基于K-means 和AGNES 的未知二进制协议聚类*
2020-09-23尹世庄陈庆超刘丽君阎韶林
尹世庄,王 韬,陈庆超,刘丽君,阎韶林
(1.陆军工程大学石家庄校区,石家庄 050003;2.陆军工程大学,南京 210000)
0 引言
网络协议识别与分析的主要对象是网络中传输的比特流数据。对于已知协议识别,通常以比特流中包含的协议类型、端口、长度、方向及特殊字段等为特征参数,基于模式匹配[1]、机器学习[2]等方法实现。对于未知二进制协议比特流,如何对其进行有效地区分,是网络协议识别与分析中亟待解决的问题。在比特流中包含较多未知协议的情况下,单纯使用已知协议识别方法对所有比特流的协议属性进行判别,存在着执行效率低下的问题。同文本协议相比,二进制协议在协议逆向处理上一个比较重要的特点是格式固定且多位置对齐。由于二进制协议传输效率高,因而在网络中的应用也越来越广泛,并且因为真实网络中未知协议数据构成非常复杂,所以对未知二进制协议进行有效地聚类,将具有相似协议属性的二进制协议划分到相应集合中,是提高网络协议分析效率、进行未知协议格式分析的基础。
1 国内外研究现状
比特流中已知协议的特征主要表现为协议类型、端口、长度、方向及特征字段等。目前大多采用基于端口,基于内容和基于行为的协议识别技术。但是随着网络的速度加快,人们又从流量特征这一方面对协议进行分类和识别,主要适用于流量特征明显的协议[3-4]。但是随着大数据和深度学习的兴起,基于隐马尔可夫模型和基于正则表达式成为了新的研究方向[5]。
目前针对未知二进制协议分类的研究还比较少,大多数是面向比特流的未知协议分类。对于比特流协议数据先经过帧切分,生成比特流协议数据帧,可采用提取前导码与关联规则相结合方式[6],然后通过多协议识别模型将多协议数据帧分离成不同单协议的数据帧集合[7]。张俊娇[8]引入特征序列位置信息作为协议特征提取的约束条件,将特征序列及其位置信息构成二维的复合特征,解决了特征字符串重复性的问题。阳水桥[9]基于K-means 提出了受限K-means 聚类方法,采用地址和端口号进行辅助聚类,从而更加准确地分类不同类别的网络流数据。陶思宇[10]在层次聚类中引入轮廓系数确定二进制帧的最优聚类数,提出了一种改进的多序列比对算法。以上研究成果可为未知协议比特流特征参数的选择和提取提供一定的借鉴。
二进制协议格式固定且多位置对齐。复杂度相较于其他协议来说较低,而K-means 算法虽然存在聚类参数k 选择困难等局限性,但由于其具有较低的实现复杂度,被广泛用于大型数据集的聚类。AGNES 算法在聚类过程中聚类距离可以采用汉明距离和pearson 相关性距离,能够更好地反映二进制协议比特流之间的相关程度。在未知二进制协议聚类的过程中,将主要采用K-means 算法和AGNES 算法进行聚类。
2 未知二进制协议聚类
2.1 实现方案
为实现对未知二进制协议的高效聚类,提出一种基于K-means 聚类和AGNES 算法的未知二进制协议聚类方法。协议是否已知并不影响聚类的准确度,为了更好地检验聚类效果,所以采用已知二进制协议代替未知协议。并且研究对象是已经做了初步切分,协议头部位置确定的比特流(以下均称为未知二进制协议比特流)。首先对数据进行预处理,针对二进制协议的特性,选取了4 bit 作为处理单位;处理数据时采用最短数据作为依据进行切割;将每一个单位作为一个特征得到一个n×m 的二维矩阵。再采用K-means 算法对其进行聚类分析,获得聚类的评估函数值,后用来确定聚类的k 值。然后采用确定k 值的K-means 和Agnes 算法对数据进行聚类,将未知二进制协议划分为二进制协议子集。在Agnes 算法中采用PEARSON 相关性距离作为度量,通过这些改进来提高聚类精度。

图1 比特流聚类与筛除实现方案
2.2 数据预处理
数据预处理阶段首先将从wireshark 中抓包得到的.Pacp 格式包另存为txt 格式,并且去除协议头部的多余数据,然后以4 bit 为单位进行处理。比如111111110011 转换为ff3 和15153,f、f、3 和15、15、3 为处理单元。将输入的数据帧构成一个n×m 的二维矩阵。n 为所输入的数据帧的行数,m 为所截取的数据帧的前m 个处理单元[12]:
生成一个m×n 的矩阵,其中n 为协议的总条数,因为二进制协议的头部比较短,因而太多的数据量会增加时间开销,所以每种协议取150 条。由于协议长度未知,为了更好地保留协议信息,同时有效地去除数据部分内容。M 值的确定以最小m 值为准,首先确定每种协议的最短比特流长度,然后以所有协议中最短协议的长度作为m 值。

数据预处理算法参数:m(指定取数据帧的前m 个处理单元)输入:n 条数据帧输出:n 行,m 列的二维矩阵步骤:1.针对不同的协议帧,去除其多余的头部数据。2.计算输入数据帧的条数,将其值赋予n;初始化n行m 列的二维数组,记为a[n][m];3. for 循环遍历每条数据帧4. 将数据帧按4 个bit 分割为m 个字节5. 分别将每个字节赋给矩阵对应行的每个元素6. 输出二维矩阵,并存储到txt 文档。
2.3 基于K-means 算法的比特流聚类
在数据预处理的基础上,采用K-means 算法对实验数据集中的比特流进行了聚类分析,对聚类参数k 分别取2~9,输出聚类结果和对应k 值下的轮廓系数S、误差平方和sse 和Calinski-Harabasz 分数值ch。
轮廓系数适用于实际类别信息未知的情况。对于单个样本,设a 是它与同类别中其他样本的平均距离,b 是与它距离最近不同类别中样本的平均距离,则轮廓系数S 为:

Calinski-Harabasz 分数值ch 越大则聚类效果越好。设m 为训练样本数,k 为类别数。Bk 为类别间协方差矩阵,Wk 为类别内部的协方差矩阵。Tr 为矩阵的秩。其公式为:
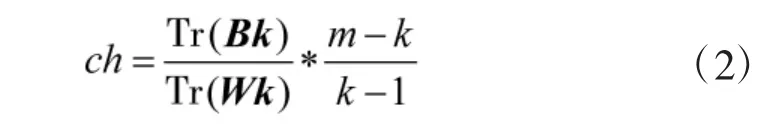
SSE(sum of the squared errors,误差平方和)其中,Ci是第i 个簇,p 是Ci中的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE 是所有样本的聚类误差,代表了聚类效果的好坏。

聚类过程的伪代码:

K-means 算法输入:n 行,m 列的二维矩阵;输出:k 个类簇,与之相对应的s、ch 和sse 的值步骤:1.从n 个样本中随机选择k 个样本作为初始聚类中心。2.for i=1 to n:3.计算样本xi 与各聚类中心的距离D(D 为欧式距离),将数据帧xi 划分到距离最近的类簇中。4.按公式images/BZ_130_1541_878_1830_987.png计算误差平方和E 5.for j=1 to k:6.计算新的聚类中心7.重新计算误差平方和E*8.比较E 和E*的差的绝对值,若小于阈值则转到步骤9,否则转到步骤2;9.输出K 个类簇。10.计算与k 相对应的s 值和ch 值11.输出K 、s、ch、sse。
2.4 确定k 值的AGNES 聚类
由轮廓系数S、Calinski-Harabasz 分数值ch 及误差平方和sse 的公式可知,随着聚类数k 的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE 自然会逐渐变小,k 值增大的前期s 值和ch 值会逐渐增大,并且当k 小于真实聚类数时,由于k 的增大会大幅增加每个簇的聚合程度,故下降和上升的幅度会很大,而当k 到达真实聚类数时,再增加k 所得到的聚合程度回报会迅速变小,所以幅度会骤减,然后随着k 值的继续增大而趋于平缓,而这个时候对应的k 值就是数据的真实聚类数。
为了更好地确定k 值,定义i 点的斜率变化率为该点的斜率值减去上一点的斜率值,同时为了方便比较将3 种不同评价参数的斜率变化值进行归一化处理。

为了提高精度,假定当3 种参数的变化率均大于斜率变化平均值(通过实验获得,太小没有区分度,太大3 种参数没有同时符合标准的k 值)时该点作为备选点,同时由于在实验中取了36 个特征,为了防止出现聚类粒度过细的现象,取备选点里面第一个点作为k 值。
指定聚类个数为k,进行AGNES 聚类,由于相关性距离更能反映数据帧之间的差异,所以类内距离采用PEARSON 相关性距离。

AGNES(AGglomerative NESting)算法输入:样本集D={x1,x2,…,xn};距离度量d;聚类个数k。输出:k 个类簇步骤:1. for i=1 to n:2. Ci={xi}#初始化单样本聚类簇3. end for 4. for i=1 to n:5. for i=1 to n:6. Mij=D(ci,cj)7. Mij=Mji 8. end for#初始化距离9. 设置当前簇个数q=m 10. while q>k:11. 找到最相似的两个簇,合并最相似的两个簇12. 将聚类簇重新编号,删除相对应的距离矩阵的行和列13. q=q-1 14. end while 15. 输出K 个类簇。
3 实验结果与分析
实验数据集由真实的网络环境获取,用ARP、DNS、ICMP、TCP 和SMB 代表5 种未知二进制协议比特流子集,文中分别用P1、P2、P3、P4和P5表示。每种协议取150 条。假定所有协议做了初步切分,均从对应协议头部开始并且包含数据部分。取所有报文中最短长度144 bit 作为m 值。
3.1 聚类个数k 提取结果与分析
对K-means 算法中的k 值进行调整,将聚类数设置为2~9,通过不同的k 值,分别记录对应的s、ch、sse 值。得到的结果如图2~图4 所示。
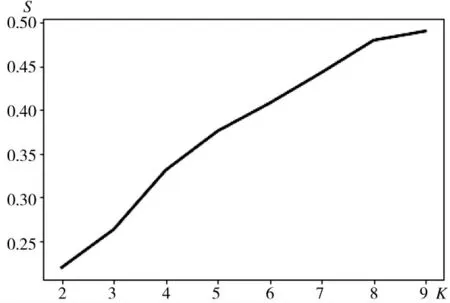
图2 轮廓系数s 随k 值变化情况
轮廓系数取值范围是[-1,1],同类别样本距离相近且不同类别样本距离越远,s 值越大。对于Calinski-Harabasz 分数值,类别内部数据的协方差越小,类别之间的协方差越大,Calinski-Harabasz 分数越高。

图3 Calinski-Harabasz 分数值ch 随k 值变化情况

图4 误差平方和sse 随k 值变化情况
通过对比3 种参数的变化,发现在k=5 和k=8的时候s 值、sse 值和ch 值均发生了较大的变化,斜率变化率均大于平均值,但由于k=5 是第一个出现的k 值,故对于这个数据集而言,最佳聚类数为5。同时,也将k=8 作为对比项,进行下一步实验。
3.2 基于K-means 算法的聚类结果与分析
在确定好k 值的基础上,采用K-means 算法对实验数据集中的比特流进行了聚类分析,在取聚类参数k 为5 的情况下,获得了较为准确的聚类结果,如下页图5 所示。为了验证在上一步中k 取5是合理的,另取聚类参数k 为8 的情况下,得到的聚类结果如下页表1 所示。
表1 中数据表示聚类后每一种协议所包含的报文条数,图5 中x 轴是协议编号,y 轴是协议种类,反映的是协议种类随编号的分布情况。在数据预处理的过程中由于是将已知二进制协议充当未知二进制协议,并且聚类中心是随机选取的,不影响最后结果。为了统计方便将5 种协议按顺序排列。通过图表可以看出聚类效果较好,各类数据都能有效区分,但是在第3 类中仍有28 条协议被划分到了第4 类。
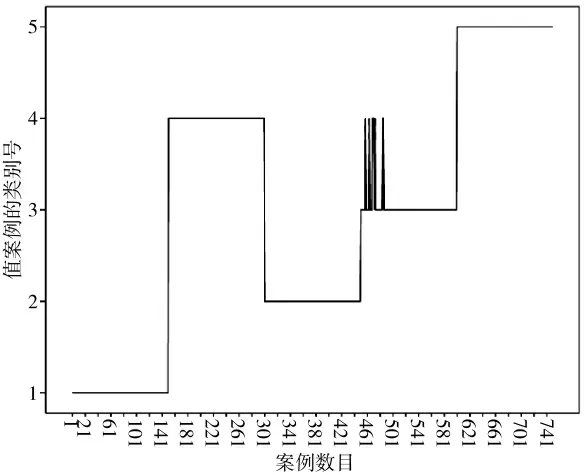
图5 k=5 聚类结果分布图

表1 k=5 和k=8 聚类结果
当k=8 时结果如图6 所示,可以看到新增加的3 类大部分分布在在第4 类协议中,也就是TCP 协议中,通过研究具体TCP 协议聚类结果,发现,由于tcp 协议报文内部格式差异较大,当k 值较大时,造成了分类粒度过细。

图6 k=8 聚类结果分布图
3.3 基于AGNES 聚类结果与分析
在聚类过程中,设定方法为中位数聚类法,度量标准采用PEARSON 相关性距离,聚类数指定为5,对750 条协议报文进行聚类,聚类的结果如图7所示。

图7 AGNES 聚类结果树状图
图7 中x 轴是协议编号,y 轴是聚类距离参数,反映的是在不同距离参数情况下协议的聚类情况。
当k=5 时,聚类结果如图8 所示,AGNES 算法将5 种协议较好地区分开,其中有10 条p3 协议被划分到了p4 类。
显效:患者的临床症状和体征缓解50%以上,尿微量白蛋白下降50%以上或是恢复正常水平。有效:临床症状和体征缓解30%~50%,尿微量白蛋白下降30%~50%。无效:不符合上述标准者。

图8 k=5 AGNES 聚类结果分布图
3.4 聚类结果与传统K-means 对比分析
在相同的k 值下通过准确率、识别率、误识别率来比较两种方法的聚类结果。
准确率Acc:表示用某种算法进行聚类操作时,正确分类的协议数量占协议总数的比例,具体计算如式(5)所示。

其中,Count(Corr_frame)表示正确分类的数据帧数量,Count(total_frame)表示所有的数据帧。
识别率TP:表示用某种算法进行聚类操作时,属于类别X 的数据帧被正确分给X 的比例,具体计算方法如式(6)所示。

其中,Count(corr_X)表示类别X 的数据帧正确分给X 的数量,Count(total_X)表示属于类别X 中的数据帧总数。
误识别率FP:表示用某种算法进行聚类操作时,不属于类别X 的数据帧被分给X 的比例,具体计算方法如式(7)所示。
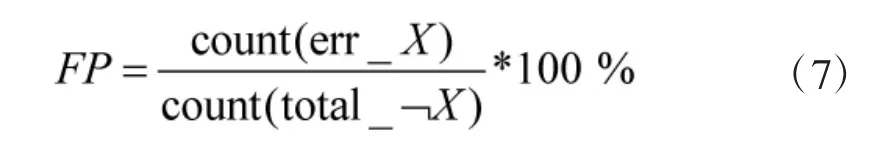


表2 k=5 时K-means 和AGNES 聚类结果对比
以P1~P5 这5 种协议种类为横坐标,画出两种不同算法下的TP 值和FP 值折线图。如图9、图10所示。
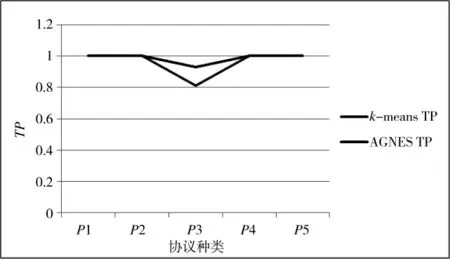
图9 两种算法协议聚类效果TP 比较

图10 两种算法协议聚类效果FP
通过对比发现K-means 算法比AGNES 算法运算速度快,但是聚类结果较差。从理论上分析是由于K-means 的时间复杂度小于AGNES,所以运算速度优于AGNES;但在聚类过程中K-means 采用的是欧式距离,而AGNES 采用的是PEARSON 相关性距离,更符合二进制协议的特性,所以精确度不如AGNES。
在未知二进制协议聚类过程中,由于K-means算法时间复杂度低,首先设定不同k 值采用K-means 聚类方法对协议报文进行聚类分析,然后通过评价函数确定k 值,再指定聚类个数为k,进行AGNES 聚类。通过不同k 值的K-means 聚类可以发现在某种程度上k 值反映了聚类的粒度。k 值越大,聚类粒度越细。
4 结论
为解决先验知识不足条件下的未知二进制协议聚类问题,在数据预处理的基础上,采用能够快速获得聚类结果的K-means 算法对原始比特流集合进行聚类分析,通过聚类的评估函数值后用来确定聚类的k 值。然后采用确定k 值的K-means 和Agnes 算法对数据进行聚类,将未知二进制协议比特流划分为二进制协议子集。通过最后结果比较可以确定先通过K-means 确定k 值再通过Agnes 进行最终聚类,可以在保证精度的基础上提高运算速度,并且对数据进行预处理和改进参数可以使模型更好地适应未知二进制协议的聚类。
提出的方法在完成未知二进制协议聚类的基础上,能够较快地计算出聚类结果。聚类距离的选择对二进制协议这一特殊对象有较大的影响,对K-means 算法进行改进从而使其提高其聚类精度将会是一个新的研究方向。
