SKASNet:用于语义分割的轻量级卷积神经网络
2020-09-18孙怀江
谭 镭,孙怀江
(南京理工大学 计算机科学与工程学院,南京 210094)
0 概述
近年来,深度卷积神经网络(Convolutional Neural Network,CNN)[1-3]因其在图像处理中的高效性而被广泛应用于计算机视觉领域。在图像语义分割任务中,CNN在权威公共数据集,如Cityscapes[4]数据集上已经获得了很高的精度。相较于一般的分类任务,图像语义分割[5-7]是基于像素级的多类分割任务,其更具挑战性。然而,传统的CNN在进行图像特征提取时,同一层的神经元仅使用相同大小的感受野,导致该层的神经元只能获得固定尺度的信息而丢失了其他大小的尺度信息。因此,对不同的目标对象使用相同大小的感受野时效果较差。
为解决上述问题,文献[8]提出了选择核神经网络,其通过对同一区域使用不同大小的感受野来获取不同尺度的语义信息。选择核卷积能够满足不同大小的目标对象对感受野的要求,并且可以根据输入自适应地调节感受野大小。Inception[9]采用了类似的机制,在同一区域采用不同的感受野,但与选择核卷积不同的是,Inception对于获取的多尺度信息只进行一个简单的线性聚集,这导致其模型无法具有较高的自适应能力。选择核卷积的自适应调节感受野的特性,在语义分割任务中可以使得模型获得更多、更丰富的语义信息。
选择核卷积由于需要对同一输入进行多次卷积操作,因此在实现对多尺度[10]空间信息的提取时也带来了大量的网络参数,提高了计算量,这不利于模型在无人系统中的应用。
为降低网络参数量,多数模型[11]在网络结构中使用分组卷积来达到降参的效果。目前,分组卷积的使用难点在于分组数没有一个明确的指标。为降低模型的参数量和计算量,模型结构需要尽可能地增加分组数。但是,由于组间相互独立地进行卷积操作,组间无信息交流,因此过多的分组数使得模型丢失大量组间的相关性信息,从而导致模型无法提取丰富的语义信息。但是,过少的分组数虽能在一定程度上减少组间相关性信息的丢失,却也导致模型无法更加轻量化。
为获得多尺度语义信息并构建一个轻量级网络模型,本文使用选择核卷积构建一个新的残差模块SKAS(Selective-Kernel-Array-Shuffle),利用选择核卷积能够根据输入信息自适应调节感受野大小的特性来获得多尺度语义信息。同时,本文提出一种锯齿状逐层分组卷积模型结构,该结构以4个SKAS模块为一组,组内每个SKAS模块的分组数分别为4、8、16和32,使得模型既不会因为过多的分组数丢失大量组间相关性信息,也不会因为过少的分组数导致模型无法轻量化。锯齿状的堆叠方式使得组间能够进行一定的信息交流,此外,本文还采用文献[12]提出的通道混合技术进一步增强组间的信息交流。
1 相关工作
图像语义分割作为计算机视觉领域中的重要分支,在自主导航和机器人系统中得到广泛应用,同时其也为无人系统中的重要一环。目前,图像语义分割任务主要包括提升精度与减小模型参数2个目标。本文的目的是在不降低分割精度的同时减少模型参数,使模型具有更好的实用价值。
全卷积神经网络FCNs[13]将分类模型从基于图像级分类转变为基于像素级分类,实现了输入输出均为图像。同时,FCNs提出了跳跃结构,其将浅层特征叠加到输出,以此提升分割精度。为获得高精度的分割效果,一些网络模型增加了网络层数。然而,当网络深度达到一定程度时,会出现梯度消失和梯度爆炸问题。ResNets[14]提出了残差结构,其通过恒等映射使网络更深,而不会出现梯度消失和梯度爆炸现象。PSPNet[15]是基于ResNets构建的一种高精度语义分割模型。
目前,多数语义分割模型都是编码-解码模型。文献[16]为了实现快速推理以及得到较高的分割精度,提出了ENet模型结构。ENet采用深层编码器进行特征提取,同时使用浅层解码器恢复图像分辨率。相对于SegNet[17]和U-net[18],ENet采用了一个较小的解码器,而SegNet与U-net的编码器和解码器采用相同的网络层数。此外,ERFNet[19]在ENet的基础上,采用空间分离卷积,通过文献[20]提出的空洞卷积搭建网络结构。对于空洞卷积,文献[21]指出不同空洞卷积应该以锯齿状的形式叠加,并且所叠加的空洞卷积的大小之间不能有大于1的公约数。此外,文献[8]为提取多尺度语义信息提出了选择核卷积,其能够根据输入自适应地调节感受野大小。
高精度的模型在获得较好分割效果的同时,也带来了庞大的模型参数与较高的计算量。Inception-v2[11]采用分组卷积,在一定程度上降低了参数数量。分组卷积较早出现在AlexNet[22]网络中,其最初目的是为了解决显存不足的问题,将网络布置在2个显卡上。随着深度学习技术的发展,分组卷积也得到了广泛应用。MobileNets[23]提出了深度可分离卷积,大幅降低了模型参数。文献[24]通过简化Inception-v3[11]提出了Xception,当Xception的分支数达到极限时,其效果就与深度可分离卷积相似。BiSeNet[25]和ContextNet[26]均采用2个深度不同的网络分别提取图像的空间信息和上下文信息,从而降低了模型的计算量。
2 网络模型
本文以ERFNet模型为基础,构建一种轻量级网络结构,如表1所示,通过使用SKAS模块以及逐层分组卷积,以在减小网络参数的同时保持或提高分类精度。

表1 网络模型结构Table 1 Network model structure
2.1 ERFNet模型与自适应选择核卷积
ERFNet是以ENet模型为基础的实时高效模型[27-28]。ERFNet使用4个空间可分离卷积,构建一个Non-bottleneck-1D残差模块,如图1所示,其中,每2个1维的3×1卷积和1×3卷积为一组,表示一个2维的3×3卷积。

图1 模型中的核心模块结构Fig.1 The core module structure in the model
在语义分割任务中,卷积核的感受野对不同大小的目标对象会产生不一样的敏感度。为提升模型对不同目标的敏感度,本文采用文献[8]提出的自适应选择核卷积,这种卷积方式能够对同一输入使用不同尺寸的卷积核来获得多尺度语义信息,并对这些多尺度信息进行融合,最终通过一个门结构自适应地选择不同尺度。
2.2 SKAS模块
本文提出一种新的模块SKAS,如图1所示,该模块的前2层网络与Non-bottleneck-1D相同,采用2个一维的3×1卷积和1×3卷积,后2层使用2个一维的SKA选择核卷积,每个SKA选择核卷积通过M个不同大小的卷积核提取多尺度特征并进行融合。选择核卷积SKA的操作过程可以表示为:

(1)

此外,为避免模型出现梯度爆炸或梯度消失的情况,本文还采用文献[14]提出的残差结构。由于在实验中本文对同一输入使用了2种不同的感受野,因此模型的规模会大幅提升,本文通过空间分离卷积与分组卷积来降低模型规模。
2.3 逐层分组卷积与通道混合技术
为建立轻量级网络模型,本文提出一种逐层分组卷积,不同于传统的分组卷积使用固定的分组数,逐层分组卷积中连续的几个SKAS模块之间的分组数A是不同的。在实验过程中,设置A=(4,8,16,32),并以锯齿的方式进行堆叠,如表1所示,这样设计有如下2个目的:
1)为了避免模型参数量太大而无法轻量化,或者太小使得模型无法学习到足够的特征信息。若所有卷积层的分组数g均相同,当g太小时,模型参数量仍然很庞大,模型规模并没有得到大幅降低;当g太大时,模型参数量大幅降低,但由于参数过少,降低了模型的学习能力及性能。此外,参数的变化幅度较大,本文提出的分组形式可以使得参数的变化过程变得平缓。
2)锯齿状的堆叠方式可以在一定程度上避免组间无信息交流的现象。如图2所示,传统的分组卷积使得各组之间独立进行卷积操作,彼此之间无任何信息交流。但是,通道间却存在着一些相关性信息,这些信息对于提升模型的学习能力具有很大的作用,传统分组卷积会丢失这些相关性信息,不利于模型的学习。本文提出的锯齿状逐层分组卷积并不会使各分组完全独立地进行卷积操作,因此,其在一定程度上减少了相关性信息的丢失。
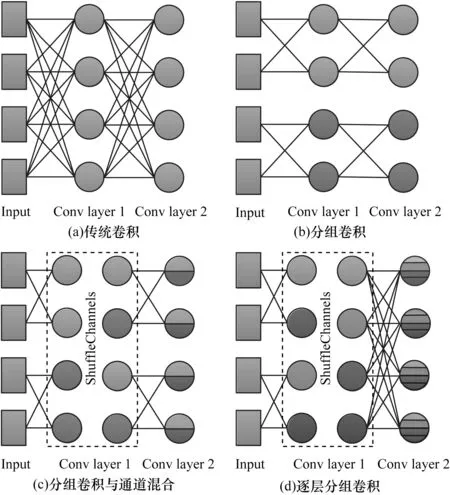
图2 不同形式的卷积操作Fig.2 Different convolutional operations
为进一步加强组间的信息交流,本文采用ShuffleNet[12]提出的通道混合技术。该技术与传统的堆叠方式相结合,仍然存在部分通道之间无任何信息交流的问题,如图2(c)所示。本文提出的锯齿状逐层分组卷积能够有效降低这种损失,如图2(d)所示。综上,本文提出的方法不仅降低了网络参数,还缓解了分组卷积存在的问题。
3 实验结果与分析
本文模型以ERFNet[19]为基础,实验中使用Cityscapes作为数据集,Cityscapes数据集在语义分割任务中主要注释了19个类,分别为Road、Sidewalk、Building、Wall、Fence、Pole、Traffic light、Traffic sign、Vegetation、Terrain、Sky、Person、Rider、Car、Truck、Bus、Train、Motorcycle、Bicycle。由于其高精度的标签注释以及明确分配的训练集、验证集和测试集,因此广泛应用于语义分割模型的测试中。Cityscapes数据集共有5 000张不同城市的分辨率为2 048×1 024的街景图。其中,2 975张图片作为训练集,500张图片作为验证集,1 525张图片作为测试集。实验中的所有模型都只在训练集上进行训练,在验证集上进行模型性能验证,最终以测试集上的平均交并比(mean Intersection-over-Union,mIoU)作为模型性能高低的衡量标准。
本文实验环境为NVIDIA GTX 1080Ti 11 GB GPU。训练配置:输入图像大小为1 024×512,batchsize为5,epoch为150,weight-decay为2e-4,初始学习速率为5e-4。分别采用Adam optimizer和交叉熵损失函数作为随机梯度下降的优化器以及损失函数。同时,采用一个学习速率时刻表,使得学习速率随着epoch次数的增加不断减小。整个训练过程分为训练模型的编码器与解码器2个步骤。
3.1 逐层分组卷积与传统分组卷积的对比
表2所示为本文逐层分组卷积和传统分组卷积在Cityscapes的验证集和测试集上的实验结果,其中最优结果加粗表示。模块SKG与SKA相比,SKG的分组数固定而SKA的分组数不固定。当使用SKGS(G表示分组数,S表示通道混合技术)模块时,随着分组数的增加,模型参数大幅减少,但是模型性能也随之下降,并且参数数量处于一种急剧变化的过程。从表2可以看出,SK1、SK8S、SK32S3种模块的参数从3.17 M开始急剧降到了1.80 M、1.65 M。在Cityscapes的验证集上,SK1、SK8S、SK32S 3种模块分别获得了70.70%、70.56%、69.84%的mIoU,在测试集上分别获得了69.8%、68.1%、68.0%的mIoU。该结果表明,虽然对模型进行适量地降参,能够有效地避免模型过拟合,提升模型性能,但是,过度地降参不仅不会提升模型性能,反而因为模型复杂度不够而导致其无法拥有足够的学习能力。

表2 逐层分组卷积与传统分组卷积在Cityscapes数据集上的Val_mIoU和Test_mIoU对比Table 2 Comparison of Val_mIoU and Test_mIoUbetween layering packet convolution andtraditional packet convolution on Cityscapes dataset
本文提出的逐层分组卷积可以使得模型参数平缓降低。表2显示了模块SKAS和SKA的优越性,两者在Cityscape的验证集上分别取得了70.64%、70.47%的mIoU,在测试集上分别取得了68.5%、68.3%的mIoU。与SK8S模块相比,SKAS模块不仅降低了模型参数,还在Test_mIoU上提升了0.4个百分点,这显示出本文逐层分组卷积能够在一定程度上减少组间信息丢失量。SK32S模块的参数虽然少于SKAS模块,但是Test_mIoU很低。此外,实验结果表明,使用通道混合技术有利于提升模型精度。
3.2 模型性能对比
为更好地验证本文模型的效果,将其每一个类别的分割精度与基础模型ERFNet进行比较。从表3可以看出,本文模型能够更好地分割小物体,如Fence、Pole、Traffic light、Traffic sign、Terrain、Person和Rider。此外,在大物体的分割精度上本文模型也取得了与ERFNet相似的精度。图3所示为本文模型与ERFNet模型在Cityscapes验证集上的定性对比。从最右边一列可以看出,本文模型能够更好地对Traffic sign这类小物体进行有效分割;从最左边一列可以看出,本文模型对Bus这类较大的物体同样具有有效的分割性能。

表3 本文模型与ERFNet模型在Cityscapes测试数据集上的分割精度对比Table 3 Comparison of segmentation accuracy betweenthe model in this paper and the ERFNet model onCityscapes test dataset %

图3 本文模型与ERFNet模型在Cityscapes验证数据集上的定性结果对比Fig.3 Comparison of qualitative results between the model in this paper and ERFNet model on Cityscapes validation dataset
3.3 语义分割模型对比
本文模型旨在尽可能降低模型参数与计算量的情况下保证获得与当前经典模型相似的精度。表4所示为本文模型与一些经典模型以及最新模型在模型参数量、Class_mIoU以及Category_mIoU上的比较结果,所有对比均在Cityscapes数据集的测试集中进行。本文模型在Class_mIoU和Category_mIoU上分别取得了68.5%和86.7%的精度,精度高于多数模型。与基础模型ERFNet相比,本文模型不仅在参数量上降低了19%,并且在Class_mIoU上也提升了0.7%。从表4可以看出,性能较好的PSPNet[15]、ICNet[29]模型都具有庞大的参数量,分别为本文模型的147.5倍和15.6倍。参数相对较小的DFANet A’[27]也比本文模型多了3.6倍的参数量。其他模型不仅在参数量上远高于本文模型,在Class_mIoU上也低于本文模型,如DeepLab[5]模型的参数量是本文模型的154.2倍,但Class_mIoU只有63.1%。经典的FCN-8S[13]的参数量也为本文模型的78.8倍,而Class_mIoU只有65.3%。ENet[16]虽然在参数量上低于本文模型,但是其Class_mIoU也大幅降低,仅为58.3%。因此,本文实现了以轻量级的网络模型获得高分割精度的目标。

表4 不同模型在Cityscapes测试集上的Class_mIoU和Category_mIoU对比Table 4 Comparison of the Class_mIoU and Category_mIoUof different models on the Cityscapes test set
4 结束语
本文设计一种逐层分组卷积,结合该逐层分组卷积与选择核卷积构建高精度的轻量级卷积神经网络。该网络利用选择核卷积提取多尺度语义信息,从而提升网络精度,同时采用逐层分组卷积降低网络参数量,增强分组间的信息交流。在Cityscapes数据集上的实验结果验证了该网络模型的高效性。下一步将研究各分组之间的相关性信息,并探索能够高效提取相关性信息的方法。
