跨领域文本情感分类研究进展*
2020-09-23赵传君王素格李德玉
赵传君 , 王素格 , 李德玉
1(山西财经大学 信息学院,山西 太原 030006)2(山西大学 计算机与信息技术学院,山西 太原 030006)3(计算智能与中文信息处理教育部重点实验室(山西大学),山西 太原 030006)
根据中国互联网络信息中心(CNNIC)发布的第44 次《中国互联网络发展状况统计报告》,截至2019 年6月,我国网络购物用户规模达6.39 亿,而社交软件“微信”的全球月活跃用户数首次突破10 亿大关.随着诸如在线评论、微博、微信和论坛社区等社会媒体(social media)的蓬勃发展,网络上呈现出海量带有情感的主观性文本数据[1,2].文本情感分析专家Liu 教授将文本中的情感(sentiment)定义为“描述观点中所蕴含的褒义或贬义的情感倾向”[3].在本文中,情感特指情感极性(倾向),是个体用户对于产品、服务或者社会舆论等的情感认知与评价的具体体现[4].倾向性文本中的情感具有多极性,即正面(positive)、中性(neutral)或者负面(negative).按照文本情感类别的细粒度,还可以分为1~5 个星级,即强烈正面倾向、正面倾向、中性、负面倾向和强烈负面倾向.
2015 年,Hirschberg 教授指出了开展识别社会媒体中产品评价和服务中隐含的情感(sentiment)和情绪(emotion)研究的重要性[5].同年,LeCun 教授指出,深度学习在情感分析的各项任务中均取得了非常好的效果[6].社会媒体中,文本数据的大幅增加可为现有的深度学习(deep learning)模型提供丰富的数据支持[7].社会媒体中的主观性文本蕴含着丰富的情感信息,通过挖掘这些文本的情感类别信息,可为产品推荐、客户管理、口碑分析、新闻评论分析和股票推荐等应用提供技术支持.
迁移学习(transfer learning)自1995 年起受到了广泛的关注和研究,亦称作知识迁移(knowledge transfer).2005 年,美国Defense Advanced Research Projects Agency(DARPA)信息处理技术办公室发布通告,定义迁移学习为“系统识别和应用之前任务的知识和技能到新任务的能力”.文献[10]于2010 年将迁移学习定义为:利用数据、任务或模型间的相似性,将在旧领域学习的模型应用于新领域的一种学习过程.一般情况下,有标注数据的原始领域称为源领域(source domain),待测试的新领域称为目标领域(target domain).传统的文本情感分类研究假设用于训练和测试的领域间数据是独立同分布的(independent and identical distributions,简称I.I.D.),然而,现实条件下不同领域间存在分布差异,在源领域训练的分类器很难直接用于目标领域的情感分类任务.
在面对特定领域的情感分类任务时,往往缺乏大量的带标签数据,而标注需要消耗大量的人力物力,有时还需要语言学专家的支持.已有的研究积累了部分领域的带标签情感数据,完全丢弃这些数据是非常可惜的[8].因此,将现有的机器学习模型用于特定领域文本情感分类任务时,解决问题的思路之一是:有效利用其他领域的带标签数据,以摆脱对该领域标注样本的过度依赖,提升模型的泛化能力[9].跨领域文本情感分类任务存在以下3个特点.
· 第1 个特点是数据量的不对称性.源领域中往往带有大量的带标签数据,有时还可能存在多个源领域.而目标领域标注样本往往很稀少,这些宝贵的目标领域带标签信息可以为构建目标领域分类器提供有效的指导信息;
· 第2 个特点是跨领域统计的异构性.源领域和目标领域的特征分布差异性大,源领域训练的分类器不能直接应用于目标领域任务,需要执行特定的情感迁移策略;
· 第3 个特点是领域情感的可移植性.不同领域间存在领域通用的情感特征,可以作为领域迁移的桥梁,因此核心问题就是寻找领域不变性要素.
针对跨领域异构问题,迁移学习利用源领域中带标签的训练样本建立一个可靠的模型,对具有不同数据分布的目标领域不带标签样本进行预测.Yang 等人提到迁移学习可以减少跨领域情感分类的标注工作量,在某些产品上训练的分类模型,通过迁移可以帮助建立其他产品的分类模型[10].已有的大量研究工作表明:迁移学习是解决跨领域文本情感分类的有效手段之一,主要的研究思路包括实例迁移方法、特征迁移方法、模型迁移方法、基于词典的方法、联合情感主题方法和图模型方法等.
随着卷积神经网络(convolutional neural networks,简称CNN)和循环神经网络(recurrent neural networks,简称RNN)等深度学习技术在自然语言处理中广泛使用,其中词语的分布式表示(distributed representation)和多层网络架构具有强大的拟合和学习能力,已成为现阶段自然语言处理的主流技术方案[11].深度学习在面对文本情感分类任务时往往面临特定领域缺少大规模标注数据的问题.随着深度迁移学习(deep transfer learning)方法在解决领域适应(domain adaption)问题取得成功,很多研究者探索采用深度迁移学习机制解决跨领域文本情感分类问题[12].
跨领域文本情感分类(cross-domain text sentiment classification)作为自然语言处理任务中的重要问题之一,一直是产业界和学术界关注的研究热点和难点[13].国务院发布的2017 年《新一代人工智能发展规划》提出,要实现“多风格多语言多领域的自然语言智能理解和自动生成”,跨领域文本情感分类可作为完成此任务的有效手段之一.跨领域文本情感分类涉及机器学习、知识工程、人工智能以及相关的语言学研究等[14].关于跨领域文本情感分类,年度的数据挖掘和自然语言处理顶级会议以及学术期刊已有相当多的研究报道,例如国际会议ACL,AAAI,COLING,EMNLP,ICML,NeurIPS 以及ICDM 等,重要期刊IEEE TKDE、IEEE TASLP、Knowledgebased Systems、Expert Systems with Applications、Computer Speech and Language、《软件学报》以及《计算机研究与发展》等.
本文首先介绍了跨领域文本情感分类相关的背景知识.随后,分别从目标领域中有无带标签数据、情感迁移策略和可用源领域个数这3 个角度对已有工作进行了总结.由于深度迁移学习的兴起,我们还重点介绍了其在跨领域情感文本分类中的应用.我们进一步分析了跨领域文本情感分类面临的研究挑战和未来可能的突破方向.最后,我们对全文进行了总结.
1 背景知识
1.1 问题描述
在文本分析中,领域(domain)通常指文本内容所涉及的现实生活中的相似主题,如电子产品、酒店服务、电影评论和音乐评论等,亦可指微博、论坛等某种形式的社会媒体平台中文本的集合.社会媒体中的主观性文本所属领域具有多样性、数据来源具有多源性.表1 是4 个领域中部分正面和负面评论的例子,由表1 中的评论可以发现:不同的领域中用户倾向于使用不同的情感词表达情感特征,例如电影评论领域的词“无聊”和酒店评论领域的词“舒服”,Books 领域的词“thin”(薄)和DVDs 领域的词“stuck(卡住)”等.另外,同一个情感词或者短语在不同领域中的情感极性可能是不同的甚至是相反的.例如:酒店评论领域的“软”表达了正面的情感倾向,而电影评论领域的“软”则表达了负面的情感倾向.因此,当源领域训练的分类器转移到另一个新的领域时,由于源领域和目标领域不满足数据独立同分布假设,分类效率和精度会出现明显下降[15].

Table 1 Eight examples of positive and negative sentiment reviews from four domains in Chinese and English表1 中文和英文4 个领域中8 个正面和负面情感倾向评论例子
数据驱动的分类模型的性能需要满足两个基本假设:一是用于学习的训练样本与新的测试样本满足独立同分布;另一方面是必须有足够多的训练样本才能得到一个好的分类模型[16].我们看到:跨领域文本情感分类放宽了这两个基本假设,它被定义为通过迁移源领域和源领域任务的情感信息到目标领域,利用由源领域带标签数据学习的一个精确情感分类器,实现对目标领域的情感极性分类任务.
在文本情感分类任务中,X是文本集,x={w1,w2,…,wT}∈X为包含一系列词wi的评论文本.在传统文本情感分类任务中,文本由词的独热(one-hot)表示.在深度学习模型中,词wi由word2vec 表示为一个d维向量,即.词向量矩阵记为E∈RV×d,这里,V为词典的大小,d为词向量的维数.Y是情感分类的标签空间,对于二分类任务Y={正面,负面},对于5 级细粒度情感分类任务Y={强烈正面,正面,中性,负面,强烈负面}.每个训练样本记为(x,y),y∈Y是训练样本x的标签.
在文本情感分类问题中,领域D被认为是某个特征空间X及其上的概率分布P(X),通常情况下,P(X)是未知的.跨领域文本情感分类涉及多个领域,不同的领域其特征空间和对应的概率分布不同.源领域训练数据记为DS={(xi,yi)|1≤i≤N},源领域分布为PS(X).DL={(xi,yi)|1≤i≤n}为目标领域中带标签数据集,DU={xi|1≤i≤p}为目标领域测试数据集,DT=DL∪DU为目标领域数据集,分布为PT(X).一般情况下,源领域数据规模远大于目标领域数据规模,即|DS|>>|DL|.
从标记空间角度,本文将讨论两种情形的跨领域文本情感分类:一是源领域和目标领域的标记空间是相同的,即YS=YT;另一种是源领域和目标领域的标记空间是不同的,即YS≠YT.
1.2 数据集资源
已有研究工作积累了大量跨领域文本情感分类语料资源,如亚马逊(Amazon)英文DVDs,Books,Electronics和Kitchen 等4 个领域的在线评论语料是研究者们使用最多的数据集.已有的数据集资源见表2,其中多为英文数据集,如文献[2,8,14,17-66].其次是中文数据集,如文献[67-74],也有少量的German,French 和Japanese 评论数据集,如文献[75-77].已有数据集多为在线产品评论数据,也有少量的博客数据集[62]、微博数据集,如Stanford Twitter Dataset Test Set(STS),Obama Healthcare Reform(HCR)和Obama-McCain Debate(OMD)等[60].这些数据集普遍规模不大,规模较大的有:Amazon 4 种领域的大规模数据集[25];文献[63]中的IMDB,Yelp,Cell phone 和Baby数据集;文献[66]中的Large Movie Review 数据集等.

Table 2 Dataset resources of cross-domain texts sentiment classification表2 跨领域文本情感分类数据集资源

Table 2 Dataset resources of cross-domain texts sentiment classification (Continued)表2 跨领域文本情感分类数据集资源(续)
1.3 关键技术问题
跨领域文本情感分类研究面临以下4 点关键技术问题.
(1) 弱监督条件下的标签数据依赖(dependency of labeled data)问题.传统机器学习模型需要大量的标签数据支持,而数据标注费用高昂,对于特定任务构建大规模高质量标注数据非常困难.因此,情感迁移建模中弱监督条件下的标注数据依赖是一大重要挑战;
(2) 目标领域缺乏高质量标签数据(lack of comprehensive data annotation)问题.即使在特定任务/领域下训练好的模型也往往存在可扩展性差的问题,当目标领域缺乏高质量标签数据时,如何建模情感迁移是一个重要挑战;
(3) 不同领域情感分布的差异鸿沟(distribution gap)问题.文本中情感的表达具有领域依赖性,这导致了不同领域的情感分布差异是非常明显的,在源领域训练的模型很难直接应用于目标领域中,需要执行特定的情感迁移策略;
(4) 数据来源具有多源性(multi-source domains)问题.社会媒体的主观性文本可以属于不同主题的领域,在面对特定目标领域的情感分类任务时,可能有多个源领域的带标签数据进行训练,而多个源领域的情感分布与目标领域是不同的,需要有效融合多个源领域的情感信息.
1.4 研究思路
针对以上技术问题,跨领域文本情感分类研究主要解决以下3 个问题:(1) 克服领域间情感分布差异,利用源领域的带标签情感数据实现不同领域的情感知识迁移;(2) 目标领域可能有少量带标签数据(但不足以训练一个有效的分类模型),如何有效避免过拟合问题;(3) 并非所有的源领域数据对于目标领域分类均有积极作用,如何选择合适的源领域数据避免所谓的负迁移(negative transfer)现象[67].
认知科学的研究表明:人类大脑能够借鉴地处理不同领域的任务,并能很自然地从一项技能迁移到另一项技能中.关于如何模拟人类大脑的认知过程解决现有的跨领域文本情感分类问题,研究者多采用迁移学习(transfer learning)或领域适应(domain adaptation)的方法[68,73].情感迁移学习是指迁移源领域的情感信息和模型到新的目标领域.而领域适应是指从一个或者多个源领域中获取知识和经验,适应到与源领域分布不同的目标领域的过程[69].
尽管不同领域之间存在分布差异,不同领域的情感知识仍然是可迁移的.主要原因有两个:(1) 大多数单词或短语在所有领域和任务中表达相似的情感极性,这表明不同领域的情感分类任务可以共享多个领域通用的情感特征;(2) 不同任务和领域中情感的表达方式是非常相似的,用户往往遵循相似的句法结构和语法规则.
关于跨领域文本情感分类,最早可追溯到2005 年Anthony 等人[17]在目标领域缺少大量带标签数据的情况下提出了4 种研究策略,将在源领域训练的情感分类器适应到新领域中.按照不同的角度,我们可以对已有的工作进行分类,主要的角度有3 个,分别是按照目标领域中是否有带标签的数据、不同的情感适应性策略和可用源领域的个数等.本文将在第2 节按照这3 个角度对已有的跨领域文本情感分类工作进行总结.随着深度迁移学习方法的兴起,本文在第3 节对其在跨领域文本情感分类中的应用进行了重点介绍.
1.5 研究意义
综上所述,跨领域文本情感分类利用已有的源领域标注数据辅助目标领域的文本情感分类任务,不仅可以减少新领域数据标注工作量,而且可以显著提高源领域标注资源的利用率,是很多机器学习和自然语言处理专家关注和研究的课题之一.情感迁移学习将在大规模数据环境下学习到的情感知识迁移到特定的小众领域,可以拓展情感语义分析的应用场景,有效解决特定领域数据标记不足问题,还可以为社会媒体情感分析提供新的研究思路,实现对蕴含于主观性文本中情感的全面和深层次理解.
2 跨领域文本情感分类方法
如前所述,迁移学习或者领域适应的方法是实现情感迁移的主要方法,而目标领域分类预测的有效性很大程度上取决于源领域与目标领域之间的相关性程度以及所采用的迁移算法.已有的跨领域情感分类问题的主要解决思路有:
(1) 按照目标领域中是否有带标记的数据(whether there is labeled data in the target domain),可以分为直推式和归纳式的跨领域情感分类方法:在归纳式条件下,目标领域有少量的带标签数据,但是数量不足以训练一个好的情感分类器;在直推式的情况下,目标领域中没有任何带标签数据,相比较归纳式的情况更有挑战性;
(2) 根据不同的情感迁移策略(sentiment transfer strategies),可以分为实例迁移方法、特征迁移方法、模型迁移方法、基于词典的方法、联合情感主题方法和基于图模型方法等;
(3) 根据可用的源领域个数(available number of source domains),可以分为单源领域和多源领域的跨领域情感分类方法.
不同视角的跨领域文本情感分类代表性方法如图1 所示.不同年度的跨领域文本情感分类代表性方法如图2 所示.

Fig.1 Cross-domain text sentiment classification methods from different perspectives图1 不同视角的跨领域文本情感分类方法

Fig.2 Timeline of cross-domain text sentiment classification methods图2 不同年度的跨领域文本情感分类代表性方法
2.1 直推式和归纳式的跨领域情感分类方法
根据目标领域有无可用的带标签数据,跨领域文本情感分类可以分为直推式的情感迁移方法(transductive sentiment transfer method)和归纳式的情感迁移方法(inductive sentiment transfer method),两种方法的流程如图3所示.
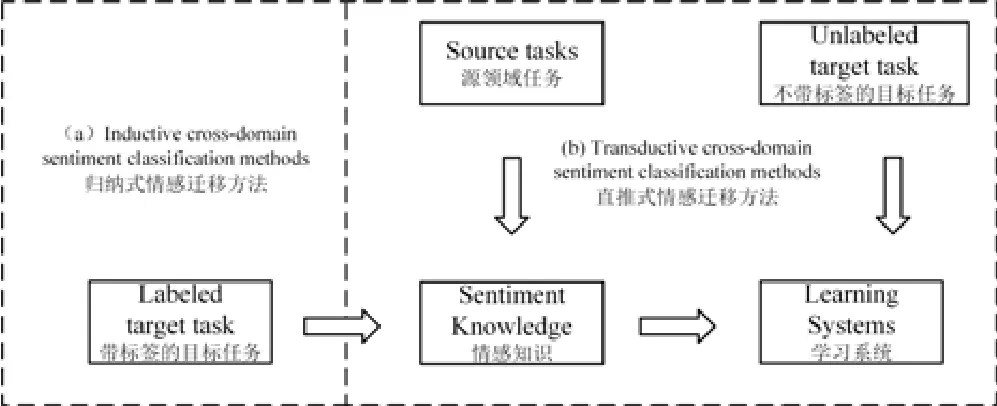
Fig.3 Schematic diagram of transductive and inductive cross-domain sentiment classification processes图3 直推式和归纳式的跨领域文本情感分类流程示意图
2.1.1 直推式情感迁移方法(transductive sentiment transfer method)
如图3 所示:在目标领域没有任何带标签数据的情况下,直推式情感迁移方法使用来自源领域的带标签样本训练情感分类器,然后迁移此情感分类器到另一个不同的目标领域中.例如,2005 年,Anthony 等人[17]提出了4种适应情感分类器到新领域(目标领域)的策略,发现Naïve Bayes-EM 算法能够充分利用目标领域不带标签数据取得了最好的结果.杨文让等人[26]选择高可信度的目标领域文本加入到训练集中,同时去除源领域距离“质心”较远的文本,通过此过程,有效减少了领域分布差异,在Amazon 产品评论数据集上达到了74.6%的平均准确率.为解决在没有目标领域数据的辅助下构建高效分类器问题,Matthew 等人[78]结合领域词典之间余弦相似度适应性形式用于新的目标领域有效模型构建.吴琼等人[70]首先根据源领域带标签数据对目标领域进行分类,将得到的高置信度文本作为“源点”和“汇点”,再根据物理学热传导模型得到目标领域不带标签样本最终的情感分.实验结果表明,该方法在书籍、酒店和电脑评论数据集上实现了71.5%的平均分类准确率.
2.1.2 归纳式情感迁移方法(inductive sentiment transfer method)
文本情感分类是一个领域依赖问题,然而许多领域中仅有少量的带标签数据不足以支持训练有效的情感分类模型.如图3 所示:与直推式的情况不同,在归纳式的条件下,源领域中有大量的带标签数据,目标领域中有少量的带标签数据.在此条件下,跨领域文本情感分类的目标是在源领域和目标领域的带标签数据的共同帮助下训练跨领域情感分类器.例如,赵传君等人[2]提出了一种基于分组提升集成的跨领域情感分类方法.为了更有效地利用目标领域的带标签数据,目标领域文本初始标签算法(initial data labeling algorithm)首先利用少量人工标注的目标领域数据,基于合成过抽样技术产生一定量的虚拟数据,得到新的数据集.在此基础上,采用自适应提升(Boot Strapping)方法获得目标领域更多的高可信度的带标签数据.再将源领域数据等量分割与目标领域数据组合,在每个组合块上进行适应性提升.最后将得到的多个分类器进行线性集成,得到目标领域上的分类器,在Amazon 产品评论数据集上实现了79.3%的平均准确率.此外,Deshmukh 等人[25]首先抽取和分类源领域的观点词,使用目标领域带标签数据联合二部图聚类和改进的最大熵模型预测目标领域的观点词,在Amazon 产品评论数据集上实现了80.69%的平均准确率.
2.2 跨领域情感迁移的不同策略
2.2.1 实例迁移方法(instance transferring based method)
由于领域间的情感分布差异,在源领域中,只有部分训练数据对于目标领域是有用的.实例迁移方法的思路是:根据对于目标领域的重要性,对源领域数据进行加权适应,用于训练目标领域的情感分类模型.其中,权重选择与相似度度量往往依赖经验知识.
例如,Robert 等人[61]提出了一种从源领域训练集中选择与目标领域最相似的样本的领域自适应方法,并在半监督跨领域文本层次情感分类实验评估了此方法.领域Di和Dj的JS(Jensen-Shannon)散度由Kullback-Leibler距离得到,见公式(1)和公式(2):

在此方法中,初始的源领域训练集大小由源领域和目标领域的领域相似度和领域复杂性自动确定.他们在Multi-domain sentiment dataset v2.0 数据集上取得了73.4%的平均准确率.
Xia 等人[28]提出了一种基于特征集成和样本集成的联合迁移策略.他们首先使用特征集成策略学习一个新的标记函数重新计算新的特征,使用基于PCA 的特征选择方法进行实例适应,在Amazon4 种产品评论数据集实现了77.5%的平均准确率.Xia 等人[29]还提出了基于PU 学习的实例选择和实例权重方法.PU 学习首先学习一个目标领域的选择器,高概率值的样本被选作训练数据.校准后的目标领域权重被用作样本权重训练一个基于最大加权似然朴素贝叶斯模型.在Movie 领域迁移到Multi-domain sentiment datasets 数据集达到了77.1%的平均准确率,在Video 数据集迁移到12 个评论数据集取得了79.9%的平均准确率.为了选择对于目标领域合适的源节点,Lin 等人[30]提出了一种基于树的回归模型,该模型使用树结构化的领域表示,联合了领域相似性和领域复杂度,预测从多个源节点到目标节点的准确性损失,在Amazon Electronics,Books 和Kitchen 数据集上实现了77.37%的平均迁移准确率.Domeniconi 等人[31]通过马尔可夫模型结合迁移学习和情感分类任务,使用极性依赖的词进行分类取得了很好的结果,在Amazon4 种产品评论数据集上达到了75.88%的准确率.
2.2.2 特征迁移方法(feature transferring based method)
情感在不同的领域中被不同的特征词表达,在源领域出现的情感词可能不会出现目标领域中,因此特征的分布差异阻碍了跨领域的情感迁移.特征迁移方法主要是基于特征映射的方法,旨在发现领域特定特征和领域共享特征之间的关联.在执行领域适应之前,一个重要的预处理步骤是选择领域共享(枢纽)特征的集合.已有的跨领域情感分类实验表明,适应性的特征表示对于减少领域之间的差异是非常有效的.
例如,Blitzer 等人[79]使用源领域和目标领域不带标签的数据学习跨领域共享特征表示,提出了一种结构一致化学习(structural correspondence learning,简称SCL)方法.领域共享(枢纽)特征被定义为有较高互信息的极性特征,SCL 的核心思想是:通过建立领域特定特征和共享特征的相关性,识别来自不同领域的特征相关性,使用领域共享表示训练的判别式模型可以更好地推广到目标领域.Yftah 等人[62]结合结构一致化学习和神经网络模型,首先学习输入样本领域共享特征的低维表示,再将低维表示用于学习此任务的学习算法.通过引入预训练的词向量到模型中,利用相似的共享特征提高跨领域的泛化能力.魏现辉等人[68]改进传统的SimRank 算法,以领域间的共享特征作为桥梁构建潜在的特征空间,将源领域和目标领域的样本映射到潜在的特征空间中,有效减少了源领域和目标领域之间的分布差异.张博等人[32]结合传统的典型相关性分析和特征迁移学习策略,分析领域特定特征和共享特征之间的关联,并选择合适的基向量训练线性分类器.张玉红等人[33]根据词频和对数似然比信息挖掘在源领域带情感极性,且在目标领域判别性较高的特征,构建了不同领域之间的共享特征空间.
在领域共享(枢纽)特征(pivot features)作为桥梁的帮助下,Pan 等人[24]提出一种谱特征对齐(spectral feature alignment,简称SFA)算法对齐来自不同领域的领域特定特征.特征和领域之间的互信息建模见公式(3):
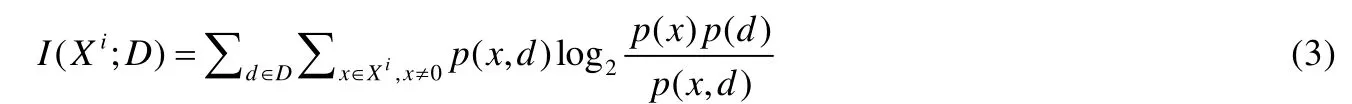
在此方法下,聚集的簇可以减少两个领域的领域特定词的差异,用于训练目标领域的精确分类器.在Amazon 4 种领域评论数据集和SentDat 数据集上分别达到了77.71%和75.41%的平均准确率.
类似地,Wang 等人[74]创造了情感相关索引(sentiment related index)衡量特定领域中不同的词汇元素之间的关联,并提出了一种基于情感相关索引的跨领域情感分类算法,在RewData 数据集(Computer,Education 和Hotel)和DoubanData 数据集(Movie,Music 和Book)上达到了82.3%的平均准确率.Wei 等人[34]提出了跨领域语义相关自动对应方法,捕捉来自不同领域的相似语义特征.抽取源领域和目标领域共同的前N个共享特征,构建表达相似特征对并转换为相似的情感特征表示,有效减少了领域情感差异性.Tareq 等人[80]使用条件概率联合关联度量源领域和目标领域的迁移特征,利用朴素贝叶斯模型和3 种特征选择方法(信息熵、比值比和卡方检验)应用到跨领域情感分类任务中.Zhang 等人[75]提出了一种基于迁移学习的非负矩阵分解策略,用相似的特征簇迁移知识,通过连接相似的特征簇进行情感分类.在相似的词聚类矩阵和相似的约束加入到知识迁移函数中,可以应用到跨语言和跨领域情感分类任务中.Zhang 等人[58]迁移源领域特征的极性到目标领域,使用领域共享的特征作为桥梁.
2.2.3 模型迁移方法(model/parameter transferring based method)
基于模型或参数迁移的跨领域情感分类研究假设相关的文本情感分类任务的模型共享部分参数或超参数的先验分布.已有的方法致力于利用源领域的模型提升目标领域的表现,主要解决两个问题:(1) 共享模型中的哪些参数;(2) 如何共享参数,即选用何种方法实现模型参数的迁移.
例如,Bollegal 等人[23]将跨领域情感分类看作是嵌入式学习任务,构造了3 种目标函数,分别是共同特征的分布式属性、源领域文本的标签约束信息、源领域和目标领域不带标记样本的几何特性.为解决一个领域训练的分类器在不同的领域表现不好的问题,尤其是带标记数据的分布和不带标记数据的分布不一致的时候,Zhu等人[81]使用神经网络上的特征对齐(feature alignment)方法用于跨领域情感分类任务,使用了基于SVD 分解的方法,见公式(4):

其中,Mm×n为文本矩阵,U和V为正交矩阵,Σm×n为对角矩阵.通过分解,可以有效地过滤掉噪声特征.
Li 等人[35]针对跨领域文本情感分类问题提出了一种端到端的对抗记忆网络框架,包括两种参数共享记忆网络,分别是是情感分类和领域分类.通过联合训练这两种网络,使得选择的特征能够最小化情感分类错误率,同时获得源领域和目标领域的表示.为解决情感分类的领域适应性问题,Bach 等人[36]提出了利用通用方法进行特征学习和特征子空间映射,并将词嵌入和典型相关性分析应用到在跨领域情感分类任务.Glorot 等人[37]提出了一种深度学习策略,解决情感分类器的领域适应性问题.通过用一种堆叠去燥自编码(stacked denoising autoencoders)获得每篇评论的有意义的表示,在Amazon 4 种类型的产品评论实验表明,用高层次特征训练的情感分类器要好于基准方法.借鉴结构一致化学习策略,Yu 等人[82]用神经网络架构研究跨领域的情感分类问题,利用两个辅助的任务提升句子嵌入在跨领域情感分类上的表现,联合学习句子嵌入和情感分类器的方法,在英文电影、相机、笔记本电脑和餐馆数据集上达到了79.6%平均准确率.
2.2.4 基于词典的方法(lexicon based method)
已有的研究积累了大量的情感词典资源,基于词典的方法利用领域通用的情感词典知识和领域特定的语料生成领域特定的情感词典,以此解决跨领域的文本情感分类问题.例如,Mao 等人[83]提出了一种联合情感词典和机器学习的跨领域中文产品评论情感分类方法.首先适应领域通用的词典到书籍、酒店和电子产品领域中,然后根据情感词、N元语法、统计信息和基于词典方法的结果共16 个特征构建分类器.通过使用不同的词典和分类器评估提出的方法,在中文Hotel,Electronics 和Book 数据集上实现了86.8%的平均准确率.
Dolores 等人[84]针对西班牙语酒店领域开发了一种无监督极性分类系统,引入领域独立的词典为SOL 和iSOL,旅游词典为加入领域知识的eSOLHotel,并在酒店领域评估了这3 个情感词典的分类表现.Bollegala 等人[21]使用源领域的标记数据、源领域和目标领域未标记的数据创建一个情感敏感的分布式同义词库,给出特征ui和文档d的排序分score(ui,d),见公式(5):

他们使用同义词库的扩展特征在分类器上进行训练和测试,并在单源和多源领域、有监督和无监督的领域适应和各种相似度度量方法进行了实验验证,在Amazon 4 种领域数据集上达到81.91%的平均准确率.
Rishabh 等人[38]使用多领域的不带标签的评论和K-SVD 算法学习到一个基于稀疏表示的词典,从而实现自学习的目标.给定一组样例集Y,K-SVD 的目标是找到一个词典D和一个系数矩阵X,最小化表示误差:

其中,γi表示矩阵X的某一行,为表示非0 的个数.此方法在Amazon 4 种领域评论数据集实现了81.25%的平均准确率.
类似地,Li 等人[39]从烂番茄(rotten tomatoes)网站和IMDB 论坛带星级的电影评论中学习语言表示和能够表达评论观点的情感词,提出了一种新的情感迁移机制:通过在源领域和目标领域的词-文本矩阵进行受约束的非负矩阵分解,成功地迁移这些知识到目标领域中.
2.2.5 联合情感主题方法(sentiment-topic joint based method)
主题模型(topic model)是以非监督学习的方式对文集的隐含语义结构(latent semantic structure)进行聚类(clustering)的统计模型[85],主题模型被用于自然语言处理中的语义分析(semantic analysis)和文本挖掘(text mining)问题,例如按主题对文本进行收集、分类和降维等[86].联合情感主题的方法假设源领域和目标领域共享某些特定的主题,这些主题可以作为连接不同领域之间的桥梁.例如,产品评论的各个领域中往往都有“价格”(price)属性,电子产品评论中都有“屏幕(screen)”和“电池(battery)”等属性.
He 等人[87]通过改进主题依赖联合模型抽取极性依赖的主题,将这些主题加入到初始的特征空间中,利用扩展的特征和信息增益标准进行特征选择,在跨领域情感分类任务上取得了很好的效果,此方法简单且不需要困难的参数调试过程.相比较领域内(in-domain)测试的结果,他们提出的Joint sentiment-topic(JST)模型在IMDB 的电影数据集和Amazon 4 种领域评论数据集达到了平均4.1%的平均适应性损失.为了搭建领域间的桥梁,Zhou等人[40]提出了主题一致性迁移(topical correspondence transfer)算法.每篇文本被表示为词-文本矩阵的形式,包含了领域特定主题和领域共享主题.共有的主题的一致性可以作为桥梁减少领域之间的差异性,在Amazon 4 种领域评论数据集上达到了79.43%的平均准确率.Yang 等人[12]提出了一种Link-Bridged 主题模型,利用辅助连接网络发现文本之间直接或者间接的共引关系,挖掘出的共引关系可以作为不同领域的连接桥梁.Suman 等人[88]针对社交流媒体和传统媒体领域之间的实时迁移学习,提出了一种可扩展的SocialTransfer 模型.使用在线流LDA 模型学习社交流媒体的主题,利用来自于社交媒体和视频领域抽取的主题构建起中介主题空间.再使用谱学习(spectral learning)的方法学习跨领域的共享特征表示,最后通过更新迁移拉普拉斯矩阵(laplacian matrix)得到主题.源领域为10.2 million Twitter 数据,目标领域为5.7 million YouTube 数据,在YouTube 的7 个领域上,实现了75.5%的评论准确率.
Huang 等人[41]提出了一种主题相关适应性提升(topic-related trAdaBoost)跨领域情感分类框架.他们认为:主题分布捕捉文档的领域信息,对于跨领域情感分类是有价值的.实验结果表明:TR-TrAdaBoost 表示的文档提升跨领域的表现和鲁棒性,在Amazon 4 个领域评论数据集上达到了76.0%的平均准确率.张慧等人[73]根据4 种评价对象:整体、硬件、软件和服务,每种评价对象构建独立的分类器,每个评价对象看作是一个独立的视图,使用协同学习(collaborative learning)的方法进行跨领域情感分类任务,在中文4 个领域(酒店(hotel)、笔记本(notebook)、家具(furniture)、数码相机(digital camera))数据集上迁移到Hotel 和Notebook 领域达到了75.0%和59.0%的F值.
2.2.6 基于图模型的方法(graph based method)
基于图的算法被广泛应用于半监督和跨领域的研究问题中,对于解决数据受限问题非常有效.基于图模型的跨领域情感分类方法通过构建不同领域之间的情感传播图,实现源领域到目标领域的情感传递.在情感传播图中,节点为情感特征或者文档,边为他们之间的语义关系.节点之间的相似度越大,则具有较高的情感相似度;反之则越低.
例如,Arun 等人[89]提出了一种基于图的迁移学习研究,使用用户-文本-特征的三部图从带标签的样本、用户和关键词特征到不带标记样本中传播情感信息,通过排除一致的用户在不同的领域间具有不一致的行为解决“负迁移”问题.吴琼等人[69]将源领域和目标领域中文本和词的4 种关系纳入到随机游走模型中,待算法收敛时得到文本稳定的情感分,以此判断目标领域文本最终的情感倾向.此外,Wu 等人[71]将图排序算法应用到跨领域情感分类中,将源领域的精确标签和目标领域的伪标签进行迭代,最终得到测试文本的精确情感分,情感分的计算见公式(8):

其中,i=1,2,…,n,α+β=1,为归一化的相似度,为情感分,为行归一化后的邻接矩阵.
Giacomo 等人[42]提出了一种基于马尔可夫链理论的跨领域情感分类方法.基本的思想是对词在语料中的语义分布信息进行建模,首先将文档语料表示为图,每个不同的词为一个结点,不同的共现词之间有一个连接.构建马尔可夫转移矩阵,其中,状态表示词或者类别,从源领域的领域特定词到目标领域特定词之间迁移学习.在Amazon 4 种领域评论数据集上实,现了77.75%的平均准确率.
Wu 等人[72]通过充分融合文本和词的4 种关系,在不同的领域中迁移情感信息,提出了一种迭代的增强学习研究.文本(词)的情感分由它相互关联的文本和词决定,更新后的文本(词)的情感分同样也会影响和它相互关联的文本和词.在Book,Hotel 和Notebook 数据集实现了75.2%的平均准确率.Natalia 等人[43]将基于图的标签传播算法(label propagation algorithm)应用到情感分类任务中.他们研究了修改的图结构和参数变化,比较了基于图的算法在跨领域和半监督的情况下的表现,在Amazon 4 种领域数据集上达到了78.4%的平均准确率.
2.3 多源跨领域文本情感分类方法(multi-source cross-domain sentiment classification)
以上方法仅从单个源领域迁移情感信息,当源领域和目标领域的特征分布有显著不同时,适应性表现会显著下降[89].在存在多个源领域数据集的前提下,多源迁移学习方法提取的迁移知识已不再局限于单个源领域,而是来自于多个源领域[59].大部分多源跨领域情感分类研究主要专注于目标领域数据样本稀缺问题和如何利用多个源领域数据,多采用基于实例迁移或者参数迁移的方法.
从实例迁移的角度看,Xu 等人[90]提出了一种多视角适应性提升(multi-view adaboost)多源领域迁移学习算法.他们认为:所有的源领域和目标领域任务是成分视角,每个任务可以从不同的视角下学习.此方法不仅利用了多个源领域的带标签数据帮助目标任务学习,而且同步地考虑如何在不同视角下的迁移.Fang 等人[91]通过抽取在多个源领域标签的共享子空间,提出一种多标签共享子空间的多领域迁移学习方法.此方法转换目标领域的样本到多标签样本,能够分析预测标签和多个源领域的关系.Sun 等人[44]提出了一种二阶段领域适应性方法(MDA),能够从多个源领域中联合加权数据:第1 阶段为边际概率差异,第2 阶段为条件概率差异.最小化条件概率的权重由同时计算多个源领域之间的潜在的交互作用,在Amazon 4 种领域评论数据集上实现了60.14%的平均准确率.Hu 等人[45]提出了一种基于类分布的多源领域适应性算法(MACD),类分布信息被用于从所有的源领域中选择一些适应性基分类器,选择的“自标签”样本根据源领域和目标领域的相似度被动态地加入到训练数据中.最终使用类分布信息构建集成分类器,在Amazon 4 种领域评论数据集上实现了79.75%的平均准确率.Li等人[46]在多个源领域适应到一个特定领域的情况下,提出了一种多标签一致训练框架.首先在多个领域的带标签数据上使用不同的学习算法、训练数据和特征集训练基分类器,各种不同的规则联合基分类器构建多分类器系统框架,在Amazon 4 种领域评论数据集上达到了80.1%的准确率.
从参数迁移的角度看,Tan 等人[92]定义了多视角和多源领域的迁移学习,提出一种新算法协同利用不同视角和源领域的知识,通过不同源领域互相协同训练的方法,可以弥补不同领域之间的分布差异.Zhuang 等人[47]提出了一种多个源领域的迁移学习框架(CRA),在此框架中,利用自编码器构造从初始的样本到隐含表示的特征映射,从源领域的数据中训练多个分类器,通过执行基于熵一致正则化矩阵完成目标领域样本的预测.Wu 等人[48]在从不带标签的目标领域数据中词的情感极性关系的帮助下,提出了一种基于情感图的领域相似性度量方法,相似的领域通常会共享共同的情感词和情感词对,在Amazon 4 种领域评论数据集上实现了81.97%的平均准确率.Yoshida 等人[93]提出了一种贝叶斯概率模型处理多个源领域和多个目标领域的情况.在此模型中,每个词有3 个要素:领域标签、领域共享/特定、词的极性.从带标签和不带标签的文本中使用Gibbs 采样推断模型的参数,同时能表明每个词的极性是领域特定还是领域共享的.他们抽取出的领域共享词有:正面great,good,best,excellent;负面bad,instead,actually,wrong;中性quite,long,right away.Electronics 领域的领域特定词为small,light,soft,Kitchen 领域的领域特定词为stainless,sturdy,fresh,healthy.赵传君等人[94]从参数迁移和集成学习的角度,提出了一种基于集成深度迁移学习的多源跨领域文本情感分类方法,通过迁移学习实现源领域到目标领域的模型迁移,最终通过集成学习方法联合各基分类器输出.
2.4 不同策略的情感迁移方法性能比较(comparison of different sentiment transfer strategies)
我们对传统的领域适应综述中的代表性方法在亚马逊英文DVDs,Books,Electronics 和Kitchen 等4 个领域的在线评论语料的结果进行了展示,见表3.
由表3 可以发现:相比较6 种单源跨领域文本情感分类方法,多源领域条件下的实例迁移和参数迁移方法均取得了较好的结果.这表明在多个源领域的条件下,充分利用多个源领域的数据,可以有效提高跨领域情感分类的准确率.多源领域优势在于可以利用多个源领域的信息训练更鲁棒的模型,难点在于如何选择合适的源领域和如何融合多个多领域的情感信息.
在跨领域文本情感分类研究初期,研究者多采用实例迁移和特征迁移的方法,这两种方法较为直观,具备良好的可解释性.其中:实例迁移方法具有良好的理论支撑,有清晰的泛化误差上界,但是此类方法在不同领域间差异较大时效果往往并不理想;特征迁移方法寻求领域通用情感特征,将源领域和目标领域的数据特征映射到统一的特征空间,可以有效减少不同领域表示上的差距.模型迁移要求不同领域训练的模型尽可能接近,由于深度迁移方法的兴起,大多数模型迁移的方法结合深度神经网络模型,也是绝大多数跨领域情感分类研究工作的热点.在6 种方法中,基于词典的方法取得了较好的结果,但是依赖于已有的情感词典资源和人工劳动.联合情感主题和基于图模型的方法结合了传统的主题模型和图模型方法,也是解决跨领域文本情感分类的重要方法.

Table 3 Different sentiment transfer strategies,methods and classification effects表3 不同情感迁移策略、方法及其分类效果
3 深度迁移学习及其在跨领域情感分类中的应用
3.1 深度迁移学习(deep transfer learning)
深度学习模型通常是带有很多隐藏层和参数的神经网络,所以需要大量训练数据才能取得好的结果,否则非常容易过拟合[33].然而,标注特定领域的大规模数据是非常困难的.近年来,迁移学习中的子领域深度迁移学习受到了广泛关注和研究,特别是在图像识别、自然语言处理等领域取得了很大成功[95].深度迁移学习通过共享源领域和目标领域的模型结构和部分参数,将源领域中学到的特征表示迁移到目标领域中,以此利用深度神经网络的可迁移性,提高目标领域的任务表现.深度迁移学习可以放松领域独立同分布的假设,有效减少目标领域训练数据的规模,还可以有效避免过度拟合现象.
已有的深度神经网络实验表明,较浅的层往往学到的是领域通用特征.随着网络层数的逐渐加深,特征逐渐领域特定化,可迁移性也随之降低.在网络更高层次上计算的特征很大程度上依赖于特定的数据集和任务[98].深度迁移学习模型的迁移能力主要受到两个因素的影响:(1) 深度模型在越深的层,其领域相关性越强,即只能完成领域特定的任务,而较浅的层可迁移性越高;(2) 模型在优化过程中,层与层之间参数的优化具有关联性.因此在模型迁移时,需要固定浅层网络的结构和参数,重新训练高层参数,可以提高模型泛化性.
微调策略(fine-tuning)是一种有效的深度迁移学习技术[32].在深度迁移学习的背景下,对预训练的源领域深度神经网络进行微调是学习特定任务常用的策略.微调策略的步骤主要有:首先训练源领域深度神经网络,将它的前N层复制到目标网络的前N层,目标网络的剩下的其他层则随机进行初始化.在使用目标领域训练数据进行误差反向传播训练神经网络的时候有两种策略:(1) 固定源领域迁移过来的模型和参数,即在训练目标任务时保持改变;(2) 执行微调策略,即在训练过程中可以不断调整其参数权重.
下面给出深度迁移学习的形式化定义:给定源领域DS和源任务TS,目标领域DT和目标任务TT,深度迁移学习致力于使用DS和TS中的知识,帮助提高DT中预测深度神经网络函数fT(·)的学习.其中,D={X,P(X)},DS≠DT意味着源领域和目标领域实例不同XS≠XT,或者源领域和目标领域边缘概率分布不同PS(X)≠PT(X).同理,T={Y,P(Y|X)},TS≠TT意味着源领域和目标领域标签不同(YS≠YT),或者源领域和目标领域条件概率分布不同(P(YS|XS)≠P(YT|XT)).
3.2 深度迁移学习在跨领域情感分类中的应用
在文本特性社会媒体的跨领域情感分类任务中,需要深入理解语言表达的机理和情感迁移的机制.构建大规模、高质量的带标注数据集非常困难,而深度迁移学习可以显著降低目标领域对带标签数据的需求,因此深度迁移学习被广泛应用于跨领域情感分类任务.作为解决跨领域文本情感分类问题的新途径和有效手段,深度迁移学习方法主要分为两个步骤:首先,选取合适的深度情感语义组合方法;然后选择合适的深度迁移学习算法,有效地迁移相关的情感知识.
我们沿用Tan 等人在文献[95]中对深度迁移学习的分类方法,将深度迁移学习分为4 类:基于实例的深度迁移学习、基于映射的深度迁移学习、基于网络的深度迁移学习和基于对抗的深度迁移学习.我们从以上4 个角度对跨领域文本情感分类工作进行总结.
3.2.1 基于实例的深度迁移学习方法(instance-based deep transfer learning method)
类似于传统的基于实例的情感迁移策略,基于实例的深度迁移学习在解决跨领域情感分类任务时,往往根据目标领域的数据分布对源领域的样本进行加权权重适应,选择部分高置信度样本加入到目标领域训练集中.例如,Dong 等人[96]通过引入有监督额外数据的情感嵌入,将通用的线索加入到网络的训练过程中.然后通过基于专用存储器的组件将其馈送到模型中,在给定有限训练数据的前提下可以有更泛化的能力.提出的模型在Stanford sentiment treebank(SST)数据集上,在20%,50%和100%训练数据集的条件下,分别达到了85.06%,86.16%和86.99%的情感分类准确率.
Sharma 等人[49]使用跨领域不改变其极性和显著性表示的可迁移信息,用于跨领域文本情感分类任务.具体地,他们提出了一种基于χ2检验和单词上下文向量之间的余弦相似性新方法,识别跨领域保留重要单词的极性.其中,χ2测试计算如公式(9)所示:
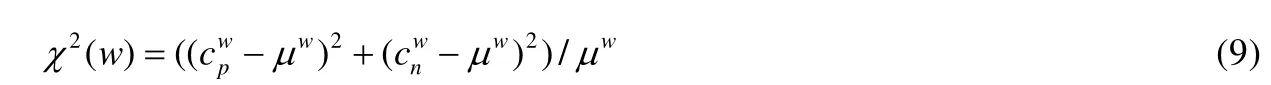
其中,为词w在正面文档中的出现次数,为负面文章中的出现次数,μw为在正面和负面文档中出现的平均次数.
Cui 等人[97]对仅适用于源领域标记数据以及未标记数据的不同策略进行了比较研究,选择无监督域适应(unsupervised domain adaptation,简称UDA)的领域共享特征执行跨领域文本情感分类任务.Khan 等人[66]将余弦相似性度量应用于SentiWordNet 计算特征权重并生成修订的情感分数,模型学习由支持向量机使用两个实验设置执行,即单个源和多个目标域以及多个源和单个目标域.在9 个标准数据集上实现了85.05%的准确率.Cummins 等人[98]通过提供额外的数据集,利用不同的词袋模型辅助情感检测.实验结果表明,使用包含来自测试域和领域外数据集的信息的Bag-of-words 提取范例可以获得系统性能的提升.源领域数据来自于包含237 clips的Music Review Dataset,目标领域为包含359 个YouTube 视频的Movie Review Dataset,在发展集上达到了80.7%的平均准确率,在测试集上达到了79.8%的平均准确率.
3.2.2 基于映射的深度迁移学习方法(mapping-based deep transfer learning method)
基于映射的深度迁移学习主要基于以下假设:尽管源领域和目标领域之间在原始的特征空间中存在分布差异,在源领域和目标领域映射到新的特征空间后可能有相似的分布.度量不同领域距离的比较流行的方法是最大均值差异(maximum mean discrepancies,简称MMD)方法及其变体方法.MMD 方法是Borgwardt 等人[99]提出的一种边际分布自适应方法(marginal distribution adaption,简称MDA).MMD 将源领域和目标领域的分布映射到再生核希尔伯特空间(reproducing kernel Hilbert space,简称RKHS)中,目的是减少源领域和目标领域的边际分布距离.Duan 等人[100]提出了使用多核MMD 方法和一种新的求解策略,提出了领域迁移多核学习方法(domain transfer multiple kernel learning,简称DTMKL).He 等人[63]通过最小化嵌入特征空间中源领域实例和目标领域实例之间的距离,提出了一种领域自适应半监督学习框架(domain adaptive semi-supervised learning framework,简称DAS).Sarma 等人[101]提出了一种将通用嵌入广度与领域特定嵌入的特异性相结合的方法,领域适应的词嵌入(Domain adapted word embeddings)由对齐相关的词向量使用典型性相关分析(Canonical correlation analysis)或者非线性核典型性相关分析得到.
Shi 等人[51]提出了一种学习领域敏感和情感嵌入的新方法,该方法同时捕获情感语义信息和单个单词的领域敏感性,可以自动确定和生成领域通用嵌入和特定领域的嵌入.基于HL 和MPQA 情感词典在Amazon 4 种领域评论数据集上达到了81.0%和79.8%的平均准确率.
Wang 等人[76]提出了一种用于跨领域情感分类的软组合迁移学习算法,将两个非负矩阵三因子分解集成到一个联合优化框架中.对词簇矩阵和簇关联矩阵近似约束,从而使知识转移具有适当的多样性.在Amazon 多语言Books,DVD 和Music 这3 种产品评论数据集上实现了81.31%的平均准确率.
Jia 等人[55]提出了基于关联规则的词对齐(words alignment based on association rules,简称WAAR)方法.通过学习领域之间的强关联规则,可以在不同领域的领域特定词之间建立间接映射关系,在一定程度上减少源领域和目标领域之间的差异,并且可以训练更准确的跨领域分类器.单词作为领域共享特征的可能性的评估函数计算见公式(10):

Savitha 等人[102]提出了一种基于推文(Tweets)优化主题适应的词扩展模型(optimized topic adaptive word expansion,简称OTAWE).该算法从特定领域中选择更可靠的未标记推文,在共同的情感词和混合带标签的推文进行主题适应,并在每次迭代中更新领域自适应词.
Gupta 等人[103]利用了半监督和迁移学习方法提升低资源(low resource)情感分类任务的表现.该方法通过尝试提取密集特征表示和带流形正则化的模型预训练,可以显著提高情感分类系统的性能.提出的最优的分类器f*为
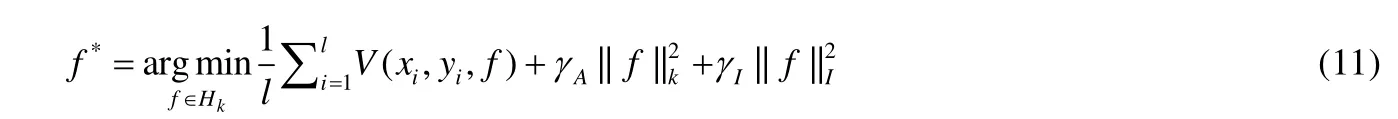
其中,Hk为再生核希尔伯特空间(reproducible kernel Hilbert space,简称RHKS),V为损失函数,为正则化损失,为额外的平滑损失控制,γA和γI为权重参数.
虽然相应的实例在原始特征空间中存在偏差,但可以映射到其他特征空间,对于源领域或者目标领域是无偏差的.基于以上假设,Zhou 等人[77]提出了一种混合迁移学习框架(hybrid heterogeneous transfer learning,简称HHTL),选择偏向于源领域或者目标领域的跨领域相应的实例,在英语数据作为源领域和目标领域时,达到了79.50%和78.46%的平均准确率.
3.2.3 基于网络的深度迁移学习方法(network-based deep transfer learning method)
基于网络的深度迁移学习方法往往首先使用源领域大量带标签样本预训练深度神经网络,然后将其网络结构和连接参数迁移到的新的目标领域中,再使用目标领域的少量带标签数据微调整个或者部分神经网络.例如,Zhao 等人[32]针对短文本跨领域文本情感分类任务提出了一种两阶段的双向长短时记忆模型和参数迁移框架,首先利用源领域带标签数据预训练双向LSTM 网络,通过使用少量的目标领域训练样本共享网络的底层参数和重新训练高层参数,在目标领域带标签数据上进行微调.在中文Hotel,Notebook,Weibo 和Electronic 数据集上实现了77.5%的平均准确率.
Manshu 等人[65]针对跨领域文本情感分类任务,提出了融合先验知识信息的分层注意网络(hierarchical attention network with prior knowledge information,简称HANP).HANP 具有注意机制的分层表示层,因此可以捕获与情感相关的重要单词和句子,在Amazon 5 个领域Books,DVD,Electronics,Kitchen 和Video 数据集上达到了87.76%的平均准确率.
为了有效地利用目标领域标记数据,Peng 等人[50]引入一些目标域标记数据学习特定领域的信息,分别同时提取领域特定和不变表示,使用源领域和目标领域标记数据训练基于领域不变表示的分类器,在Amazon 4 种领域评论数据集上达到了81.88%的平均准确率.
Yang 等人[64]提出了一种用于跨领域方面层次情感分类的注意力模型(neural attentive model for crossdomain aspect-level sentiment classification,简称NAACL),利用监督深度神经网络的优势以及无监督概率生成模型加强表征学习.
Zhang 等人[52]提出了一种交互式注意力转移网络(interactive attention transfer network,简称IATN)用于跨领域文本情感分类任务.IATN 提供了一种交互式注意力转移机制,通过整合句子和方面的信息,可以更好地迁移情感.主要包括两个关注网络,其中:一个是通过领域分类识别领域共同特征,另一个是通过使用共同特征作为桥梁从提取跨领域信息.生成注意力向量αi见公式(12):

Zhang 等人[54]引入了用于领域适应场景中情感分析的Capsule 网络,此网络利用胶囊网络对内在空间部分-整体关系进行编码,构成领域不变知识,作为源域领域和目标领域之间的桥梁.该方法还将语义规则纳入胶囊网络,以增强综合句子表示学习.在Amazon 4 种领域评论数据集上实现了88.6%的平均准确率.
Ji 等人[56]设计了一个Bifurcated-LSTM 网络,利用了基于注意力的LSTM、增强数据集和正交约束.该方法可以从源领域提取领域不变情感特征,在不同的目标领域中执行情感分析.在Amazon 的7 种领域的数据上达到了80.92%的跨领域情感分类平均准确率.
3.2.4 基于对抗的深度迁移学习方法(adversarial learning-based deep transfer learning method)
为了实现源领域到目标领域有效情感迁移,选取的特征应该为目标领域的情感分类任务有良好的辨识度,而对于源领域和目标领域之间不可区分.基于此,基于对抗的深度迁移学习方法引入生成对抗网络(generative adversarial networks,简称GAN)中的对抗技术,找到适合于源领域和目标领域的领域不变特征.
Zhang 等人[53]提出了分层注意力生成对抗网络(hierarchical attention generative adversarial networks,简称HAGAN).通过交替地训练一个生成器(generative model)和一个判别器(discriminative model)生成一个文档向量表示(document representation),它是情感可区分但是领域无法区分的.此外,HAGAN 模型应用双向门控循环单元(Bi-GRU)将单词和句子的上下文信息编码到文档表示中,在Amazon 4 种评论数据集上实现了81.56%的平均准确率.
Liu 等人[57]提出了一种基于模糊的领域对抗神经网络与自动编码器(fuzziness based domain-adversarial neural network with auto-encoder,简称Fuzzy-DAAE).主要包括:(a) 自编码,无监督的神经网络隐含表示用于重构初始化表示;(b) 领域分类器,即简单的逻辑斯蒂回归器(logistic regressor);(c) 情感分类器,拼接自编码的表示h1和领域分类器的隐含表示h1作为情感分类器的输入,最后是模糊情感分类器的输出.为了引入更多目标样本的监督信息,此模型根据其模糊性将未标记的目标样本及其预测标签添加到原始训练数据中,然后重新训练整个模型.
除了以上工作,Omar 等人[104]在目标领域中引入文本生成作为目标领域中的带标签数据集,并且比较了基于诸如LSTM,RNN 深度学习的文本生成和基于马尔可夫链(Markov chain)的文本生成,在Kitchen 作为目标领域数据集上达到了最高72.0%的准确率.此外,Cai 等人[105]使用去噪自动编码器提取具有鲁棒性的更深层共享特征,使用基于Wasserstein 距离的领域对抗和正交约束组合以更好地提取不同领域的深度共享特征,用于跨领域文本情感分类任务.
3.3 深度迁移学习方法效果比较(comparison of different deep transfer learning methods)
我们对深度迁移学习中的代表性方法在亚马逊英文DVDs,Books,Electronics 和Kitchen 这4 个领域的在线评论语料的结果进行了比较,分类效果见表4.

Table 4 Different sentiment transfer strategies,methods and classification effects表4 不同深度情感迁移方法及其分类效果
由表4 可以发现,基于深度迁移学习的跨领域文本情感分类方法在Amazon 经典数据集上均取得了较好的效果.可见,基于深度迁移学习的方法将是解决此问题以后的主流方法.相比较传统的情感迁移方法,基于深度迁移学习的方法可以实现端到端的跨领域情感迁移任务,具备更好的鲁棒性和泛化能力.对应不同的情感迁移策略,基于实例的深度迁移学习方法属于实例迁移方法的范畴,基于映射的方法属于特征迁移,基于网络和对抗的深度迁移学习方法属于模型迁移的范围.基于实例的方法通过对源领域样本加权训练,具备良好的可解释性.基于映射的方法通过学习领域通用的特征表示减少领域之间的偏差,最终减少学习误差,可以有效地提升网络性能.在4 种方法中,基于网络的方法取得了最好的效果,实现了最高88.6%的分类准确率.这说明在大规模的情感数据上预训练模型,迁移到特定的小众领域,可以有效地提升目标领域的情感分类表现.基于网络的方法通过预训练可以有效地节约时间成本,在精度上也有很大优势.基于对抗的方法结合生成对抗式网络模型,属于较新的方法,是未来的重点研究方向之一.
4 研究挑战及展望
尽管已有工作引入迁移学习或领域适应机制解决跨领域文本情感分类任务取得了很大地成功,但在很多重要的问题的研究上还不够完善和深入,从理论和技术上仍然有很多问题需要探索.本节分析了仍然存在的3点研究挑战,并指出了下一步可能的研究方向.
4.1 研究挑战
目前来说,跨领域文本情感分类的研究挑战主要列举如下.
(1) 由于不同领域间的分布差异,只有部分源领域的知识适合目标领域分类任务,若引入不相关的知识可能会导致负迁移,反而会降低目标领域情感分类的准确率,直接影响跨域学习的分类精度与效率.针对负迁移中的噪声样本和分类器问题,Xu 和Gui 等人[106,107]使用Rademacher 分布的总和来估计传输数据的类噪声率,针对一组由噪声数据的负面影响引起的弱分类器来学习基于训练误差和类噪声估计的整体强分类器.情感的“负迁移”是一个尚未得到完全解决的问题,选择更合适的领域和样本进行情感知识的迁移,才能避免情感的“负迁移”现象发生;
(2) 不同领域之间的相似度通常依赖经验进行衡量,缺乏统一有效的相似度度量方法.目前,跨领域文本情感分类仅局限于相似性较大的领域之间的迁移,如何实现相似性较低的领域之间或者源领域数据受限时的情感迁移,是一个值得注意的问题,需要选取更合适的情感领域距离度量准则;
(3) 现有的跨领域情感分类的方法往往只针对单语言和单模态(文本)之间的迁移,现实条件下往往存在多个语言以及多个图像、语音或者文本等多个模态的情感信息.然而不同语言和模态之间的特征空间是完全不同的,因此,如何实现异质空间任务的情感迁移,是下一步重点需要解决的问题.
4.2 未来研究方向
(1) 关注于情感迁移学习机制和情感内部表达机理的研究.情感迁移学习机制主要是寻求领域不变性因素作为跨领域迁移的桥梁,包括句子级情感注意力迁移和句法结构一致性学习等.另一方面,同时考虑边际分布和语义分布的距离度量方法,可以更好地选择源领域中对目标领域分类有利的训练样本;
(2) 关注于多个源领域条件下的跨领域情感分类研究.多源领域适应可以从多个源领域获取知识和经验,适应到与源领域分布不同的目标领域中.多个源领域之间的知识往往存在共性和交叉,有效利用和融合多个领域的情感知识,可以提高目标领域分类的泛化性,较单个源领域的情感迁移有明显的优势;
(3) 通过参数迁移和微调策略可以有效地迁移跨领域情感知识.相比较传统的情感迁移方法,深度迁移学习方法在情感迁移效率和跨领域情感分类准确率上有很大提升.其中,参数迁移技术可以将已经训练好的模型参数迁移到新的模型帮助新模型训练,而在源领域模型基础上的微调策略是非常有效的泛化手段;
(4) 有效的领域相似度衡量和常识知识的引入.目前,跨领域的情感分类仅局限于相似性较大的领域之间的迁移,如何实现相似性较低的领域之间或者源领域数据受限时的情感迁移,是一个值得研究的问题.源领域的知识往往是有限的,融合已有的先验知识和相关的语言学知识,可以辅助和提升目标领域的情感分类任务的效果.例如,通过引入知识图谱知识,充分利用人工标定和海量的无标记数据,将是未来非常有价值的研究思路;
(5) 跨领域的细粒度情感分类任务研究.传统的跨领域文本情感分类往往是实现不同领域之间篇章级的情感迁移,较少关注于跨领域细粒度的句子(sentence)级、方面(aspect)级、评价对象(target)及其属性的情感倾向任务研究.下一步可以研究篇章级的情感分类任务到细粒度情感迁移任务,或者不同领域之间细粒度情感分类任务之间的情感迁移;
(6) 跨模态和多模态的情感迁移机制研究.现实条件下,往往存在图像和语音等多个模态的情感信息,然而不同模态之间的特征空间是异构的.Cummins 等人[98]针对跨模态的情感迁移进行了有效探索.在未来的工作中,可以通过文本、图像和声音的跨模态特征学习,将不同模态的特征映射到共同的语义空间中,充分利用多模态的情感知识,实现跨模态和多模态的情感分类目标;
(7) 引入在大规模语料上的预训练模型并结合特定的领域知识.在面临特定领域的任务时,引入在大规模无监督语料上预训练的语境化的嵌入表示,例如ELMo[108]、OpenAI GPT[109]、BERT[110]、基于全词覆盖(whole word masking)的中文BERT 预训练模型[111]、XLNet[112]等,在下游任务中,结合特定的领域知识和迁移学习技术,如有监督的微调等,完成特定领域的情感分类任务.
5 结束语
跨领域文本情感分类可以弥补不同领域间情感分布差异,对提升情感分类的泛化性有重要意义,是情感分析的研究热点和难点之一.本文综述了跨领域文本情感分类的相关背景、现有技术和应用,从目标领域中有可用数据、不同的情感迁移策略和可用源领域的个数这3 个角度对已有的跨领域文本情感分类工作进行了总结.我们还重点介绍了深度迁移学习方法在跨领域文本情感分类中的应用.最后总结了目前跨领域情感迁移面临的主要挑战,并对其未来的研究方向进行了展望,尤其是跨模态情感迁移、常识知识以及领域知识应用于跨领域情感分类,可能是下一步的研究热点.
