时域注意力Dense-TCNs在多模手势识别中的应用
2020-09-18赵杰煜
张 毅,赵杰煜,王 翀,郑 烨
(宁波大学 信息科学与工程学院,浙江 宁波 315211)
0 概述
随着科学技术的迅猛发展,手势识别已成为当前科学研究领域的热点之一,其主要应用领域有目标检测[1]、视频检索、人机交互[2]、手语识别[3]等。由于手势识别存在相似手势之间的细微差别、复杂的场景背景、不同的观测条件以及采集过程中的噪声等,使得通过机器学习得到一个鲁棒性手势识别模型具有较大的挑战性。
基于深度学习的手势识别主要任务是从图像或视频中提取特征,然后将每个样本分类或确定到某个标签上。手势识别旨在识别和理解手臂与手在其中起着关键作用的人体有意义的运动。但是在动态手势视频中,一般只有少量的手势可以从图像或单个视频帧中的空间或结构信息中识别出来。事实上,运动线索和结构信息同时表征了一个独特的手势,而如何有效地学习手势的时空特征一直是手势识别的关键。尽管在过去的几十年中,人们提出了很多方法来解决这个问题,如从静态手势到动态手势,从基于运动轮廓到基于卷积神经网络,但是在识别精度方面仍然存在不足。
目前,现有的基于深度学习的孤立手势识别模型已经拥有了较高的识别率,多数方法都是基于卷积神经网络(CNNs)[4-5]或递归神经网络(RNNs)[6]开发的。
随着深度学习的发展,越来越多新颖且高效的网络体系结构被提出,其中比较有代表性的方法为文献[7]提出的密集卷积神经网络(DenseNets),相比于传统的CNNs,DenseNets拥有更深的网络层级结构,并且模块内的卷积层互相密集关联,从而使网络在拥有深层层次结构的同时,避免由于网络过深而导致信息丢失的问题。实验结果表明,DenseNets拥有较高的特征提取能力和识别率。而针对复杂的手势,三维CNNs能够有效地学习到视频内连续视频帧中的手势短时的空间、结构和姿态变换,这是单帧图像或图片的二维CNNs所欠缺的。但由于在传统三维CNNs模型训练过程中,作为输入的视频片段(较短的连续帧)会有重复输入的部分出现,且如果重复部分较大则会大幅延长模型的训练速度,因此如何简化学习操作与高效训练模型是一个十分重要的课题。
对于时序模型而言,文献[8]提出一种新的解决序列问题的结构——时间卷积神经网络(TCNs)。与传统的RNNs及其典型的递归体系结构LSTMs和GRUs相比,TCNs具有较好的清晰性和简单性。
为提取更完整更有代表性的特征信息,文献[9]证明了在神经网络中特征信息的内部存在多种关系,并提出将注意力机制作为深度学习模型的嵌入模块。而压缩-激励网络SENets[10]是一个高效的基于注意力机制的体系结构单元,其目标是通过显式地建模其卷积特征通道之间的相互依赖性来提高网络生成的质量表示。
本文采用三维DenseNets提取多段基于连续视频帧片段的短时空间特征,并组成一条由短时空间特征组成的序列。将短时空间特征序列输入到TCNs中完成分类任务,并采用针对时间维度改进的压缩-激励方法(TSE),增强TCNs在时间特征提取方面的能力。
1 相关研究
基于视觉的手势识别技术包括面向静态手势的方法和面向动态手势的方法[2]。近年来,CNNs[4]凭借其强大的特征提取能力,在计算机视觉相关任务上取得了重大突破,因此,CNNs提取的特征被广泛应用于许多动作分类任务中以获得更好的性能。二维卷积网络(2D-CNNs)最初是应用于二维图像中的,也就是静态手势或者是动态手势视频中的单帧图像,如文献[11-12]使用二维CNN并通过多层等级池化对图像手势进行识别,提取空间与时域上的信息。而三维卷积网络(3D-CNNs)的发展,使得三维卷积(C3D)在后续的研究中被广泛应用。文献[13]将三维CNNs引入到动态视频手势识别中,具有较好的性能,该研究的主要贡献是提出了一种从视频片段中提取时空特征的体系结构。另一方面,文献[14]设计了一个用于手势识别的多流3D-CNNs分类器,该分类器由两个子网络组成:高分辨率网络(HRN)和低分辨率网络(LRN),这为后续研究提供了宝贵经验。为解决视频中的手势片段训练的问题,文献[15]提出了一种新的时间池化方法。
随着深度卷积神经网络的发展,越来越多的CNNs体系结构被提出,如AlexNets[11]、VGGNets[16]、GoogleNets[17-20]、ResNets[21]和DenseNets[7]。上述模型的目标就是构建一个更高层次的CNNs体系结构,从低层次的图像帧中挖掘更深入、更完整的统计特征,然后进行分类。在孤立手势识别领域,文献[22]使用Res-C3D模型应用于手势识别任务中。文献[23]同样适用Res-C3D模型,并在2016年和2017年的ChaLearn LAP多模态孤立手势识别挑战赛[24-25]中两次获得第一名,这足以证明层次越深的网络拥有更强的特征学习能力。而DenseNets[7]作为最新的卷积结构之一,逐渐被应用于动作识别,特别是人脸识别[26]和手势识别。除图像识别领域外,在最近的研究中,DenseNets也被用来对不同的行为进行分类,如文献[27]使用DenseNets进行行为识别的研究。而深度信息作为除RGB信息外的额外视频信息被国内外研究所应用,其中文献[28-29]使用深度图对手势进行识别。
对于视频序列的时间信息,LSTM网络是手势识别的常用选择。例如,文献[30]将卷积长短期记忆模型(conv-LSTM)引入到时空特征图中,从而通过手势视频中的前后关系进行识别。文献[31]使用2S-RNN(RGB和深度图)进行连续手势识别。然而,包括LSTMs和GRUs在内的RNNs在时域上存在着短时信息学习、存储容量过大等缺点。为了弥补这些不足,人们提出TCNs并将其应用于手势再现中。文献[32]提出了基于骨架的动态手势识别方法Res-TCNs,实验结果表明,相较于传统的RNNs,TCNs在结构上更加简洁,并能够有效地提高识别率。在整个时序数据中有许多冗余信息,因此,引入注意力机制显得非常重要。文献[33-34]在使用时序模型的同时,嵌入了相关的注意力机制模型,在原有时序模型识别率的基础上降低了错误率。
本文方法具体工作如下:
1)为解决单帧图像不能承载足够的手势空间和结构信息,而多视频帧训练又需要避免视频片段所导致数据重复训练的问题,结合截断的3D-DenseNets(T3D-Dense)和局部时间平均池化(LTAP)两种方法作为短时空间特征序列的提取模型。
2)利用时间卷积网络代替传统的递归神经网络作为短时空间特征序列分析的主要模型,并对压缩-激励网络(SENets)进行改进,使其能够应用于时域维度嵌入TCNs中,重新调整层间的短时空间特征序列的权值,从而更有效地对短时空间特征序列进行分析,达到更高的分类精度。
2 时域注意力Dense-TCNs
本文提出一种新的模型来提取时空特征,并对时空特征序列进行识别和分类。模型流程如图1所示,整个过程可分为以下2个部分:
1)通过截断的T3D-Dense、局部时间平均池(LTAP)和多模式特征串接提取多模式的短时时空特征序列模块。
2)基于TCN和TSE的时空特征序列识别模块。
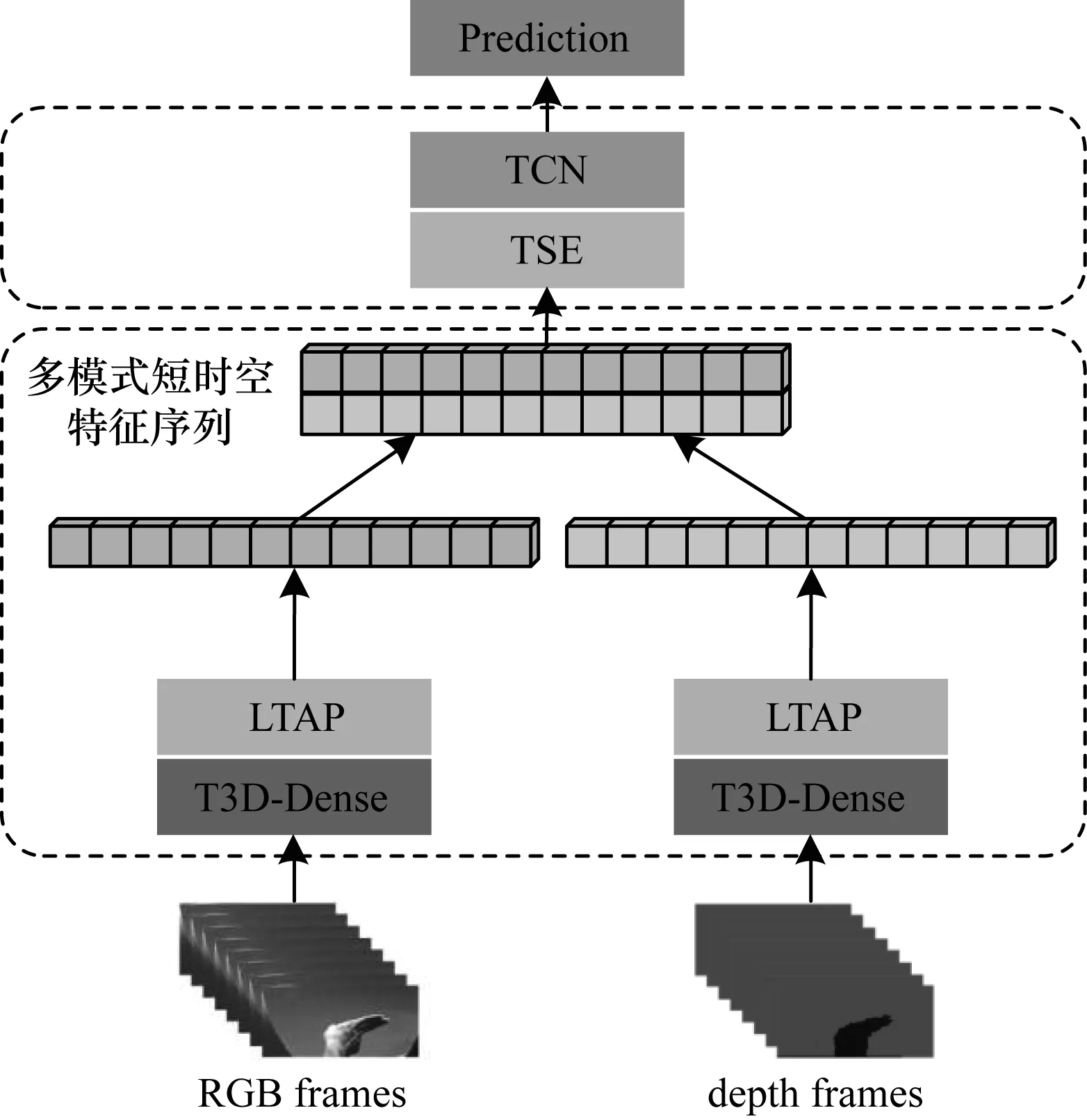
图1 本文模型的流程
2.1 短时时空特征学习
由于签名视频的性质,一个健壮的视频特征表示需要结合多模态手势信息。在手势视频中,前后帧之间存在着多种关系,包括位置、形状和序列信息。因此,本文设计一个基于C3D的多流DenseNets作为时空特征提取器,从视频中提取时空特征。在此模型中,所有视频集的长度必须相同。因此,一个给定的视频V和n帧需要规范化为k帧。本文设置的输入为:
VS=[V1,V2,…,Vk]
(1)
其中,Vk是输入视频序列的第k帧图像。
如前文所述,本文考虑多种形式的手势视频数据作为输入。每种类型的数据被设置为一个数据流并馈送到相同的网络结构,它们的输出随后将被融合,见图1。每个数据流共享相同的网络结构,网络结构如表1所示,模型包含4个致密块体,每个区块包含6、12、24、16层密集连接卷积层,网络的增长率为12,表1中显示的每个“conv”层对应于BN-ReLU-conv序列。值得注意的是,大多数卷积层都使用3×3×3大小的卷积核,同时在空间和时域上进行分析,但是为了避免短期时间信息的融合,将所有过渡层的时间池大小和步长设置为1,这主要是区别与其他传统的C3D模型。

表1 三维DenseNets架构
由于三维DenseNets是一个短期的时空特征提取器,因此在本文中其被截断,使模型只得到经过全局空间平均池化后的特征。具体来讲,首先用孤立的手势数据对模型进行预训练,然后丢弃全局时间平均池层、最后一个softmax层和完全连接层。因此,模型可以在全局空间平均池层之后得到全局时空特征Fk:
Fk=[f1,f2,…,fk]
(2)
其中,时间长度为k,并且表示k帧的短时时空特征。
然后从全局特征Fk中剪切和合并T个短时时空特征。第t个短期时空特征xt构造为:
(3)

经过局部时间平均合并后,本步骤可以得到一系列单模态的短期特征。多模特征序列在输入TCN前融合成一个序列。整体短时时空特征模块在预训练时与截断后的流程如图2所示。
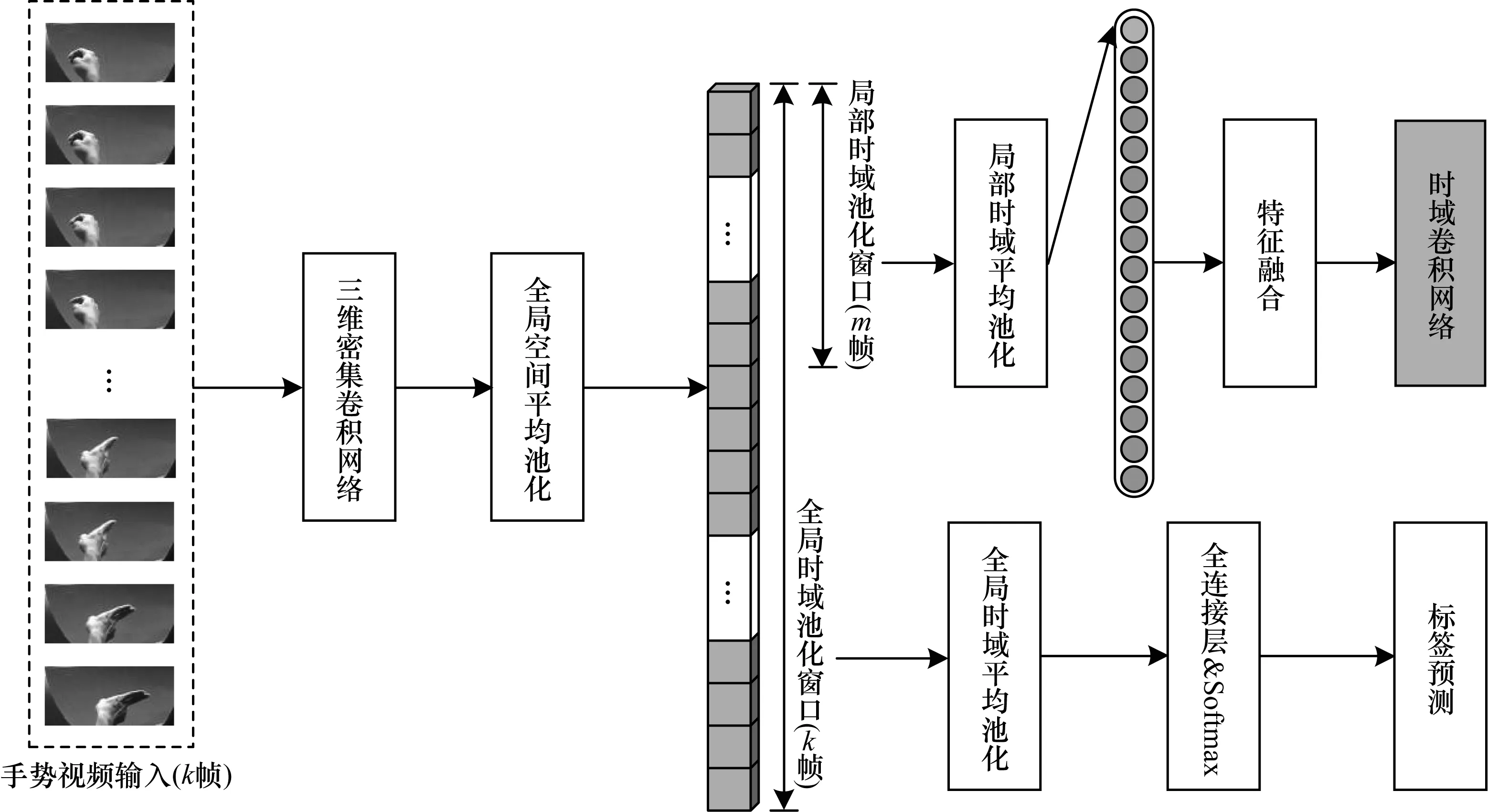
图2 短时时空特征模块流程
2.2 短时时空特征序列的识别
基于从各种数据模式(RGB、光流、深度等)中提取的短时时空特征,考虑整个视频的长期时间特征,对给定手势进行分类。本文采用一种序列识别模型TCNs,并对其进行了改进以处理长期时间信息。TCNs的主要特点是使用因果卷积和将输入序列映射到相同长度的输出序列。此外,考虑到序列具有较长的历史,该模型使用了能够产生大的卷积野的膨胀卷积以及允许训练更深网络的残差连接。考虑到本文的任务是对手势视频的类别进行分类,TCN的输出层通过一个完全连接层进行进一步处理,得到每个手势序列的一个类标签。改进的TCN模型结构如图3所示。

图3 本文改进的TCNtse模型结构
在TCN模型中,从短时时空特征模块所学习得到的序列X=[x1,x2,…,xt]作为TCN的输入序列,其经过多层时间卷积后的输出设定为Y=[y1,y2,…,yt]。而每一层的卷积核本文都将使用膨胀卷积使得TCNs能够在不同层学习不同时序跨度的特征。膨胀卷积的计算公式为:
yt=(x*dh)t=∑xt-dmhm
(4)

(5)
其中,Wo、bo分别为训练后得到的全连接层参数。
值得注意的是,X=[x1,x2,…,xt]中的特征在整个序列识别过程中的贡献是有所不同的。由于手势的组合特性和复杂性,在不同手势中必然会有一部分的手势片段是接近的,可将这些连续的手势片段进行识别区分,本文是通过TCN模型来学习手势片段间的时序关联性。但与此同时,如何学习到特征序列中的关联强度(权重)也是本文需要考虑的一个问题。为此,本文引入注意力机制,改进了压缩-激励网络(SENets)并将其应用嵌入到时序特征序列模型TCN中。
如图3所示,时域压缩-激励网络模块(TSENet,TSE)被嵌入到TCN模块每一层时间卷积层输入前,首先将时间卷积层的输入X=[x1,x2,…,xT]在通道上进行全局平均卷积,从而获得一条T×1大小的权值序列Z=[z1,z2,…,zT]。
假设时间卷积层输入通道数为C,则t时刻的平均通道值zt计算公式如下:
(6)
与此同时,可以将平均通道所得到的值作为当前t时刻特征的权重,而本文为了重新调整各个时刻特征的权重,则加入了第2个操作,即压缩-激励操作。为使网络能够自动学习到这一权重值,加入了一个简单的激活门控制整个权值序列的计算:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(7)
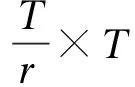
(8)

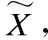
3 实验结果与分析
本文所提出的网络结构由tensorflow平台实现,并使用NVIDIA Quadro gp100 GPU进行训练。多模态截断的密集卷积网络(T3D-Dense)分别使用RGB、深度信息和光流信息(如果存在光流或可计算)数据作为输入进行预训练。Adam优化器用于训练T3D-Dense的预训练模型3D-DenseNets,学习率初始化为6.4e-4,每25个epoch下降10倍。权值衰减率设置为1e-4,Drop_out设为0.2,3D-DenseNets内每个block的压缩率c和增长率k分别设置为0.5和12。对于TCN模型,本文使用Adam优化器进行训练,学习率初始化为1e-4,epsilon为1e-8。
3.1 数据集
本节将本文方法与其他最新的动态手势方法进行比较。在实验中,本文使用两个公开的多模态动态手势数据集来评估文中提出的模型。
1)VIVA[15]。VIVA challenge数据集是一个多模态的动态手势数据集,专门设计用于在真实驾驶环境中研究自然人类活动的复杂背景设置、不稳定照明和频繁遮挡等情况。此数据集是由微软Kinect设备捕获的,共有885个RGB和深度信息视频序列,其中包括8名受试者在车内进行的19种不同的动态手势。
2)NVGesture[6]。NVGesture数据集为了研究人机界面,采用多传感器多角度进行采集。它包含1 532个动态手势,这些手势是由20名受试者在一个有人工照明条件的汽车模拟器中记录下来的,这个数据集包括25类手势。它还包括动态DS325装置作为RGB-D传感器,用DUO-3D进行红外图像采集。在实验中,本文使用RGB、深度和光流模态作为模型的数据输入,而光流图则使用文献[31]提出的方法从RGB流计算得到。
3.2 数据预处理
数据预处理包括数据增强和数据规范化2个部分:
1)数据增强。在VIVA数据集中,数据增强主要由3个增强操作组成,即基于视频帧的反序、水平镜像或同时应用前2个操作。如VIVA中有一类手势是在视频中从左往右移动,通过反序操作或者水平镜像,能够得到一个从右向左移动的手势作为从右向左移动的手势的增强。而同时应用反序和水平镜像操作,就能够得到一个从左往右移动的手势作为从左往右移动的手势的增强。
在NVGesture数据集中,每个视频图像被调整为256×256像素的图像大小,然后用224×224块随机裁剪,在裁剪时,同一数据的裁剪窗口在视频中位置不变。
2)数据规范化。对于机器学习而言,数据规范化是必要的,特别是对于时序模型,时序上的量是固定的,所以对时序维度的重采样尤为重要。本文给定一个额定帧数k,对于小于额定帧大小或大于额定帧数大小的视频,使用上采样和下采样的统一标准化来统一帧的数量。给定的视频V和n帧需要压缩或扩展到k帧,有以下2种情况:
(1)当n>k时,将视频V平均分割为k节视频集VS,其中VS=[V1,V2,…,Vk]。对于视频集VS中的每个片段,随机选择一个帧作为多个连续视频帧的表达。最后,将所有表示帧连接起来,并使它们成为规范化的结果。
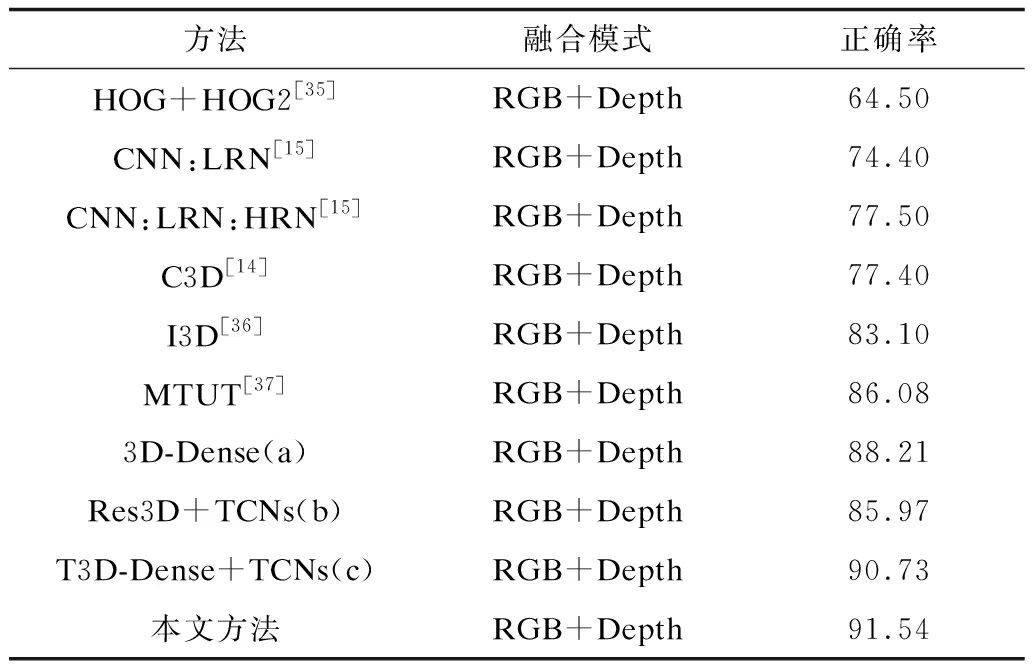
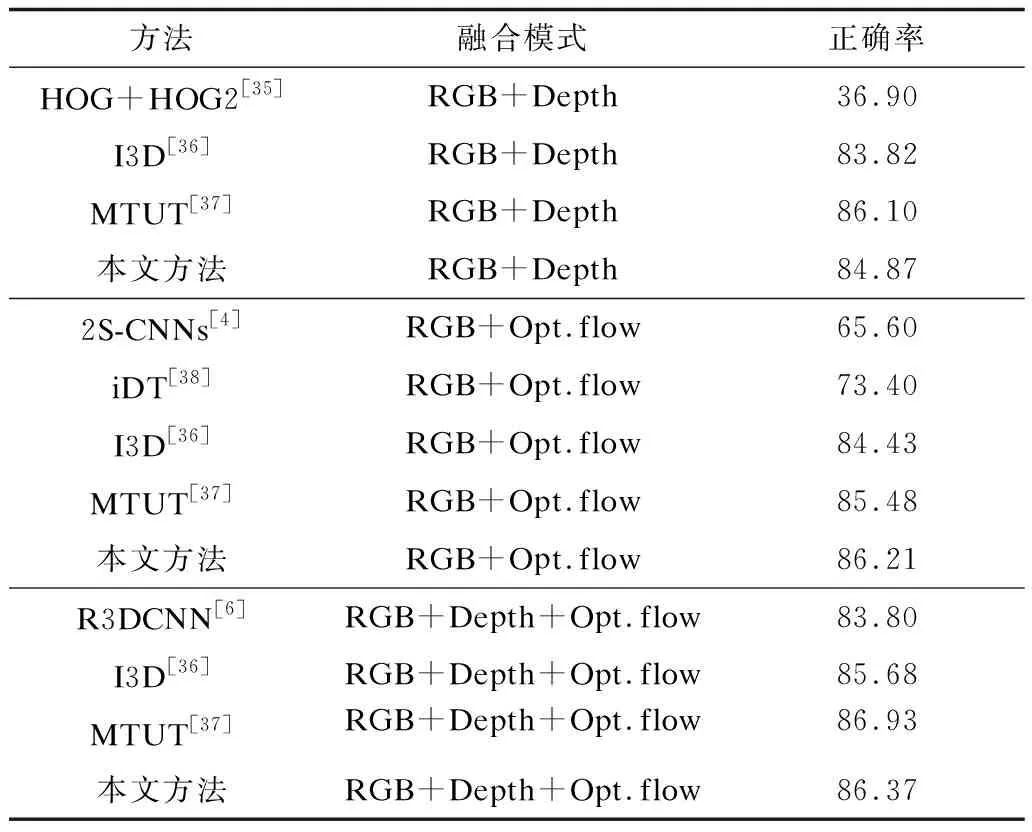
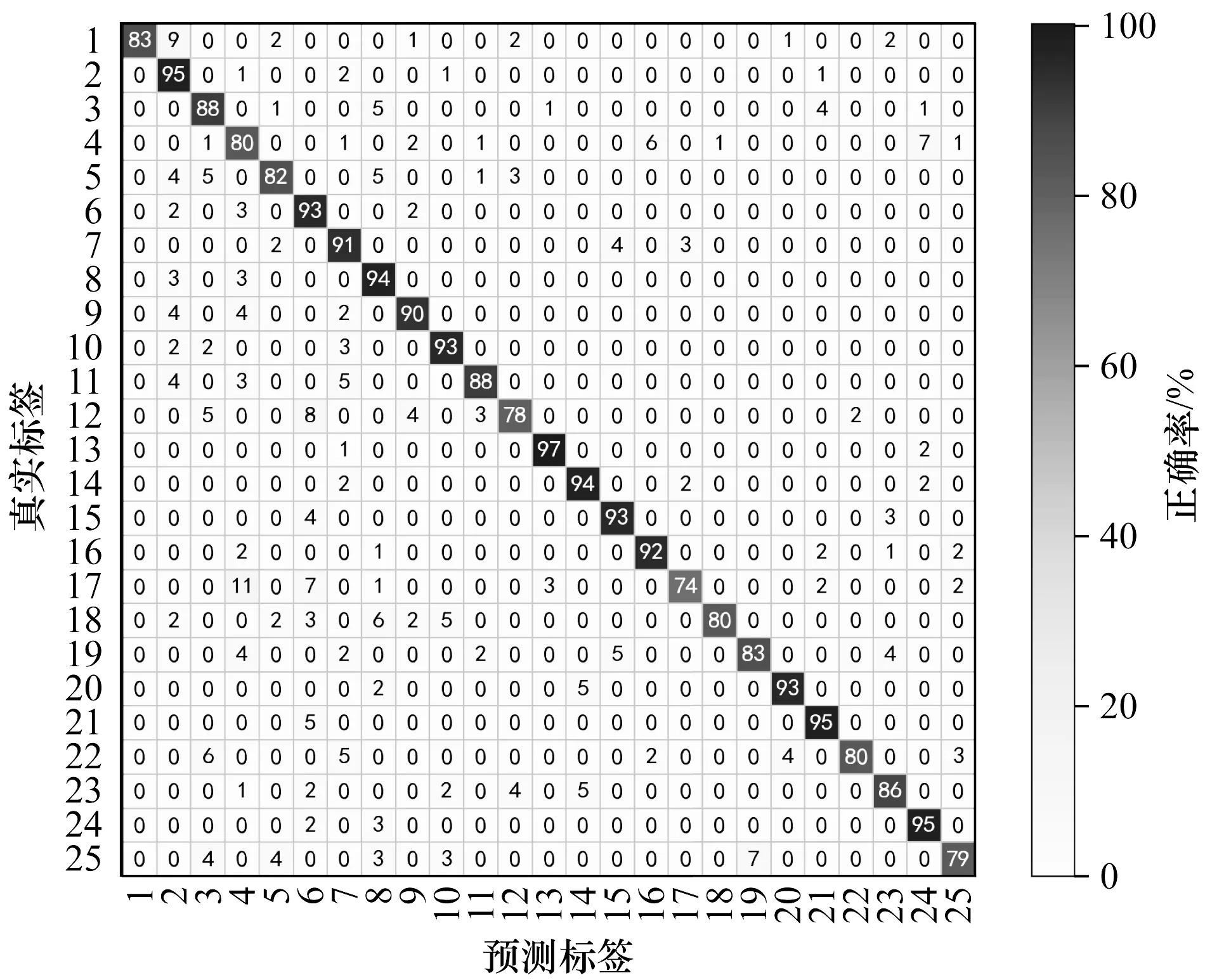
(2)当n 在T3D-Dense模型和TCNs模型中,输入数据的维数是固定的,具体来说,3D-DenseNet在预训练过程中的所有输入的帧数都应该是固定的。经统计,VIVA数据集的平均帧数k是32帧,NVGesture数据集的平均帧数k是64帧,所以在实验中本文将VIVA数据集中的k设置为32,NVGesture数据集中的k设置为64。 由于C3D计算的高复杂性,输入的视频图像像素大小被重采样为112×112像素。 表2为在VIVA数据集的RGB和深度信息2个模态上测试的动态手势的性能。 表2 本文方法与其他方法在VIVA数据集上正确率对比 实验结果表明,本文方法在VIVA数据集上获得了91.54%的正确率。从表2可以看出,本文提出的T3D-Dense+TCNtse在正确率上远优于HOG+HOG2、CNN:LRN、CNN:LRN:HRN以及C3D方法,分别高出27.04%、17.14%、14.04%以及14.14%。而本文方法的识别正确率与I3D与MTUT方法正确率较为接近,这在一定程度上是由于I3D和MTUT与本文方法使用了较为相似的预训练方式。尽管如此,可以看到本文方法RGB和depth网络的性能在I3D和MTUT的基础上分别提高了8.44%和5.46%。 同时,本文在VIVA数据集上测试了其他方法以证明各模块的有效性,测试的方法主要有: 1)完整3D-DenseNets。3D-DenseNets预训练的过程其本质就是完整3D-DenseNets对动态手势的识别训练,所以可以直接对预训练的3D-DenseNets进行测试,测试识别正确率为88.21%。 2)Res3D+TCNs。通过将短时时空特征提取模块的主干框架T3D-Dense改变为Res3D网络,可以发现基本的T3D-Dense作为主干框架在正确率上优于以Res3D为主干框架的Res3D+TCNs网络。并且本文T3D-Dense+TCNs网络的参数量仅为141万,而Res3D+TCNs网络的参数量为4 535万,是T3D-Dense+TCNs参数量的30倍之多,证明了本文算法的优越性。 3)T3D-Dense+TCNs与本文方法之间的区别在于TCN网络中是否有TSE模块的嵌入,可以看到TSE模块的加入使得网络获得了0.81%的识别率提高。 本文统计了根据本文方法所得到的最终分类的混淆矩阵,如图4所示。 图4 VIVA数据集上输入为RGB+深度信息的识别混淆矩阵Fig.4 Confusion matrix with RGB+depth information input on VIVA data set 在实验中,发现在VIVA数据集上第1类与第2类、第16类与第17类上有着较高的误识别率,尤其是第16类与第17类(其中第16类为手势顺时针划圈,第17类为手势逆时针划圈)之间,误识别率为15%。为此,从TCN各层中提取出第16类与第17类中TSE模块的权值作可视化。从图5中发现,由于第16类与第17类的结构空间信息在短时上拥有较多的相似性,导致TSE在权值控制上并不能很好地区分开两者,使得两者在识别上会有较高的误识别率。但在大多数手势的权值上,尤其是TCNs第3层的5帧~12帧上拥有较大的区分度。实验结果证明,TSE对于TCNs识别具有较好的效果。 图5 VIVA数据集中TSE模块可视化图 为了在两种以上数据流的任务中测试本文的方法,在NVGesture数据集上分别以RGB+深度信息、RGB+光流信息以及RGB+深度+光流信息作为输入进行了测试,分类结果如表3所示。 表3 本文方法与其他方法在NVGesture数据集上正确率对比 在RGB+深度信息中,将本文方法与HOG+HOG2、I3D以及MTUT方法进行比较,可以看出,对于较为复杂的数据集,相较于传统HOG+HOG2方法,本文方法具有较高的正确率,但与3D与MTUT方法相比识别率不明显,甚至比MTUT正确率低了1.23%,可能是因为在复杂的数据集中,由于较为轻量的模型导致在时间跨度较大的数据中并不能很好地识别出视频片段间的联系。 在RGB+光流信息中,将本文方法与2S-CNNs、iDT、I3D以及MTUT方法进行比较。虽然iDT通常被认为是目前性能最好的手工识别方法,但可以看出,本文的方法识别正确率高于iDT方法19.88%。并且在此模态中,由于光流信息同时包含了许多前后帧的手势变化信息,因此本文方法在精度上都高于其他方法。 在RGB+深度+光流信息中,将本文方法与R3DCNN、I3D以及MTUT方法进行比较。其中R3DCNN是该数据集原始方法,可以看出本文方法比原始方法正确率高2.57%,比I3D方法高0.69%。虽然本文方法正确率比最新的MTUT方法低0.56%,但由于模型在特征融合上较为简单,因此结果在可接受范围内。在此基础上,本文方法在NVGesture数据集中各手势的误判率较为平均,平均误判率为0.51%,识别混淆矩阵如图6所示。 图6 NVGesture数据集输入为RGB+深度+光流信息的识别混淆矩阵 综上所述,本文方法在NVGesture数据集上的识别正确率取得了与当前最新方法相近的水平。 本文提出一种基于时域注意力机制的Dense-TCN模型。该模型通过截断预训练的3D-DenseNets和局部时域池化的方式来避免时间片段过多的重复训练,同时根据嵌入时域注意力机制改进TSE模块对短时时空特征序列进行识别。实验结果表明,该模型具有较高的识别率,且参数量较少。由于3D-DenseNets需要预训练且被截断才能提取局部的短时时空特征,依赖于预训练时3D-DenseNets的正确率和多模态融合方法,导致针对一些分类多、噪声大的数据集时正确率较低,因此下一步拟将3D-DenseNets模型改为端到端模型,并对多模态融合方法进行改进,以进一步提高模型识别率。3.3 在VIVA上的测试结果


3.4 在NVGesture上的测试结果
4 结束语
