一种自适应步长的复合梯度加速优化算法
2020-09-16印明昂王钰烁孙志礼于云飞
印明昂, 王钰烁, 孙志礼, 于云飞
(1. 东北大学 机械工程与自动化学院, 辽宁 沈阳 110819;2. 中车长春轨道客车股份有限公司, 吉林 长春 130062; 3. 中国航发沈阳发动机研究所, 辽宁 沈阳 110015)
以分类算法为基础的“人工智能”正深刻影响着科研领域的每一方面.在此背景下,各项实验中样本数据的数量和维度呈现出“爆炸”增长的态势.为适应这种趋势,近年,数值计算理论与优化方法得到了长足发展.其中,一阶优化算法以其出众的计算效率在数值优化领域得到了广泛的研究和应用[1].Sashank等[2]指出自适应步长加速算法Adam在收敛性上存在缺陷,并通过赋予历史梯度的“长期记忆”提出AMSGrad算法,从理论上解决了收敛问题.Jun等[3]同样从Adam的收敛问题出发,通过一种基于历史与当前梯度的平方衰减构建了一种有针对性的自适应优化算法.Ma等[4]在动量加速随机梯度下降法的基础上提出准双曲权重衰减的加速算法QHM,并找到一种通过改变超参数将该算法转变为其他算法的方法.Luo等[5]对比了随机梯度下降法(SGD)与自适应方法的泛化与收敛能力,通过使用动态的学习率变化界限提供了Adam和AMSGrad的一种新变种,分别称为AdamBound和AMSBound,实现了从自适应方法到SGD的渐进平稳过渡.
本文基于一种当前梯度、预测梯度及历史动量梯度三者结合的复合梯度,提出一种新型自适应步长加速优化算法,称为复合梯度下降法(C-Adam),并通过寻找在文献[6]中定义的遗憾(regret)上界,证明C-Adam算法的收敛性.最后对MNIST,Cifar-10常用测试数据集及45钢静拉伸破坏实验的实验数据通过多种算法建立Logistic回归模型,对比验证本文算法的性能表现.
1 复合梯度下降法
1.1 算法描述及更新规则
算法 1 复合梯度法C-Adam
输入:超参数:b1,b2;迭代步长η
初始化θ=0;(待求参数)
初始化gt=0;(当前梯度)
ut=0;(预测梯度)
mt=0;(动量一阶矩)
vt=0;(动量二阶矩)
初始化t=0;(迭代次数)
当θ不收敛或未达到最大迭代次数时,循环:
t=t+1;
gt=▽θJ(θt-1);(取得参数当前梯度)
θt=θt-1-η·gt;(梯度下降法更新参数)
t=t+1;
ut=▽θJ(θt-1);(取得参数预测梯度)
mt=b1·mt-1+ (1-b1)·(gt+ut);(梯度复合)
vt=b2·vt-1+ (1-b2)·(gt+ut)2;
θt=θt-1-η·mt/(vt)1/2;(更新参数)
循环结束
输出:参数θt
算法1为复合梯度下降法的伪代码描述.其中,θ表示所求问题的解;gt表示数据在当前位置的梯度;ut表示利用梯度下降法更新θ后下一位置的梯度(如采用mini-batch策略在此次更新中不改变所选数据),称为预测梯度;mt表示动量梯度,由历史动量、当前梯度及预测梯度三者复合而成;vt表示三种梯度二阶矩的复合,用以自适应控制迭代的步长;mt,vt的惯性衰减通过超参数b1,b2控制,通常b1=0.99,b2=0.999;t表示迭代次数.
算法1与以往加速算法的区别在于将预测梯度与历史动量区别开,通过一次真实的梯度更新找到下一步动量更精准的下降方向.这一过程虽进行了两次迭代,但与其他算法的两次迭代相比下降速度更快,结果更为精确.这一结论将在第二节数据测试部分得到验证.
1.2 收敛性证明
运用文献[6]中的收敛性分析方法对复合梯度法进行收敛性证明.
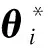
首先观察下式:
(1)
由算法1可知式(1)成立,将其进一步展开,有
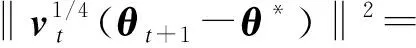
(2)
其中,〈,〉表示向量之间的内积.根据算法1中mt的更新规则,有
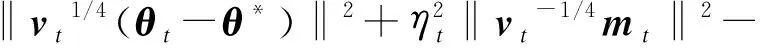
(3)
(4)
根据柯西-许瓦兹不等式:2ab≤a2+b2,有
(5)
根据文献[6]定义遗憾(regret)为
(6)
又由凸函数性质:
(7)
因此为寻找复合梯度法的遗憾上界,将式(5)和式(7)代入式(6),有
(8)
下面首先整理含有mt的项,
(9)
式(9)表示将求和的最后一项单独处理,并写成向量的分量形式.其中,d表示向量维度.由η=η/t1/2及mt,vt的更新形式,通过数学归纳法,式(9)可变形为
(10)
根据闵可夫斯基不等式
∑(ak·bk)2≤∑ak2·∑bk2
(11)
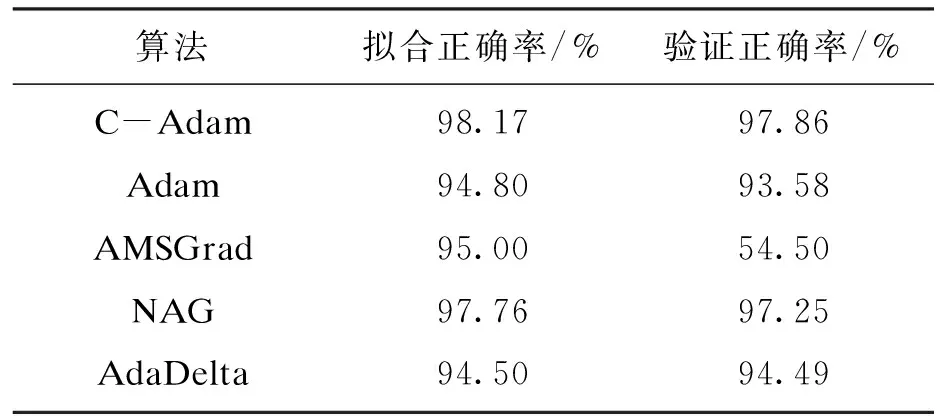
由于0 (12) (13) 由于每次迭代均可以放大为式(13)的最后一项,因此式(13)不等式的右侧可继续放大为 (14) 式(14)的最后一个等式由数学归纳法得出.通过观察可知,式(14)中j的取值从t开始,因此j≥t.由此可继续整理得 (15) 由等比数列求和公式及柯西-许瓦兹不等式,式(15)可放大为 (16) 式(16)可继续放大为 (17) 将式(17)的结论代回式(8),整理得 (18) 根据vt的更新规则,有 另由假设θ的凸可行域F的半径存在上界D∞,式(18)可变为 (19) 最终可得复合梯度法的遗憾上界为 (20) 综上,复合梯度下降法存在遗憾上界,因此该算法具有收敛性. 由美国邮政系统开发的MNIST数据集[7]是图像识别的经典数据集,共包含7万张出自不同人的手写0~9数字图片.每张图片均为28×28像素的黑白图片,因此每组样本由784维的数据和一个样本标签组成. 利用MNIST数据集建立Logistic回归模型.C-Adam算法超参数b1=0.99,b2=0.999;Adam,AMSGrad算法采用默认设置;NAG算法的惯性系数选择0.99;AdaDelta算法的权重衰减系数选择0.01.所有算法的迭代步长均为0.001,mini-batch随机数量选择256,最大迭代次数设置为500.5种算法的训练损失及测试损失见图1,图2. Cifar-10数据集[8]共包含10个种类、6万张像素为32×32的彩色图像,每个像素点包括R,G,B三个数值,因此该数据集维度为32×32×3=3 072. 对Cifar-10数据集建立Logistic回归模型.C-Adam算法超参数b1=0.99,b2=0.999;Adam,AMSGrad算法采用默认设置;NAG算法的惯性系数选择0.99;AdaDelta算法的权重衰减系数选择0.01.所有算法的迭代步长均为0.001,mini-batch随机数量选择256,最大迭代次数设置为1 000.5种算法的训练损失及测试损失见图3,图4. 对45钢试件进行两次静拉伸破坏实验,分别采集实验过程中产生的声发射信号数据,并根据拉伸机信息划分实验阶段,最终将两组数据合并,建立Logistic回归模型. 试件的样式尺寸根据国标GB/T6398—2000的有关内容确定,具体尺寸见图5.试件中部狭长型缺口为预制缺陷,通过两圆孔与拉伸机连接.控制拉伸机加载速度恒定为0.033 mm/s,两次实验分别进行511,673 s,分别测得声发射信号27 081组和18 463组. 得到原始信号后首先根据文献[9]所述方法进行特征提取,获得每组信号的30个特征参量;然后利用文献[10]的降噪方法对所有特征进行降噪处理,并将所得数据归一化;最后绘制拉伸机的时间-力曲线,找到试件经历的不同状态,以此对数据进行类别划分.两组实验的阶段划分如图6,图7所示. 将两次实验数据合并,并建立Logistic回归模型.其中,5种算法的超参数选择与Cifar-10数据集实验相同.训练损失与测试损失见图8,图9,模型的拟合正确率及验证正确率见表1. 表1 模型拟合及验证正确率Table 1 Model fitting and verification accuracy 1) 由三组训练损失图可以看出,C-Adam在训练过程中的收敛速度明显高于其他算法,且随着迭代次数的增加损失值下降明显,证明该算法具有快速收敛的特性. 2) 对于三组测试损失,C-Adam的收敛速度同样优于其他算法,且收敛于更小的损失水平,说明该算法具有良好的稳定性. 3) 通过45钢拉伸实验数据的模型拟合结果可知,C-Adam的拟合正确率达到98.17%,验证正确率达到97.86%,明显高于其他算法,说明该算法可以提供更优的解.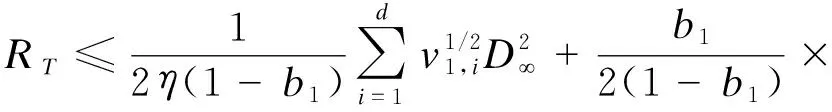
2 案例分析
2.1 MNIST数据集
2.2 Cifar-10数据集
2.3 基于声发射信号的静拉伸破坏实验
3 结 论
