随机森林结合直接正交信号校正的模型传递方法
2020-09-23王其滨杨辉华潘细朋李灵巧
王其滨,杨辉华,,潘细朋,李灵巧,
(1.桂林电子科技大学电子工程与自动化学院,广西 桂林 541004;2.北京邮电大学自动化学院,北京 100876)
1 引 言
近红外光谱分析技术能够实现快速、无损、在线分析样本,在化工,食品,农业,药品等多个领域得到了迅速的发展[1-4]。模型传递技术是近红外光谱分析中一种常用的方法,用于解决仪器间因不同的时间,环境或者机械加工误差,而导致模型通用性较差的问题[5]。在实际的应用中,一台光谱仪上建立的校正模型,如果直接用于另一台光谱仪进行样本的分析会产生较大的偏差,无法得到理想的预测结果。尽管相同型号的仪器实现模型的共享最终必须要依靠硬件的提高,但模型传递方法依然有必要进一步研究下去[6]。目前,模型传递技术主要分为有标样和无标样两种方法,在实际中使用最为广泛的是有标样的直接校正算法(DS)、分段直接校正算法(PDS)以及Shenk′s算法等。这些方法能够实现模型传递的效果,但在进行模型传递的过程中,并没有考虑待测量的特征,无法在去除光谱中存在的背景噪声的同时,很好的保留与待测变量有关的光谱信息。对此,多项研究将正交信号校正方法引入光谱的处理中,王安冬等人[7],提出用正交信号回归法对不同批次中药材光谱进行模型传递研究。贾一飞等人[8],提出直接正交信号校正方法结合SBC算法,用于近红外定量模型批次间的传递并取得了不错的效果。刘贤等人[9],提出将正交信号校正用于秸秆青贮饲料粗蛋白近红外分析模型传递中,较好的实现了模型传递的效果。
直接正交信号校正(Direct Orthogonal Signal Correction,DOSC)方法已经被证明能够大幅提高近红外光谱模型的预测能力和稳健性,是一种被广泛采用的预处理方法[10]。但在实验过程中发现,光谱数据中的噪音并不绝对正交于光谱的浓度阵,因此DOSC方法只能除去它们在与浓度阵正交方向上的投影,噪音残留的部分便会影响模型的稳定性,并可能造成过拟合。针对DOSC的这个缺陷,本文提出了一种改进的方法,即RF-DOSC模型传递方法。该方法在应用DOSC处理数据之前,首先采用随机森林波长选择方法预先除去那些噪音含量丰富的区域,尽可能的去除噪音残留部分的干扰。
2 RF-DOSC算法
RF-DOSC模型传递方法,首先将光谱运用随机森林算法进行波长筛选,用于去除光谱中含有丰富噪声的区域,之后利用DOSC方法对优选后的光谱进行校正,减小不同批次样本的光谱背景差异,最后在构建一元线性回归模型,求得传递矩阵。通过在近红外玉米光谱数据集之间进行传递模型实验,实验结果相较于传统方法光谱差异和预测标准偏差都有所降低。
2.1 变量筛选
RF-DOSC模型传递方法,采用随机森林算法进行近红外光谱波长筛选。随机森林最早是由Breiman提出的一种集成学习方法[11],它以决策树为基学习器,在训练过程中加入了随机属性选择。随机森林算法利用Bootstrap重采样建立训练集,根据包外数据误差OOB(out-of-bag)对特征变量重要程度进行衡量,将各个变量重要程度进行降序排列,通过剔除相对不重要的变量,从而实现变量的筛选。
对于每一个随机森林中的决策树,使用其相应的OOB(包外数据)数据来计算它的包外数据误差,记为errOOB1。随机地对包外数据OOB中所有样本的特征X加入噪声干扰,并再次计算它的包外数据误差,记为errOOB2。假设随机森林中有Ntree棵决策树,那么对于特征X的重要性MX便可以根据公式(1)计算得到。
(1)
随机森林特征选择的步骤为:
(1)对随机森林中的特征变量的重要程度进行衡量,并进行降序排列。
(2)确定删除数目,从当前的特征变量中剔除相应数目不重要的变量,得到一个新的特征集。
(3)用新的特征集建立随机森林,重复以上步骤,直到剩下N个特征变量。
2.2 直接正交信号校正算法
RF-DOSC模型传递方法在波长优选后,采用DOSC方法对光谱进行校正处理。DOSC算法是在正交信号校正算法的基础上提出的一种改进算法[12],该方法将光谱矩阵X与浓度矩阵Y正交,之后将光谱阵X中与Y无关的信号去除,保留与浓度阵Y相关的光谱信息,从而能够实现在去除光谱噪声的同时,保留光谱中与目标值有关的有用信息。该方法的实现过程如下。
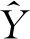
3)通过将ZZ′进行奇异值分解,求得Z的得分矩阵T。
4)回归计算权重矩阵W=X-1T,计算新的得分矩阵T=XW,载荷矩阵P=X′T(T′T)-1。
5)去除X中与Y正交的噪声,XDOSC=X-TP′(XDOSC为正交信号校正后X矩阵)。
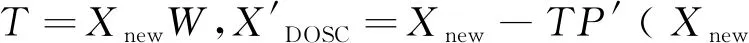
从上述方法步骤可以看出,DOSC算法是将光谱阵X投影到一个由标样集光谱X和浓度Y确立的空间中,光谱X在此空间中只保留了与浓度阵Y相关的部分,与浓度阵Y无关的部分被去除,因此该方法能够有效的消除光谱中与目标值Y无关的背景噪声。通常运用DOSC方法进行预处理后的光谱,在进行回归建模分析可以取得比不经过预处理建模更好的预测结果。
2.3 校正模型建立
RF-DOSCR模型传递方法在经过直接正交信号校正处理后,采用一元线性回归建立模型传递的校正模型[13]。设主仪器上测得光谱矩阵表示为Xm,从仪器上测得光谱矩阵表示为Xs,则光谱数据第i个样品在第j个波长点上的吸光度可表示为Xm(i,j)和Xs(i,j),其应满足如下一元线性回归方程:
(2)
式(2)中,第j(j∈1,…,p)个波长点对应的回归系数分别为b0(j)和b(j)。由式(2)可得:
(3)
其中,[1n×1Xs(:,j)]+表示[1n×1Xs(:,j)]的广义逆矩阵。
(4)
式中,回归系数b0(j)和b(j)可以通过公式(3)求出。从仪器上测得的未知样品光谱X′(n′×p)(其中n′为未知样品数),通过公式(4)可以转换为与主仪器上测得的一致的光谱Xstd,传递后的从仪器的光谱数据便可以使用主机建立的校正模型进行样品的分析。
3 实 验
3.1 实验数据
实验采用玉米数据集验证了RF-DOSC模型传递方法的有效性。数据是由Eigenvector Research公司提供的玉米数据集(http://www.eigenvector.com/data/Corn/index.html),数据集包含3台仪器上80组玉米的光谱数据,数据的波长范围为1100~2498 nm,样本维度为700,波长间隔为2 nm,提供了包括玉米的水分、油分、蛋白质和淀粉四种性质参数。
3.2 数据处理
光谱处理过程主要分为两个阶段,分别是利用随机森林进行光谱变量的优选和通过DOSC对光谱进行校正处理。波长优选阶段,将光谱信息重叠、冗余,含有大量背景噪声等光谱区间作为主要的关注对象,采用随机森林算法将变量的重要程度进行排序,通过剔除相对不重要的变量,实现变量的筛选。实验过程中,采用交叉验证均方根误差(RMSECV)作为模型的评价指标,通过选择不同的波长数进行实验,将误差最小时对应的波长数设为最佳波长数。光谱校正处理阶段,采用DOSC方法,将光谱正交分解后,进一步去除与待测量无关的光谱信息,能够很好的校正光谱中因温度,时间,仪器等因素的变动带来的光谱背景差异。对比试验采用SG卷积平滑预处理方法对光谱数据进行处理,用于消除光谱的噪声,提高样本的信噪比。
3.3 建立定量模型及评价指标
实验过程通过K-S算法对玉米数据集进行标样集的选取,该方法通过计算光谱之间的欧氏距离,能够选取光谱中最具代表性的样本子集作为标样集。实验将数据集按照成分进行降序排列,然后通过改变不同的目标值,就能够对不同的成分进行预测。玉米数据集一共80个样本,在主仪器光谱数据集上选取50个测试集,30个校正集,采用10折交叉验证,利用预测标准偏差(SEP)作为评价指标得到最优的PLS模型主因子数,建立主仪器的定量分析模型。实验采用光谱平均差异(ARMS)、预测标准偏差(SEP)和光谱校正率(Prcorrected)作为RF-DOSC模型传递方法的评价指标。其中ARMS越小,说明两个不同的主从光谱仪测得的光谱差异越小,SEP越小,表明所建模型的预测能力越强,Prcorrected值的大小,代表模型传递方法的传递效果好坏。ARMS和SEP计算公式如下式(5)和(6):
(5)
(6)
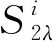
(7)
式中,ARMSuncorrected代表模型传递前为校正的平均光谱差异;ARMScorrected代表模型传递后校正过的平均光谱差异。
4 结果与讨论
4.1 波长变量数筛选结果分析
近红外光谱往往变量数很大,维数较高,且光谱信息重叠、冗余,光谱中含有大量背景噪声等问题。通过对光谱数据进行波长选择,可以去除冗余数据和背景噪声,降低数据维度,简化算法的复杂度。实验采用玉米水分成分含量为例,通过随机森林算法进行波长筛选,然后进行PLS回归建模预测。实验采用交叉验证均方根误差(RMSECV)作为模型的评价指标。如图1所示,波长数的变化对RMSECV有很大的影响,整体的变化呈先降低后升高的趋势。RMSECV的值越小,说明模型的预测能力越强。在波长数为70周围时,RMSECV的值最小,之后随着波长数的增加,RMSECV的值又逐渐变大,这有可能是加入了一些与模型预测不太相关甚至无关的变量。所以,本文的实验,波长筛选的数目设定为70,以获取一个最优的样本集,从而达到最好的预测效果。
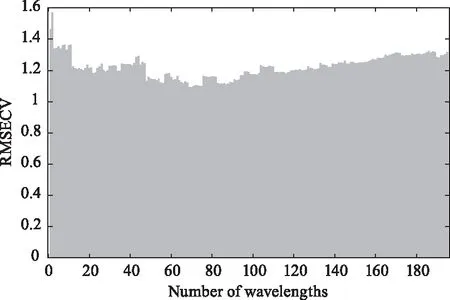
图1 玉米水分成分RMSECV随波长变量数的变化情况
4.2 数据校正处理结果分析
在波长优选后,采用直接正交信号校正算法进行光谱的处理,通过正交的数学方法将与浓度阵无关的光谱信号滤除。设从仪器1表示为S1,从仪器2表示为S2。为了能够直观的观察直接信号校正算法的校正效果,实验在全光谱上进行光谱的校正处理,实验结果如图2(a)、(b)所示。
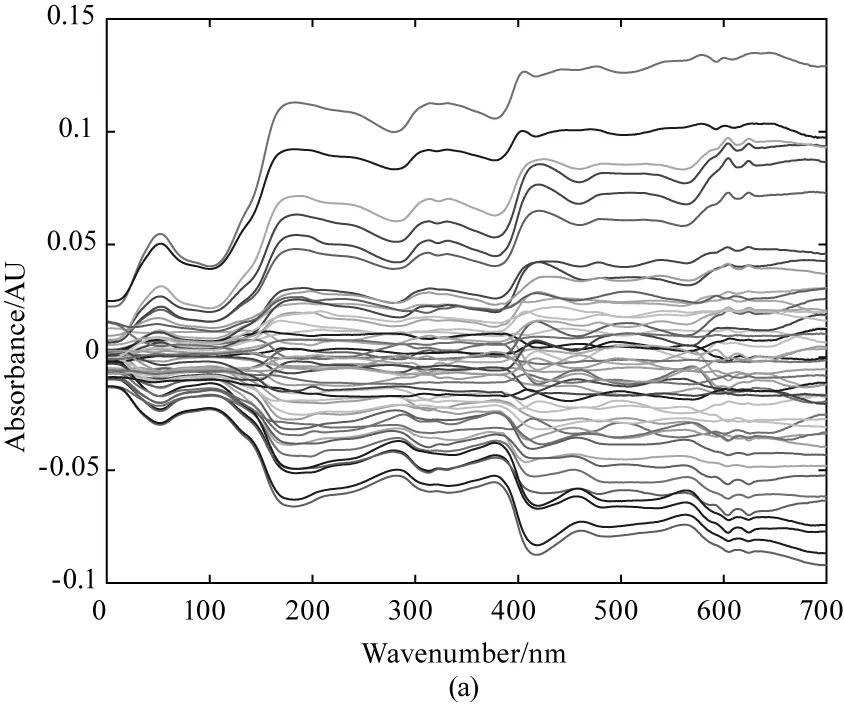
图2 处理前后S1玉米样本光谱对比图
其中,图2(a)为S1原始光谱与平均光谱的差值光谱图,图2(b)为S1直接正交信号校正处理后与平均光谱的差值光谱图。通过将玉米样本处理前(a)后(b)的S1差值光谱图进行对比,可以发现在光谱的处理过程中,光谱的整体形状并没有发生很大的差别,但校正处理后,光谱曲线变的更为光滑,且光谱的排列也比校正前更整齐紧密,也说明直接正交信号校正处理后去除了光谱中的噪声,同时也保留了原光谱中的主要信息。
4.3 模型传递前后平均光谱差异对比
使用RF-DOSC模型传递方法,建立玉米样本近红外光谱校正模型。分别计算对比两个从仪器玉米样本传递前后的平均光谱差异,可以得出RF-DOSC模型传递方法的效果。表1记录了RF-DOSC算法模型传递前后S1和S2间的光谱差异以及光谱校正率。以S1玉米的水分成分为例,校正前光谱与主仪器光谱平均差异为0.2096,校正后光谱的平均差异为0.0568,通过校正率计算公式(8)计算可得其光谱校正率为92.66 %,可见RF-DOSC模型传递方法可以很好的消除主仪器光谱和从仪器光谱之间的差异。

表1 测试集经RF-DOSC算法传递前后主从仪器间的光谱差异
将RF-DOSC算法与DS、PDS和DOSC三种算法模型传递后以及未校正的光谱平均差异进行对比,如表2所示。从表2数据我们可以看出,四种模型传递的算法均能有效的减小光谱的平均差异,其中RF-DOSC模型传递方法的光谱差异最小,也说明本文的提出的方法在四种方法中,效果最优。DOSC方法效果相较于DS、PDS模型传递方法整体表现更优,但在S1、S2仪器玉米水分成分的光谱差异不如其他方法,也说明DOSC方法在实际的实验过程中,表现不稳定,容易出现过拟合的现象。从DS、PDS方法与DOSC和RF-DOSC方法的光谱差异对比可以发现,DOSC和RF-DOSC模型传递方法在校正的过程中,受到了目标值变化的影响,而另外两种方法,则与目标值Y无关,四种成分的光谱差异均相同。
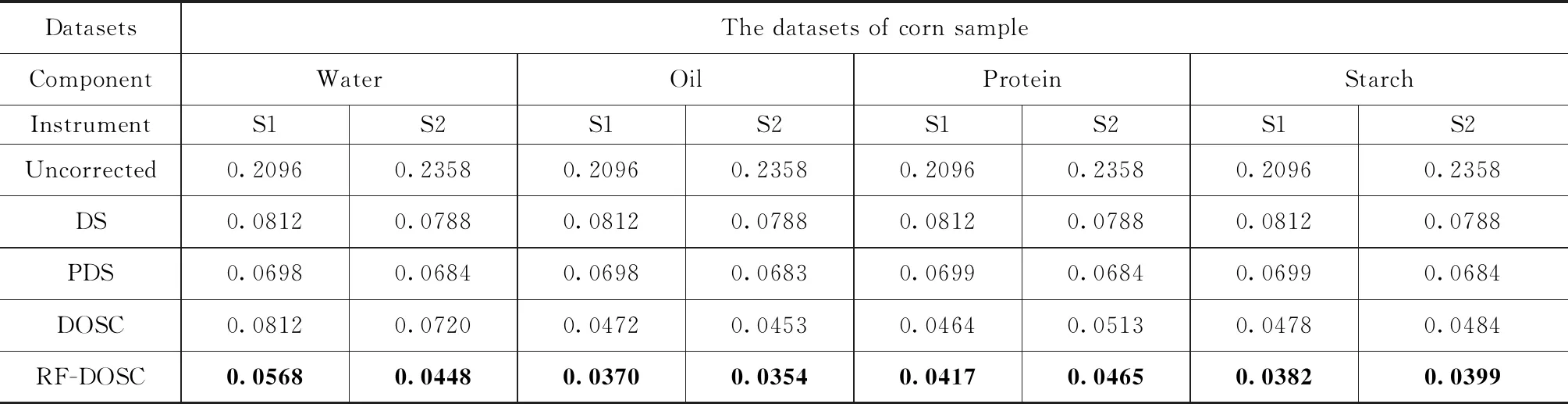
表2 DS、PDS、DOSC和RF-DOSC传递后测试集主从仪器间的光谱差异(ARMS)
4.4 模型传递前后预测结果对比
为验证RF-DOSC模型传递方法在预测精度,稳健性方面的表现,实验使用主光谱仪测得的光谱数据集进行PLS回归建模分析。通过将模型传递前后的光谱数据代入回归模型中进行分析对比,采用预测标准偏差作为评价指标,可以得出模型传递方法的传递效果。通过与DS、PDS、DOSC方法的对比,可以发现RF-DOSC模型传递方法表现最优,预测标准偏差最小。结果如表3所示。
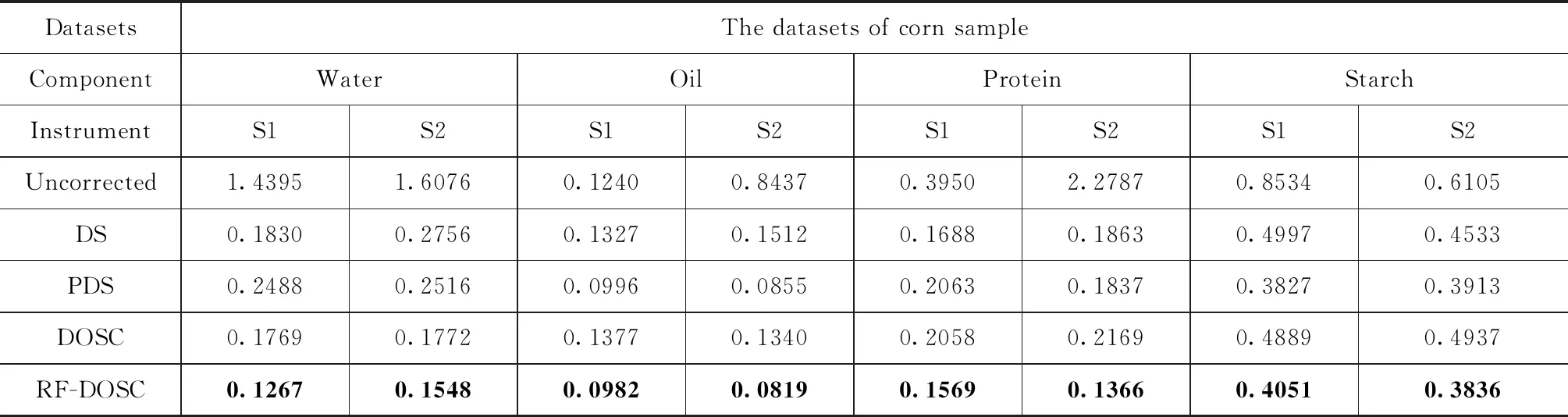
表3 DS、PDS、DOSC和RF-DOSC传递后测试集预测标准偏差(SEP)
实验结果显示,在光谱模型传递前,未校正的从仪器光谱直接带入主仪器光谱数据建立的PLS回归模型进行预测分析,会产生较大的误差。在经过模型传递之后,校正后的从仪器光谱数据预测标准偏差均有减小,其中RF-DOSC算法整体预测标准偏差最小,此时所建模型预测能力和稳健性最好。PDS整体结果表现优于DS、DOSC方法,DOSC方法在某些成分预测上,优于DS、PDS,这可能是因为光谱残留的噪声,通过DOSC正交分析后影响了模型的稳定性。实验结果也说明,通过随机森林算法预先进行波长筛选,去除含有大量噪声的光谱区间是有必要的。实验结果表明RF-DOSC算法在经过波长筛选后,采用直接正交信号校正算法消除光谱背景噪声,在建立校正回归模型,可以较好地实现近红外光谱模型的传递。
5 结 论
针对近红外光谱模型通用性较差的问题,提出了一种基于随机森林结合直接正交信号校正的模型传递方法。该方法首先使用随机森林算法实现光谱波长点的筛选,然后利用直接正交信号算法进行光谱校正,最后采用回归分析求得模型传递矩阵。该方法首先采用随机森算法进行波长的筛选,有效地去除了光谱中含有大量噪声的区间,避免了直接正交信号校正算法可能会造成过拟合的弊端。在一台主仪器,两台从仪器上测的玉米光谱数据集进行实验验证,表明该方法能够消除不同仪器间光谱的平均差异,提高模型的预测能力和稳健性。在与其他传统模型传递方法DS,PDS和DOSC算法对比之后,得出结论基于随机森林结合直接正交信号的模型传递方法能够较好地完成近红外光谱的模型传递,实现不同仪器间模型的共享。
