基于数据流聚类挖掘算法的入侵检测系统研究
2020-09-27梅莹莹梁月放
梅莹莹,梁月放
(安徽三联学院 计算机工程学院,安徽 合肥230601)
随着网络技术的飞速发展,网络数据流量急剧膨胀,攻击手段和技术呈多样化、智能化,网络安全防御中的入侵检测系统面临了新的挑战[1]。近年来,基于数据流挖掘的入侵检测系统成为研究的热点。但数据流是连续快速、出现时间短且不可逆的[2],所以解决挖掘算法中对数据流的实时处理问题显得尤为重要。
将数据挖掘技术应用于入侵检测是近几年来网络安全领域研究和发展的课题,国内外学者做了许多研究[3-4]。例如:美国的哥伦比亚大学的DMFCFM IDS项目[5]基于数据挖掘技术构造了一个入侵检测系统(IDS),较以往IDS更加自动化和系统化。DMFCFM IDS提出了用频繁情节规则和关联规则来构造更具预测性的、额外的特征。在国内,中科院利用数据挖掘算法,通过层次化协作模型分析和处理安全审计数据,可在系统中实现入侵检测规则自动生成,并建立异常检测模型。清华大学使用多种数据挖掘算法建立检测模型,其中采用Agent/Manager/UI三层实体结构,提出了一种基于数据挖掘算法的协同入侵检测系统[6]。
基于数据挖掘的入侵检测系统已经取得了一些研究成果[7],但也存在着许多问题。采用传统的基于静态数据库的数据挖掘算法在高速网络环境下进行有效挖掘是行不通的。本文针对实现高速网络数据流实时检测处理的需求,将数据流挖掘技术和入侵检测技术相融合,研究新的入侵检测系统,以解决传统入侵检测系统对海量、高速数据处理实时性差的问题。
1 基于数据流挖掘的入侵检测模型
将数据挖掘技术应用于入侵检测能够广泛、有效地审计数据,得到攻击行为的模型或特征,进而精确地分辨和捕获实际的入侵和正常行为模式[8]。这种方法的优点在于相同的数据挖掘工具可应用于多个数据流,从而有利于构建适应性强的入侵检测系统[9-10]。
1.1 基于数据流挖掘的入侵检测模型(DSMIDS)设计
当网络外来信息流入后,采集设备负责采集,并通过数据挖掘算法程序对采集的数据进行挖掘,按一定的规则聚类(或分类)流入的信息特征,该特征与现有系统的入侵特征进行匹配。根据匹配成功与否,判断流入系统的信息是否含有入侵信息。当然,系统需经常对匹配规则进行更新处理。图1描述了基于数据流挖掘的入侵检测模型(Data Stream Mining-based Intrusion Detection System,DSMIDS)。

图1 基于数据流挖掘的入侵检测模型
根据上述分析,基于数据流的入侵检测系统模型由数据流采集模块、数据整理模块、数据挖掘模块和入侵检测模块等组成。其模型设计如图2所示:
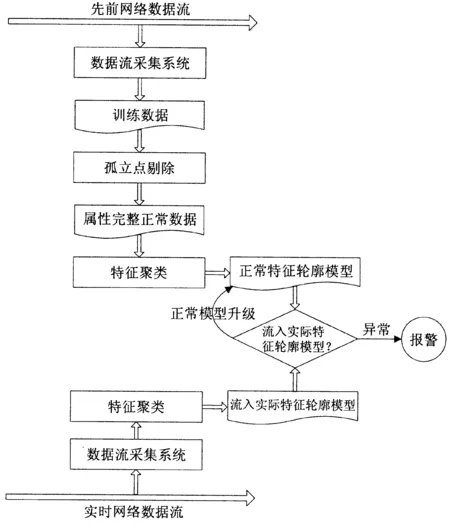
图2 入侵检测系统的模型设计
数据流采集模块的作用是捕获无损报文以及检查简单的报文,如IP报文版本检查、校验以及协议检查等。数据流整理模块包括整理训练数据、剔除孤立点等。对于在采集时段中采集到的正常数据,将其当作训练数据集来处理,以实现正常信息轮廓的挖掘。孤立点就是在数据集中与众不同的数据[11]。为解决数据流挖掘中训练数据的可靠和匹配模型轮廓的正确,在构造正常数据模型时必须将孤立点剔除。入侵检测模块是为了将待训练的数据进行聚类,通过对比并匹配运算实际的信息特征轮廓和获得的信息特征轮廓,从而判断网络信息是否存在入侵行为,以便进行及时防范。实际信息的特征轮廓通过对信息流的聚类产生。
1.2 孤立点剔除算法
在数据流的采集和传输中,由于干扰等因素,会出现一些偏离正常模型的孤立点。这些点会影响到正常轮廓模型的生成或导致正常模型不精确。因此,在产生训练数据样本时,必须要对孤立点进行剔除。
这里采用分治策略,将空间域用一条x=c的垂直线递归的划分为左右两个子域,并分别求出两个子域的最近对d1和d2,然后求出d=min(d1,d2),这个d不一定是空间域的最近对,因为还要考虑左右之间点的距离问题。那么有没有左右之间两点的距离小于d?可以证明,如果存在这样的点,该点一定在以x=c为轴,左右距离为d的空间内,同时可以证明,这样的点最多只有6个[12]。也就是说,经过这样的优化,求最近对的问题可以归结为:用递归的方法将整个空间域分为左右两个子域,分别求出两个子域的最近对,再从两个最近对中找出较小的一对,然后选出以x=c为轴,以[y-d,y+d]为空间的候选点,计算它们之间的距离,经比较得到全部空间域的最近对。
最近对求出后,可以用上述思想分离出孤立点。这样分离孤立点的过程如图3所示。

图3 优化最近对求法 图4 ASWDStream算法流程
可以推算,该方法的时间复杂度为:T(N)∈Θ(nlogn),和基于最近对技术的孤立点发现算法[13]相比,大大提高了算法的时间效率,满足了数据流挖掘对时间复杂度的要求。
2 ASWDStream算法
ASWDStream(Attenuation Sliding Window Density-based Data Stream Clustering Mining)算法的理论要点为:处理已知的临界候选 微簇,判断其能否作为离群 微簇或者候选 微簇。在处理数据流时,该算法依次读入滑动 窗口中的所有 子窗口的数据。通过聚类操作将这些数据并入多个候选 微簇和临界候选微簇,接着把临界候选 微簇保存到另一个临界候选 微簇集中,将候选 微簇保存到一个候选 微簇集中,等处理完所有子窗口后,再处理保存的临界候选微簇和候选微簇。
2.1 ASWDStream算法实现
ASWDStream算法包括在线的微簇维护以及离线的最终聚类生成两个步骤。和CluStream算法[14]的离线聚类生成过程大致相同,ASWDStream算法也是用相同的金字塔时间框架来存储聚类结果(见图4)。
2.2 数据流聚类挖掘算法
为尽快查找进化数据流中的簇,应该对临界候选 微簇和候选 微簇进行维护。所有的临界候选微簇被维护在一个独立的内存空间内,称为临界候选缓存[15]。所有的候选 微簇被维护于另外一个专门的内存内,称之为候选缓存区。大部分的新数据点都可以匹配现有的簇,因此现有的临界候选微簇和候选微簇可以吸收新数据点。当一个新数据点p到达时,合并过程如表1所示:

表1 数据流聚类挖掘算法流程
对现有的每个候选微簇Cp来说,如果不吸收新的数据点,则将会不断地衰减Cp所占的权重。一旦Cp的权值小于βu,则表明这个候选微簇Cp己经完成向一个离群点噪声的退化。此时该离群点噪声将会被删除以释放内存空间。因此需要对各个候选微簇的权值进行持续性检查。首先需要确定检查的周期,以避免太频繁的权值检查工作。将一个候选微簇退化成离群点需要的最小时间跨度[16]如公式(1)所示:
(1)
由式(1)可见,只需要做定期的检查,周期为Tp。因为所有数据流的权重为w,通过采用此检查方法后,能够实现在内存中的最大候选微簇数量为w/βu。
若某一滑动窗口的所有子窗口均采用ASWDStream算法来实现对候选微簇和临界候选微簇的挖掘,并存储到T1(候选微簇集)和T2(临界候选微簇集),则算法就会合并T1和T2内的微簇。由于新的微簇的产生,此时需要合并候选微簇集中的所有微簇。如果没有候选微簇从已合并的临界候选微簇产生,则其继续保留在临界候选微簇集中,再次对临界候选微簇进行合并。最后,ASWDStream算法在该滑动窗口中,由聚类运算生成两个微簇集:候选微簇集T1和临界候选微簇集T2。
3 仿真实验与结果分析
实验在统一平台下进行,其中:CPU为2.16 GHz的 Pentium(R)Dual T3400,内存为2GB,操作系统为Windows Xp。算法采用Microsoft Visual C++编程实现,并通过Matlab7.0对结果进行分析和比较。
3.1 验证数据集
实验采用KDD CUP竞赛中的数据。该数据集采自于主机上的一个模拟网络,产生于美国国防部DARPA部门的一项入侵检测评估系统,它包括了63天的TCP Dump现实数据,累计有500万余次的会话内容,攻击方式大约有几十种。KDD CUP数据是受认可度较高的一套数据,经常被用于入侵检测系统性能的评估,在挖掘试验中具有广泛应用。数据集在正常网络数据的基础上,又将多种类型的入侵数据加入进去。这些入侵行为主要有以下四大类[17]:DOS、R2L、U2L和Probing。
3.2 数据集处理
本次试验所使用的数据集实际上是静态数据。若使用传统的基于静态数据集的数据挖掘方法对其进行挖掘和分析,可以得到令人满意的结果。但由于我们重点关注的是数据流中的数据挖掘算法,为保证算法的有效性,首先需要对静态数据集作动态化的处理。在试验之前对原始数据进行了如下的处理规定:
单遍扫描是对每条TCP连接记录的读入、分析处理和丢弃实施一次性处理,这样在效果上便实现了对数据流单遍处理的目的。实时处理是指加入一个3秒时钟周期,每隔一个时钟周期便将分析结果记录归档,并将其与上次结果进行比较,描出二维状态转移图像,这样便可以对网络数据流进行实时监控。
3.3 聚类结果比较
算法中的参数进行如下设置:初始数据点个数N=200 k,衰减因子λ=0.25,数据流流速v=1000,u=10,ε1=ε2=16,离群点阀值β=0.2。ASWDStream算法和CluStream算法采用同样的参数,从两个方面对两种算法进行聚类精度对比实验。

图5 运行时间比较 图6 运行时间比较
3.3.1 算法时间效率比较 图5描述的是两个算法的运行时间随自然簇个数增加而变化的情况。数据集中所使用的数据维数为20,生成的数据的个数为200 k。结果表明,在固定数据流的维数和个数的情况下,从5到25递增自然簇的个数,两个算法的执行时间随着簇个数的增多呈线性增长,ASWDStream算法的运行时间始终要快于CluStream算法。原因在于ASWDStream算法采用微簇取代单个记录作为增量更新的粒度,从而降低了算法的处理步骤。
图6同样为算法运行时间的比较,在产生另一组数据时,由5至25数据点的维度不断变化,此时数据点的个数和自然簇个数保持不变。由此可见,当维度从5至25数据点变化,ASWDStream算法和CluStream算法运行的时间都呈线性增长,ASWDStream算法的运行时间始终要快于CluStream算法。
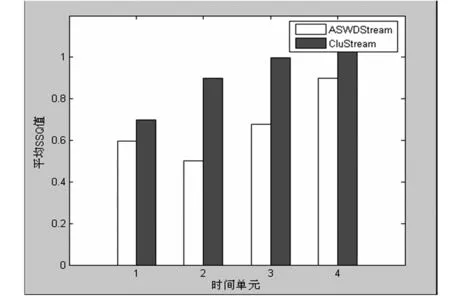
图7 聚类质量比较
3.3.2 聚类质量比较 图7显示的是两个算法的聚类质量比较图。该图呈现的是在不同的时间单元下,算法计算得到的SSQ值(SSQ是一种比较聚类质量的方法,其值越小,算法的聚类质量越好)。由上图表明,通过CluStream算法获得的SSQ均值要小于通过ASWDSteam算法获得的SSQ均值,也就是说ASWDSteam算法的聚类质量要好于CluStream算法。
3.4 应用验证
由于KDDCUP数据集数据过多,且内容属性有较多类似的地方。因此只从中选取1万条记录用于本试验,该数据由以下两部分组成:(1)3000条测试样本中包含9种入侵类型,分别为:
ftp_write,ipsweep,neptune,pod,spy,buff_overflow,perl,eject,nmap。(2)7000条训练样本中包含7种入侵类型,分别为:ftp_write,ipsweep,neptune,pod,spy,buff_overflow,perl。
试验数据的组成如表2和表3所示。
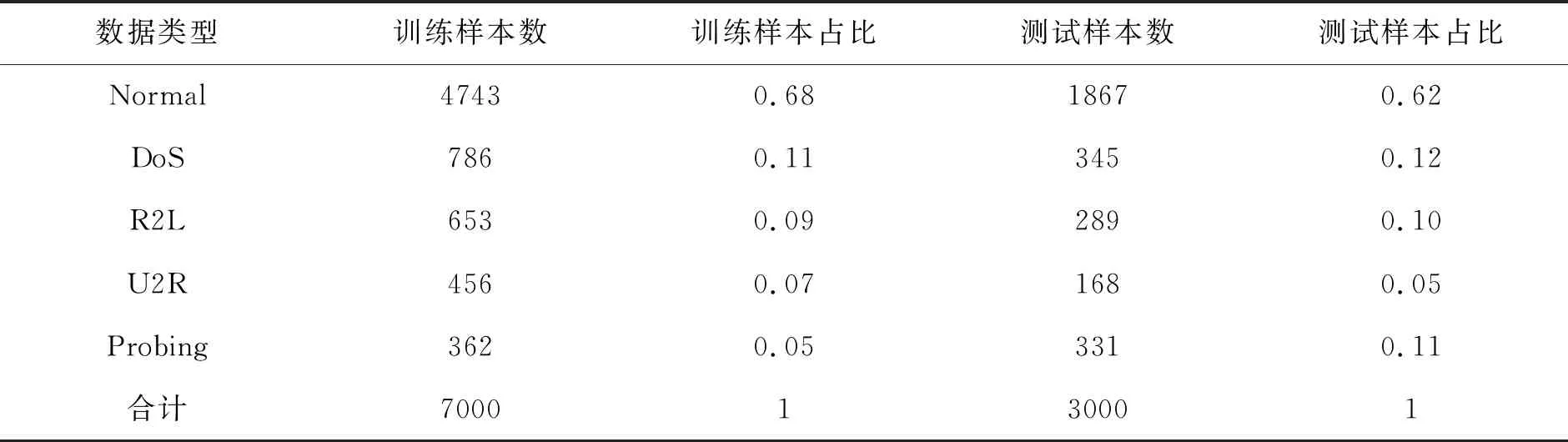
表2 试验数据类型分布

表3 试验数据入侵部分的组成
三个参数(准确率、误报率、漏报率)来衡量入侵检测系统的检测性能。表4和表5为算法分别对训练数据集和样本数据集入侵检测的实验结果:
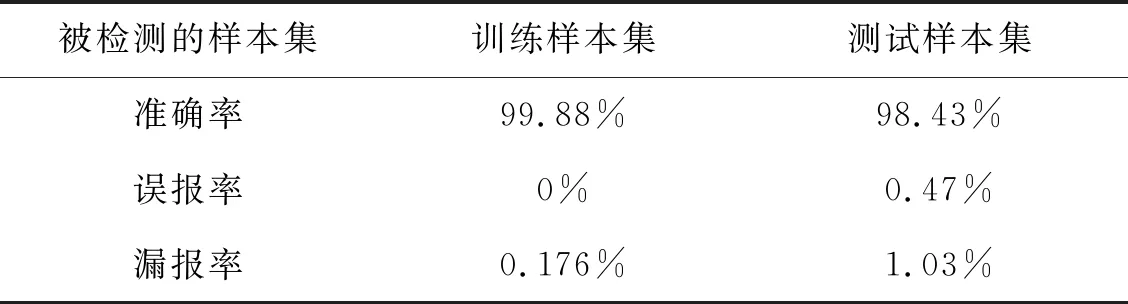
表4 试验结果分析1
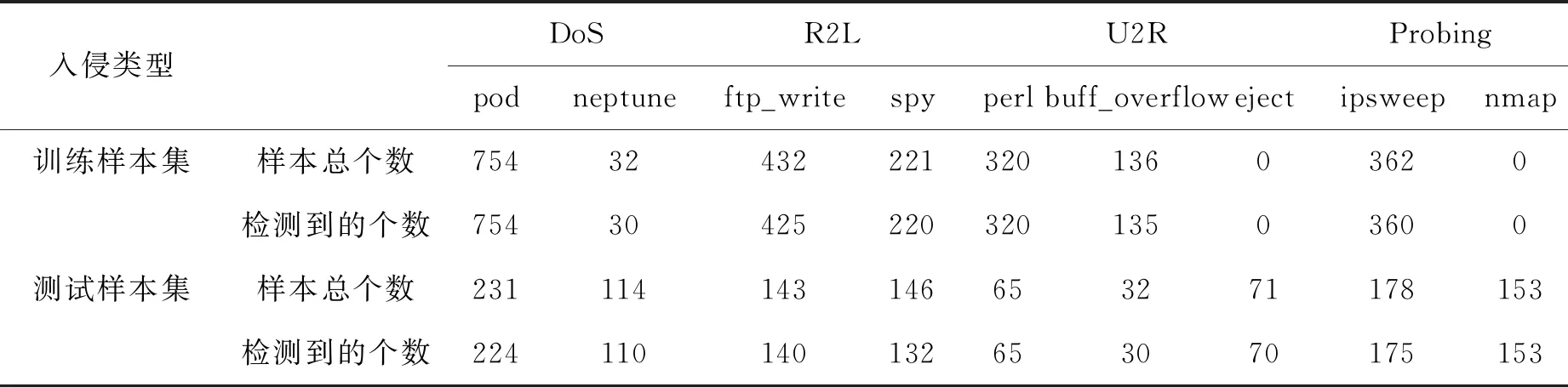
表5 试验结果分析2
从表4和表5分析可知,基于ASWDStream算法的入侵检测系统在应用验证中表现出了较好的检测性能。应对海量、高速数据流,该算法具有较高的检测率、较低的误报率和漏报率,且保证了处理的实时性,对特定类型,尤其是R2L和Probing两种入侵行为,具有较高的检测能力。另外,对于新的入侵类型,ASWDStream算法也有较好的识别能力。
4 结语
基于对传统的入侵检测系统进行的模型分析,尝试将数据流聚类挖掘融合到入侵检测中,提出了DSMIDS模型。通过一种基于分治思想的发现孤立点的优化方法,研究并设计了快速剔除孤立点的算法,解决了孤立点对提取训练模型的影响。提出了基于时间衰减滑动窗口的数据流聚类挖掘的改进算法ASWDStream,本算法有效弥补了传统数据流聚类算法的不足。仿真实验表明,ASWDStream具有较好的聚类效果,在入侵检测系统中具有较高的实时性和检测率。在以后的研究中,可以尝试将人工智能的最新研究领域成果与入侵检测系统相结合,开发出对网络变化适应性更强的、检测效率更高的网络安全检测系统。
