模拟退火聚类算法在结构面产状分组中的应用
2020-09-16王述红朱宝强王鹏宇
王述红, 朱宝强, 王鹏宇
(东北大学 资源与土木工程学院, 辽宁 沈阳 110819)
岩体是由结构面和岩石组成的复杂块体,它作为一种非均质材料,破坏时往往是沿着结构面断裂,因此,结构面决定了岩体的强度及稳定性[1].然而,由于野外环境的复杂性,结构面的很多特征参数获取较为困难,并且在利用数学手段对结构面进行分组时,分组参数的增加则使得计算的维度大大增加,数据之间的差异性使得其相似性也难以度量,因此目前最常用的仍然是依据结构面的产状数据(即倾向和倾角)进行分组.传统的产状分组方法多是人为的由玫瑰花图和极点图进行直观判断,主观性很大,无法准确定量地给出客观性分组结果.
为了避免这种主观性,在1976年,Shanley等[2]首次提出了一种客观的聚类分组方法,该方法有着严格的数学理论依据,可以得到较为理想的结构面分组结果,然而在寻找密度点时小球半径的合理确定问题一直未能得到解决.后来,Harrison等[3]和Hammah等[4]在总结前人的研究成果后又提出并发展了模糊C均值(FCM)聚类算法在结构面分组中的应用,均取得了不错的进展.但上述方法本质上都属于局部寻优的聚类方法,当分组边界不明确时,极易陷入局部极小值.随着计算机技术的发展,智能算法等机器学习方法迅速兴起,越来越多的学者将智能算法应用于结构面的分组中.李宁等[5]将改进遗传算法引入支持向量机的分类中,以此对结构面进行分组,分组结果较为客观,但由于遗传算法过程较为复杂,因此该方法应用时存在一定的缺陷.后来,Li等[6]、王述红等[7]、Li等[8]分别将蚁群算法、鱼群算法、粒子群算法引入岩体结构面分组的K-means聚类算法中,均得到较为满意的分组结果,但是上述算法的复杂性使得这些方法的分组效率较低,不利于实际工程应用.
鉴于此,本文提出了一种新型的融合模拟退火算法与K-means聚类(simulated annealing algorithm and K-means clustering,SAK)的结构面产状优势分组方法.该方法通过对K-means聚类算法进行优化,克服了K-means算法对初始值敏感,从而影响聚类结果的缺陷[9],该算法简单易实现,最终可搜索到全局最优的结构面分组结果.通过对计算机模拟生成的结构面数据及现场实测结构面数据进行分析,并与已有方法进行对比,验证了该方法的合理性、高效性和工程实用性.
1 岩体结构面分组数学模型的建立
1.1 结构面产状的空间表示法
对结构面产状进行分组,先要对结构面倾向α和倾角β数据进行归一化处理,常用的方法是将结构面视作无厚度的无限延伸平面,然后用其单位法向量来表示[10].由数学知识可知,这可以由空间中的单位球体表示,其在各坐标轴上的分量如下:
(1)
则结构面的单位法向量坐标可表示为
p=(n1,n2,n3).
(2)
1.2 结构面产状数据之间的相似性度量
为了避免倾向相差约180°的两组高陡倾角结构面分组时出错的情况,本文采用任意两结构面p1和p2之间所夹的锐角γ的正弦值作为两结构面之间产状的相似性度量[11],即
γ=arccos|p1·p2T|.
(3)
则两结构面单位法向量之间的距离为
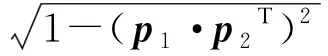
(4)
1.3 结构面分组的目标函数
假设有n个结构面Fi(i=1,2,…,n),其单位法向量分别为pi(i=1,2,…,n),可划分为k组,每组聚类中心为cj(j=1,2,…,k),定义uij为第i个结构面属于第j个分组的隶属度,定义目标函数J为所有结构面单位法向量p与各分组中心c之间的距离和(即结构面分组的总类间离散度),即
(5)
(6)
式中:pi分别为第i个结构面的单位法向量坐标;cj和cs为各分组中心的法向量坐标;m为权值分配系数,一般取1~2,本文取m=2;d(pi,cj)和d(pi,cs)分别为第i个结构面到第j个和第s个分组中心之间的距离,采用式(4)计算.由式(6)可知:结构面参数到各结构面分组中心的距离越小,聚类的误差越小,分组的结果也更精确.
2 基于SAK的岩体结构面产状分组
2.1 算法基本原理
模拟退火算法[12](SA)在20世纪80年代由Metropolis首次提出的一种启发式随机搜索算法,其基本原理来源于固体的退火过程.在SA算法中,目标函数由内能模拟,控制参数为温度和温度冷却参数,通过对初始解重复执行“扰动产生新解—计算目标函数差—由Metropolis准则判断是否接受新解”的过程,逐步进行优化,算法迭代终止时的当前解即为近似的最优解.该算法具有渐近收敛性和并行性,已在理论上被证明是一种以概率1收敛于全局最优解的全局优化算法[13].
本文将其引入结构面分组中,组成全局寻优能力强的SAK算法,通过对K-means算法聚类结果进行优化,从而有效改进K-means算法易受初始聚类中心影响的缺陷.
2.2 SAK算法的实现过程
在SAK算法中,初始温度t0和温度冷却参数q的选取是非常重要的,它们对算法的收敛速度和全局最优性有很大的影响.当q取值较大时,算法的收敛速度大大降低;当q取值较小时,温度下降过快,此时则不易获得全局最优解.为了使最初产生的初始解能够按照Metropolis准则被接受,算法一开始就应达到准平衡状态,因此选取初始温度为t0时的聚类结果t0=J0作为算法的初始解,温度冷却参数由优化效果适当选取,降温过程如下:
t(b+1)=t(b)q
(7)
式中:t(b)为当前循环次数下的温度值;t(b+1)为进一步循环后的温度值;q为冷却参数,略小于1.
另外,SAK算法中新解的产生是通过对当前解随机扰动得到,扰动公式如下:
r=fix[rand()×n+1]
(8)
h=fix[rand()×k+1]
(9)
(10)

基于SAK算法的结构面优势分组流程如下:
1) 首先对待分组的结构面数据集进行归一化处理并执行K-means聚类,将聚类分组的结果作为初始解s,由式(6)计算出初始目标函数值Js;
2) 初始化温度t0=Js、最大迭代次数L、温度冷却参数q和每个温度t下的循环次数l(即Metropolis链长);
3) 通过随机扰动产生新解s′,这代表随机产生了一个新的结构面分组方式,计算此时对应的目标函数值Js′;
4) 判断此时的目标函数值Js′是否为最优解,如果是则保存此时的结构面分组方式为最优分组、Js′为最优目标函数值,否则执行步骤6);
5) 计算目标函数差△J=Js′-Js,并判断其是否小于0,若小于0则接受新解s′作为下一个当前解,否则按照Metropolis准则(即以概率exp(-△J/t))接受新解s′;
6) 判断当前迭代次数是否达到最大迭代次数,若是,则执行步骤7),若否,则继续执行步骤3)~5);
7) 判断是否达到终止温度,若是,则算法结束,输出当前聚类划分结果作为结构面优势组分类结果;若否,则降低温度,继续执行步骤3)~6).
2.3 聚类有效性评价
为了避免对最优分组结果判断的单一性,本文采用模糊分类系数F和分类熵指标H进行聚类有效性评价,这两类指标也是最常用的衡量聚类有效性的函数[5],其计算公式分别为
(11)
(12)
式中:n为结构面数据集的个数;uij为第i个结构面属于第j个分组的隶属度,由式(5)计算所得;a为对数的底数,a∈(1,+∞),规定当uij=0时uijloga(uij)=0,本文取a=10.当F越大,H越小,表明分类的模糊度越小,聚类效果越好.因此,对于同一方法,当F较大、H较小时,结构面分组结果较好;而对于不同方法,F相对较大,H相对较小的方法为较好的方法.
3 算法准确性验证
为了验证SAK算法应用于结构面产状优势分组中的准确性,采用计算机随机模拟生成了3组界限并不明显的120个结构面数据(服从正态分布).表1为这三组结构面数据的详细参数及两种算法聚类后分组中心的对比结果;表2为聚类有效性评价结果;图1为这3组结构面数据的极点及密度等值线图;图2a和图2b分别为采用K-means算法和SAK算法分组的结果.SAK算法相关参数设置为:初始温度tbegin=20 ℃,终止温度tend=0.1 ℃,温度冷却参数q=0.92,每个温度t下的循环次数(即Metropolis链长)l=400,最大迭代次数L=500.
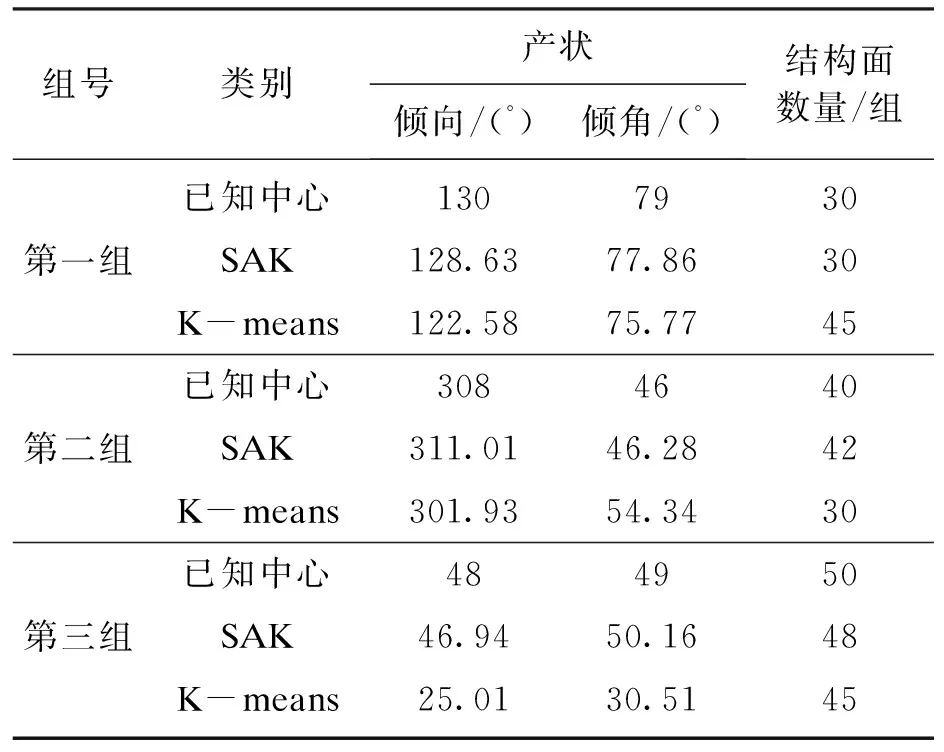
表1 结构面数据参数及分组中心Table 1 Discontinuity data parameters and grouping centers
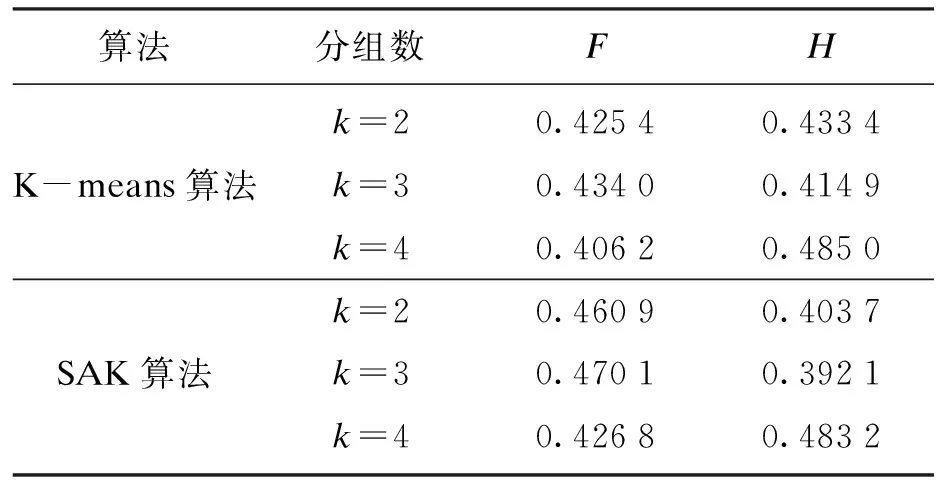
表2 随机数据聚类有效性检验Table 2 Clustering validity test of random data
由表1中分组结果与已知结果的对比中可以看出,SAK算法的分组中心与已知中心更为接近;表2显示了两种算法的聚类有效性结果,当分组数为2和3时,结果较为接近,但综合比较F和H两指标后可知最优分组数为3.此时,从图1、图2a和图2b的对比中,也可以很明显地看出SAK算法准确性更高,分组结果更符合图1中实际的情况.
4 工程实例
重庆市三环高速公路合川至长寿段兴隆隧道位于重庆市渝北区木耳镇,隧址区属构造侵蚀丘陵地貌,隧道大体沿垂直构造线方向布设,与岩层走向呈大角度相交,穿越地层主要为侏罗系上沙溪庙组地层,地层分布连续.围岩岩性主要为侏罗系中统上沙溪庙组泥岩和砂岩,中风化岩体较完整,发育高倾角的构造裂隙.隧址区无活动性断裂、泥石流、滑坡等不良地质现象,地下水类型主要为第四系松散土层孔隙水及基岩裂隙水.
本文以隧道洞口段现场实测的118个基岩露头结构面产状数据为例,进一步验证所提SAK模型在结构面分组中的合理性和工程实用性.赤平投影下结构面产状的极点及密度等值线图如图3所示.
由图3可看出,各组结构面之间的界限并不明显,根据该图可大致判断出分组数为2~4,因此对结构面数据分别采用K-means和SAK算法进行聚类分析,并与文献[8]中的KPSO算法进行对比,利用F和H两指标进行聚类有效性评价,对比结果如表3所示.由表中结果可以看出,当分组数为2时,聚类效果最好,此时三种算法聚类结果分别如图4a、图4b和图4c所示.K-means算法、SAK算法和文献[8]中KPSO算法迭代速度对比结果如图5所示;结构面优势产状统计结果见表4.

表4 结构面优势产状分组结果Table 4 Grouping results of discontinuity dominant orientation

表3 实测数据聚类有效性检验Table 3 Clustering validity test of measured data
对比图3、图4a和图4b,不难看出,SAK算法的结构面优势分组结果更符合密度等值线图所反映的分组区域,且与图4c中KPSO算法的分组结果几乎一致.原因主要是K-means算法通过随机生成初始聚类中心进行聚类,因此其聚类结果容易不理想,而采用全局寻优能力强的模拟退火算法可以对K-means算法聚类结果进行优化,从而改善原始K-means聚类算法由于初始聚类中心选择不当而使聚类效果不理想的缺陷.根据表3中聚类有效性检验结果的对比也可以看出,无论分组数为几组,SAK算法及KPSO算法的聚类的结果都要大大优于K-means算法的聚类结果,并且本文所提方法略优于文献[8]中的KPSO算法,进一步验证了所提算法具有较高的精度.
另外,从图5中可以很明显地看出,同样都是对K-means算法进行优化,文献[8]中算法整体迭代速度大大降低,而本文提出的SAK算法的迭代速度则降低较少,本文方法的迭代速度要大大优于文献[8]中KPSO算法(大约提高50%),表明了算法的高效性.因此,基于模拟退火算法K-means聚类(SAK)的结构面优势分组方法更适合应用于结构面的分组中,具有较强的合理性和工程实用性.
5 结 语
本文将模拟退火算法引入了结构面的优势分组中,提出了一种新型的基于模拟退火算法K-means聚类(SAK)的结构面优势分组算法.该算法通过逐次迭代后进行最优解的精确搜索,最终搜索到全局最优的结构面分组结果,有效克服了K-means算法对初始值敏感,从而影响聚类效果的缺陷,避免了人为划定分组方式的主观性.结合计算机模拟生成的结构面数据及重庆市三环高速公路兴隆隧道洞口段现场实测的结构面数据,将该算法与文献[8]中提出的KPSO算法进行对比,证明了SAK算法在聚类准确性、聚类精度及迭代速度上均较优,可以得到较为合理的结构面分组结果,有一定的推广应用价值.
