多种算法融合的产品销售预测模型应用①
2020-09-22张雷东李冬梅朱湘宁焦艳菲
张雷东,王 嵩,李冬梅,朱湘宁,焦艳菲
1(中国科学院大学 计算机控制与工程学院,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(沈阳高精数控智能技术股份有限公司,沈阳 110168)
1 引言
随着经济全球化的逐渐加深,企业之间的竞争日益激烈.并且当下随着电子商业的飞速发展,每天都有上万笔交易在互联网上完成,这样就产生了海量的数据.企业如果能利用这些数据,从数据中挖掘出用户购买的一些规律,就能更好的在这个市场中占据有利的位置.销量预测一直是一个重点研究的问题,一个准确的销量预测可以为企业控制成本,提前规划市场和部署战略.这个问题解决的好就能为企业的未来规划提供重要决策的理论支持.
目前为止,销量预测的研究方法有自回归移动平均法 (ARMA)、线性回归、灰色系统理论等.基于时间序列的预测方法也被越来越多的学者采用,郑琰等基于时间序列的商品预测模型研究[1]、顾涵等支持向量归等在高频时间序列中的研究中[2]以及Fan ZP 等在预测产品销售时[3],采用这样方法都得了良好的效果.随着深度学习的崛起,又有了长短记忆网络(LSTM)这样优秀的预测算法,葛娜等利用Prophet-LSTM 组合模型对销售量进行预测研究[4].除此之外,张彤等利用LSTM 的该井模型GRU 结合LMD 形成了一种新的预测方法[5].往往将传统的线性模型和深度学习算法相结合,通常比单一算法表现优秀,或者结合以上某两种算法.例如冯晨等基于 XGBoost 和 LSTM 加权组合模型在销售预测的应用[6],表示不同模型的组合,很大的提高了模型的泛化能力.
集成学习就是这样的一种策略,集中几种模型的优势,大大提高模型的性能.Stacking 模型堆叠就是一种集成学习的思想,集成几种模型的优势.盛杰等利用Stacking 算法对恶意软件进行检测[7],包志强等将传统的Stacking 算法进行了改进,提出了一种熵权法的Stacking 算法[8],明显提高了算法的预测性能。
2 预测算法核心内容
2.1 预测算法框架
整个预测算法框架如图1所示.
(1) 将整个数据集分为训练集和测试集.
(2) 对所有的特征进行Pearson 相关系数计算,筛选掉冗余的特征,选择相关性的特征,作为模型训练的特征向量.
(3) 将SVR、GRU、XGBoost 作为Stacking 的基础模型,利用特征向量进行训练.
(4) 将历史信息、均值、价格变化、评价分析和Stacking 第一层的输出以及原始的特征进行特征融合,形成最终预测模型的输入.
(5) 将lightGBM 作为Stacking 算法的次级预测模型,进行训练并且在测试集上进行预测,得到结果.

图1 预测算法框架图
2.2 Stacking 算法
Stacking 算法简单理解就是几个简单的模型,一般采用将它们进行K 折交叉验证输出预测结果,然后将每个模型输出的预测结果合并为新的特征,并使用新的模型加以训练.
Stacking 通常分为很多层,每一层的输出作为下一层的输入.但是伴随着层数的增多,模型的复杂度也在增加,训练起来也会慢很多.所以通常采用两层结构.在第一层时,将K-1 份数据作为训练集进行训练,将剩下的一份用来预测.这样K轮下来以后,将K轮的预测结果和原始数据进行拼接就形成了新的训练集.然后,第二层的模型利用新的数据集进行训练.最终预测,输出结果.如图2所示.
在本文中,将SVR、GRU、XGBoost 作为第一层的预测模型,lightGBM 作为第二层的预测模型.具体训练过程如下:
(1) 将处理好的训练集平均分为5 份数据量大小相等的数据Di(i∈1,2,3,4,5);
(2) 在每一轮训练中,对于每一训练模型,例如SVR,在4 份数据上进行训练,剩下一份用来预测得到Pi;
(3) 将第一层预测模型的输出Pi和原始的特征进行拼接,得到最终的训练数据集D;
(4) 利用最终模型lightGBM 在训练集D上进行训练;
(5) 最后在测试集上进行预测,得到最终的预测结果Prediction.

图2 Stacking 算法结构图
2.3 LightGBM 算法
LigthGBM 是Boosting 集合模型中的新进成员,由微软提供,它和XGBoost 一样是对GBDT 的高效实现.LightGBM 通过使用Gradient-based One-Side Sampling(GOSS)和Exclusive Feature Bundling (EFB)两种方法来解决特征选择的问题,进而加速训练速度.伪代码如算法1 及算法2.

算法1.GOSS算法伪代码输入:I:training data,d:iterations,a:sampling ratio of large gradient data,b:sampling ratio of small gradient data,loss:loss function,L:weak learner 1-a models ← {},fact ← topN ← a*len(I),randN ← b*len(I)For i=1 to d do preds ← models.Predict(I)g ← loss(I,preds),w ← {1,1,…}sorted ← GetSortedIndices(abs(g))topSet ← sorted[1:topN]b randSet ← RanomPick(sorted[topN:len(I)],randN)usedSet ← topSet+randSet W[randSet] *=fact ▷ Assign weight fact to the Small gradient data newModel ← L(I[usedSet],- g[usedSet],w[usedSet])Models.append(newModel)

算法2.EFB算法伪代码输入:F:feature,K:max conflict count输出:bundles Construct graph G searchOrder ← G.sortByDegree()Bundles ← {},bundlesConflict ← {}for i in searchOrder do needNew ← True for j =1 to len(bundles) do cnt ← ConflictCnt(bundles[j],F[i])if cnt + bundlesConflict[i]<= K then bundles[j].add(F[i]),needNew ← false break if needNew then Add F[i] as a new bundle to bundles
2.4 数据预处理
(1) 对于缺失值和由于促销引起的销量数据激增,采用这个月销量的均值代替.
(2) 将标签特征利用one-hot 编码转化为0 或1 的特征.
2.5 特征工程
特征工程的结果对模型对着模型效果改善有着重要的作用.特征工程通常用来减少冗余的特征,提高模型训练的速度以及准确率.经常用的特征选择的方法有Pearson 相关系数、互信息和最大信息系数、皮尔森卡方检验、距离相关系数等.
2.5.1 特征选择
在这里选用Pearson 相关系数,这是比较简单使用的特征选择方法.这种方法能够反映特征和预测值之间的线性相关关系,结果值范围在[-1,1],-1 表示该特征和预测值完全是负相关,0 表示没有线性相关的关系,1 则表示该特征值和预测值正相关.其计算公式如下:

在式(1)中c ov(X,Y)表示两个变量的协方差,其计算公式如下:

在式(1)中 σX表示变量X的标准差,计算公式如下:
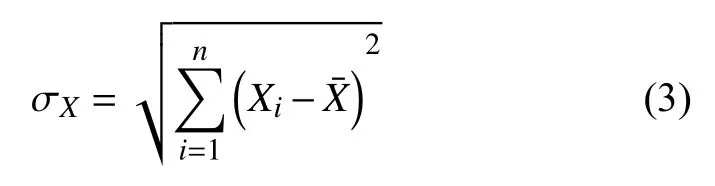
2.5.2 特征构造
(1) 按照一级类型、二级类型统计该类型产品月销量的均值.
(2) 提取当前月的前第一个月、前第二个月、前第三个月、前第四个月、前年该月的销量数据.
(3) 加入商品的价格变化.
(4) 商品的评价分析:对评论数据进行分词,然后构造情感词典,计算每条评论的情感值,最后累加每天的评论情感值.
3 实验与结果分析
本实验数据来源于一个氨纶制造的企业.数据主要包括从2014年1月到2018年1月每一天的历史销量数据.数据属性主要有:产品id、产品类型、产品等级、产品用途、产品价格、重量、日期等.
3.1 评价指标
(1)RMSE均方根误差
均方根误差是预测值与真实值偏差的平方与观测次数n比值的平方根.计算公式如下:

(2)MAE平均绝对误差
MAE是真实值与预测值的差值的平方然后求和平均.计算公式如下:
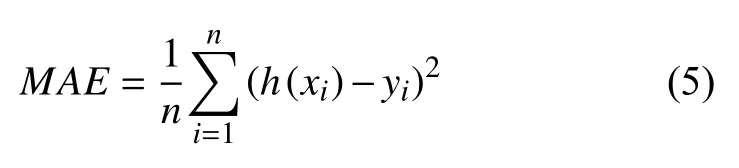
(3)MAPE平均绝对百分比误差
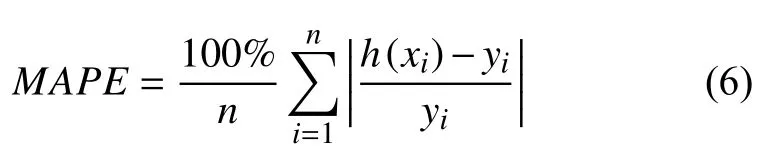
3.2 特征选择
利用Pearson 相关系数,筛选掉一些相关性弱的特征.最终选择了产品id、产品等级、价格、产品类型、产品用途、颜色、材质、是否有促销活动、所属的年月等属性.
3.3 实验结果
3.3.1 模型参数设置
利用XGBoost 和LightGBM 单模型在训练集训练模型时,使用Skit-learn 机器学习库中的GridSearchCV方法,对模型的参数使用交叉验证的方式去探索最优的参数.核心参数如表1和表2所示.
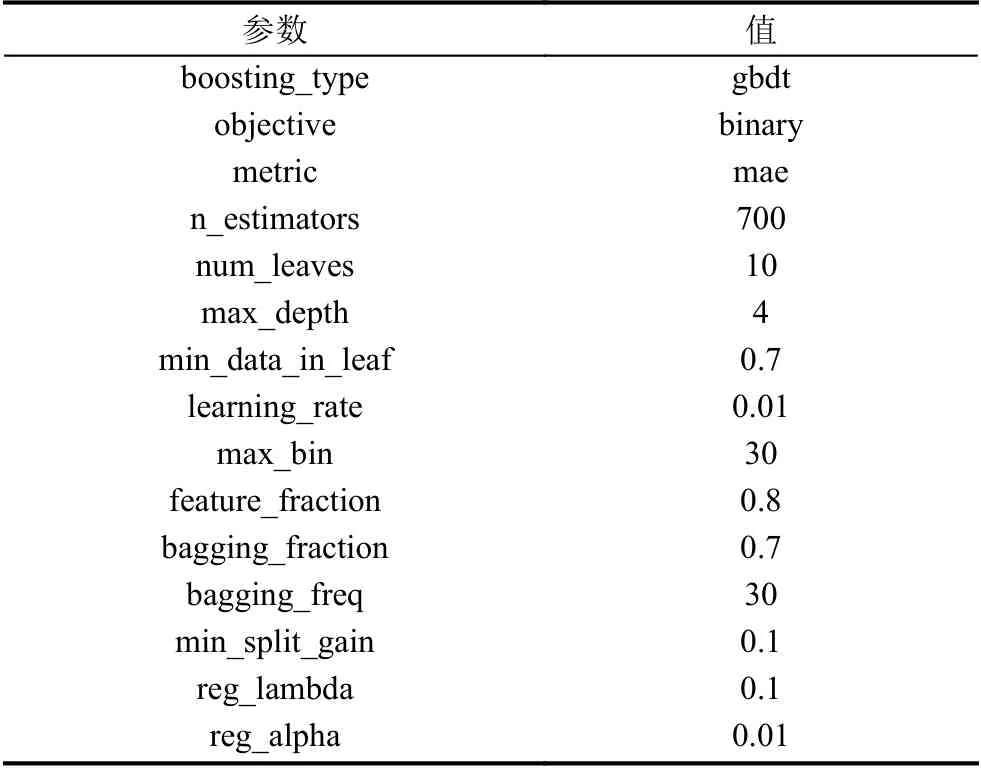
表1 LightGBM 参数表

表2 XGBoost 参数表
SVR 模型涉及的核心参数主要有3 个:选用的核函数、惩罚因子以及核系数.通过Grid Search 实验验证最佳的参数见表3.

表3 SVR 参数表
3.3.2 预测结果分析
在训练集上训练单模型以及组合模型,最终在测试集上进行预测.将预测结果绘制成折线图,得到的结果图对比如下.
为了更加具体的比较出各个模型预测性能之间的差异,采取RMSE、MAE以及MAPE3 个评判指标进行对比.具体的结果对比见表4.

表4 各模型预测性能对比
从图3中可以看出SVR 预测结果最差,LightGBM要比XGBoost 好一些.组合模型和SVR、XGBoost、LightGBM 以及GRU 相比,性能都有所提升.Sacking组合模型的性能最优.因此,基于Stacking 集成策略的组合模型确实能提升算法的预测性能.在做回归问题时可以使用Stacking 方式集中几个模型的优势,可以为实验准确度的提升带来一定的帮助.
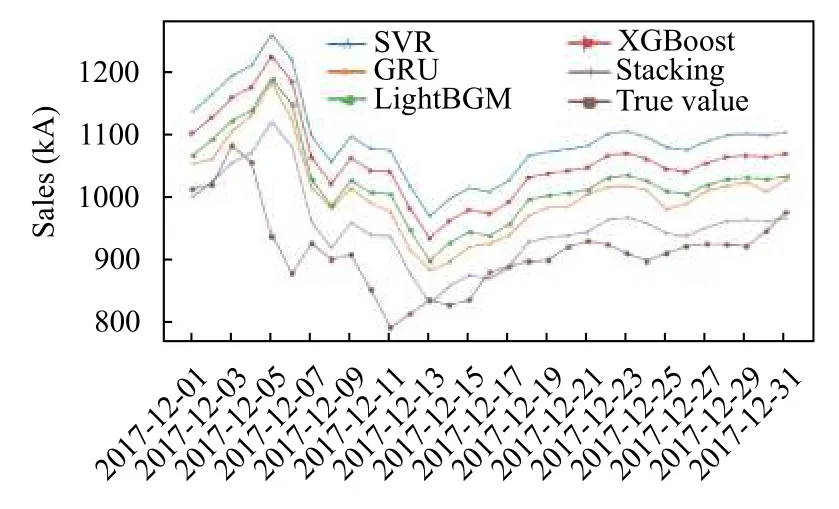
图3 各个模型最终预测效果图
在加入历史信息、均值、价格变化以及评价分析这些新的特征以后,和没有进行特征融合的算法预测结果进行对比.将预测结果绘制成图,如图4所示.

图4 特征融合之后预测结果对比图
按照评价标准进行计算后,具体结果见表5.

表5 模型融合后的预测性能对比
从预测效果图上可以看出,在加入新的特征之后,算法预测性能有明显提高.从3 个评价指标的数值上也可以看出,特征融合之后的算法预测的MAPE提升到了2%.也证明这些新的特征确实发挥了作用.
4 总结
本文使用Stacking 策略结合了LightGBM、GRU、SVR、XGBoost 几种经典的解决回归问题的算法提出了一种多种算法融合的产品销售预测模型,并且结合数据做了实验.实验证明这种多种算法融合的产品销售预测模型的预测结果要比这些单一模型的预测结果更加接近真实数据.并且在引入了历史信息、均值、价格变化以及消费者的评价分析等这些新的特征后,算法的预测性能又有了进一步的提升.
最终实验表明,通过集成学习能够有效提高氨纶产品销量的预测性能.为回归问题的提出一种新的思考方式和解决办法.同时,Stacking 策略也使得整个组合模型的复杂度变高,训练速度变得缓慢,这也是进一步要尝试改进的地方.同时未来工作中,将进一步尝试结合不同新的模型来做回归类问题的研究.
