中国教育实证研究中的定量方法:五年应用述评
2020-09-17吕晶
吕 晶
(华东师范大学教育学部,上海 200062)
一、引言
回溯教育科学的发展历程,其每一次重大突破,都离不开研究方法的发展。教育调查方法的进步,使教育调查受到重视并逐步走向规范;教育测量方法的进步,使各种客观标准化测量迅速兴起;教育统计方法的进步,使教育研究向定量化、科学化跨进了一大步。“工欲善其事,必先利其器”,要提高教育科研水平,就必须掌握合适的研究方法。定量和质性研究方法是教育科学研究中最主要的两大类研究方法。其中,定量研究方法主要服务于教育实证研究中的定量研究或混合研究,是对实验性数据、观察数据和挖掘数据进行统计分析,对理论假设进行检验的过程中所应用的一系列数学、统计学方法的统称。建立在实证数据基础上的定量研究方法具有客观性、准确性和可预测性,为教育研究走向科学化奠定了基础,也越来越受到国内外教育研究者的重视。
定量研究方法被越来越广泛地应用于教育实证研究中是符合社会科学的一般发展规律的。社会科学是研究并阐述各种社会现象的特征及其发展规律的科学。而探索社会现象的特征及其发展规律又需要依靠反映社会现象量的概念抽象和反映社会现象质的概念抽象。相比于质的概念抽象,量的概念抽象更直观、客观和具体,且往往为质的概念抽象提供科学基础。换句话说,在没有量的事实依据情况下所进行的质的研究往往不会被人们当作科学论断所接受。虽然不是所有的社会现象都可以定量地描述,但总体上,相较于质性描述,定量描述能更客观、科学地反映社会现象的特征和发展规律。由于量的概念抽象需要依靠定量方法来实现,现代社会科学研究正在完成一个由以质性研究方法为主向定量研究方法为主且质性、定量研究方法相结合的过渡,社会科学发展的一般规律也是随着研究的深入,其定量化水平越来越高(佟庆伟,2004)。
定量研究方法在20 世纪30 年代被引入中国教育领域后,逐渐引起重视。尤其是2015 年华东师范大学教育学部、北京师范大学教育学部、全国教育科学规划领导小组办公室、光明日报教育研究中心共同在全国范围内发起教育实证研究论坛后,定量方法作为教育实证研究的主要方法学范式之一被更多地应用在中国教育实证研究中。袁振国(2017)在《实证研究是教育学走向科学的必要途径》一文中更是强调了定量研究方法、手段和技术是促进教育科学取得突破性进展的关键。然而,目前我国教育科研中使用定量研究方法的频率、水平还是远远低于美国。例如,在美国教育技术领域,结构方程模型、元分析等定量方法被广泛应用在远程教学理论建构、理论综述等方面。相对而言,我国教育技术领域多采用质性方法辅以现代教育媒体技术的研究范式去建构、探索教学理论。另一方面,由于我国很多教育科研人员没有系统地学习过定量研究方法,还没有对教育实证研究中定量方法的应用形成全面客观的认识,所以在应用定量方法时显得力不从心,甚至误用、错用。针对这些问题,刘建设(1999)、黎荷芳(2001)提出定量方法的应用要与研究问题相切合、与质性方法结合使用。有研究更是指出我国教育研究中对定量方法的重视还是不够,还有待加强(谢美华,2005,第33—34 页)。Yue &Xu(2020)随后通过对自1978 年改革开放以来我国教育实证研究中有关定量方法研究的分析,总结出定量研究方法在我国教育领域发展的四个主要阶段,肯定了我国教育研究中定量方法的发展进步,建议再进一步关注教育测量与评价、提高大数据的挖掘和利用率、增强研究人员的协作和资源共享。然而,这些研究述评多是对统计数据的简单描述与概括分析,针对应用中遇到的具体问题的详细分析几乎没有,更没有针对实际方法误用的纠正,无法切实帮助到具体方法的应用者。
因此,详细梳理、分析定量研究方法在我国的实际应用情况,并尝试对其不足给出较为具体的建议,对定量研究方法在教育领域的发展与成熟具有重要价值。借鉴相关研究,通过综合运用频率统计法、关系网络法、比较研究法、内容分析法,本文以11 本教育综合类中文社会科学引文索引(CSSCI)期刊在2015—2019 年间发表的应用定量方法的论文(仅应用了最基本的频次统计的排除在外)为研究对象,分析总结定量研究方法五年来在我国教育实证研究中的应用现状,并针对具体问题提出对策与建议;整理了一些常见的定量研究方法的误用情况,并针对这些误用给出正确应用建议;分析了定量方法在教育实证研究中的使用趋势。
二、研究方法
(一)研究对象
本研究随机选取了11 本影响因子高于1.00 且排名前25%的教育综合类中文社会科学引文索引(CSSCI)期刊,以这些期刊在2015—2019 年间发表的使用定量方法的论文为研究对象(频次统计除外)。这些期刊包括《华东师范大学学报(教育科学版)》《教育研究》《清华大学教育研究》《中国教育学刊》《北京大学教育评论》《复旦教育论坛》《教育发展研究》《教育学报》《教育科学》《教育研究与实验》和《湖南师范大学教育科学学报》(如表1 所示)。选取综合类期刊是为了从总体角度比较分析教育科学各领域的情况,而排名靠前的CSSCI 论文可以代表目前我国教育领域较优秀的研究成果,更有利于分析定量方法在我国教育实证研究中应用的成熟度和先进度。

表1 选取期刊简介
(二)文献筛选与数据采集
1. 文献筛选
本研究先后进行三次文献筛选。第一轮筛选是在中国知网(CNKI)数据库高级检索设置的检索条件中设置“定量”“量化”“统计”“问卷”“量表”“测量”“实验数据”“观测数据”“挖掘数据”“数据分析”“样本”为关键词、篇名、摘要和全文的共同检索词,即只要论文的关键词、篇名、摘要或全文中出现这些检索词的任何一个就会被检索出来。把发表时间设定为从2015 年1 月1 日到2019 年12 月31 日,初步筛选出4722 篇论文。批量下载这些文章的PDF 版;在第二轮筛选中,粗略地查看第一轮筛选的4722 篇论文,留下有数据的文章,共余2669 篇;在第三轮筛选中,再一次查看2669 篇论文的方法论部分,剔除掉没有应用定量方法的和只应用了频次统计或百分比的论文,剩余1018 篇论文。
2. 数据采集
在CNKI 的4722 篇论文中选择筛选出的1018 篇论文,导出数据,数据导出类型设为“Reworks”。将导出数据上传到CiteSpace,并将“题目、作者、发文机构、关键词、期刊、年份”数据导出为.csv 文件。
(三)文献分析
本研究采用的具体文献分析方法如图1 所示。由于定量研究方法的种类很多且很少被列在目标文献的标题或关键词中,单靠工具软件记录不同方法的应用频率等统计方式,会出现较大偏误。因此,本研究依次浏览1018 篇目标文献的“研究方法”和“研究结果”部分,人工记录具体定量方法和分析工具的使用次数。教育学各领域和署名机构出现的频次则依赖CiteSpace 对关键词和机构的计量分析。作者合作网络也通过CiteSpace 分析完成。2015 年到2019 年各年段的发文量通过Excel 进行统计。

图1 文献分析流程图
三、定量研究方法在我国教育实证研究中的应用现状分析
根据对目标文献的分析,发现全国教育实证研究论坛的召开对重视定量研究方法的应用具有一定的推动作用,这五年来定量方法在我国教育领域的应用越来越广泛。然而,我国教育科学领域在定量研究方法的应用上取得一定进展的同时也存在着诸多问题,并呈现出以下特点。
(一)应用定量研究方法的论文数量增多,但总占比仍然较小
如图2 所示,应用定量研究方法的目标文献数量逐年增加,且每年较上一年的增率都大于3%(2016—2019 年增率分别为4.28%、3.59%、5.45%、3.76%)。由于“全国首届教育实证研究论坛”的召开是在2015 年10 月,所以2015 年的文献量可以当作实证论坛召开前的基准量。由此可见,定量方法的应用比率有一定提高,“教育实证论坛”的开展也加速了学界对定量研究范式的重视。然而,根据朱军文和马银琦(2020)《教育实证研究这五年:特征、趋势及展望》一文中的表6 统计,11 本目标期刊五年间的发文总量为6994 篇,其中实证文献为2434 篇。那么,应用定量方法的研究只占了总发文量的14.56%、占实证发文量的41.82%。作为教育科学研究的主要方法学范式之一,14.56%的总占比说明定量方法在我国教育研究者中的普及度还有待加强,并且将会有很大的提升空间。
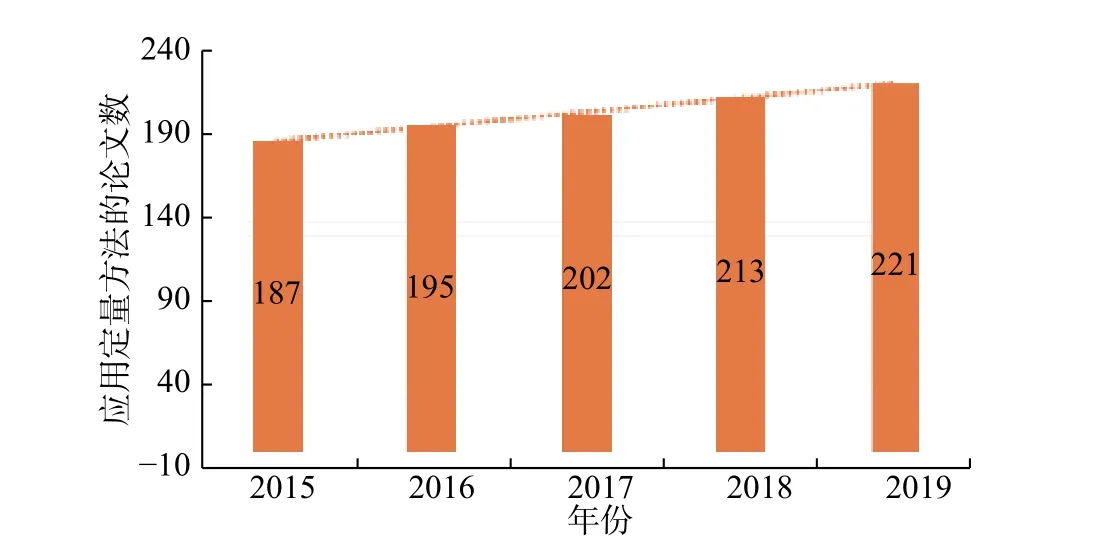
图2 应用定量方法的论文数量
(二)研究团队间沟通较少,学者间存在不稳定的小团体合作
图3 左半边展示了完整的作者合作网络,除了少数团体间存在着密集的合作网络外,大多数团体网络联结密度小、沟通性和互动性差,尤似一盘散沙。图3 右半边展示了随机选取的200 篇论文作者的合作网络,核心作者周边会有些较小较弱的联结,但核心作者之间很少存在联结。说明核心作者倾向于和不同的人合作,但这种合作并不是长期稳定的,且强强联合的研究合作十分匮乏。由此可见,我国教育科学领域研究团队之间的沟通交流不够,知识的传播和分享较差,长久下来将不利于促进整个领域的发展。因此,各大研究机构需要鼓励团队间的合作,争取通过大团队作战获得更突出的成果。
(三)方法涉及面广,但新方法、新技术的引进速度慢
如表2 所示,在目标论文中,最常用的统计分析方法是描述性统计、回归分析、相关分析、方差分析、差异检验等传统定量研究方法。少部分研究运用了结构方程模型(SEM)、因子分析(FA)、多层线性模型(MLM)、元分析(MA)等较为先进成熟的定量方法。元分析结构方程模型(MASEM)、多层结构方程模型(MSEM)、多层元分析(MLMA)等在国际教育科研中运用越来越多的新方法更是没有出现在目标文献中。在辅助分析的工具软件上,绝大多数研究(94.18%)使用了统计产品与服务解决方案(SPSS)和AMOS 软件;极少的研究(5.49%)用到了Mplus 软件、STATA 软件及统计分析系统(SAS)等功能性软件。极个别的研究(0.33%)用到了R 语言、Python 语言等这些国际流行的开源工具。而SPSS 与AMOS 都属于易学易用但处理前沿统计能力相对较差的工具,比如AMOS 由于采用最大似然估计(maximum likelihood estimation,MLE)或加权最小二乘法(WLS)或未加权最小二乘法(ULS)等估计导致处理类别数据、类别潜变量的功能不够完善。如果使用Mplus 就可以较好地处理类别潜变量、类别数据,并提供稳健估计。此外,利用数据挖掘技术(0.27%)、大型调查数据库(4.13%)收集数据的研究也非常少。这在一定程度上说明了我国教育科学研究中方法涉及面广,大多数成熟的方法都有应用,但新方法、新技术的引进、推介速度慢,远远落后于美国等教育强国。研究方法的落后又制约着我国教育科学的发展。因此,各高校教育学院和教育科研院所要更多地吸收、培养专门从事定量研究的人才,开设相关课程,普及量化知识。不仅要吸纳借鉴国际上先进的技术和分析方法,更要融合其他学科的方法、技术作为辅助,在本土、本学科内结合实际应用不断改进新技术、研发新方法。
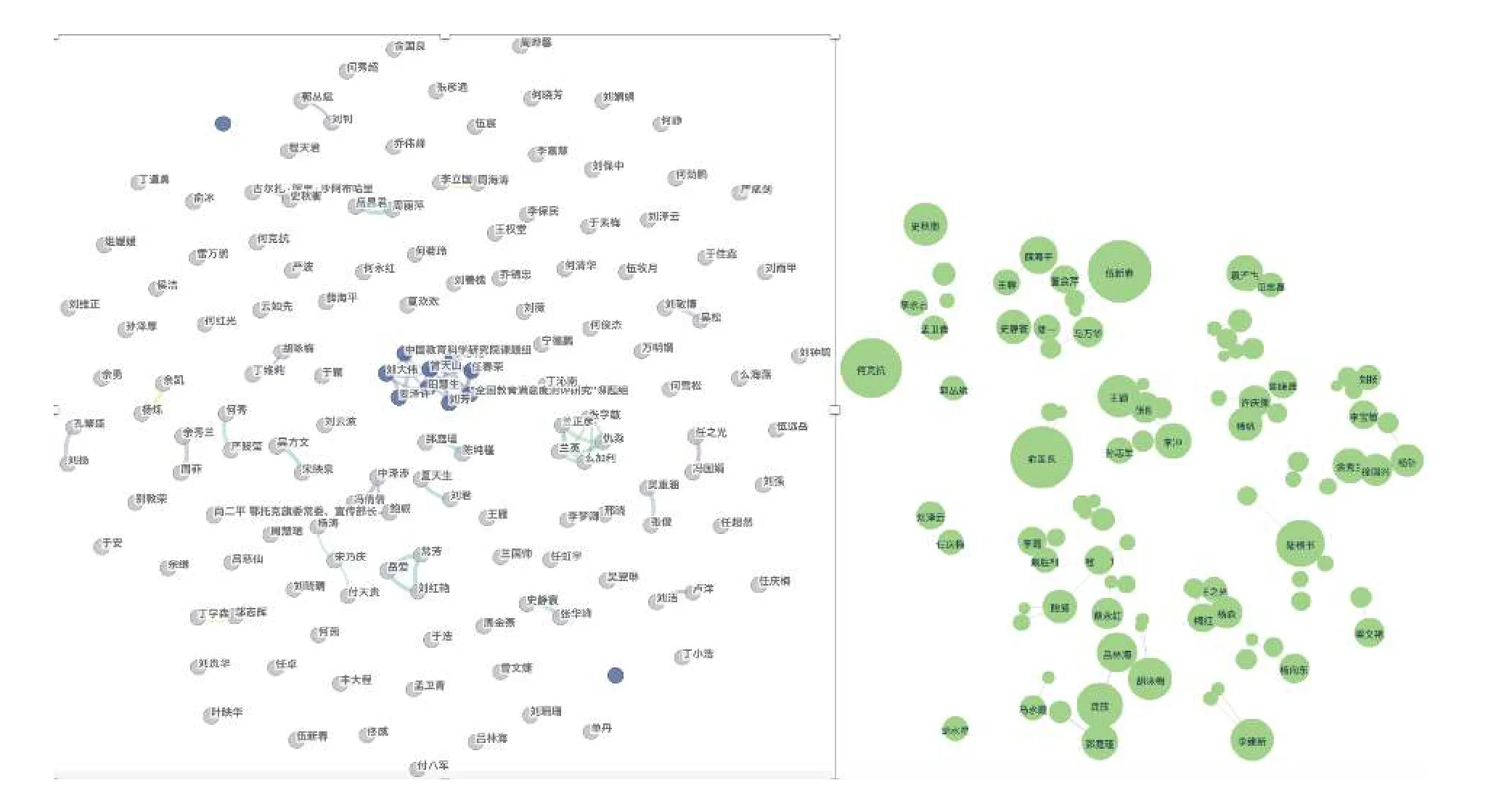
图3 核心作者合作网络图

表2 定量方法和分析工具应用情况
表3 列出了一些国际上常用的但目标论文中较少或从未出现的定量研究方法供教育研究者参考。比如,MLMA、MASEM 和MSEM 这三种在国际上被认为是很有前途的分析方法就没有出现在目标文献中。其中,MLMA 特别适用于总结层次结构数据,它能够检查研究之间的差异、揭示组间异质效应(van den Noortgate & Onghena,2008)。鉴于基于层次结构数据的已发表研究越来越多,使用MLMA 变得越来越重要(van den Noortgate & Onghena,2003)。在目标文献中,有一篇是运用MA 综合不同研究的效应量来分析课外辅导对学生学业成绩的影响效应。有时,一个研究可能既报告每个学生的成绩,也会报告不同班级的整体成绩,那么采用MA 就会忽略文献中可用的一部分研究数据。而MLMA 则能够总结不同班级和学生个体的特定效应大小,在样本量足够的情况下,会给出更详尽的分析。MASEM 结合了MA 和SEM 的优点,是一种强大的方法学工具(Lv & Maeda,2020)。它不仅可以帮助研究者利用SEM 进行理论的定量综述、增强结论的可概括性,还可以帮助研究者测试在单个研究中无法测量的复杂模型。这种方法的应用正在逐年增加(Lv & Maeda,2020),研究人员越来越有兴趣将该方法应用于实证研究。著名期刊《研究综合方法》(Research Synthesis Methods)在2016 年还特别出版了一期关于MASEM 的专刊,讨论了当前MASEM 遇到的问题和对未来研究的建设性意见。相似的,MSEM 是一种广泛应用于多层次研究的先进的SEM 技术(Ryu,2014),用来弥补MLM 和SEM 的缺憾。很多方法论研究也阐述了如何将MSEM 应用在不同的SEM 模型中,如验证性因子分析(Geldhof,Preacher,& Zyphur,2014)、测量和结构模型(Rabe-Hesketh,Skrondal,& Zheng,2007)、中介模型(MacKinnon & Valente,2014)和调解模型(Preacher,Zhang,& Zyphur,2016),并且将其实现方法编码到已有的工具软件中,如Mplus version 5 和Stata version 8,进而引入到社会科学领域的实证研究中。随着其理论和软件包的发展,如今的MSEM 在社会科学领域的使用也越来越普遍(Ryu,2014)。
表3 国际上常用但目标论文中较少或从未出现的定量研究方法

续表3
(四)方法误用情况屡见不鲜
目标文献中有些研究未能根据实际情况来正确选择更合适的定量方法。如某作者收集到的是逐月的追踪数据,在因素回归时把时间当作一个自变量来分析,以预测某学生群体未来成绩。事实上,使用时间序列分析可能就会更合适该研究。需要注意的是,并不是复杂的方法就比简单的方法好,有时复杂的方法不但费时费力,还可能在解决旧偏误、甚至未能解决旧偏误的同时增加新的偏误。分析方法的选择是要以完成研究主题、目的为出发点,在保证分析结果具有高信效度的基础上,尽可能选择相对简单、易于操作的定量分析方法。
另一方面,相当多的目标研究没有对其所用定量方法的适用条件进行考量,而是直接将采集到的实证数据用来跑数学模型、进行统计检验等。从方法论层面讲,所有定量研究方法都有其适用条件,并且不同方法的适用条件存在一定差别。例如,对多元回归而言,当自变量之间的相关性较强时,回归系数的估计就会出现很大偏差、甚至无法进行。只有当回归模型的自变量之间没有密切关系时,多元回归分析的结果才有效。而应用多元回归的几乎所有目标文献都没有完成自变量之间的独立性检验。同样地,目标文献中应用了MLM 的研究也没有对观测数据做任何独立性检验。在MLM 中,虽然数据的嵌套结构并不遵循回归的独立性假设,观测数据的聚类可以有较强相关性,但其也是一种基于回归的分析方法,因而应用MLM 需要对每一层次的观测数据的独立性进行检验。同样情况也普遍存在于其他定量方法的应用中,如方差分析时缺少对观测数据分布状态的检验、修正等。
其他方面的误用导致分析结果出错的情况也同样存在,如使用错误的估计方法,忘记给不同样本数据做加权平均而直接用了平均数,或选择错误的数据收集和处理方法等。再如,在应用FA、SEM 等依赖于大样本量方法的文献中,却发现了小样本量(小于200,且未使用贝叶斯等方法)的存在等。此外,绝大多数存在缺失数据的目标文献都没有在统计分析前对缺失数据进行预处理。然而,由于绝大多数数理运算、估计都是建立在完整数据的前提下,对缺失数据的检测和正确处理是保证分析结果具有高可信度和有效度的前提。
由此可见,在应用特定定量方法前,必须在考虑其适用条件的情况下对实证数据进行检验,并尽量避免因方法的误用而得出错误的结论。因此,教育研究者应努力加强自身定量分析的专业素养,在提高统计分析知识水平的基础上多与定量方法论专家交流合作,以避免在方法设计和应用上出现漏洞、偏差。期刊还应专门邀请从事定量方法论研究的专家参与方法设计等方面的审稿工作,以保证期刊质量,避免错误信息对读者的误导。
(五)不同教育领域间差距大
我国教育研究的各个领域对定量方法的重视程度有所不同,应用频率、成熟度也差别较大。如表4所示,在目标文献中,教育经济学、教育社会学、教育心理学这些偏实验的、收集数据较多的交叉学科领域应用定量方法较多,在方法的掌握上也更为成熟。教师教育、职业技术教育等专业领域对定量方法的应用非常少。教育技术、高等教育等领域虽然对定量研究方法的重视程度不如教育经济学等学科,但也有一定占比,尤其是教育技术领域研究的定量化程度在五年内呈现逐步上升的趋势。此外,在应用定量研究方法的目标文献中,几乎看不到如教育学原理、教育史等教育基础理论领域的研究。

表4 各教育领域每年发文量
教育学各领域间在应用定量研究方法上的这些差异在一定程度上是与各领域的性质相关联的。教育经济学、教育社会学、教育心理学是教育学与数学、经济学、社会学、心理学交叉的学科领域。经济学、社会学和心理学的量化程度相对较高,定量研究方法在这些学科发展的也更成熟,导致教育学与这些学科的交叉学科领域的定量化程度要比纯教育的学科领域好很多。相反,教师教育、职业技术教育是教育学本身衍生出的学科领域,基于定量研究和混合研究在教育学领域的发展较其他社会科学(如心理学、经济学)领域的发展更为缓慢,这些教育学领域在定量方法的应用上也会与其他教育学领域(如教育心理学、教育经济学)有所差距。而教育学原理、教育史这些更偏重哲学思辨的人文领域,往往很难实施测量和收集大量数字化数据,因而更加难以广泛地应用定量方法。
事实上,在定量方法的应用上,这种教育领域间的差距在欧美等国家也是存在的。我国教育学各领域间存在这样的差异也说明定量研究方法的实际应用中虽然存在很多问题,但也没有严重到“滥用”定量方法的地步。我们需要提高教师教育、职业技术教育领域的研究人员的量化素质,同时鼓励教育学原理、教育史等领域采用量化分析辅助哲学思辨,使相关研究更客观、科学。
(六)缺乏定量与质性方法的结合,研究深度不够
目标文献中鲜有定量与质性研究方法的综合运用,多是单一定量研究方法的应用或多元定量研究方法的嵌套应用,很少辅以质性数据的收集和严谨的质性分析。这说明我国教育研究者在方法的使用上常常是把定量和质性研究方法明确划分开的,认为有了定量方法就不需要考虑质性方法,而往往不去关心选定的研究方法对具体研究主题的贡献大小。在某种程度上也说明有些研究者甚至可能是基于研究方法而选择研究主题,而不是基于研究主题进而选择研究方法,本末倒置了研究主题和研究方法的关系。另一方面,绝大多数研究采用定量研究方法的单独应用,从侧面表明了我国教育实证研究有流于表面、研究深度不够的缺憾。
由于定量研究方法是建立在大量实证数据基础上的、针对教育现象的本质或因果关系等做出概括性分析的研究范式,其统计分析结果往往强调教育现象的本质或因果关系等在特定群体中的“普遍性”。然而,教育是一种错综复杂的人文现象(付瑛,周谊,2004),许多个体或小样本群体具有特殊性。虽然定量研究方法逻辑严谨、客观科学,但很难对大样本中的少数特征做精确测量与分析,无法进一步深入研究教育现象。相反,定性研究着重观察、描述个体或少数群体的行为(Mcintyre,2003,p. 15)、感知和交互活动,可以帮助研究者发现教育现象中蕴含的复杂规律。因此,在实际应用中,很多定量研究方法是和质性研究方法混合着使用的,即从定量角度研究教育现象的一般性规律,再从质性角度对教育现象进行深入探究。
例如,某目标研究应用多元回归分析探究了自信心、父母期待、同伴竞争等因素对学生考试成绩的影响。然而,只进行多元回归分析,研究者仅能知道自信心帮助学生提高学习成绩,却无法了解到自信心让学生对学习产生兴趣从而愿意花更多时间来学习。其实,研究者可以采用收敛并行设计补充信息量,研究过程的同一阶段分别使用定量和定性方法,对两类方法进行同等优先级排序,并在分析过程中保持两类方法独立性,然后在分析完成后混合结果、整体解释、得出结论(Creswell & Clark,2018,pp.69−71),即在一个学期里,研究者通过调查问卷收集到有关学生自信心、父母期待、同伴竞争等量化数据,以该学期中的某次综合考试成绩为因变量,应用多元回归分析测出这些因素对学生成绩的影响;并在同一学期中,研究者对部分学生进行焦点小组访谈,以探究自信心、父母期待、同伴竞争等因素是如何具体影响学生成绩的;最后,研究者把多元回归分析结果与对焦点群体进行的质性分析结果相融合,得到相对全面的研究结论。
这种混合应用在美国教育研究中获得了广泛的关注、认可和运用(唐涌,2015)。例如,Greene(2012)阐述了混合研究方法比仅使用纯定量或纯质性研究方法进行研究产生了更有意义的结果。Teddlie & Tashakkori(2012)概述了教育研究者在使用混合研究方法前应考虑的问题。Creswell(2015)出版了有关混合研究方法的工具书。甚至还有诸如《混合方法研究杂志》(Journal of Mixed Methods Research)这种专门发表应用了混合研究法论文的期刊。而定量和质性方法的混合使用虽然被我国不少学者提议(如,高潇怡,2010;向荣,2019;田虎伟,2007;张东辉,2013;邓猛,潘剑芳,2002;张绘,2012),但在实际教育实证研究中的应用范围还有待扩大。建议我国各高校教育学院和教育科研院所以教育研究成果的质量评估为基础和出发点,在政策上鼓励教育研究的深入,从而促进混合研究方法在教育实证领域的应用。
四、定量研究方法误用的纠正建议
正确使用定量研究方法对教育实证研究至关重要,倘若误用,即便是成熟、科学的方法和技术,也会导致结论的错误。本研究通过阅读分析目标文献发现,定量研究论文中存在着诸多定量研究方法误用的现象,如忽略定量研究设计、忽略统计学方法的应用条件、盲目使用统计软件、分析方法不恰当等,影响研究结论的正确性。为改善定量方法误用的现状,下文对目标文献中出现频率较高的方法误用情况进行梳理、分析。
(一)回归分析误用的纠正建议
在教育实证研究中,回归分析这种研究因变量和自变量关系的预测性建模技术常常受到研究者青睐,不同回归建模方法在目标文献中有所涉及,如多分类logistic 回归、二元logistic 回归和分层回归等。虽然很多研究者能够根据研究目标和自变量、因变量类型等选择较为合适的回归分析方法,但由于忽略回归分析的条件限制,仍然存在方法的误用。
例如,某目标研究收集了2473 份关于学生每周花在学生工作与社团活动的时间、是否担任学生干部、大学学业成绩对大学学业排名影响的研究数据。在没有对原始数据进行任何检查和预处理的情况下直接进行多元线性回归分析,且未进行残差分析就得出回归模型构建较好的结论。
缪误1:没有对数据的异常值(包括缺失数据)进行任何预处理。回归分析对异常值(包括缺失数据)较为敏感,如果有异常值存在,不对异常值做任何预处理的话,可能会使估计结果产生偏差。
纠正1:在回归分析前可通过散点图、箱线图、正态图、描述统计等检验数据中是否有异常值(包括缺失数据)的存在。若存在异常值,一般要先把异常值剔除。但如果考虑到实际情况确实无法剔除异常值,则应考虑应用稳健回归建模。
缪误2:没有对自变量的共线性情况进行分析。在实际分析中,自变量之间彼此相关的现象很容易出现在线性回归中。如果一个或多个自变量和其他自变量之间显著相关,则可能存在共线性问题。虽然适度的共线性不会对回归分析造成大的问题,但是严重共线性会导致分析结果不稳定,导致本该显著的自变量不显著、本该不显著的自变量显著,甚至导致回归系数的正负估计与实际完全相反情况。
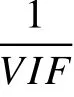
值得注意的是,本例是应用回归模型检测多个自变量对学业成绩的影响情况,因此研究者需要考虑是否处理共线性问题。倘若某个回归模型只是用来预测,那么只要模型拟合指标好,共线性问题通常不会影响预测结果,也不必处理。
缪误3:没有进行残差分析。由于回归模型中的预测值和观测值的差异是随机且不可预测的,那么回归残差(即真实误差的估计)也应该是随机且不可预测的。如果在残差中发现有可预测的信息,则说明回归模型中缺少了某些可预测信息。由此可见,残差分析是回归分析中非常重要的部分。若残差的正态性、独立性及方差齐性假设不能满足,说明回归模型的构建差,回归估计结果不准确。
纠正3:回归分析过程中保留残差项。然后,对残差的正态性、独立性及方差齐性依次进行检验。残差的正态性可使用正态图等进行检测,若残差整体上满足正态性,说明模型构建好,若残差正态性差,说明模型构建差,需要重新构建回归模型。残差的独立性可使用德宾—沃森(D—W)自相关性检验,若D—W 值介于1.7 到2.3 之间(接近2),说明残差独立,模型构建好,若D—W 值小于1.7 或大于2.3(明显偏离2),说明残差自相关,模型构建差,需要重新构建回归模型。残差的方差齐性可通过分别与自变量或因变量作散点图进行检测,若散点没有规律性,说明方差齐性,模型构建好,若散点有明显规律性,说明方差异质,模型构建差,需要重新构建回归模型。
(二)t 检验误用的纠正建议
在目标文献中,常用独立样本t 检验或配对t 检验来比较两组数据间的差异(几乎很少出现应用了单样本t 检验的研究)。即便大多数研究能够根据比较样本等具体情况适当选择独立样本t 检验(两比较组样本量不同)或配对t 检验(两比较组样本量相同),但不少研究在t 检验过程中仍存在问题,影响分析结果的可靠性。
例如,某目标研究采用t 检验(未说明t 检验的类型)比较不同类型学校支持对抑郁大学生心理健康干预的差异。在该研究中,实验组有男生24 人,女生26 人,实验组干预前的总体均分是189.72(SD=58.07),实验组干预后的总体均分是165.18(SD=47.73),且不存在干预后对同一被试得分的重复测量。该研究用t 检验对比了实验组干预前和干预后的总体得分情况。
缪误1:没有交代清楚所应用t 检验的类型。不同类型t 检验过程是不同的。如独立样本t 检验是以t 分布为基础,用于检验两个独立样本总体均值是否相等,即H0: µ1=µ2是否成立;而配对t 检验用于检验两个关联样本的总体差值均值是否为0,即H0: d¯=0是否成立。因此,两种检验方式得出的结果也会有些许差别。
纠正1:在本例中,实验组干预前和干预后的样本都是实验组原样本(自身配对),实际上两个样本的个体是两两配对的,只有50 个独立个体。只有采用配对t 检验,把每组配对当作一个单位进行统计检验,才能确保结果的可靠。而原文中未交代清楚具体t 检验的使用情况,降低了分析结果的信度。
例如,某目标研究采用独立样本t 检验比较大学生直系亲属中是否有人吸毒对贝克抑郁量表(BDI)得分的影响的差异。在该研究中,直系亲属中有人吸毒的样本量为10,BDI 得分均值为5.20(SD=4.39);直系亲属中无人吸毒的样本量为2778,BDI 得分均值为5.83(SD=6.31)。除了平均数、标准差外,在独立样本t 检验前,研究者未对两组数据做其他统计学分析。
缪误1:忽略了独立样本t 检验对样本正态性的要求。在本例中,直系亲属中有人吸毒的样本量为10,对独立样本t 检验而言,若是小样本,则要求样本的总体必须服从或近似正态分布。由于本例中直系亲属中有人吸毒的样本量过小,仅靠提供的均值与标准差无法判断该样本的总体是否服从或近似正态分布(t 检验对正态性稳健)。
纠正1:鉴于本例中的样本量较小,在进行独立样本t 检验前先要检验样本的正态性。如果数据不呈正态或近似正态分布,可以使用非参数检验。或可以先通过算法转换把原始数据转换,使之服从正态或近似正态分布后再进行独立样本t 检验。如果原始数据转换后仍不能呈正态或近似正态分布,再使用非参数检验替换独立样本t 检验,来分析数据。但数据转换可能引起BDI 得分和对直系亲属中是否有人吸毒关系的估计偏误,因此不建议使用数据转换法。
缪误2:忽略了独立样本t 检验对方差齐性的要求。独立样本t 检验要求两组样本的总体方差齐性。在本例中,直系亲属中有人吸毒的BDI 得分均值为5.20(SD=4.39),直系亲属中没人吸毒的BDI得分均值为5.83(SD=6.31)。两样本的标准差有一定差别,可能出现方差不齐现象。
纠正2:在本例中,两样本的总体可能出现方差不齐现象,因而需要对两样本数据进行方差齐性检验。如果方差不齐,则采用Wilcoxon 秩和检验、或近似t 检验方法替代独立样本t 检验,进行分析。
(三)方差分析误用的纠正建议
三组或三组以上样本的差异性检验需要用到方差分析这种重要的处理多元信息的分析方法。但在部分目标文献中,不同的方差分析方法却被混淆误用,致使所采用的方差分析模型与研究设计不匹配,得出的结论出现较大偏误。
例如,某目标研究采用多个单因素方差分析分别比较我国不同区域幼儿园物质条件、师幼互动、健康与安全及幼儿发展的差异。在该研究中,各地区个案数及分析结果如表5 所示。研究者对东中西部地区的数据进行了方差齐性检验、事后检验,但未做正态性检验。
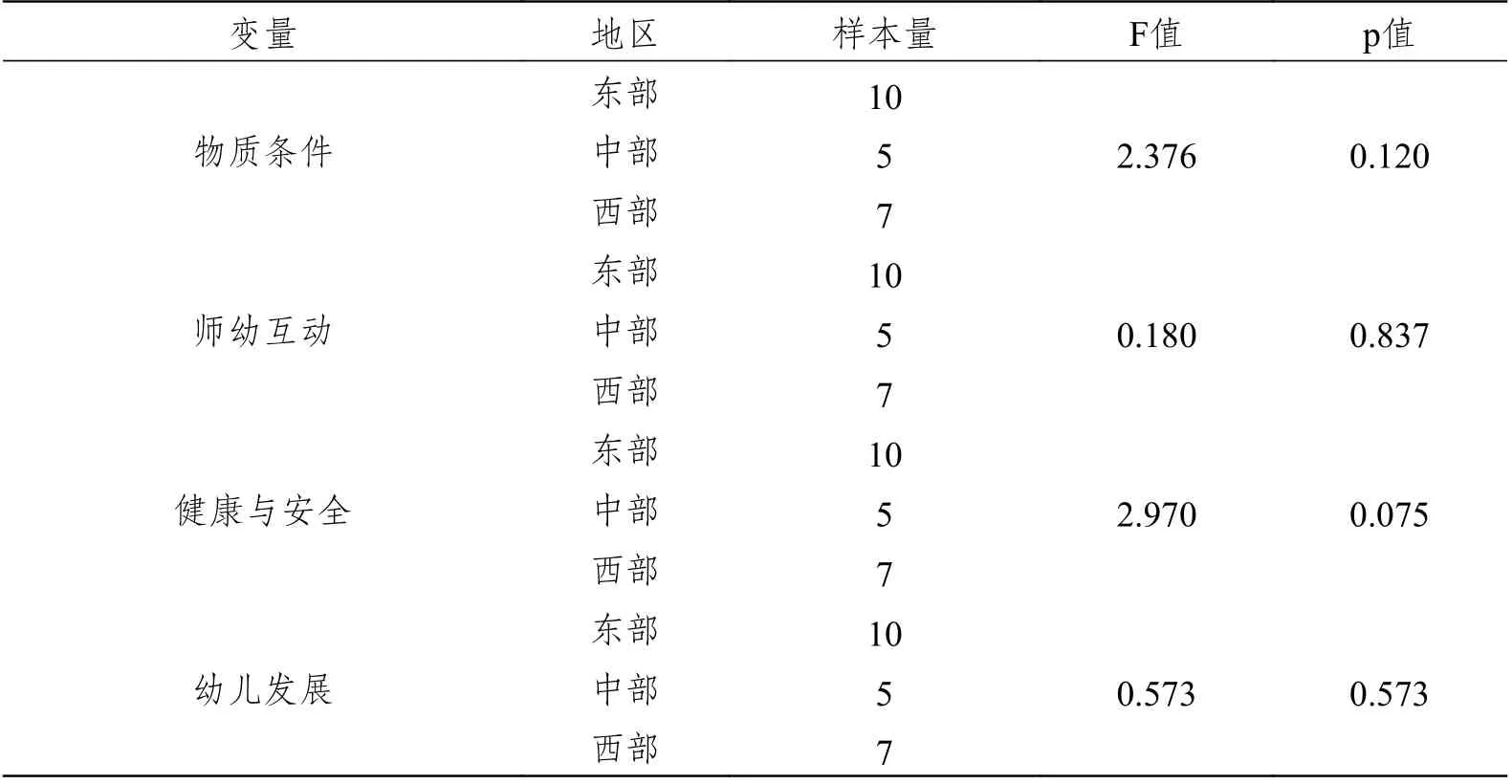
表5 不同区域幼儿园的比较分析结果
缪误1:未检验方差分析的适用条件。在本例中,东部样本量10 个、中部5 个、西部7 个,虽然是三个独立样本且方差齐性,但样本量过小,各种数据很可能不服从正态或近似正态分布(方差分析对正态性稳健),可能不满足方差分析的适用条件。
纠正1:在进行方差分析前,应先对各个样本数据进行正态性检验。但由于每组样本量过小,很难直接对每组因变量进行正态性检测,研究者可以选择合并检验因变量残差的正态性。如果残差不呈正态或近似正态分布,可以转换数据使其残差服从正态或近似正态分布,或使用非参数检验替换单因素方差分析。
缪误2:方差分析方法选择有误。多个因变量可能是相关的,可能更适合应用多元方差分析。在本例中,幼儿园物质条件、师幼互动、健康与安全及幼儿发展间很可能存在相关关系,本例更适合使用多元方差分析。
纠正2:类似本例情况,鉴于方法的简便性,大多数目标研究都应用了单因素方差分析。但是,如果因变量间存在相关,使用单因素方差分析会忽略因变量之间的相关关系,导致犯Ⅰ型错误的概率变大、检验效率低,即拒绝了实际上成立的、正确的假设。尤其当各个因变量的单因素方差分析结果不一致时,难以对分析结果下总体结论。因此,本例应先检查各因变量(幼儿园物质条件、师幼互动、健康与安全及幼儿发展)之间是否具有显著的相关性,如果相关,推荐采用多元方差分析,如果不相关,则可采用单因素方差分析。
例如,某目标研究采用重复测量方差分析探索学生从小学到大学元认知控制的准确性和一致性是否随着年级升高而逐渐提高。在该研究中,研究者采用2(时间:前、后测)×6(学段:小学一、三、五年级,初中、高中、大学)混合实验设计。样本量为345 名不同学段的学生,时间和学段为自变量,重读选择为因变量。在进行重复测量方差分析前未对数据进行任何检验。
缪误1:没有进行一般方差分析的条件检验,更没有检验协方差矩阵的球对称性。重复测量方差分析除了要满足一般方差分析的条件(即独立性、正态性、方差齐性)外,还需要满足协方差矩阵球对称性。如果协方差矩阵球对称性得不到满足,会增大犯Ⅰ型错误的概率。
纠正1:在确定数据满足独立性、正态性和方差齐性后,用Mauchly 方法检验协方差矩阵的球对称性。如果协方差矩阵的球对称性得不到满足,则需要对与时间有关的F 统计量的自由度进行调整,以降低犯Ⅰ型错误的概率。一般采用Greenhouse-Geisser(G-G)法、Huynh-Feldt(H-F)法和Lower-Bound(L-B 下界)法对自由度进行调整。最后根据原F 值和调整后的自由度,判断时间或学段的主效应、时间和学段的交互效应是否显著。
(四)卡方检验误用的纠正建议
卡方检验在目标文献中的应用也十分广泛,其使用频率仅次于回归分析、t 检验和方差分析、结构方程模型、因子分析,主要用于分类资料间的比较。虽然对分类变量的统计常常需要用到卡方检验,但卡方检验在对分类变量的频数分布分析上并不是万能的,因此目标文献中也或多或少地出现了误用、乱用卡方检验的情况。
例如,某目标研究采用卡方检验比较分析不同办园体制下幼儿园的教师资质。其分析结果如表6所示。研究者得出“不同办园体制普惠性幼儿园在教师学历、教学年限、职称上均呈现出显著差异,且普惠性他办园的师资水平在多个维度上优于教办园和普惠性民办园”的结论。

表6 不同办园体制幼儿园教师资质的比较分析结果
缪误1:误用卡方检验分析数据。在本例中,研究者想要比较不同办园体制普惠性幼儿园在不同师资水平维度上是否有差异,并判断出孰优孰劣。然而,运用卡方检验仅能回答不同办园体制普惠性幼儿园在不同维度师资水平“分布”上的差异是否在统计学上呈现显著状态,无法判断出“他办园的师资水平在多个维度上优于教办园和普惠性民办园”。
纠正1:由于本例中的因变量是等级变量,因此可以使用非参数检验,如秩和检验或Ridit 分析,来比较不同办园体制普惠性幼儿园在师资水平的不同维度上是否有差异和孰优孰劣。
例如,某目标研究采用卡方检验考察不同性别和民族大一新生的抑郁状态等级构成的分布是否有差别。其分析结果如表7 所示。

表7 大一新生抑郁情况
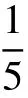
纠正1:每个2×4 列联表中都有两个格子的理论频数小于5 且大于1,应该使用Fisher 确切概率法替换卡方检验。
例如,某目标研究采用卡方检验探究在就业和创业两种情境下,不同调节定向被试决策偏好的差异。其分析结果如表8 所示。进一步对数据卡方检验后得出,预防定向被试的就业选择显著高于促进定向被试的就业选择( χ2=4.30,p<0.05),促进定向被试的创业选择显著高于预防定向被试的创业选择( χ2=8.73,p<0.01),促进定向被试在就业和创业选择中不存在显著差异( χ2=1.00,p<0.05),预防定向被试的就业选择显著高于其他创业选择( χ2=33.64,p<0.001)。

表8 两种情境下不同调节定向被试的决策偏好差异
缪误1:滥用卡方检验或卡方分布分析数据。不论是用卡方对拟合度进行检验,还是对变量的独立性(即分布的差异)进行检验,都不适用于本例。在本例中,研究者试图比较同一决策情境下不同调节定向的优劣,无法应用卡方检验得出。更严重的问题是,一般情况下,仅靠两组实际频数(理论频数)算不出卡方检验值。因此,本例中的研究者具体应用了什么方法得出的卡方值还有待商榷。
纠正1:根据本例的数据情况,只能得出同一决策情境下不同调节定向的数理频数孰高孰低,无法在统计检验层面上得出有关差异的显著性结论。
(五)探索性因子分析(EFA)误用的纠正建议
探索性因子分析(EFA)主要用来探索观测数据的基本结构,多应用在量表开发的过程中。EFA 在目标文献中的应用也有一定的占比(约5%),且越来越成熟。然而,研究者误用EFA 的情况却时有发生,导致其研究结果缺乏可信度、甚至错误。
例如,某目标研究采用EFA 对《博士生学术经历量表》进行探索性因子分析,以提炼出构念维度。在本例中,测量工具《博士生学术经历量表》采用4 级计分方式,共收集到有效问卷188 份,应用SPSS 软件分析数据。在探索性因子分析过程中,研究者“使用‘最大方差法’进行正交旋转,项目选取标准为因子负荷大于0.45,因子提取标准为特征值大于1。最终在删除5 道题后得到一个包含5 个因子的稳定因子结构(KMO=0.82,累积解释变异量为72.1%)”。其分析结果如表9 所示,该研究并未做出有关该探索性因子分析过程的其他描述。
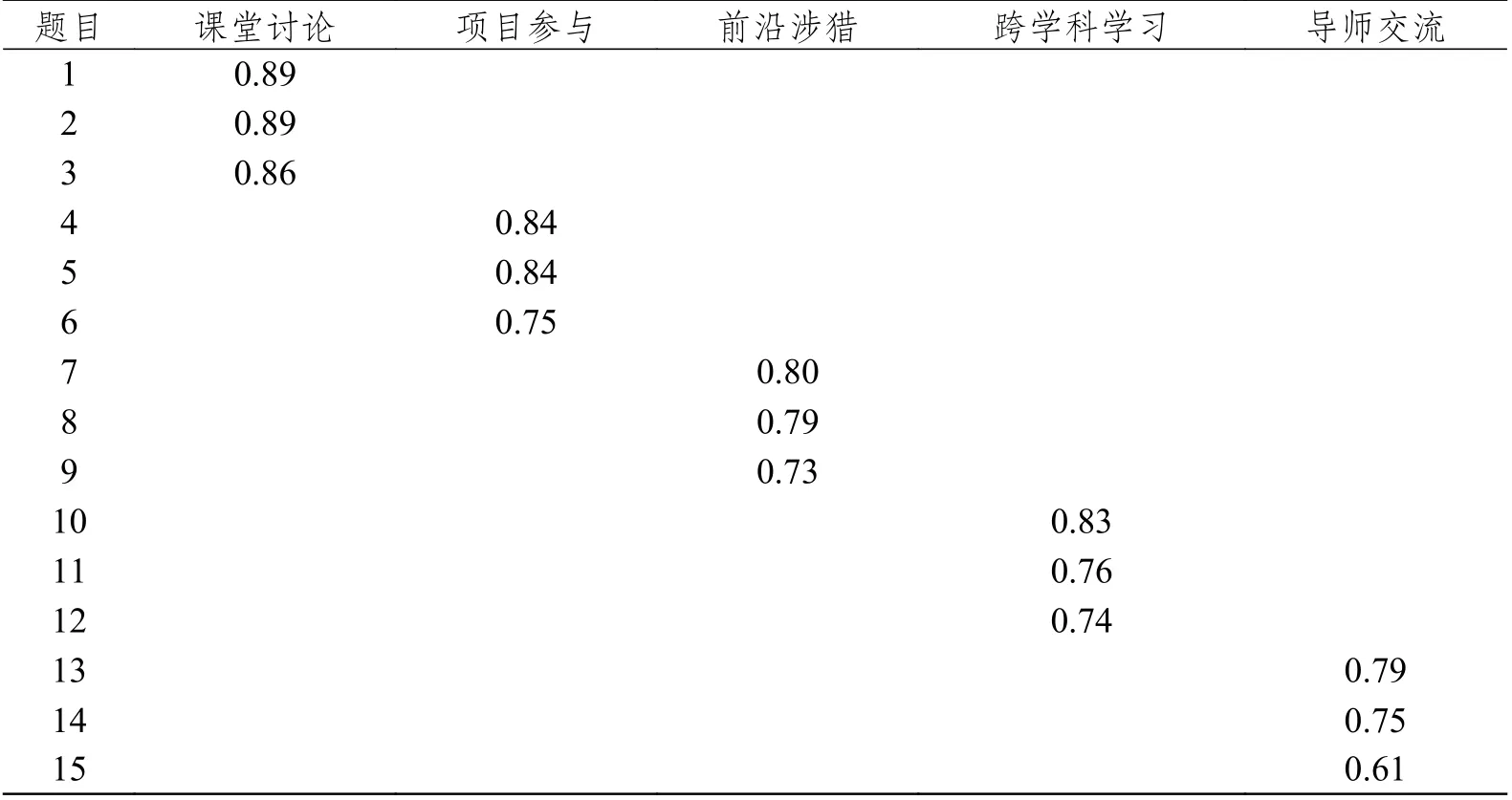
表9 因子提取结果
缪误1:忽略EFA 的适用条件。EFA 很重要的一个应用前提是要求观测变量之间存在模式化关系,且不存在多重共线性问题。这就需要研究者在分析前,首先获得所有变量的相关矩阵(或协方差矩阵),以检验是否有变量缺少模式化关系,或是否存在问题项导致多重共线性问题,并通过Bartlett 球形检验确定变量间的模式化关系,及KMO 测度确定是否适合应用EFA。但在本例中,研究者并没有进行这些分析,而是直接报告EFA 分析后的KMO 值(KMO 测度应当在EFA 分析前进行)。
纠正1:在正式分析前,先算出所有变量的相关矩阵(或协方差矩阵)。如果存在变量具有大量低相关系数(−0.30<r<0.30),则表示这些变量缺少模型化关系,需要进行删除处理。如果相关矩阵中存在r>0.90 或r<−0.90 的情况,说明数据可能存在共线性问题,需要使用Haitovsky 检测是否存在多重共线性问题。如果存在多重共线性问题,则需要确定导致多重共线性问题的变量并将其删除。然后,通过Bartlett 球形检验来确定变量(剩余变量)间确实存在模式化关系。最后,通过KMO 测度进一步确定EFA 是否可应用于本例。如果KMO 值大于0.50,则表示EFA 可适用于本例。如果KMO 值小于0.50,则意味着数据无法产生显著而可靠的因素,EFA 不适用于本例。
缪误2:忽略因子提取方法的选择。在SPSS 中有七种因子提取方法供选择,包括“主成份法”“未加权最小二乘法(ULS)”“广义最小二乘法(GLS)”“最大似然法(ML)”“主轴因子提取法”“ α因子提取法”和“映像因子提取法”,且这些因子提取方法提供的结果稍有不同。需要注意的是,“主成份法”不是一种探索性因素分析方法,而是一种减少拒绝测量误差维度的方法,一般用于主成分分析(PCA)中,不应用于EFA 分析中。研究者需要根据研究目的、数据的基本情况及对采用拟合优度指数的兴趣,选择合适的因子提取方法。在本例中,研究者没有交代使用了具体哪种方法来提取因子。
纠正2:在该例中,测量工具《博士生学术经历量表》采用4 级计分方式,属于类别变量(5 点或以上的李克特量表的变量才可当作等距变量处理)。ULS 或加权最小二乘均值和方差调整(WLSMV)都可用在基于类别变量的EFA 分析中,且WLSMV 是更优的选择(Muthén,du Toit,& Spisic,1997)。由于SPSS 中没有WLSMV 方法的设置,因此,在SPSS 中,对于类别变量,建议使用ULS 方法。如果研究者应用Mplus 作分析,则最好使用WLSMV 方法。
缪误3:忽略选择正交旋转的前提条件。正交旋转的前提条件是因子间不相关,而斜交旋转则允许因子间存在相关。在本例中,研究者并未给出因子之间的相关关系,因而无法判断因子间是否存在相关。如果“项目参与”与“前沿涉猎”“跨学科学习”“导师交流”间存在相关,那么进行正交旋转会忽视这些因子间的相关,对分析结果造成影响。
纠正3:首先检查一种常用的斜交旋转方法产生的解。斜交旋转后,会得到三个基本结果,即因子模式矩阵、因子结构矩阵和因子相关性矩阵。如果因子相关性矩阵中因子间的相关较低,那么可以进行最大方差法正交旋转。如果发现其中一些因子相互关联,那么应当采用斜交旋转。需要注意的是,当采用斜交旋转后,若发现因子间的相关较高(r>0.60),那么因子模式矩阵和因子结构矩阵可能会有显著差异。在这种情况下,建议报告两种矩阵结果,或者明确说明报告的载荷是因子模式系数还是因子结构系数。
另外,在本例中还存在着其他缺陷。本例没有交代是否具有或如何处理极端值(包括缺失数据)。也没有交代清楚删除5 个观测变量的原因,是因子载荷小于0.45 或是有显著交叉载荷的存在,应明确说明的信息没有完整提供,会降低研究结果的说服力。
(六)结构方程模型(SEM)误用的纠正建议
结构方程模型,包括验证性因子分析(CFA),是一种基于变量的协方差矩阵来分析变量间关系的多元统计方法。近五年在目标文献中的应用逐年增多,2015 年占比约8.5%到2019 年占比约12.3%。但是,部分研究者由于对SEM 的基本原理理解不够透彻而误用了该统计方法,导致结论出错。
例如,某目标研究采用SEM 分析教师满意度、教育期望、政府保障和学校支持的关系。在该研究中,样本量为8150(并未对数据进行检验),测量工具采用7 点量表,估计方法选用极大似然(ML)估计,分析软件是AMOS17.0,初始模型建立如图4。
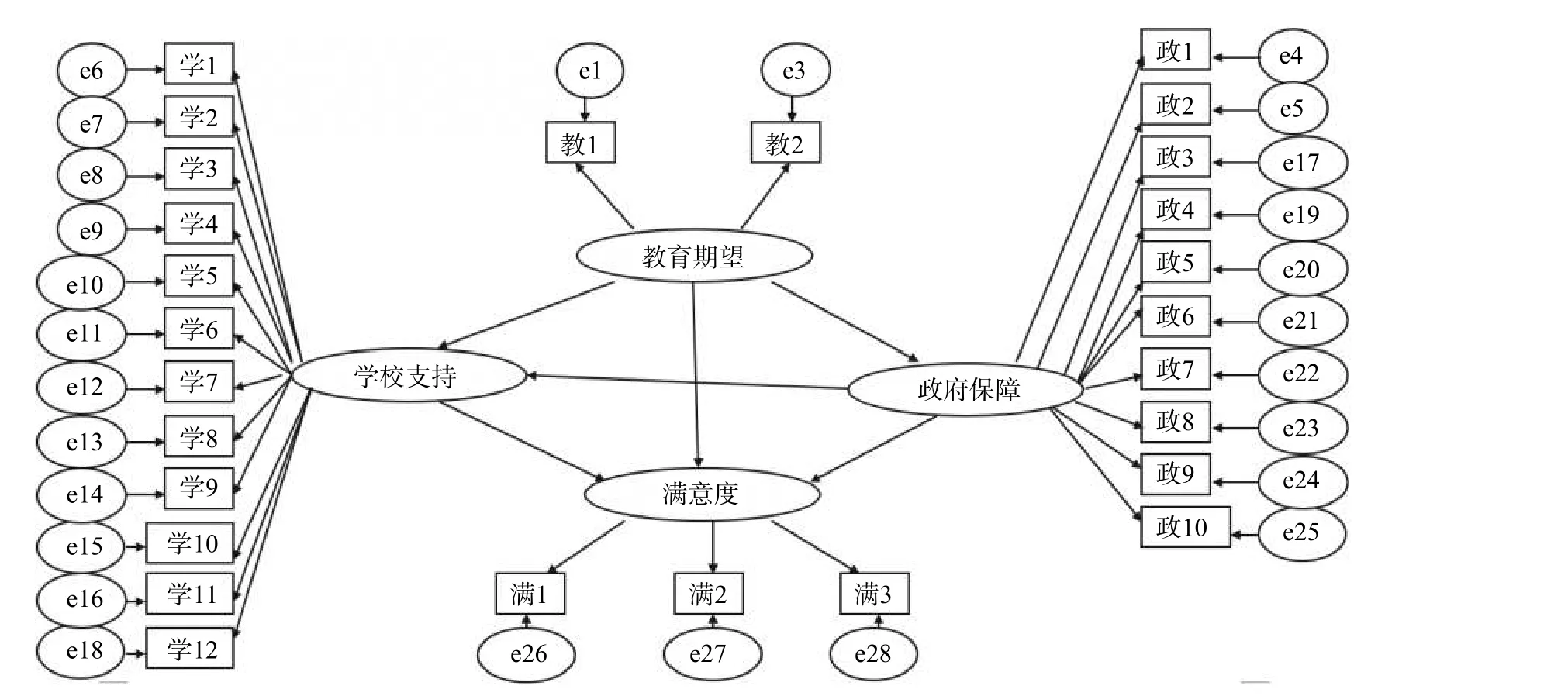
图4 初始模型
初始分析得到27 个题目的路径系数均显著。总体来看,模型拟合度较好,但是部分拟合指数未达基本要求。根据模型修改建议,研究者通过增加[e12~e13]、[e15~e16]、[e16~e17]、[e6~e7]这些M.I.值大于20 的残差路径,最终得到拟合度更好的模型。模型修正前后拟合度情况如表10 所示。

表10 模型修正前后拟合度情况
缪误1:忽略多元正态分布的前提条件。为获取准确的参数估计值和稳定可靠的分析结果,SEM 要求样本量足够大且观测变量应当服从多元正态分布。如果数据违背多元正态分布假设,那么采用ML 估计方法就会增大犯Ⅰ型错误的概率,更可能拒绝实际上建构良好的模型。在本例中,虽然样本量足够大,但仍不能保证所有观测变量服从多元正态分布,研究者未作数据分布检验是不恰当的。
纠正1:在本例中,7 点量表数据可以当作是连续数据处理。在进行SEM 分析前,应首先对数据进行多元正态性分布检验,诸如R 语言、SAS 软件、Python 语言、STATA 软件均提供了多元正态性分布检验。如果数据不符合多元正态性可使用任意分布估计方法、或用S-B 调整法调整基于正态理论的模型检验统计量和参数标准误、或通过数据转换使数据分布正态化。但是数据转换后再分析得到的因子载荷不再是原观测变量的数据载荷,对估计参数的解释应当按照新的测度进行。
缪误2:模型存在局部过饱和问题。模型的局部过饱和现象是指模型局部的自由度为负值。当模型局部存在过饱和现象时,模型局部的参数估计随意性大且不可信,却往往能在模型的总体拟合指数上得出不错的结果。而在本例中,潜变量“教育期望”下只有两个观测变量,其局部自由度为−1(3−4=−1),存在模型局部过饱和问题。
纠正2:为了保证SEM 分析结果的高可靠性,研究者需要对原始模型进行修改,即增加潜变量“教育期望”下面的观测变量数目,使其不少于3 个。
缪误3:修正模型存在较严重的测量误差相互关联问题。在本例中,作者通过增加[e12~e13]、[e15~e16]、[e16~e17]、[e6~e7]这些M.I.值大于20 的残差路径,得到拟合度更好的模型。但是,这种允许测量误差在事后关联的理由是不合理的。出现误差相关联的情况实际上是由于有误差相关联的潜变量中仍然存在潜在的分离,即观测变量还有遗漏,或相关的观测变量存在问题。况且[e16~e17]是两个潜变量“学校支持”和“政府保障”下观测变量测量误差的关联,更是不能出现在模型中的。因此,出现较严重的测量误差相互关联的情况说明初始模型的结构存在问题,初始模型成立理论不充分,需要增加或减少观测变量。
纠正3:[e12~e13]、[e15~e16]、[e6~e7]这些测量误差存在相互关联说明初始的假设模型中遗漏了观测变量,研究者可以根据理论分离这些观测变量中的部分变量(即补充遗漏观测变量),或者分别删掉e12 和e13、e15 和e16、e6 和e7 中因子载荷较小的那个观测变量。[e16~e17]属于不同潜变量中的观测变量的误差相关联,研究者应当根据理论重新检查初始模型,决定是删掉目标观测变量或是修正相关观测变量的题目。依据修正指数,在该例中,“学11”这个观测变量可能存在较大问题。不论如何修正初始模型,建立新的模型后,建议研究者用新的独立数据测试新模型。
需要注意的是,SEM 只是一种检验理论的工具,通常在没有充分理论支持的情况下,不建议研究者轻易遵照修正指数调整初始模型。此外,因为该例的样本量足够大,而卡方值容易受样本量的影响,即当样本量足够大时卡方值也会较大,所以卡方值在本例中对判断模型的拟合优度没有太大的意义。
五、定量研究方法在我国教育实证研究中的应用展望
由于定量研究方法起源于自然科学领域,那么其在教育实证研究中的应用除了受到教育学本身发展的影响,也会受到数学、计算机科学等学科发展的影响,将会呈现出跨学科、多元化的发展趋势。以下就从教育科学的发展角度,结合自然科学、技术的发展趋势及国内诸多学者的分析,对定量研究方法在我国教育实证研究领域中的应用进行初步的展望。
(一)从五年发展特点看趋势
1. 定量研究方法将更广泛地被应用
从对五年来定量方法的应用特点的分析可知,定量方法的应用率虽然是在逐年稳步地增加,但是总占比还是很低,未来还有很大的上升空间。因此,随着“教育实证论坛”的继续召开,有关定量方法的普及会继续扩大,必然会有更多教育研究会使用定量方法。
2. 机构间的合作将更频繁和深入
从对五年来作者合作网络的分析可知,我国教育科学领域研究团队之间的合作交流还有待提高。由于本身团队间的合作基数小、合作网络较疏散,所以只要各大研究机构鼓励、重视团队间的合作,未来学者间合作的比例会有较大上升。并且随着研究深入,核心作者间的合作也会逐渐增多,形式也会趋于长久、稳定,团队间的合作网络也会更牢固。
3. 定量研究方法的应用将更成熟
从对五年来定量研究方法应用特点的分析可知,新方法、新技术的引进速度慢,且方法误用屡见不鲜。而“教育实证论坛”的召开和中国教育实证研究“这五年专刊”的举动意味着我国各高校教育学院和教育科研院所已经开始重视普及量化知识,未来也会更加重视吸收、培养专门从事定量研究的人才。学者们一旦对定量方法的应用重视起来,新方法、新技术的引进和研发速度也会增快,方法的误用也会有所改善,其应用也将会更成熟。
(二)从教育科学的发展看趋势
1. 定量研究方法趋向跨学科交叉应用
教育现象本身涵盖的内容会涉及经济、生理、心理等多个学科领域,如有条件的现金转移支付承诺可以改善我国农村贫困学生高中完成情况(易红梅,何婧,张林秀,2019)。教育科学研究要有效地揭示教育现象的本质、解决教育实践中的问题,就需要在跨学科的基础上进行研究与合作。因此,针对教育现象的跨学科研究是教育科学发展与进步的必然趋势。而定量方法在各个学科领域中又都是相通的,它的应用是属于交叉学科范畴。只要研究主题和数据符合要求,一种定量方法可以应用在不同学科中,如回归分析可以应用在研究心理现象上,也可以应用在研究影响经济效应的因素上。在美国,不论自然科学界还是社会科学界对定量研究方法的应用已经相当普遍,并且定量研究方法已经成为跨学科研究的重要工具和媒介。由于我国教育科学领域目前正处在提升研究深度和广度、鼓励学科融合、吸收交叉人才的阶段,那么随着跨学科研究的逐渐增多,定量方法也会被更加广泛地应用在跨学科和交叉学科的教育实证研究中。
2. 定量研究方法趋向多元化、混合化应用
随着教育科学的发展,单一的定量方法很难处理较复杂的教育研究问题,也不容易得到准确客观的研究结论。为了更好地研究教育问题,研究者往往需要多元化应用定量研究方法,而计算机科学技术、统计学、心理学等学科的飞速进步又为定量研究方法的多元化应用提供了工具、方法论和研究范式。如李宪印等人(2019)在研究大学生创新行为的构成因素时综合运用了项目分析、探索性因子分析、验证性因子分析、信度检验和方差分析。更进一步,为适应社会科学发展的需要、深入具体地分析问题,将质性和定量方法相结合的混合研究也逐渐在国际学术界流行起来。比如Lv et al.(2020)在研究正念对抑郁的干预效果的研究中就混合了元分析和叙述性综述两类方法。“全国首届教育实证研究论坛”的召开标志着我国教育科学将进入一个新的历史发展阶段,教育研究将更加关注实证,也更趋向于科学、规范和多元化,教育研究方法的应用也将会更加多元且有混合化趋向。
(三)从自然科学、技术的发展看趋势
1. 定量研究方法趋向大样本化、大数据化应用
云计算、互联网和物联网技术的发展使得社会信息化的程度不断加深,研究者可以利用网络挖掘、大型调查数据库等方式获得大量数据。大样本的使用,既能提高定量分析结果的准确度,又能减少重复工作、节约科研成本,已经被越来越多的学者所青睐,也成为定量研究方法应用的一大趋势。另一方面,随着大规模并行处理数据库、数据挖掘、云计算平台、分布式文件系统等技术的出现,使得通过对全样本进行定量分析从而得到相对理想的分析结果成为可能。同时,我国又将大数据的研究和发展视为新的国家战略之一(何哲,2015),使得教育大数据的应用成为必然趋势。因此,定量方法会越来越多地被用来辅助大数据技术分析教育大数据。需要注意的是,虽然大数据弥补了传统数据的很多缺陷,但是也有其局限性。如由大数据方法获得的总体本身往往存在偏差,会导致分析产生系统性偏误等,因此大数据分析也不能完全取代抽样分析。
2. 定量研究方法趋向“AI+教育”的应用
伴随着人工智能(AI)的不断发展,其在教育领域的应用也愈加广泛,如伴读机器人走入课堂、智能阅卷开始出现等。在2017 年国务院印发的《新一代人工智能发展规划》中明确提出,“实施全民智能教育项目”(国务院,2017),全方位地实现“AI+教育”成为教育领域的理想和目标(吴站杰,秦健,2003)。而将定量方法应用到AI 领域不仅能推动“AI+教育”的发展,还能促进新的定量方法的产生。如研究者可以运用深度学习方法设计并训练出多款辅助教学机器人,把其分给具有相同学习基础和条件的学生使用,然后收集相关数据,通过定量分析找出辅助学习效果最佳的机器人并投入教育市场。再如,分布式计算和AI 技术的发展使得基于Agent 的建模方法应运而生,并越来越多地应用在社会科学领域,通过模拟个体或团体的行为和交互来评估其对整个系统的影响。目前,我国的“AI+教育”尚处在发展的初始阶段(余胜泉,2018,第106 页),在政策和市场的影响下,有关“AI+教育”的研究会迅速增多,定量方法被广泛应用到“AI+教育”研究中也是必然趋势。
六、本研究的局限性
由于受到研究对象、研究方法、研究工具的制约,本研究存在一定的局限性。一方面,本研究的11 本期刊并不能全完无偏的代表所有的中文期刊,定量研究方法在某些非核心期刊的应用情况可能更糟,或者在一些专业性较强的期刊的应用情况可能更好。另一方面,受专业性和评价体系的影响,某些学者会更倾向于把文章发表在专业性期刊上,或者一部分中国学者会把质量较高的文章发表在SSCI 期刊上。这样有些方法的误用情况就可能会被忽略;同样,有些应用了新方法、新技术的文章也会被忽略。因此,后续研究者可以尝试把研究样本扩大到这些期刊范围,进行更加深入的分析。
