在线学习神经网络用于空调负荷预测研究
2020-09-24沈俊杰龚延风刘伟
沈俊杰 龚延风 刘伟
南京工业大学城建学院
0 引言
空调负荷预测是冷水机组运行的基础条件,是冷冻站控制策略制定的必要依据。目前,基于历史统计数据的空调负荷预测技术发展比较成熟,方法主要有支持向量机法,神经网络法,回归分析法和时间序列分析法等[1]。但是这些预测方法都需要大量的历史空调负荷数据,需要建筑建成后运行较长时间才能应用这些方法工作,导致了新建建筑建成运行初期难以进行负荷预测。同时对于一些既有建筑,由于历史负荷数据不充足、记录不完整或缺乏历史数据,也影响了负荷预测方法在既有建筑节能改造中的推广使用。
新建建筑建成运行初期和既有建筑缺乏历史负荷数据时均称为小样本条件。为了解决小样本条件下空调负荷预测问题,扩大负荷预测的使用范围,提高冷冻站智能化运行的水平,本文提出了一种机理计算与神经网络学习相结合的在线负荷预测方法。结合暖通空调专业的已有成果和统计学习两者的优势建立适用于小样本条件的在线负荷预测流程,以求在建筑运行期间随着实际负荷数据的逐步增加,通过在线学习逐步完善BP 神经网络性能,快速建立小样本建筑的空调负荷预测模型。
1 在线负荷预测流程的建立
在小样本条件下,前期负荷预测可以依靠估算模型进行工作,并结合人的控制经验辅助其进行评判分析,但主要仍以估算负荷为控制依据,以实现冷水机组台数的实际控制。与此同时,通过测量供回水温差和流量可以得到建筑的实际逐时冷负荷,该数据将成为样本供BP 神经网络在后台试训。在持续的试训过程中,神经网络的性能将逐步得到完善,最终可以投入使用。基于此的方案的小样本条件下的负荷预测流程,如图1 所示。
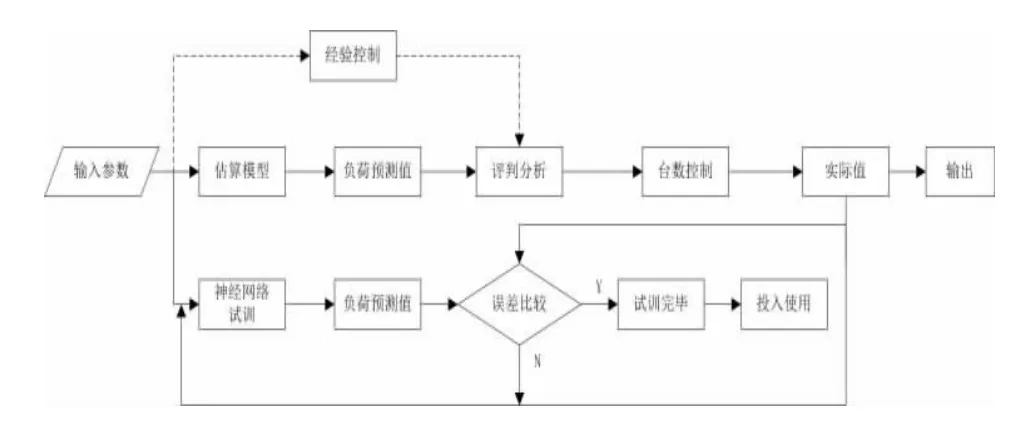
图1 小样本条件下的负荷预测流程图
当神经网络试训结束后投入使用,此时用神经网络模型取代估算模型,并结合人的控制经验对冷水机组台数进行实际控制。为了防止预测值在后续运行中出现较大误差,仍需将负荷实际值与预测值进行比较。当负荷预测值和实际值的误差满足要求时,保持原模型不变。未满足要求时,将负荷实际值继续加入神经网络模型,对模型进行修正完善。后期稳定运行时的负荷预测流程图如图2 所示。
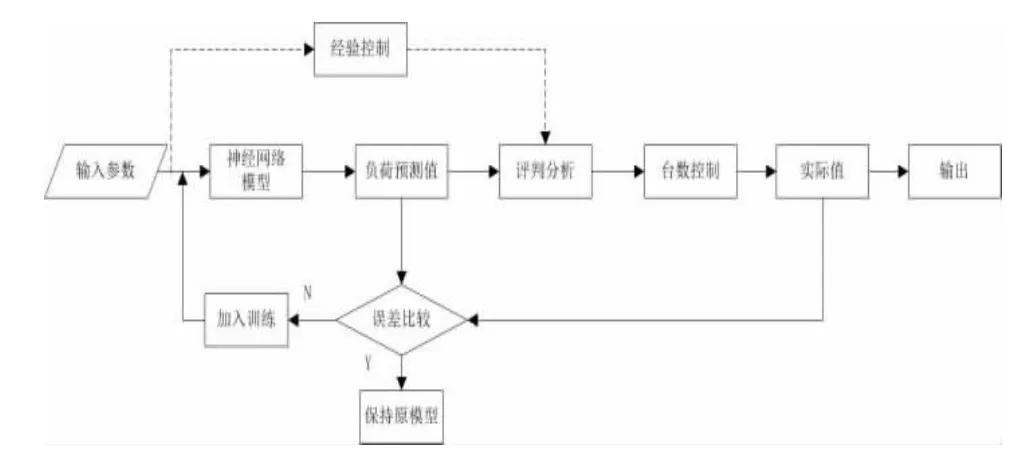
图2 后期稳定运行时负荷预测流程图
2 负荷估算模型
2.1 负荷估算方法
基于空调负荷机理的估算模型如下:
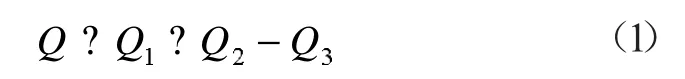
式中:Q1为通过围护结构得热量形成的冷负荷,可采用冷负荷系数法求得,分为通过墙体、屋顶和窗户瞬变传热形成的冷负荷和通过窗户日射得热形成的冷负荷,W;Q2为通过室内热湿源散热散湿形成的冷负荷,包括设备,照明和人体的得热,W;Q3为新风冷负荷,W。
Q1的计算难点在于通过墙体,屋顶和窗户的传热冷负荷计算。目前常用的负荷计算方法主要分为两类。一类是基于设计条件的动态负荷计算方法,如谐波反应法、反应系数法、Z 传递函数法等。由于现有研究成果都是计算在设计条件下的空调负荷,尚无法直接应用到实际气候条件下的动态负荷。另一类是针对季节或年度负荷的计算方法,如:如度日法、当量满负荷运行时间法、负荷频率法等,不能用来进行逐时负荷预测。空调负荷的估算面对实际不断变化的室外气象条件,本文提出基于动态负荷修正模型。
2.2 基于动态负荷的修正模型
因为此模型主要用于小样本条件下的负荷预测,所以预测值精度要求可适度放宽。基于此并考虑到估算模型的简便易算,决定将通过墙体,屋顶和窗户的瞬变传热冷负荷采用其逐时得热量进行替代。
2.2.1 通过墙体,屋顶和窗户的得热量的修正
通过墙体、屋顶的得热量:
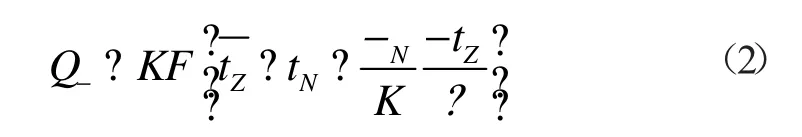
式中:K 为围护结构传热系数,W/(m2·K);F 为墙体或屋顶的面积为室外综合温度的平均值,可以根据天气预报的最低最高气温以及太阳辐射强度计算得出,℃;tN为室内空气温度,℃;υ 为外墙对综合温度扰量的衰减度,由于外墙结构已定,可通过计算获得;Δtz为实际逐时综合温度与全天综合温度的差值。
通过窗户的瞬变传热得热量:
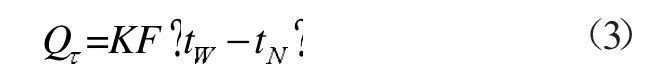
式中:F 为窗户的面积,m2;tw为室外空气逐时温度,℃。
2.2.2 其他负荷的估算
通过室内热湿源散热散湿形成的冷负荷,包括设备,照明和人体的得热。由于设备,照明和人员数量等输入参数不能准确测量,导致冷负荷无法精确计算。但可以按照建筑的具体使用功能估算得到,为了保证冷负荷具有一定的富裕量要求取较大值。相关工作人员需要根据现实情况进行合理估计,将合理逐时估算值输入程序。此外,为了与逐时冷负荷计算方法相匹配,逐时新风冷负荷需要测量计算时刻的室内外空气焓值和新风量得到。
3 BP 神经网络模型
3.1 BP 算法的选择
标准BP 算法每次只是基于单个误差Ek而言,而本文采用“累积BP 算法”,是在读取整个训练集里所有的训练样本一遍后,计算出每一个样本数据的误差Ek,得到每一个样本数据的阈值和权重的变化值,在此之后会将阈值和权重的变化值累加起来更新一次,这样不断循环,直至训练集的累计误差最小化[2],方可确定最终的阈值和权重。因为每次所有的样本数据对于模型的改善都有贡献,所以相比于标准BP 算法,参数更新的频率要更快,还可以更加有效地加快收敛速度。累积BP 算法流程图见图3。
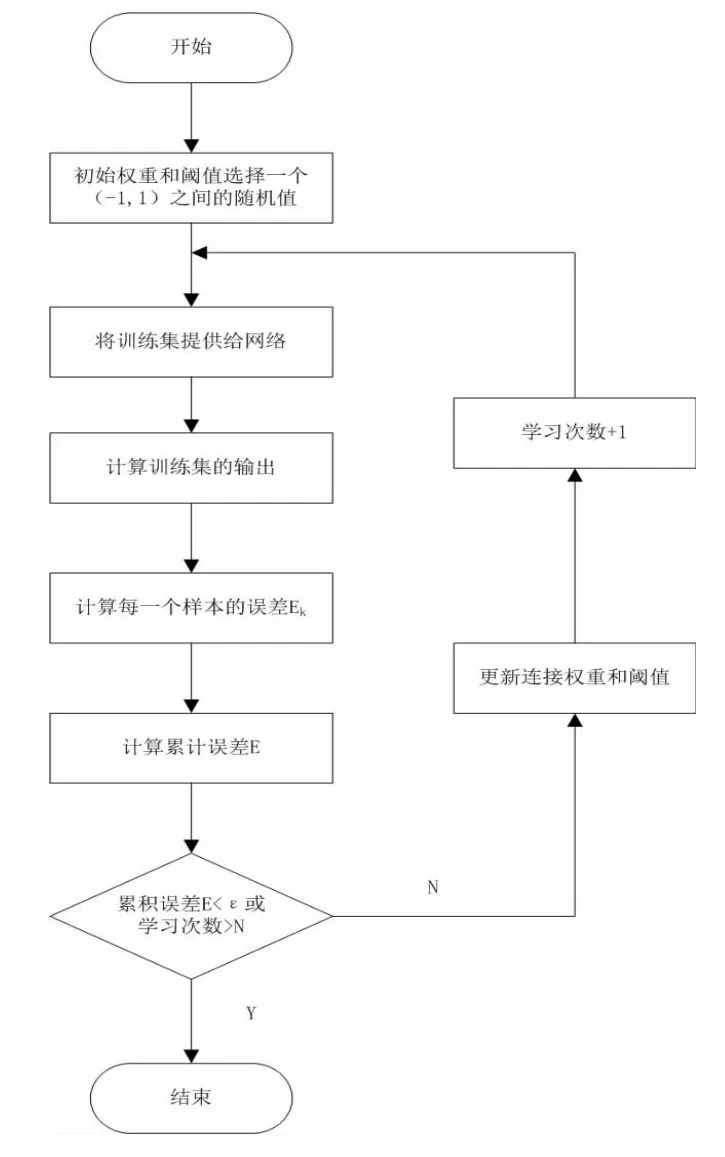
图3 累积BP 算法流程图
3.2 输入层输入参数的确定
室内空调负荷的影响因素主要包括外扰因素和内扰因素。外扰因素包含室外气象参数,其中室外干球温度和太阳辐射的影响较大。内扰因素包含室内人员、照明和设备的数量、作息和工作形式,由于室内人员情况变化较大,无法得到准确数据,因此需要对其进行模糊化处理。照明和设备相比于人员来说,影响较小也相对比较固定,可以不做考虑。综上所述,输入层输入参数选取k-1 时室外干球温度(即前1 小时)、k时室外干球温度、含湿量、k-1 时的太阳辐射、k 时的太阳辐射和k 时人员。
3.3 神经元个数的确定
在BP 网络中,隐含层神经元个数的选择非常重要。Hornik et al 在1989 年证明,只需一个包含足够多神经元的隐含层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数,然而,如何选择最佳的隐含层神经元个数仍没有定论,实际应用中通常采用试错法(trial-by-error)。为了简化模拟过程,提高试错效率,首先通过以往种种方法确定隐含层神经元个数的最大值和最小值,然后分别以其为上下边界从小到大开始训练神经网络,选出最佳神经元个数。通过对6—12 个节点分别进行试错,发现了采用8 个节点时训练效果最佳。
3.4 隐含层激活函数的选择
输入层和输出层采用LinearLayer,隐含层采用SigmoidLayer,学习率为η∈[0,1],训练至直到拟合(有最大步数限制),最终输出训练和预测误差,并将预测值和实际值的对比图形化。最终的网络结构图如图4所示。
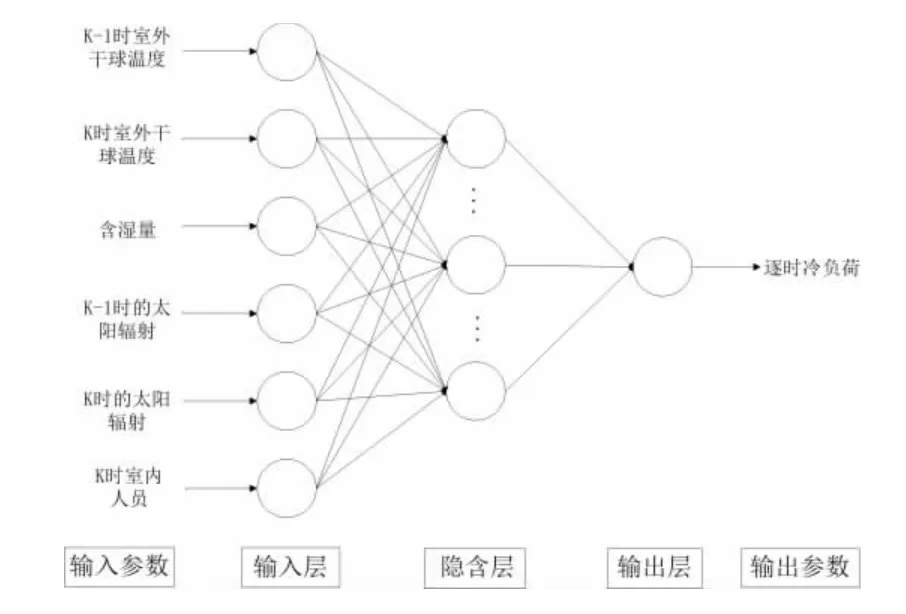
图4 神经网络结构图
3.5 数据预处理
3.5.1 数据集的建立
为了模拟小样本条件下的空调负荷预测,采用某一建筑实际运行数据创建训练所需的数据集。建筑地点位于常州,建筑高度约15 m,建筑面积约4000 m2,建筑为办公建筑,样本日期选取为2017 年6 月13日~9 月1 日和2018 年8 月1 日~8 月31 日,时间为每天的8:00~20:00(周六、周日除外)。之后将整个数据集导入MySQL 数据库,并以时为间隔将其输入神经网络模型进行训练,以求在最大效果上逼近在线负荷预测。采用“留出法”将数据集划分为训练集和测试集进行模拟,其中80%为训练集,20%为测试集,在训练集中训练出模型后,用测试集来评估其测试误差[3]。
3.5.2 归一化处理
为了消除样本数据量纲的影响,加速优化过程,提高训练精度,针对样本数据进行了归一化处理,将原始数据处理到[0,1]区间,归一化公式如下:
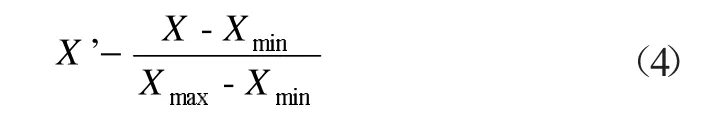
反归一化公式:
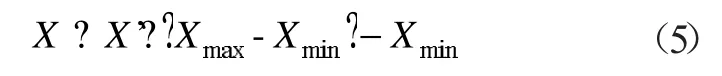
式中:X 为原始数据;X'为归一化后的数据。
4 空调负荷的预测及误差分析
4.1 预测结果和误差分析
4.1.1 对内扰因素进行模糊化处理
考虑到室内人员实际数据具有不确定性,主要是缺少统计,无法准确得到其具体数据。另外数据具有一定的波动性,不稳定。决定对其进行模糊化处理,人员的取值在[0,1]之间(0 代表没人,1 代表人满)变化。具体数据如表1 所示。

表1 模糊化取值
为了更好地比较对内扰因素模糊化和不做考虑的误差,分别选取10 天、20 天、30 天、40 天、50 天的训练样本进行预测测试,并计算了每天预测的平均相对误差,预测误差结果如图5 所示。
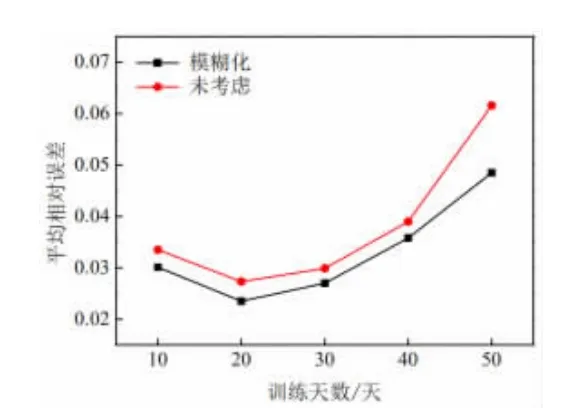
图5 平均相对误差对比图
从图5 可以看出,相比于不考虑室内人员的情况,模糊化后的平均相对误差普遍降低,降低幅度大体上在0.34%左右,最高降幅可达1.31%,说明将人员因素作模糊化处理后考虑进输入参数,可以有效降低预测误差,提高预测精度。
4.1.2 空调负荷的预测
1)在线负荷预测
衡量模型泛化能力的评估标准主要是相对误差的大小。
相对误差:
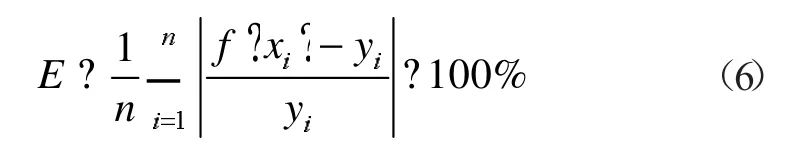
式中:n 为测试样本数量;f(xi)为预测值;yi为实际值。
将预测得到的预测值和实际值进行整理,得到图6。图6 分别为训练样本为1 天,2 天和3 天的预测值和实际值的对比(负荷负值代表冷负荷)。
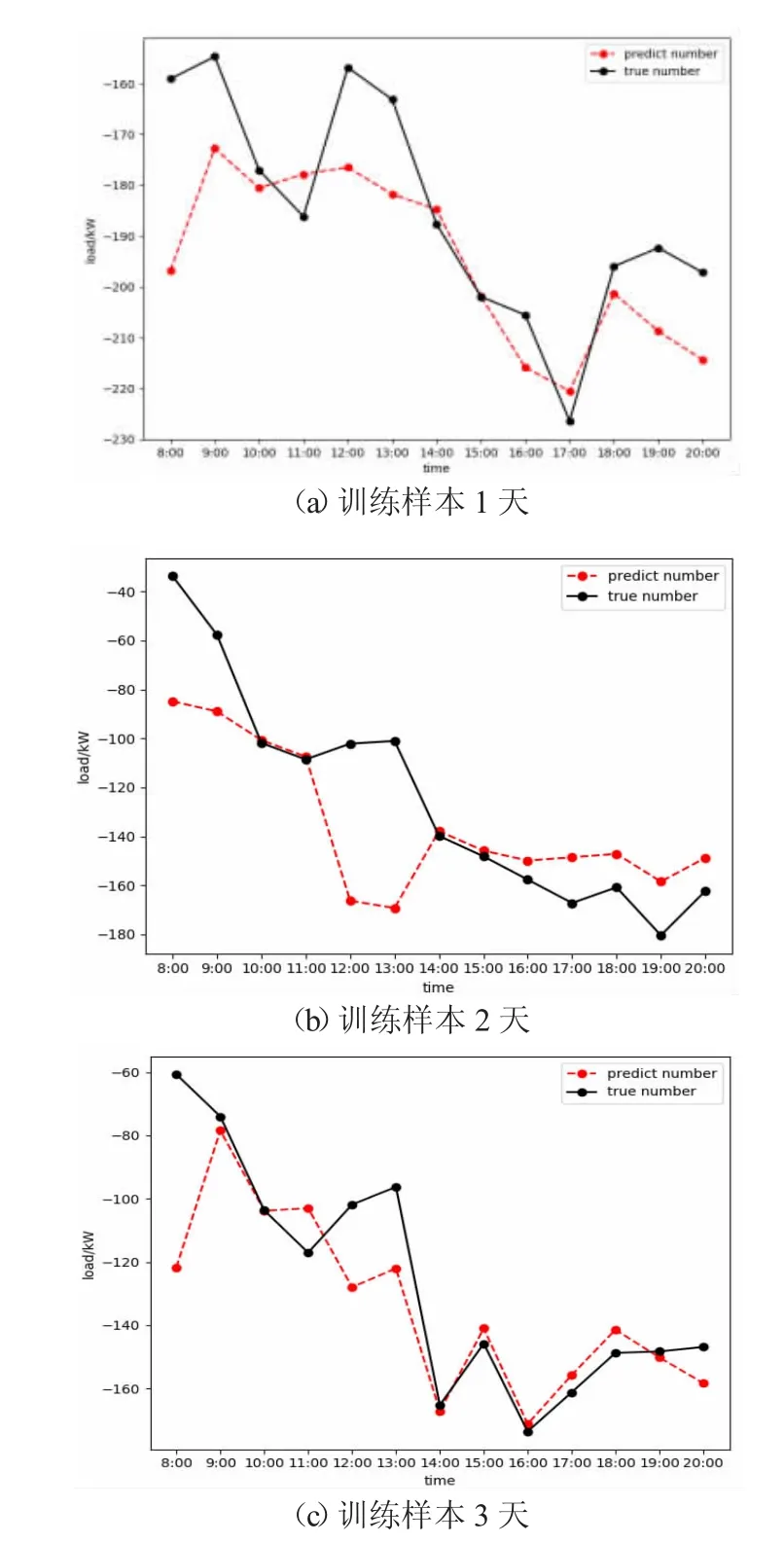
图6 训练样本为1 天,2 天和3 天时预测值和实际值比较
如图6 所示,训练样本为3 天时,起始误差仍较大,但随着预测的持续进行,预测精度逐步提高,14:00~20:00 的预测值已比较接近于实际值,相对误差在1.15%~7.79%之间。通过以上分析可得,预测刚开始前几天,大部分时刻预测值与实际值的误差较大,总体预测情况较不稳定,这是由于建筑处于运行初期,样本量数据较少导致的,但随着时间的推移,训练数据的增加,预测精度逐渐提高。
随着预测的逐步进行,预测误差逐渐变小,图7 分别为训练样本为18 天和21 天的预测结果。
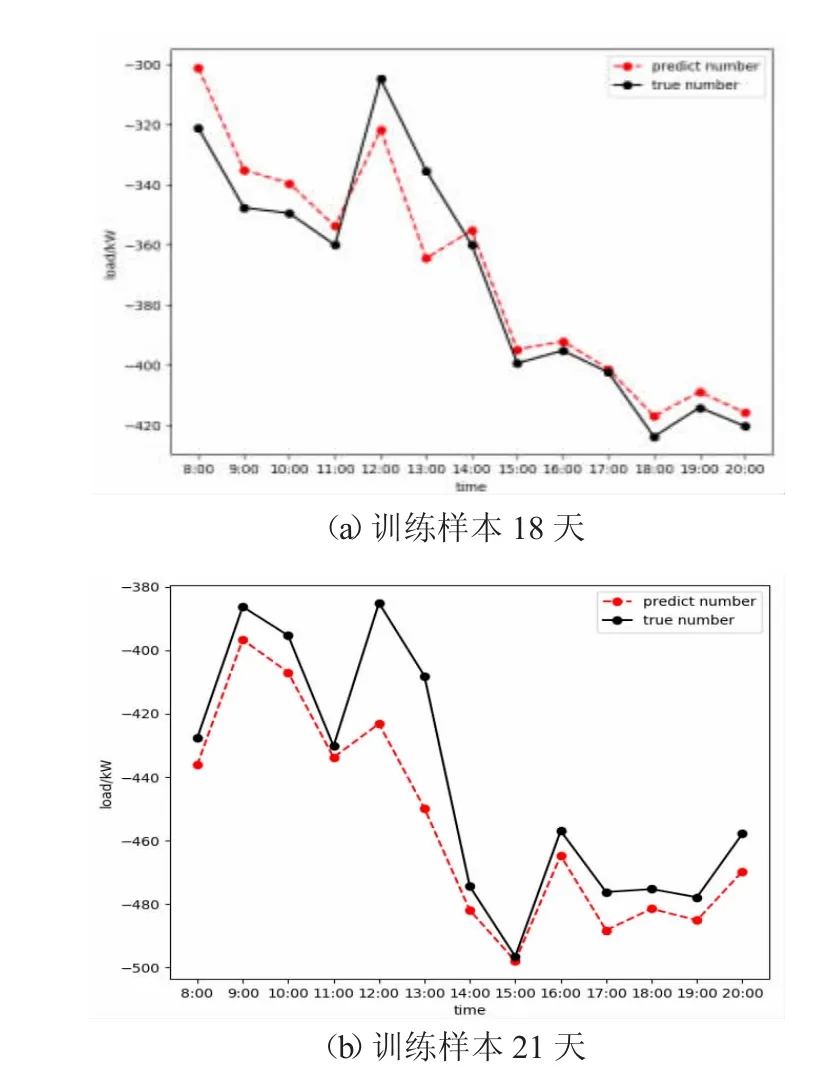
图7 训练样本为18 天和21 天时的预测值和实际值
由图7 可以看出,直到训练至第18 天时,每个时刻的预测最大相对误差为8.69%,最小相对误差为0.28%,平均相对误差为2.78%,误差很小。训练至21天时,每个时刻的预测最大相对误差为10.22%,最小相对误差为0.28%,平均相对误差为3.08%,除12:00、13:00 两个时刻误差达到10%左右,其余各时刻误差均小于3%。这两天的预测值和实际值曲线整体契合度都较高。
为了更好地分析预测精度的变化,从训练天数为18 天起,随着训练天数的逐渐增加,记录下8:00~20:00 负荷预测的相对误差和平均相对误差,具体可参见表2。
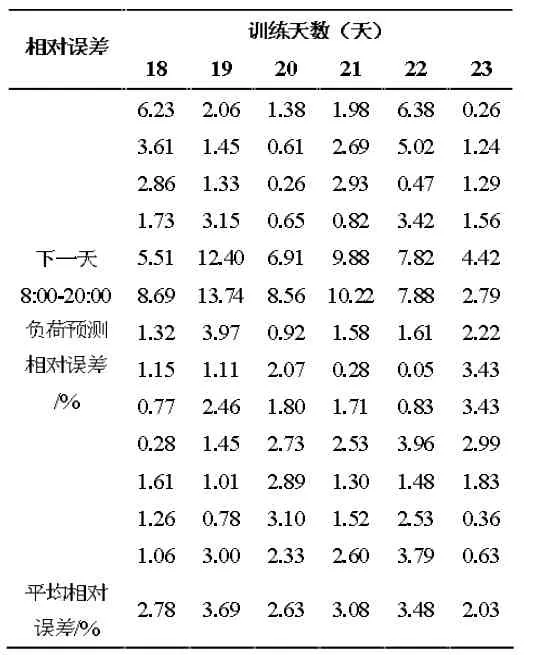
表2 负荷预测误差表
从表2 可以看出,每天的相对误差在10%以内的占96%,在5%以内的占85%。误差较大的时刻主要集中在12 时和13 时,由于人员作息情况变化较大,且较不稳定,导致预测误差相较于其他时刻明显偏大,但是总体上每天的平均相对误差都在4%以内。因此可以得出,从18 天以后,随着训练天数的增加,预测精度并没有较大提升,负荷预测的误差已经趋于稳定,预测值和实际值的相对误差在一定天数内已缩减至精度范围内,达到预期期望要求,可以选用其中预测效果相对较好且训练时间较短的模型,最终选择训练天数为22天时的模型投入中期预测。
2)模型泛化性能的分析
选用2017 年6 月13 日~7 月12 日这22 天训练所得模型,对同一年的7 月13 日~8 月3 日的空调负荷进行一次中期预测,预测结果如图8 所示。
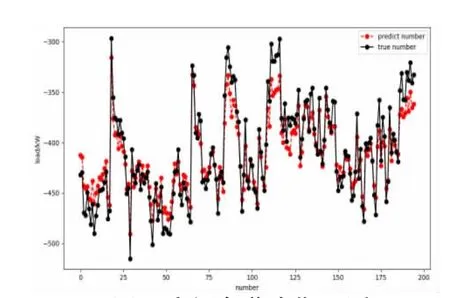
图8 空调负荷中期预测
从图8 可以看出,预测负荷的相对误差在10%以内的占96%,在5%以内的占80%,最大相对误差为12.38%,最小相对误差为0.04%,平均相对误差为3.42%,可以看出针对同一年之内的负荷数据的预测,泛化性能较好。
为了验证模型长期预测的效果,使用2017 年6 月13 日~9 月1 日的负荷数据将模型训练完毕后,采用此模型对下一年的空调负荷进行预测。由于一年的空调负荷数据过多,这里决定选取2018 年8 月1 日~8月31 日数据作为预测数据,预测结果如图9。
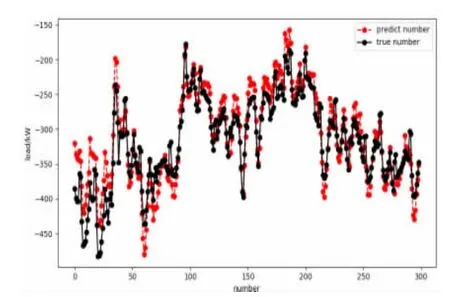
图9 空调负荷长期预测
从图9 可以看出,预测负荷的相对误差在15%以内的占96%,在10%以内的占81%,最大相对误差为17.68%,最小相对误差为0.01%,平均相对误差为6.38%,下一年的负荷预测相比同一年的误差有所增加,但仍在可接受范围内,这是因为相对于一个月内的气象参数而言,一年后的气象参数变化情况要更为复杂,预测难度加大。
6 结论与展望
1)采用基于机理的经验模型与神经网络相结合的负荷预测方法,可以实现在小样本条件下建筑空调负荷的实时在线负荷预测,为冷水机组智能控制打下基础,便于无人值守机房的实现。
2)BP 神经网络的学习时间冬、夏季分别需要20天左右,基本上满足控制精度要求,模型泛化性能较好。实际工程中,随着学习样本的不断增加,本文提出的模型将随时间逐步成长,预测的精度与泛化能力将逐步提高,直至完全满足工程要求。
