融合BERT语义加权与网络图的关键词抽取方法
2020-09-18吕学强
李 俊,吕学强
(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
0 概述
随着计算机信息技术和网络技术的快速发展,各行各业每天产生并积累大量数据,从海量数据中提取对人们有价值的信息已成为急需解决的问题。关键词抽取是在对象文本中自动抽取能够体现文本内容的中心概念或者重要词语,可帮助人们快速定位所需文档,因此其在自然语言处理、图书馆学和情报学等领域得到广泛应用[1]。
目前,关键词抽取方法主要分为有监督和无监督两种。有监督的关键词抽取方法通过二分类思想确定文档中的候选词是否为关键词。该方法将已标注的关键词数据作为训练语料库,通过语料库训练关键词判别模型,并利用该模型对待处理文本进行关键词提取,但是该方式需要人工提前标注大量语料,并且若在标注过程中存在误差,则会直接影响模型性能。无监督的关键词抽取方法无须事先标注训练语料,通过关键词重要性排序实现关键词抽取。该方法利用关键词权重等量化指标进行权重计算与排序,选出综合影响得分较高的若干词作为关键词。无监督的关键词抽取方法近年来受到学者们的广泛关注,其中的TextRank方法[2]在构建网络图时主要利用文档本身的结构信息,但缺少外部语义知识的支持,而基于Transformer的双向编码器表示(Bidirectional Encoder Representation from Transformer,BERT)语言模型能将词语映射成高维的向量,并保留其语义上的相似关系。
本文将文档信息与BERT词语语义信息同时融入基于网络图的关键词抽取模型中,通过词向量进行语义表示并利用BERT词向量加权方式计算TextRank中词节点的概率转移矩阵,以提升关键词抽取效果。
1 相关研究
文献[3]利用词图中的度中心性、接近中心性等中心性指标,加权计算邻接词语所传递的影响力概率转移矩阵,提升关键词抽取效果。文献[4]通过词语覆盖范围权重、位置权重和频度权重以及TextRank实现关键词自动提取。文献[5]提出针对中文文档的关键词抽取算法TextRank-CM。文献[6]将TextRank与隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)[7]主题模型相结合,通过融合文档整体的主题信息及单篇文档的结构信息来提高关键词抽取效果。文献[8]通过训练隐马尔可夫模型挖掘主题信息和关键词,并在测试语料上取得了较好的挖掘效果。文献[9]通过构建语义网络图并融合图路径转化量、词聚类系数以及词窗口信息提出综合计算指标,且在专利数据集中具有较好的性能表现。文献[10]利用各种图节点缩减算法重构语言网络图,筛选出文档中影响得分高的节点并将其作为关键词。文献[11]提出在TextRank转移概率计算过程中融合词图的边和点信息来提升关键词抽取效果。
近年来,随着Word2Vec[12]、GloVe[13]等词向量模型和语言模型的发展,学者们开始利用词向量模型训练文本库生成词向量获得词汇语义关系,并结合传统TextRank方法进行关键词提取。文献[14]将词向量融入候选词中以增强关键词抽取的语义关系。文献[15]通过词语的语义距离计算实现词语的主题聚类,并依据聚类结果选取中心词为关键词。文献[16]利用文本局部结构信息和文本整体的词向量语义信息抽取关键词。文献[17]通过词向量计算词语的相似性,再根据词聚类算法实现关键词抽取。文献[18]利用Word2Vec词向量实现相似词语的聚类,通过计算距离质心最远的词来更新概率转移矩阵,并将其引入到TextRank词图的迭代计算过程中优化关键词抽取效率。
综上所述,在TextRank权值分配计算中如何融合外部语义信息是TextRank方法优化的关键。词位置分布加权及LDA主题模型加权等方法均需要对待提取文本进行预处理,但对于不同数据集效果差异较大,而词向量训练与待抽取关键词的文档无关,若利用包含外部语义信息的词向量对TextRank方法进行优化,则可以更好地解决关键词抽取问题。因此,本文采用基于网络图的关键词抽取方法,将词向量计算的语义信息和文本信息融入TextRank计算过程中,先利用BERT模型[19]获取词向量,再使用词向量加权方式优化TextRank中词节点的转移概率矩阵计算,提升关键词抽取效果。
2 融合BERT与TextRank的关键词抽取
在单篇文章中通常具有多个关键词,而这些关键词一般不属于同一个主题,一些学者通过LDA主题聚类进行关键词抽取[6,20],因此结合理论分析和实际应用可知,不同的主题表明这些关键词在语义角度存在明显差异。传统关键词抽取方法通过挖掘词语的共现关系构建词的图模型,并对文档中词语进行综合影响力得分排序实现关键词抽取,从而选择相对重要的词语。该方法很容易将高频率的词语当作关键词,由于多数情况下一篇文档中的某些关键词的词频很低,因此此类关键词容易被遗漏。为此,本文在TextRank方法的基础上,引入关键词的语义差异性优化词节点间的概率转移矩阵计算,并经过迭代计算获取词语在文本中的重要程度,从而完成关键词的综合影响力排序及抽取。
2.1 候选关键词的词图构建
基于TextRank思想将一篇文档转换成词图模型,先把所有已出现的词语去重并作为单独的节点,通过词语的共现窗口决定各个词节点之间的边并构成词图。单篇文档的词图构建过程如下:
1)对文档D进行分句,则D由n个句子组成,即D=[s1,s2,…,sn]。
2)对si∈D进行分词、去停用词和保留重要词性等预处理,生成候选关键词序列si=[w1,w2,…,wn]。
3)对关键词序列进行词图构建G=(V,E),其中:V为候选的关键词节点集合,V={v1,v2,…,vn};E为候选关键词之间的链接集合,E中的边由词的共现关系决定,例如wi、wj在词窗口内共现时会在词图中新增两条有向链接边,即vi→vj和vj→vi。在生成词图后,可利用式(1)计算节点分数:
(1)
其中:In(vi)是其他节点到词节点vi的节点集合;Out(vj)是词节点vj所指向的集合;wji、wjk是两词节点所形成边的权值;S(vi)是节点vi的得分权重;d是平滑因子,其实际意义是词语转移到其他词语的概率,并且可以保证式(1)在迭代计算时能够稳定传递并达到收敛,通常设置为0.85。
利用迭代计算式(1)完成对候选关键词的重要性排序,该过程是一个马尔可夫过程,因此最终结果与词节点的最初权值及边的权值无关,仅与文档中词节点的跳转矩阵相关。传统TextRank方法使用相同的跳转概率表示相邻节点之间的比重。令P(vi,vj)代表词节点vi到词节点vj的跳转概率,利用式(2)计算词节点的转移概率[2]:
(2)
其中,deg(vi)代表词节点vi的度。本文提出一种融合BERT向量的语义信息计算方法,优化TextRank中的权值计算过程。
2.2 BERT词向量的语义加权
词向量是使用向量的形式来表达词语,此类方法中应用较广泛的为Word2Vec模型[12]和BERT模型[19]。Word2Vec模型利用浅层神经网络进行模型学习,将词语映射到相应的高维空间中得到词向量。BERT模型本质是一种可微调的双向Transformer[21]编码器,其摒弃了循环神经网络(Recurrent Neural Network,RNN)结构,将Transformer编码器作为模型的主体结构,主要利用注意力机制对句子进行建模。现有的Word2Vec、GloVe等词向量模型均不能较好地处理一词多义的情况,而BERT语言模型不仅可以生成词向量,而且可以解决一词多义问题。BERT模型结构如图1所示,其中,E表示训练向量,Trm表示Transformer编码器。
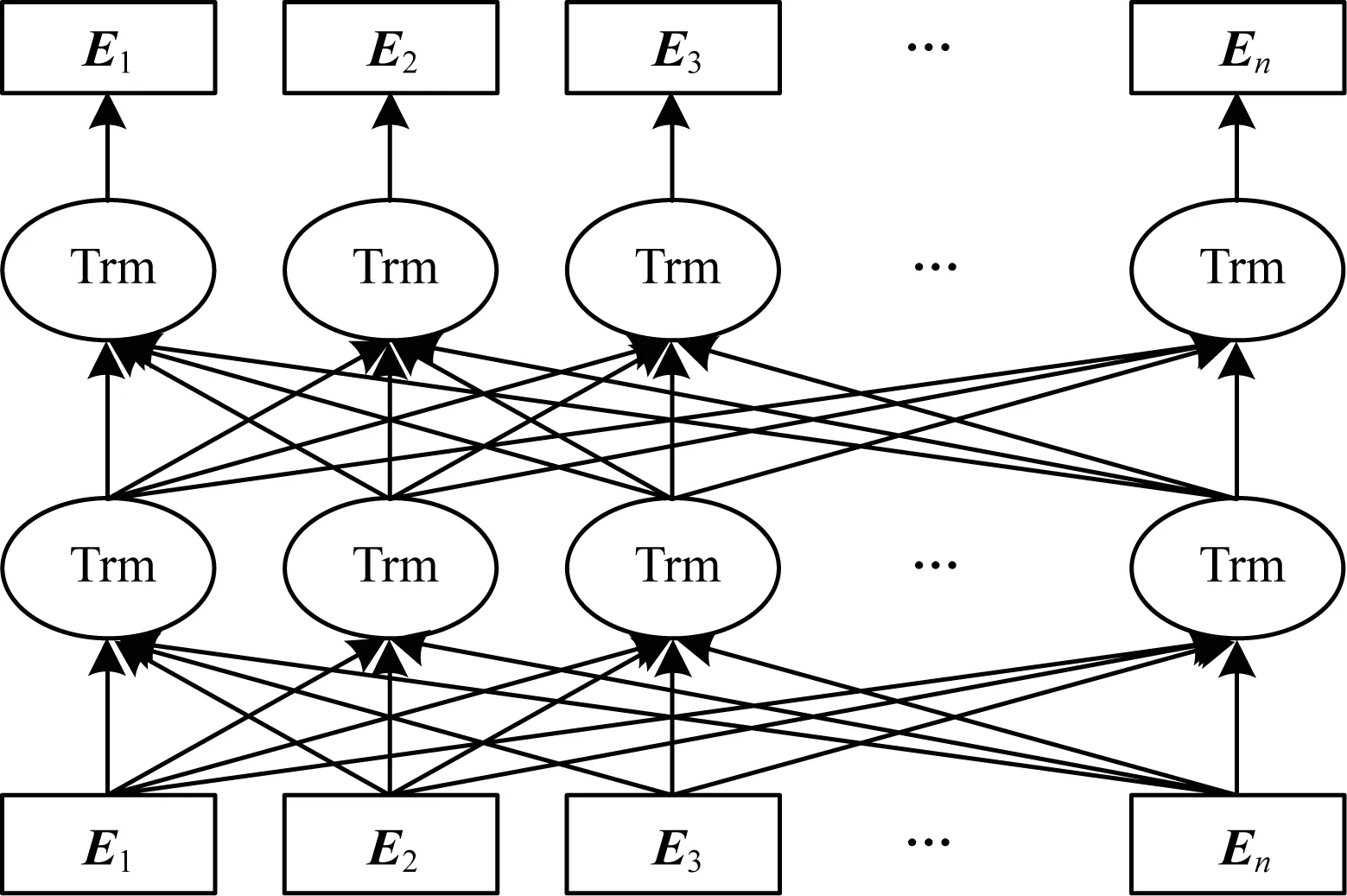
图1 BERT模型结构
BERT将两个句子序列相连并作为模型输入部分,在每个句子的开始和结束位置打上标记符号。对于每个单词,BERT分别进行单词位置信息编码、单词Word2Vec编码和句子整体编码3种嵌入操作。将这3种嵌入结果向量进行拼接获得BERT词向量。相对已有语言模型,BERT是百层左右的深度神经网络模型,其利用大规模语料进行模型参数学习,因此在BERT词向量中融入了更多的语法、词法以及语义信息,同时BERT以字为单位进行训练,在一定程度上解决了Word2Vec面临的未登录词问题。
本文采用BERT向量计算得到外部语义关系并将其融入文档关键词提取中。根据统计发现文档中的多个关键词不一定具有很强的关联性,一篇文档的关键词通常代表不同的文档主题,用于概括文档中心内容,例如利用LDA聚类的关键词抽取方法就是针对一篇文章的多个主题提取关键词并取得了较好的效果。因此,考虑到关键词所属不同主题导致的语义差异性,本文假设在TextRank词语的权值分配计算中,若相邻词节点集中两词节点的语义差异越大,则赋予更高的转移概率且具有更高的跳转权重。本文选用余弦距离表征词语的语义距离,由式(3)计算得到:
(3)
其中,ai、aj表示候选关键词词节点vi、vj的词向量。由于语义差异越大,转移概率越高,因此使用式(4)计算节点vi到节点vj的跳转概率:
Psim(vi,vj)=k-sim(ai,aj)
(4)
其中,k为实验参数,实验中需对sim(ai,aj)进行归一化处理,使得sim(ai,aj)∈(0,1),因此令k=1。
2.3 转移概率矩阵的计算
根据马尔可夫过程可知,节点的重要性得分与候选关键词图的转移矩阵有关。在TextRank节点影响力得分计算中,某个节点对其相邻节点的权重计算主要分为覆盖范围、位置和频度权重三部分[4],令W表示词节点的综合影响力权重,α、β、γ分别表示这三部分权重所占的比重,计算公式如式(5)所示:
W=α+β+γ=1
(5)
在本文实验中的参数设置参考文献[4],令α=0.33、β=0.34、γ=0.33。
借鉴传统TextRank方法,通过式(2)计算得到覆盖范围影响力Prange,而节点位置影响力Ploc由式(6)计算得到[4]:
(6)
其中,I(vj)表示词语vj在文档中的位置重要性权重,根据文献[4]可知,如果vj在标题中出现时,则I(vj)=30,否则I(vj)=1。由于本文实验语料为新闻文体,若考虑新闻中导语位置的重要性,则实验效果将得到显著改善,因此新增权重条件,若vj出现在导语中时,则令I(vj)=10。
根据上文词向量语义加权影响力的定义,将一个节点对相邻节点的权重计算优化为词覆盖范围、词位置和词语义加权影响力三部分。因此,利用式(7)计算得到词节点综合跳转概率:
P(vi,vj)=α·Prange+β·Ploc(vi,vj)+
γ·Psim(vi,vj)
(7)
改进权重转移矩阵M的计算公式为:
(8)
假设矩阵M中的j值代表第j个词节点vj跳转到其他词节点时的比重,例如pij表示vj跳转到第i个词节点vj的比重,其可通过式(7)计算得到,而矩阵M的稳定值则可通过式(9)迭代计算进行确定。
Bi=(1-d)+d×Bi-1×M
(9)
其中,Bi是第i次迭代操作结束时所有节点的综合得分。迭代次数的上限为30,当连续两次计算结果的收敛误差为0.000 1时停止,而每个词的综合得分就是其在关键词词图中的节点影响力得分,根据分值高低对所有词节点进行降序排序,并选取其中前N个词节点作为关键词抽取结果。
3 实验结果与分析
3.1 实验数据
为保证测试数据的客观性和测试结果的可重现性,同时便于对不同关键词抽取方法进行实验对比,本文实验使用搜狐校园算法大赛提供的来自搜狐网站的新闻语料,解析其中的新闻标题和正文内容并将其作为文档集,将事先标记的关键词标签作为文档对应的人工标注关键词组成测试数据集,共选取1 000篇文档数据。本文选择搜狐校园算法大赛数据的主要原因为:1)数据由搜狐提供,保证了真实性;2)搜狐新闻的新闻文章关键词通常经过人工筛选,具有参考性。
本文提出的关键词自动抽取方法采用Python实现,使用Jieba开源工具作为分词和词性分析工具。由于BERT模型对训练条件的要求较高,因此使用Google提供的BERT模型及中文预训练模型文件(词向量维度为768)。
3.2 结果分析
实验使用准确率(P)、召回率(R)以及F值(F)来评价关键词抽取效果并进行统计对比,3种指标的计算方法如式(10)~式(12)所示:
(10)
(11)
(12)
实验分别抽取N(N取1~10)个关键词作为自动抽取的关键词与数据集中人工标注的关键词进行对比。实验对比方法有:1)TF-IDF,传统词频逆文本频率关键词抽取方法;2)TextRank,传统TextRank关键词抽取方法[2];3)M1,利用Word2Vec进行词向量聚类的关键词抽取方法[17];4)M2,基于词向量聚类质心与TextRank加权的关键词抽取方法[18];5)BertVecRank,本文提出的关键词抽取方法。
结合表1与图2可以看出,对文档进行关键词抽取时,TextRank方法明显优于TF-IDF方法,抽取效果更稳定。从F值可以看出,直接利用词向量聚类进行关键词抽取的M1方法相比M2方法效果略差,而将距离词向量质心越远、权重越高的词作为关键词的M2方法的抽取效果相对更好,表明关键词差异性有助于提高关键词抽取效率,但由于其计算聚类中心时受到外部词向量计算的影响较大,因此聚类效果与BertVecRank方法存在一定差距。本文使用词节点及其邻接节点直接进行差异比较,利用BERT词向量加权方式计算概率转移矩阵,以减少质心计算误差对聚类结果的影响,并且增加了不同主题词间的跳转概率,具有较好的关键词抽取效果。
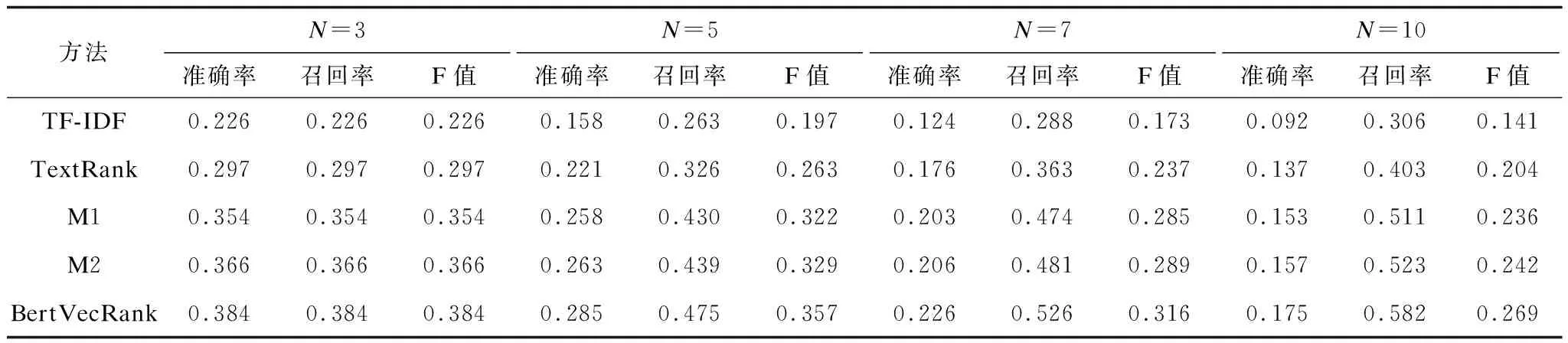
表1 5种关键词抽取方法的性能对比

图2 N取值为1~10时5种关键词抽取方法的准确率、召回率和F值对比
在表1中,当N=3时,不同实验方法的准确率、召回率和F值基本相同,在实验过程发现由于抽取语料中人工提取的关键词平均个数为3,因此导致关键词为Top3时的准确率、召回率和F值基本一致。当关键词为Top3时,BertVecRank方法与M2方法的F值均为最优,BertVecRank方法比M2方法的F值提高1.8%。当N取3、5、7和10时,BertVecRank方法的平均F值比M2方法提升2.5%,并结合图2中F值可知,当BertVecRank方法抽取的关键词数量大于Top3并不断增加时,F值与其他方法相比具有明显优势,说明BertVecRank方法抽取出的关键词整体排序靠前,改进效果明显。由图2可看出,当关键词为Top1~Top10时所有方法的准确率、召回率和F值变化情况,其中BertVecRank方法的准确率整体高于其他方法,并且其召回率与其他方法的差距不断增加。可见,本文利用BERT词向量获取外部语义信息,并结合关键词间的差异性加权明显提升了重要关键词的抽取效率,因此BertVecRank方法的整体抽取效果最佳。
4 结束语
关键词抽取是快速获取文档核心语义的重要技术,是自然语言处理和信息检索等领域的重要组成部分,具有较高的理论和应用价值。本文提出一种融合BERT语义加权与网络图的关键词抽取方法,利用BERT词向量获取外部语义信息,并结合关键词间的差异性加权提升重要关键词的抽取效率。实验结果表明,当关键词为Top1~Top10时,本文方法的抽取准确率整体高于TF-IDF、TextRank、M1和M2这4种对比方法。后续将利用神经网络方法提取文档的结构信息特征,进一步优化关键词抽取效率。
