的氢气来源。催化重整分为半再生式重整、循环再生式重整和连续再生式重整。本研究的某炼油厂的催化重整装置是连续再生式重整装置,统一简称为催化重整装置。目前,对催化重整装置反应过程及实时产品预测的建模方法主要分为两大类:第一类使用机理建模方法建立集总动力学模型[1-7];第二类是基于数据驱动的方法建模[8-19]。
使用集总动力学方法对催化重整装置进行反应过程和产品预测建模,最早于1959年由Smith[1]提出了4集总模型。2007年,王均炎等[2]建立了催化重整的集总动力学模型,基于Aspen HYSYS建立了催化重整过程的稳态模型,进行了灵敏度分析,为过程的监控和优化提供了参考。2012年,梁超等[3]基于集总理论和反应机理建立了考虑烷烃、环烷烃和芳烃间关系的反应器模型。2016年,刘子媛等[4]建立了14集总反应动力学模型用于预测催化重整产品组成。2015年,刘鹏飞[5]针对半再生催化重整装置,使用Aspen HYSYS建立了反应和分离模型并进行优化分析。李斌等[6]建立了连续催化重整的18集总27反应的动力学模型对产物进行了预测。2018年,Babaqi等[7]建立了36集总55反应的集总动力学反应机理模型,并将该模型用于监控重整过程参数。这类方法如果集总组分和集总动力学方程建立得越全面,则模型精度越高,反应过程及产品预测越准确。但是如果集总数目太多会使反应网络非常复杂,计算工作量庞大,即使采用先进的Aspen HYSYS软件进行运算,运算速度仍然较慢,在线应用十分困难。
基于数据驱动的方法进行软测量建模则具有运算速度快的优点。秦秀娟等[8]使用BP神经网络建立催化重整汽油辛烷值预测模型。郭彦等[9]采用BP神经网络和主成分分析法建立催化重整装置的收率预测模型。贺宗江[10]利用机理方法、线性拟合方法和一阶TSK模糊神经网络算法分别对催化重整装置的芳烃收率建立软测量模型。孙自强等[15-16]利用BP神经网络建立催化重整装置的辛烷值和反应器结焦量软测量研究。Abdalla等[17]使用前馈神经网络对催化重整生产过程建立模型。2016年,张凌波等[18]提出一种改进的教学算法优化BP神经网络,建立了催化重整装置的催化剂含炭量的预测模型。2016年,双翼帆等[19]使用建立多模型包括支持向量机、神经网络等软测量建模方法,建立了脱氯前氢气纯度的在线计算模型。这些方法抛开机理方程,以装置运行的历史数据和实时数据为基础,用数据驱动模型建立重整装置的相关输入参数与输出产品之间的联系,运算速度快,可以在线应用。但是模型的准确性依赖于数据的全面性,常规工况下采集的有限数据集无法实现这个“全面性”的任务,从而使数据驱动的模型精度产生偏差。
随着机器学习在数据预测和分类方面的成功应用,新的数据驱动方法,如卷积神经网络[20]、XGBoost[21]、LightGBM[22-23]等,得到飞速发展。如何将机理建模与数据驱动两种方法的优势结合为装置的在线优化操作提供理论支撑,已成为理论界和工业界共同关注的一个重要的研究课题。
数据驱动建模的关键影响因素是完备的数据集和合适的建模方法。实际生产中工况和获得的数据量很有限,为了提升建模的精度和速度并改善该问题,笔者首先使用Aspen HYSYS软件建立了与有限实际生产数据相吻合的连续催化重整装置的20集总动力学模型的机理模型,并在软件中考虑了多种生产可能性,扩展生产数据的范围,得到了更加完整的装置产品预测训练数据集。然后,与已有研究成果中常用的BP神经网络作为对比,在Python平台上采用训练速度快、预测精度高、适合非线性过程建模的LightGBM决策树模型[23]对某炼油厂的催化重整装置进行了数据驱动产品预测建模。并运用交叉验证,以均方根误差(RMSE)、解释方差得分(EVS)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)4个指标来评价预测模型,考察其预测的准确度。
1 基于Aspen HYSYS的催化重整装置模型及装置产品预测数据集的构建
1.1 基于Aspen HYSYS的催化重整装置建模
某大型炼油厂的催化重整装置由4级反应器和催化剂再生器组成。反应器主要进行催化重整反应;催化剂再生器主要进行催化剂的再生,反应器和再生器之间由管线连接。来自预处理部分的重整原料依次通过4个反应器逐步进行反应。由于催化重整反应是吸热反应,反应器间会发生温降,各反应器间使用加热炉确保下一反应器的入口温度。催化重整过程主要有9种基本反应类型,如表1所示。
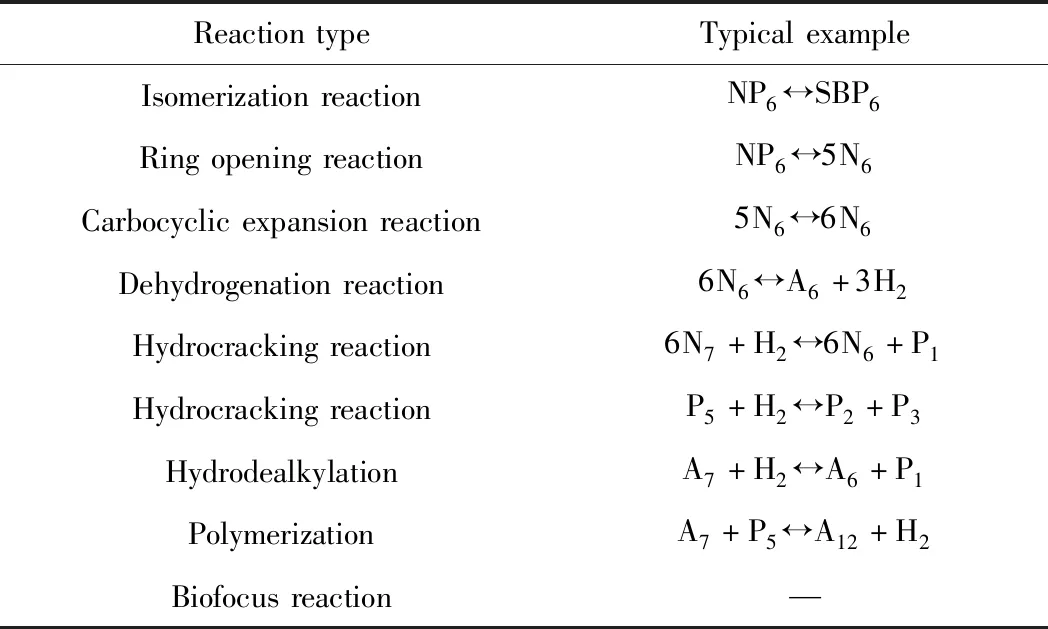
表1 催化重整反应动力学基础反应类型
Aspen HYSYS软件使用的化工流程模拟方法为序贯模块法,其优点是:可以任意组合单元模拟工艺过程,组分数、塔板数、物流数、循环数均无限制;物性数据丰富,应用领域广泛,输入、输出采用窗口技术和图形技术,使用方便。因此,经过与实际生产数据的对比测试,笔者在Aspen HYSYS的平台上构建了20集总催化重整模型,其集总组分划分如表2所示。

表2 催化重整模型的集总组分划分
采用Aspen HYSYS V8.4中Refining工具箱的Catalytic Reformer模块构建催化重整装置核心反应模型。模型的建立需要反应器的结构参数、催化剂装填量、原料油分析数据、循环氢比率、反应器操作参数等数据。然后,基于催化重整装置的工艺和生产数据对构建的模型进行调整校正,并调试收敛。Aspen HYSYS中的催化重整装置核心反应过程如图1所示。原料在4个催化重整反应器进行重整反应,产品油和氢气经空冷器、分离罐完成冷凝和气、液相的分离。
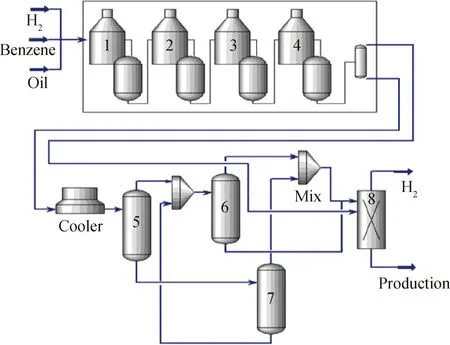
图1 Aspen HYSYS中催化重整装置模型仿真图
1.2 催化重整装置产品预测数据集的构建
构建模型后,通过数据驱动方法分析优化操作参数,需要大量的数据。由于操作参数的改变对催化重整装置的产出影响非常大,因而从实际生产中获得的装置操作参数变化范围有限。催化重整装置产品预测数据集的构建,可以通过在Aspen HYSYS软件中调整模型装置的操作参数来模拟生产过程、扩展生产数据。
催化重整装置中反应部分最重要的操作参数为4个反应器入口温度和循环氢流量,不同操作参数的调整对产品的影响程度也不同。以炼油厂中一种精制石脑油输入为例进行分析,确定了对生产结果影响大的5个操作参数,分别是:反应器1、2、3、4的温度T1、T2、T3、T4和循环氢流量F(Re H2)。催化重整装置在平稳运行时,反应器1、2、3、4的温度分别为539 ℃、537 ℃、537 ℃、537 ℃,循环氢流量为4005 m3/h。炼油厂实际数据与Aspen HYSYS软件模型数据对比情况如表3所示。其中,炼油厂装置的操作参数包括4个反应器的温度,戊烷、二甲苯、C6、重整汽油、氢气的流量,循环氢流量和氢气的纯度。

表3 催化重整装置的运行稳态数据与Aspen HYSYS模型的计算数据对比
重整装置实际运行时,近稳态值处波动多,数据量大;而远稳态时波动较少,数据量较小。因此,在扩展数据集时设定:当反应器温度在稳态值±2 ℃内时,以0.5 ℃幅度波动;在稳态值±(2~5) ℃范围时,以1 ℃幅度波动;在稳态值±(5~10) ℃范围时,以2.5 ℃幅度波动;循环氢流量波动幅度为36 m3/h,以稳态值为中间值共取5个值。
数据集构建在CPU为Intel Xeon E3-1575M v5主频为3.00 GHz的Dell移动工作站上进行,经过约79 h的计算,在Aspen HYSYS软件平台建立的模型上共扩展数据42930组。剔除问题数据后,得到39300组有效数据。表4列出10组有效数据。
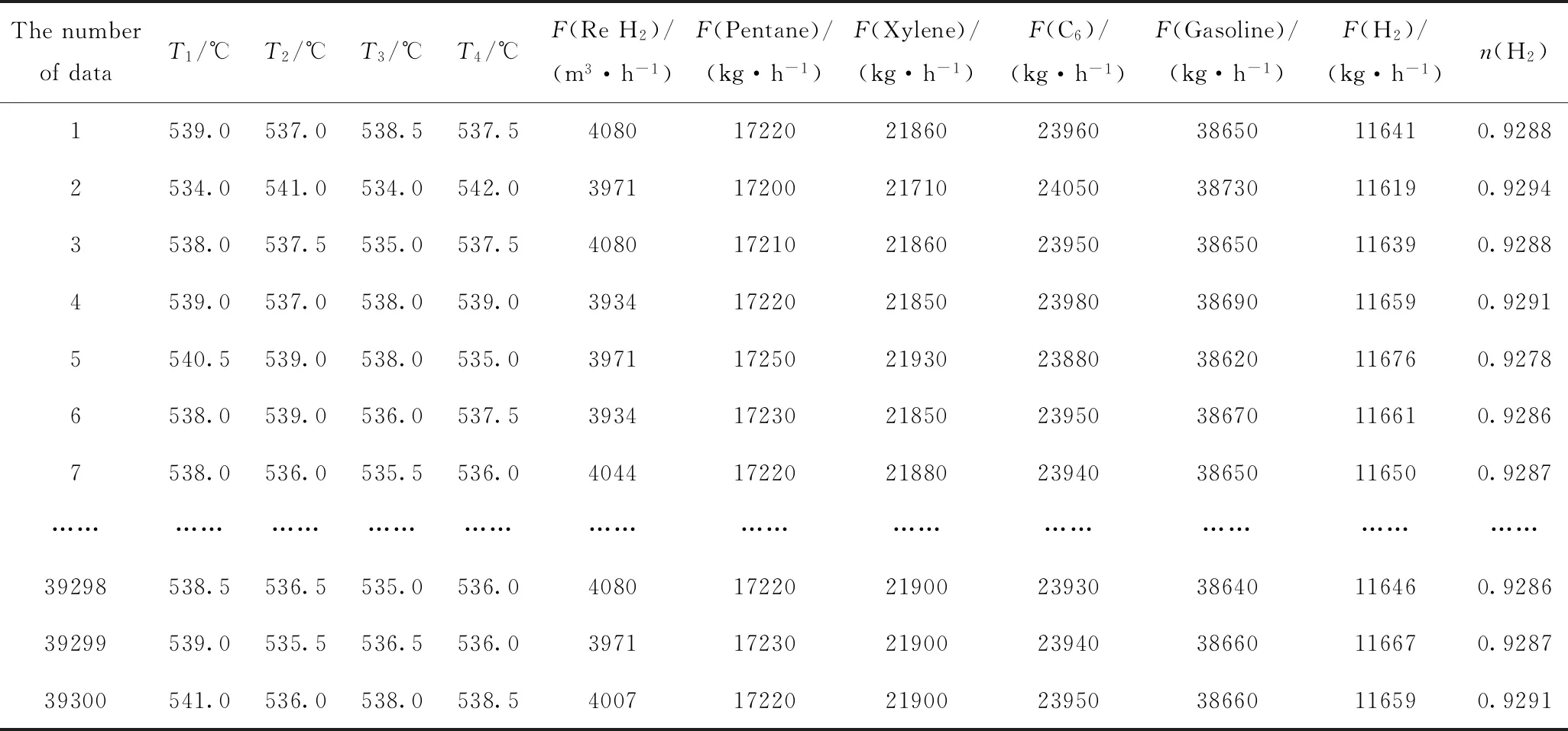
表4 催化重整装置产品预测数据集
2 基于LightGBM的催化重整装置数据驱动建模
2.1 基于LightGBM的模型训练及参数设置
梯度提升决策树(GBDT)是Friedman[24]于2001年提出的功能非常强大的机器学习模型,是基于决策树的集成学习框架,但其容易过度拟合、训练速度慢。2017年,Ke等[23]基于GBDT提出了改进的LightGBM,具有以下优点:分布式和高效性、更快的训练速度和更高的效率、降低内存使用率、更准确、能够处理大规模非线性数据。LightGBM是微软公司提供的开源算法,主要针对大规模数据提出的高效率新技术,以损失函数最小为优化策略,可以将传统GBDT的训练过程加速20倍以上,同时实现更高的精度[23]。
在Aspen HYSYS软件得到的催化重整装置运行各项参数完备数据集的基础上,笔者采用了训练速度快、预测精度高、适合非线性过程建模的LightGBM[23]决策树模型对该催化重整装置进行了数据驱动产品预测建模。在建模过程中,随机选取数据集中90%的数据作为训练数据集,其余10%的数据作为测试数据集,并指定数据集中的反应器1、2、3、4的温度T1、T2、T3、T4和循环氢流量为特征变量,分别以数据集中的戊烷、二甲苯、C6、重整汽油和氢气的流量,以及氢气纯度为目标变量,建立了6个单目标的预测模型。此外,基于Python3.6.6平台建立的LightGBM决策树模型(单棵树叶子数量为5,学习率为0.05,数据随机选择比率为0.8,其余参数为默认值),是在CPU为 i7-7600HQ 的笔记本完成的。
2.2 基于LightGBM对催化重整装置进行产品预测建模
模型的训练数据集由模型扩展的39300组有效数据组成。将其等分为10份,每次训练使用其中1份数据(3930个数据)为测试数据,其余9份数据(35370个数据)为训练数据。

为考察基于LightGBM产品预测模型的预测精度,同时采用BP神经网络建立数据驱动产品预测模型,并进行预测精度的对比。基于BP神经网络模型的结构为3层:输入层(5个节点)、隐藏层(5个节点)和输出层(1个节点),并采用随机梯度下降法训练BP神经网络每层节点间的权重。
采用LightGBM和BP神经网络分别进行10折交叉验证,并计算了均方根误差(RMSE)、解释方差得分(EVS)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)等模型评价指标,计算式分别为式(1)~(4)。
(1)
(2)
(3)
(4)
2.3 基于LightGBM和BP神经网络模型的产品预测结果
基于LightGBM和BP神经网络的预测模型,对催化重整装置目标变量(包括戊烷、二甲苯、C6、重整汽油和氢气流量,及氢气纯度)的预测值与实际值如图2~图7所示。从图2~图7可以看出,相较于BP神经网络模型,LightGBM模型的6种目标变量的预测值与实际值吻合度更高,说明其拟合精度明显好于BP神经网络模型的精度。同时,在装置的操作参数微小变化时,催化重整装置的目标变量存在局部跳变现象,波动性非常强。LightGBM利用弱分类器(决策树)迭代训练得到优化模型,对波动性强的数据拟合效果好;而BP神经网络虽然能预测跳变趋势,但拟合精度较差。
从图2、图4、图5和图7还可以看到:对于戊烷、C6、重整汽油流量和氢气纯度某些波动大的点,BP神经网络预测较差,造成了较大的误差,而LightGBM模型保持较高的预测精度。从图3和图6可以看到,对于二甲苯和氢气流量,BP神经网络预测值比较集中,不能够对不同的输入特征变量(不同工况)做出更精准的预测,区分度不强,而LightGBM模型的预测表现远远优于BP神经网络模型。这表明BP神经网络从训练数据中学习到的知识比较差,泛化能力弱,不能达到较好的预测效果。
表5中列出了对LightGBM模型和BP神经网络模型进行10折交叉验证后RMSE、EVS、MAE和MAPE的均值。其中,RMSE、MAE、MAPE指标越小,EVS越接近于1,说明模型预测精度越高。由表5可以看到,与BP神经网络模型的指标值相比,LightGBM模型的RMSE、MAE、MAPE指标更小,而EVS更接近于1。这表明从这4种评价指标来衡量,LightGBM模型的预测精度更高。
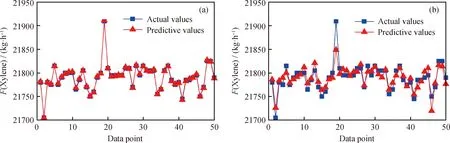
图3 二甲苯流量(F(Xylene))实际值与预测值
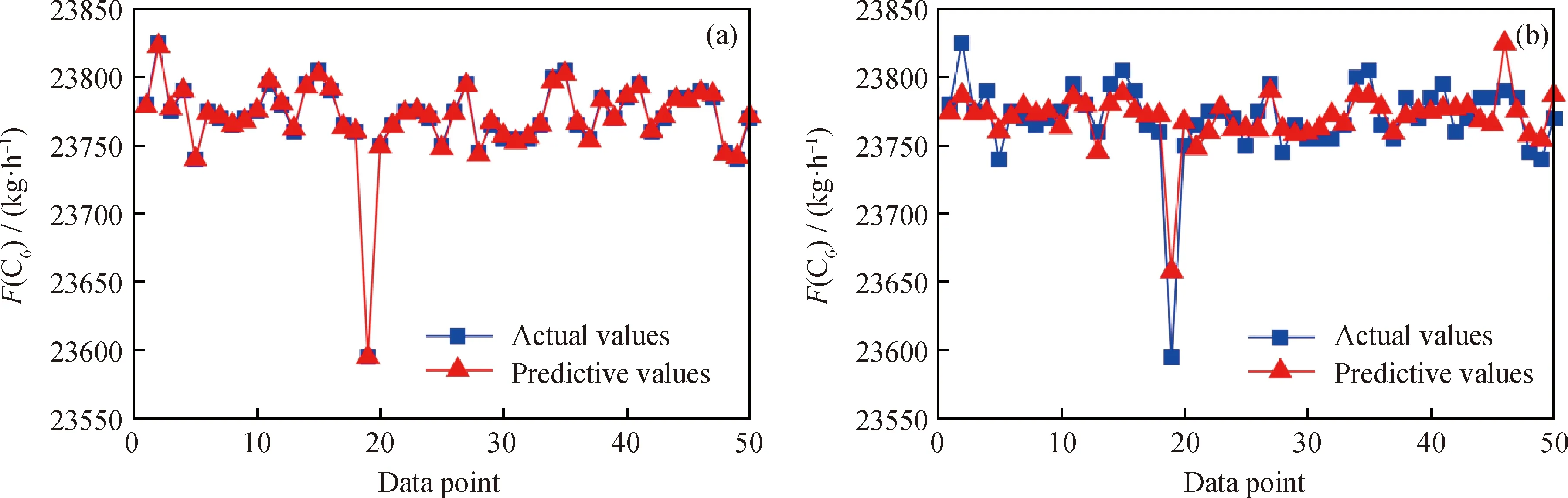
图4 C6流量(F(C6))实际值与预测值
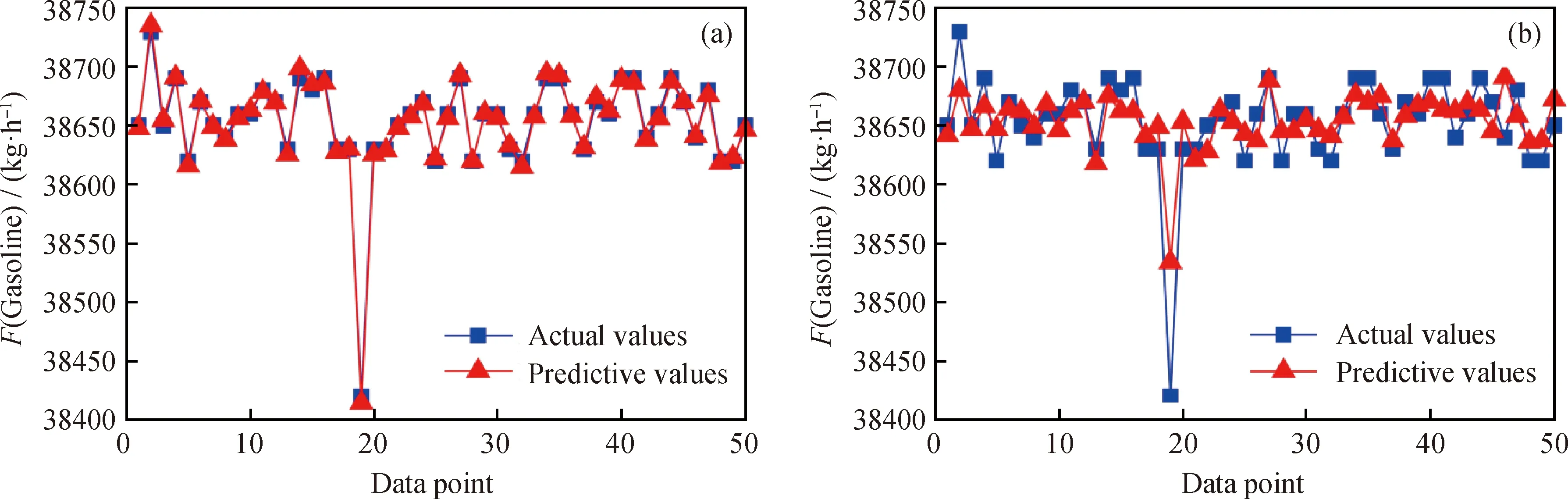
图5 重整汽油流量(F(Gasoline))实际值与预测值
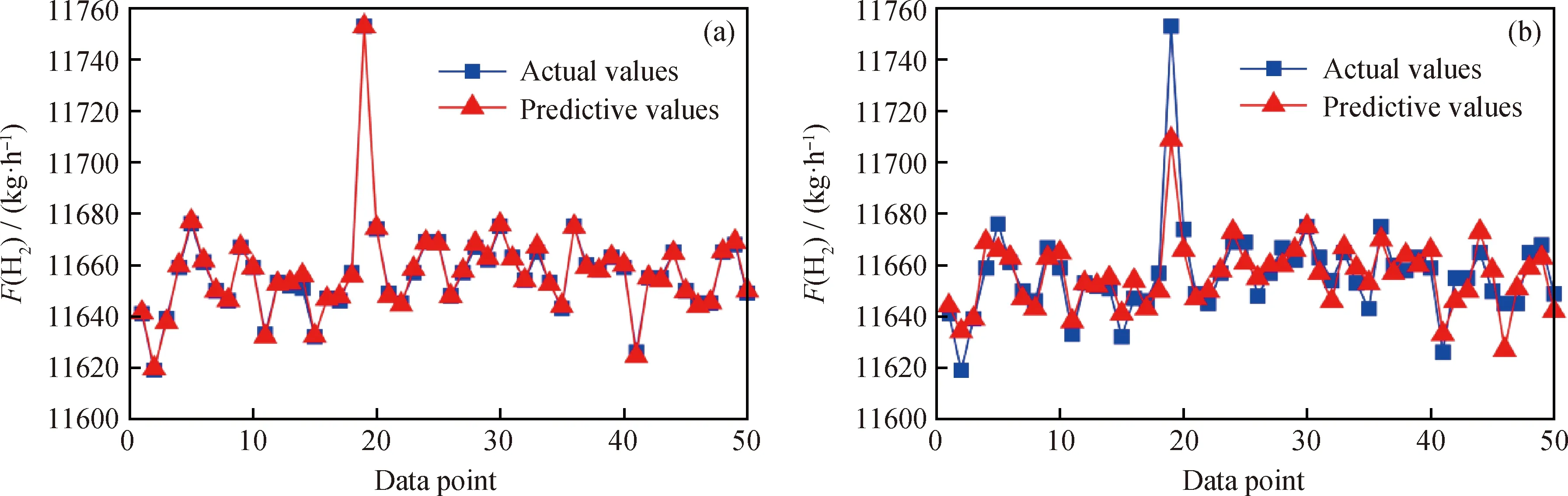
图6 产氢量(F(H2))实际值与预测值
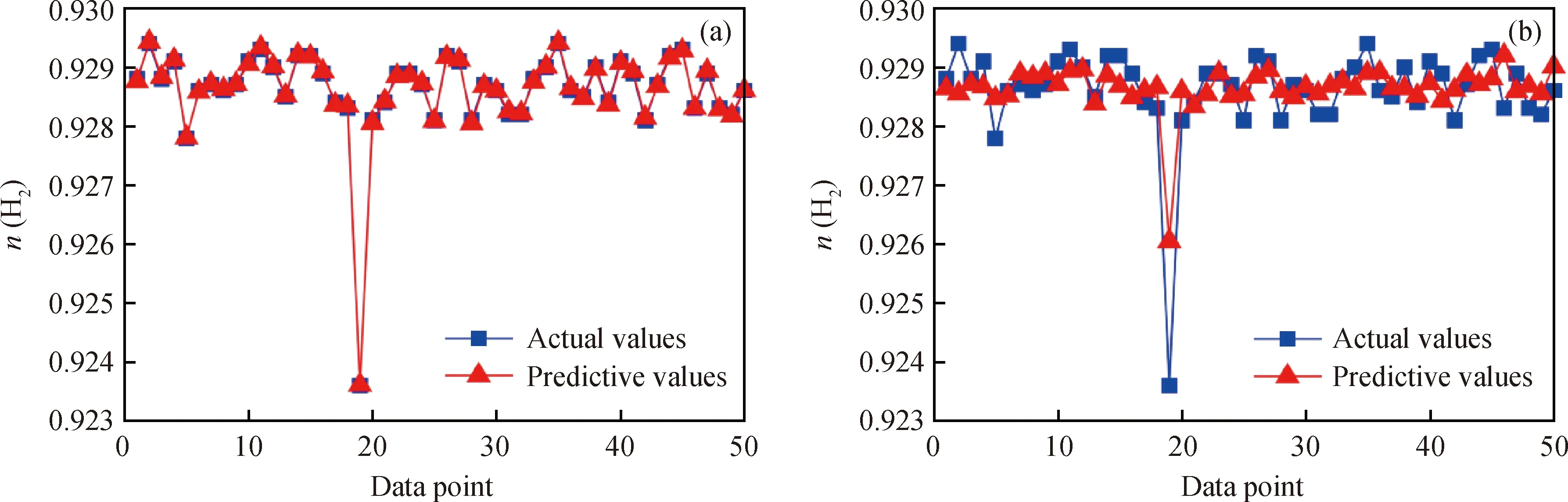
图7 氢气纯度实际值与预测值
3 基于LightGBM模型中特征变量与目标变量的相关性分析
3.1 基于LightGBM模型相关性分析原理
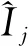
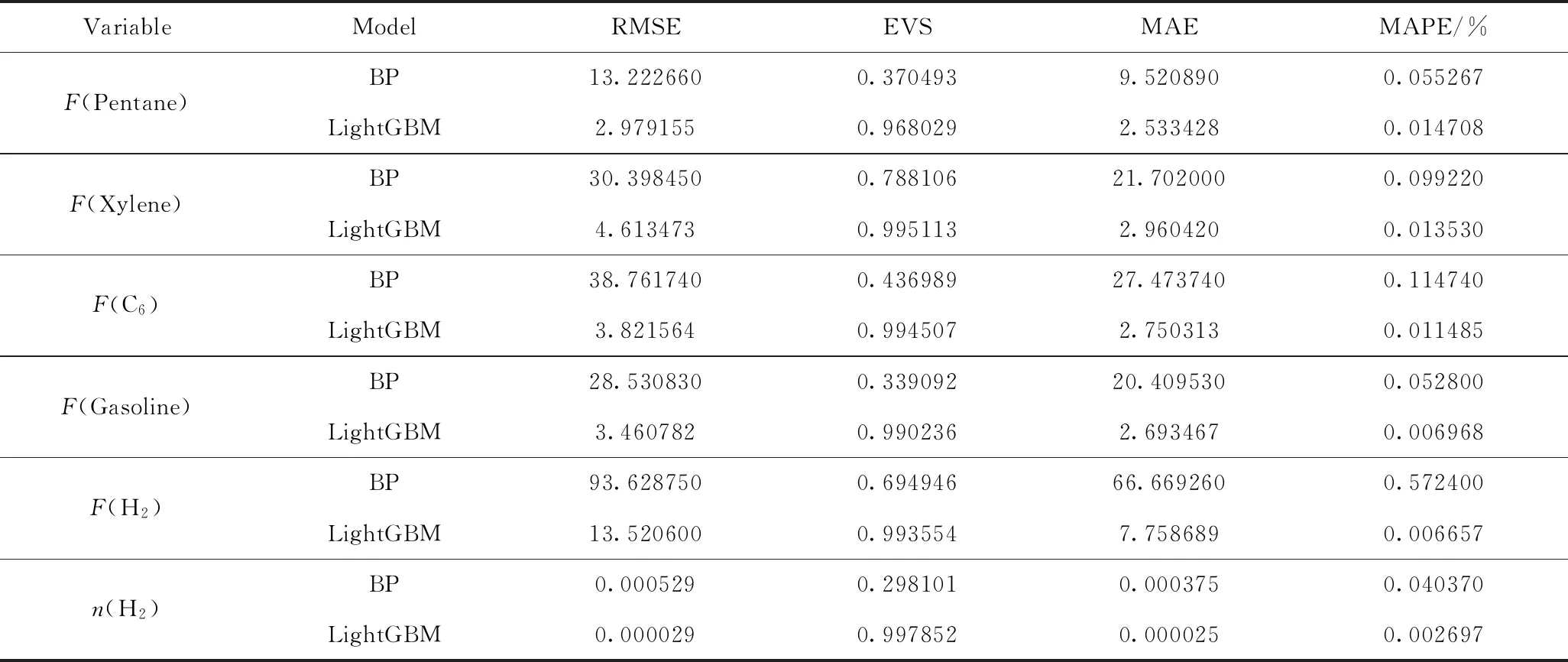
表5 预测模型10折交叉验证后的评价指标
(5)
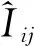
模型中特征变量向量矩阵:X=[x1,x2,…,xj,…,xn]k×n;其中xj=[x1j,x2j,…,xij,…,xkj]T。其中,x1,x2,…,xj,…,xn代表输入的特征变量向量;n代表特征变量向量个数。
设第i行的行向量xROWi=[xi1,xi2,…,xij,…,xkj]对应目标变量的值为yi,则模型中目标变量向量矩阵为:y=[y1,y2,…,yi,…,yk]T。
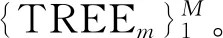
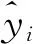
(6)
根据回归决策树的计算原理,计算每棵决策树目标变量值时,目标变量与特征变量之间的函数关系均可以表示为公式(7)。
(7)
(8)
式(8)中,En是n×n的单位矩阵。结合公式(6)则推出:
(9)
(10)
3.2 基于LightGBM模型的操作优化相关性分析
通过分析模型中输入特征变量对每个输出目标变量的影响程度值,得到特征变量和目标变量的相关性。图8给出了模型特征变量与输出变量的相关性排序,其中T1、T2、T3、T4分别为催化重整装置反应器1、2、3、4的温度;F(Re H2)为装置循环氢流量。由图8可知:对于戊烷流量,反应器2的温度影响最大,反应器4和1的温度影响也较大,而循环氢流量和反应器3温度的影响明显小很多;对二甲苯的流量,反应器1温度的影响最大,反应器4、3、2温度的影响依次减小,而循环氢流量的影响最小;对于C6的流量,反应器1的温度影响最大,反应器4的温度影响次之,反应器2和3的温度影响稍弱,循环氢流量的影响可以忽略;对于重整汽油流量,反应器4的温度影响最大,反应器1和2温度、循环氢流量、反应器3温度的影响依次减小;对于催化重整装置产生氢气的流量,反应器4温度影响最大,反应器1温度的影响次之,而循环氢流量的影响也比较重要;对于氢气纯度,反应器2温度的影响最大,而反应器4、1和3温度的影响依次减小。
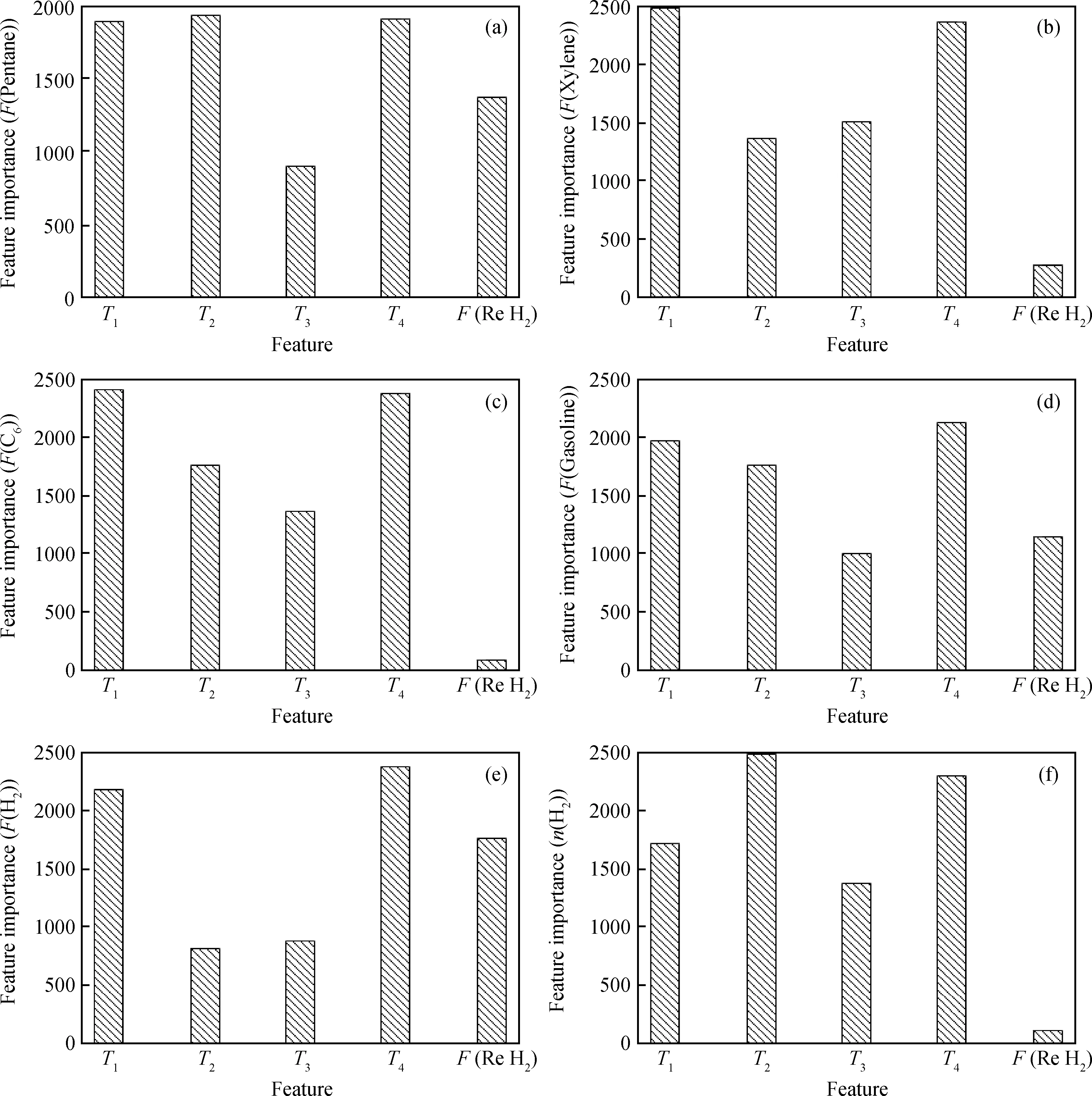
图8 特征变量对目标变量影响的重要性
在实际生产中,连续催化重整装置的生产目标存在多种变化的可能性。以装置各目标产品的输出量来表达变化可能性时,需要调整操作参数来实时调节装置的生产。目前,这项工作主要依赖于操作员的经验。根据本研究的优化操作相关性分析,得到操作参数对目标产品影响度的重要性排序,可以优先调整重要性高的操作参数,进行高效的实时优化操作。
4 结 论
(1)根据实际运行参数,利用Aspen HYSYS软件构建了连续催化重整装置的20集总动力学模型,并考虑多种可能性扩展催化重整装置数据范围,得到了更加完整的装置产品预测训练数据集。
(2)在Aspen HYSYS构建模型扩展数据集基础上,采用LightGBM决策树成功构建了催化重整装置的产品预测数据驱动模型。以RMSE、EVS、MAE、MAPE等4个指标来评价预测模型,结果表明,与采用BP神经网络构建数据驱动模型比较,LightGBM构建的模型预测准确度更高,并且保持了较快的训练速度。通过特征变量对目标变量影响大小的相关系分析,明确了特征变量对每一个目标变量影响的重要程度,从而针对不同生产目标得到影响最大的特征变量。
