基于机器学习和遗传算法的高炉参数预测与优化
2020-09-16李壮年储满生柳政根李宝峰
李壮年, 储满生, 柳政根, 李宝峰
(1. 东北大学 冶金学院, 辽宁 沈阳 110819; 2. 山西太钢不锈钢股份有限公司 炼铁厂, 山西 太原 030003)
机器学习是对能通过经验自动改进的计算机算法的研究[1].通俗地讲,机器学习就是让计算机从数据中进行自动学习,得到某种知识(或规律).作为一门学科,机器学习通常指一类问题以及解决这类问题的方法,即如何从观测数据中寻找规律,并利用学习到的模型对未知或无法观测的数据进行预测[2].
近年来,机器学习领域不断推出新的算法,比如XGBoost、LightGBM、人工神经网络等,在训练速度和拟合性能方面均有明显提升.机器学习在高炉炼铁方面的研究也有了一定的进展,但是主要应用于单目标参数预测,采用多模型集成学习预测的研究较少.
高炉炼铁是一个复杂的系统,过程参数优化实际上是多目标函数、多元非线性问题,高炉参数预测和优化是极具挑战性的课题.目前大多高炉参数优化模型主要采用单目标优化算法或者传统的多目标优化算法,得到的研究结果只是多目标优化问题Pareto最优解集上的一个点,并且大多模型都是将目标函数与变量表述为线性模型,建立的优化模型精确度不高.建立精确的多目标优化模型求解高炉生产过程中的多目标问题具有重要的学术意义和应用价值.
1 基于机器学习的大型高炉参数预测
1.1 高炉参数概述
焦比表示高炉每吨生铁需要消耗的焦炭吨数,可以反映高炉冶炼水平,是高炉最重要的经济技术指标之一.在生产过程中,高炉操作者需结合高炉顺行情况及时调整焦比.当炉况顺行时可以适当降低焦比以降低燃料成本;当炉况波动时需及时补加焦炭以稳定气流,避免因调整不及时或调剂量不够导致炉况恶化,反而造成冶炼成本的升高.
K值表征高炉的透气性,是高炉最重要的控制参数之一.K值太高表明炉内透气性变差,煤气流的通道不足或分布不合理,影响炉内反应的正常进行;而K值太低通常是炉内局部区域气流过剩,会引起气流波动,导致炉况恶化.因此,高炉操作者的一项重要工作是将K值控制在合理范围内.
高炉控制参数主要有送风参数、布料参数和原燃料参数.送风参数包括:风量、风温、富氧流量、加湿量、大气湿度、风口面积、风速、鼓风动能、理论燃烧温度、炉腹煤气量等;布料参数主要是炉顶布料角度、布料圈数、料线以及布料仿真模型计算所得参数[3];原燃料参数是指各种原料、燃料、熔剂的用量、化学分析、物理指标(粒级、强度)以及冶金性能等.
考虑到高炉不同时期的操作炉型、原燃料条件、设备运行状况等冶炼条件差异会很大,采用不同时期数据进行炉况参数预测时,预测结果可能差异很大,而且高炉预测参数受近期冶炼条件的影响大于远期冶炼条件.为了解决这一矛盾,本文采取的方法是:先用全部有效数据进行预测得到1#预测结果,再用后一半有效数据预测得到2#预测结果,然后对预测结果进行综合分析.
1.2 数据预处理
在高炉参数数据库中,存放着大量历史操作数据,但是由于人为记录或生产故障等原因,导致数据库中存在不完整、不一致、不精确或重复的数据.如果直接将这些异常数据用于建模,将产生不可靠的甚至错误的模型.所以,对数据进行预处理是十分必要的,数据预处理的主要步骤如下:
1) 数据规约.高炉数据库中存在一些与预测参数无关、重复性、同类性质的参数,需要进行剔除,以减少无效计算.高炉数据库中无关类参数包括:累计消耗值、理论消耗值与实际消耗值的差值等.重复性参数包括:校正前与校正后的燃料比、焦比、理论燃烧温度、产量等.与目标参数同类性质的参数:比如预测焦比时大块焦比;预测K值时全压差、下部压差等.此外,由于正常炉况和异常炉况(包括外围生产环境变化导致慢风或炉况波动)的参数差异很大,而且异常炉况时很多特征参数存在失真效应,不能真实反映炉况,有必要对高炉数据库中的参数进行初步筛选.本文所用数据为日平均值,筛选条件为:①风量>4 500 m3/min;②焦比<480 kg/tHM;③燃料比<560 kg/tHM;④停喷煤风口个数≤5个;⑤实际燃料比与理论燃料比的偏差<20 kg/tHM;⑥无外围设备导致减风.由于剔除了异常炉况时的参数,因此本文的主要研究对象是正常炉况下的高炉参数预测与优化.
2) 缺失值处理.在处理数据时,如果数据项中缺失值的比例很高,那么该组数据对模型可能不会有用.删除数据项的阈值应该取决于实际问题,本文将删除缺失值超过30%的列.如果某组数据中有少量缺失值,采用中位数替代缺失值.
3) 异常值处理.箱型图提供了识别异常值的方法:通常异常值定义为小于L-φ×H或大于U+φ×H的值.其中:L为下四分位数,U为上四分位数,H为四分位数间距,φ为上下界系数,本文选取φ=2.5对预测参数的异常值进行剔除.
4) 共线特征数据处理.数据库中的许多特征是多余的,相互强相关的特征被称为共线,消除这些特征对中的一个变量通常可以帮助机器学习模型推广并更易于解释.本文使用相关系数来识别和删除共线特征,如果参数之间的相关系数大于阈值(通常取值0.5~0.7),将删除一对特征中的一个.
5) 数据拆分.在机器学习时,需要将数据分成一个训练集和一个测试集.训练集用于模型计算,目地是让模型学习特征与目标之间相互映射.测试集用于验证、评估模型,并依据测试集的结果训练机器学习模型.本文用80%的随机数据进行训练,剩余20%用于测试.数据拆分后生成4个数据集:训练参数集X_train,训练目标集y_train,测试参数集X_test和测试目标集y_test.
6) 数据规范化.为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,本文采用零-均值规范化,它的优点是不用预先知道属性的最大值和最小值,而且可以显著地减小噪声点对规范化的影响.
7) 筛选重要特征参数.通过特征选择来选取最重要的特征,可以减少数据量和数据重复性,加快机器学习训练速度,最重要的是可以减少过拟合.LightGBM模型中feature_importances_函数可以快速地提取重要的特征参数[4].
1.3 机器学习
本文将用python语言实现机器学习算法,依次采用支持向量机(support vector machine,SVM)[5-7]、随机森林(random forest,RF)[6]、梯度提升树(gradient boosting regression tree,GBRT)[8]、XGBoost[9]、LightGBM[4]、人工神经网络(artificial neural network,ANN)[10]对目标参数进行机器学习训练和预测.在这些算法中,SVM和ANN算法在冶金行业中得到了较为广泛的研究,GBRT是一种基于决策树的集成学习算法,XGBoost和LightGBM都是在GBRT的基础上进行了改进,但在冶金行业的研究应用较少.
具体实现方法是依次采用Scikit-Learn学习库的回归函数SVR,RandomForestRegressor,GradientBoostingRegressor,XGBoost学习库的回归函数XGBRegressor,LightGBM学习库的回归函数LGBMRegressor,Keras库中的多层感知神经网络模型,然后调用fit(X_train,y_train)进行训练.
2 机器学习优化
本文预测参数的量纲和数量级不同,为了实现对预测结果的统一度量,采用决定系数R2进行评估.
2.1 特征工程
特征工程是使用专业的背景知识和技巧处理数据,使得特征能在机器学习算法上产生更好作用的过程.由于高炉冶炼过程的复杂性,需要将初始的检测数据转化为能真实反映高炉生产状况的参数,这就要利用高炉的冶炼原理或过程仿真进行数据加工,构造出新的参数.
由于大型高炉具有较大的时滞性,因此必须对数据进行时效处理,以确保预测模型的合理性.本文的处理方法是:影响炉缸状态的参数(比如:风口面积、小块焦比、炉渣碱度、铁水测温等),采用最近7日推移平均值,其他控制参数均采用当日入炉数据;由于控制参数入炉后未必立即影响预测参数,因此需对预测参数进行加权处理,当日、1天后、2天后的权重分别为0.4,0.4,0.2.
高炉运行状态很大程度上受高炉装料制度影响,高炉布料仿真模型是分析装料制度与炉况参数的一种重要工具,也是一项最重要的特征工程.本文将利用高炉布料仿真模型构造的高炉区域焦炭负荷指数、炉料落点等特征参数提升机器学习的拟合性能[3].特征工程前、后机器学习的决定系数如表1和表2所示.
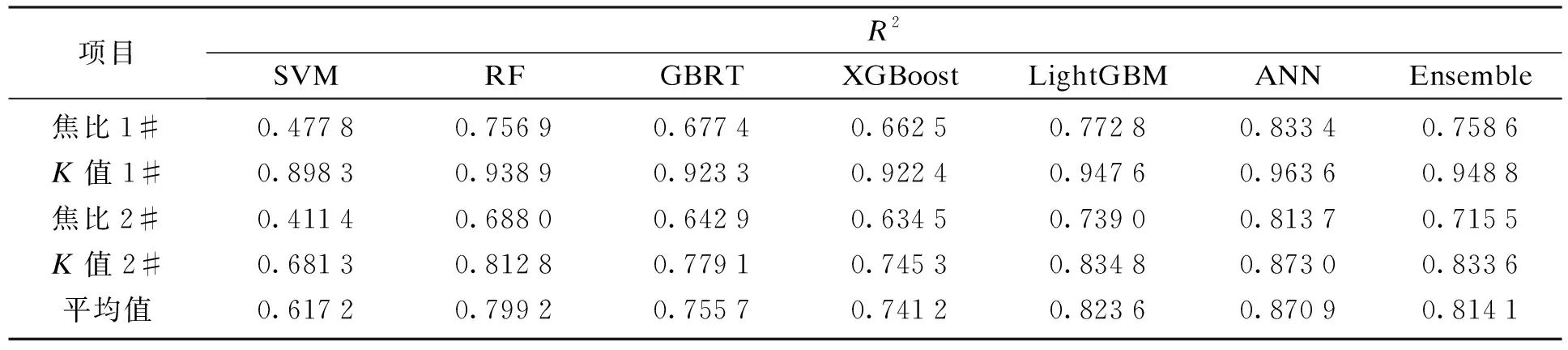
表1 特征工程前机器学习的决定系数Table 1 Determination coefficients of machine learning before feature engineering

表2 特征工程后机器学习的决定系数Table 2 Determination coefficients of machine learning after feature engineering
通过对比可知,特征工程后机器学习的预测精度明显提升,决定系数由0.814 1提升至0.883 3.
2.2 超参调优
利用Scikit-Learn可以快速实现各种机器学习算法,直接使用实际上是使用了算法的默认超参.为了提升预测效果,有必要对机器学习算法进行超参调优.Scikit-Learn的Grid search方法可以实现机器学习算法超参的自动调优,Grid search通过指定不同的超参列表进行穷举搜索,计算每一个超参组合对于模型性能的影响,并且采用5折交叉验证避免算法过拟合,来获取最优的超参组合.通过Grid search超参寻优,各机器学习算法的主要超参如表3,表4所示.

表3 各机器学习算法的主要超参(通用项)Table 3 Hyper parameters of each machine learning algorithm(generic item)
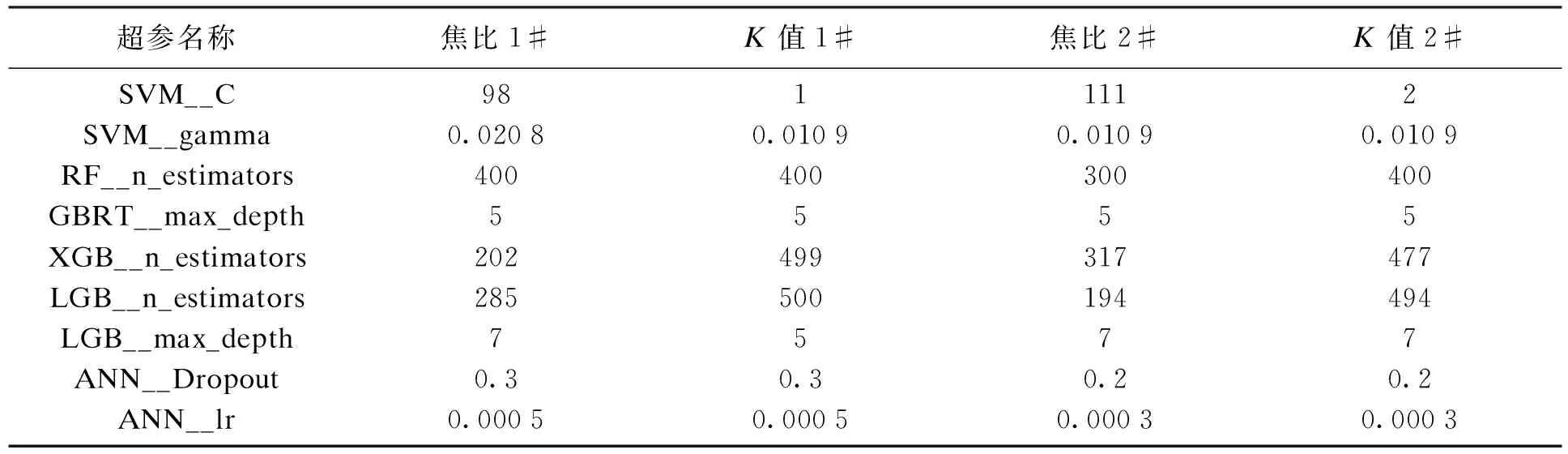
表4 各机器学习算法的主要超参数(非通用项)Table 4 Hyper parameters of each machine learning algorithm(non-generic item)
针对本文的目标预测参数,超参调优后机器学习的决定系数如表6所示.
由表5可知,ANN深度学习算法的拟合能力最强,基于决策树的算法中LightGBM表现最好,其他算法的决策系数可以达到0.85以上,均具有较强的拟合能力,适用于高炉参数预测.超参调优可以提高算法的预测精度,SVM算法尤为明显.虽然个别算法的R2有所降低,但通过5折交叉验证后的超参降低了算法的过拟合程度.

表5 超参调优后机器学习的决定系数Table 5 Determination coefficients of machine learning after hyper parameters tuning
2.3 集成算法调优
机器学习算法对不同数据集的预测效果不确定性很大,集成学习可以对不同算法进行扬长避短.考虑到高炉参数控制是多目标规划,而且高炉参数具有多变性,预测方法必须具有很强的鲁棒性,即不管预测数据变化多大,都能实现较好的预测精度.为了达到这一目标,本文集成学习算法的思路是:根据各算法R2大小,赋予算法不同的权重,R2越大赋予算法的权重越大,然后加权平均得出最终的预测值.
具体计算方法如下:将各算法R2由大到小排序, 对应权重系数依次为w1~w6,设定w6=0,为了实现R2越大赋予算法的权重越大,目标权重系数满足如下条件:
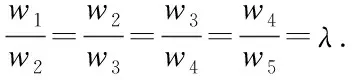
(1)
当权重系数满足式(1)条件时,不同λ值对应的权重系数计算如式(2)所示,计算结果如表6所示.

表6 不同λ值的权重系数Table 6 Weight coefficients for different λ
wi=λ6-i/(λ+λ2+λ3+λ4+λ5)
(2)
依次计算不同λ条件下集成学习的决定系数,结果如表7所示.

表7 不同λ时机器学习的决定系数Table 7 Determination coefficients of machine learning for different λ
结果表明,λ取值较小时,R2较大的算法赋予的权重不足,预测精度较低;λ取值较大时,R2较大的算法赋予的权重过大,易导致预测结果过拟合程度加强,预测效果反而变差;λ=2.0~2.4时,预测效果最好,R2为0.916 1,本文选取λ=2.2.
采用上述特征工程、超参调优和集成算法调优后,R2由0.814 1提高至0.916 1,模型的预测精度得到了提高.采用优化后的集成学习方法所得各参数的预测值与实际值的偏差很小,预测效果良好,有利于高炉操作者对炉况参数的精准控制,而且模型具有很好的鲁棒性.此外,采用上述模型对热负荷、燃料比、炉喉钢砖温度、压差等高炉参数进行了预测,预测值和真实值的R2均能超过0.8,可以实现多目标炉况参数精准预测,有效指导高炉操作.
3 基于遗传算法的大型高炉参数优化
遗传算法是一种全局优化算法,研究的思路来源于生物学理论,是一种基于生物进化论和分子遗传学的搜索优化算法,具有计算方法简单、优化效果好、处理组合优化问题能力强等优点.本文采用精英非支配排序多目标遗传算法NSGA-Ⅱ来解决高炉生产过程多目标优化问题[11-12].NSGA-Ⅱ多目标优化算法流程如图1所示.
采用NSGA-Ⅱ 算法对焦比和K值进行多目标优化,选取的优化参数包括:烧结碱度、烧结FeO、烧结SiO2、烧结MS、烧结强度、焦炭M40、焦炭M10、焦炭平均粒级、焦炭灰分、焦炭CSR、焦炭CRI、球团比例、中块焦比、理燃、炉渣二元碱度.
优化参数的约束条件设定:设定寻优数据集X,参数Xi的下限为历史数据的1.5%分位数,上限为历史数据的98.5%分位数,在此区间内进行迭代寻优.
种群规模设定为50,寻优代数为100,交叉概率Pc为0.8,变异概率Pm为0.15时,对控制参数进行寻优,NSGA-Ⅱ算法生成的Pareto前沿如图2所示.
由图2可知,NSGA-Ⅱ算法所得Pareto最优解中焦比的范围∈[339.2,345.4],K值范围∈[2.56,2.63].
与传统寻优方法相比,遗传算法具有计算方法简单、优化效果好、处理组合优化问题能力强等优点.本文采用NSGA-Ⅱ 算法进行求解,可以得到高炉生产多目标优化问题的Pareto最优解集.高炉操作者可以根据该多目标优化结果针对不同的需求选择相应的控制参数,实现高炉参数的优化控制.
4 结 论
1) 对于不同的预测目标参数,由于自身或相应的特征参数的数据分布差异较大,不同机器学习算法表现各异,没有哪一个算法总是最准确的;集成学习可以对各种算法扬长避短,预测结果误差小,还可以减少过拟合.
2) 采用特征工程、超参调优和集成算法调优后,目标参数的预测值与真实值的决定系数R2由0.814 1提高至0.916 1,不仅提高了模型的预测精准度,而且提升了模型的鲁棒性.
3) 在高炉参数预测时采用了高炉布料仿真模型得出的特征参数,使得预测结果误差减小,为高炉操作者对高炉参数的精准控制提供依据,以改善高炉运行状况,进一步提高高炉生产技术指标.
4) 采用非支配排序多目标遗传算法进行求解,最终得到高炉生产多目标优化问题的Pareto最优解集.
