基于改进极限学习机的泥石流发生预测
2020-09-15曾鼎,曾勇
曾 鼎,曾 勇
(1.兰州理工大学土木工程学院,甘肃 兰州 730050; 2.西南交通大学土木工程学院,四川 成都 610031)
0 引 言
泥石流是一种山区常见地质灾害,具有突发性、流量大、破坏力强等特点,常常会冲毁公路、铁路以及村镇,给人们带来巨大的生命财产损失,对其进行提前预测具有极其重要的意义。然而,泥石流形成原因复杂,影响因素众多,而且目前对其形成机理认识仍然不足,要建立一个确定性的预测模型非常困难[1]。
近年来,许多国内外学者采用不同的统计分析方法建立泥石流预测预报模型。BRF神经网络、BP神经网络、Fisher判别法、Bayes判别分析法等方法[2-4]被引入到泥石流的预测预报中,并取得了较好的效果。但这些方法都存在各自的局限性,比如,BP神经网络容易陷入局部最优;BRF神经网络中,如果不能获取最优样本,就无法逼近最优解[5]。将极限学习机(ELM)算法应用到泥石流预测中,该算法通过对隐含层神经元数量的设置,训练输入层矩阵得到输出权重并对预测集输出层进行分类,其特点在于可以随机设定输入层和隐含层之间的权值和隐含层的阈值,并且确定之后不需对其进行调整,隐含层和输出层之间的权值不需要通过迭代调整,而是直接由Moore-Penrose广义逆矩阵的解得来,相比于其他算法,大大地减小了运行时间和操作过程。由于隐含层权值的选择具有随机性,这样虽然增强了算法的泛化能力,但是对分类的稳定性造成了不利影响。因此,本文利用DBSCAN密度聚类算法[7]对ELM算法进行改进和优化,并将其应用到泥石流灾害的预测预报中。
1 DBSCAN聚类算法
DBSCAN是一种基于密度空间聚类的经典算法,它通过检查数据集中每个点的邻域Eps来搜索簇,当在点p的Eps邻域中点的个数比最少点数量MinPts要大时,创建一个核心对象为p的簇。在聚类过程当中,它不需要提前给出聚类所形成簇的数量,并且可以发现任意形状的聚类以及辨别出对数据具有干扰的点。
在DBSCAN算法中,将数据点分为核心点、边界点和噪声点。当某点的邻域Eps内含有点的个数不小于最少点数量MinPts时,将该点定义为核心点;某点的邻域Eps内含有点的个数小于最少点数量MinPts,但是落在核心点的邻域内时,将该点定义为边界点;既不属于核心点又不属于边界点则称为噪音点。点之间的关系分为直接密度可达、密度可达和密度相连3种。当点q在核心点p的Eps邻域当中时,称点q从核心点p直接密度可达;对于数据样本点q1,q2,…,qn,有q1=q,qn=p,当所有点都有qi+1从qi直接密度可达时,q从p密度可达;当点b同时处于点p的邻域和点q的领域时,点p和点q密度相连。
DBSCAN算法的目的就是寻找密度相连点的最大集合[8]。DBSACN通过不断聚集核心点密度可达的对象,形成一个簇,并且不断合并所有密度可达的簇,当没有新的点加入时,则聚类完成。通过分析DBSCAN算法可以发现,DBSCAN只需确定邻域Eps和最少点数量MinPts,便可获得良好的聚类结果。
2 极限学习机的改进
2.1 极限学习机理论
极限学习机是2006年由Huang等人[9-10]在Moore-Penrose广义逆矩阵的基础上提出的一种单隐层前馈神经网络的学习算法。该算法在训练过程中,不需要设置调整输入层与隐含层之间的初始权值和隐含层阈值,只需对隐含层之间的节点个数进行确定,便可通过最小二乘法计算输出权值完成训练。
对于任意的数据集xi=[xi1,xi2,…,xin]T∈Rn,n为向量特征空间的维数;ti=[ti1,ti2,…,tin]T∈Rm,ti为xi对应的分类,m为类别数。一个含有L个单隐含层节点,Ln,激活函数为g(x)的单隐含层前馈神经网络可表示为:
(1)
其中,βi=[β1,β2,…,βm]T为隐含层第i个节点与输出层之间的连接权值;wi=[w1,w2,…,wn]T为输入层与隐含层第i个节点之间的连接权值;bi=[b1,b2,…,bn]T为隐含层第i个节点的偏置,式(1)可化简为:
Hβ=T
(2)
其中,H为隐含层的输出矩阵,即:
(3)
当算法中选定的函数g(x)无限可微时,输入权值w和隐含层偏置b可以随机初始化。输出权值β可通过求解min ‖Hβ-T‖的最小二乘解获得,即:
β=H*T
(4)
其中,H*为矩阵H的Moore-Penrose的广义逆。
2.2 改进的ELM算法
在极限学习机算法中,输出权值由随机产生的初始权值和阈值计算得到,每次的分类结果都会随初始权值和阈值的不同而产生微小变化,当输入层的数据类别混乱时,会对极限学习机的稳定性和精度造成不利影响。为了提高预测结果的稳定性和准确率,将DBSCAN聚类算法引入到极限学习机算法模型中,利用DBSCAN聚类算法的特点,在无需确定聚类结果个数的情况下,就能得到差异性良好的类别,从而提高预测模型的稳定性和精度。
改进的ELM算法处理过程主要分为3个部分:1)对训练集和预测集同时进行聚类,得到K个不同的子集;2)利用K个不同子集中的训练集训练分类器,得到K个具有差异性的分类器;3)利用不同的分类器处理对应的预测集。具体改进的ELM算法实现如下:
1)处理样本数据。为了方便聚类算法的处理和排除偶然性,将训练集和预测集数据写成nm型矩阵,然后对数据的组序进行随机处理。
2)选择最恰当邻域Eps和最少点数量MinPts。为了保证每一类分类器都具有实际意义,所选择的邻域Eps和最少点数量MinPts要使得聚类完成后,每一个簇类密度差异在一定范围内,即:
P(xi+1)-P(xi)ε
(5)
其中,P(xi)=|Ne(x)|,εMax,Ne(x)为核心点的邻域Eps所代表的范围,Max为用户指定的最大差异值。
3)利用DBSCAN算法进行聚类分析。当聚类结果不满足式(5)时,重新进行步骤2,直到所得聚类结果符合需求。
4)将不同类别中的训练集进行分类。确定每个分类器的神经元个数。神经元个数的选择是ELM算法的核心部分,随着神经元个数的增加,预测精度会随之上升,但上升至一定程度之后,增加神经元数量反而会导致精度趋于不稳定。因此,在选择神经元个数时,需要综合考虑算法的准确性和稳定性。
5)利用训练集训练分类器。将分类所得到的K个训练集分别进行训练,得到K个分类器;同时,为了确保改进的ELM方法的有效性,将所有训练集组成的一个集合进行训练,得到一个对比分类器。
6)将不同类别的预测集放到对应的分类器中进行预测分类,统计分类结果;将分类结果与实际结果相比较,计算预测精度。
7)当步骤3中预测集数据形成单独一类情况时,此时该预测集数据相当于DBSCAN算法中的噪声点,为了保证预测结果的可行性和准确度,将所有训练集置于同一分类器中进行训练形成训练集分类器,然后将单独一类的预测集数据放于训练集分类器来预测结果。
3 改进的ELM算法在泥石流发生预测中的应用
3.1 预测因子的选取
泥石流的预测预报必须建立在泥石流形成条件研究基础上,泥石流形成的条件主要有地形、地质和降雨3大类[11]。通过相关研究成果的总结,选取与泥石流3大形成条件密切相关的6个因子作为输入指标[12],分别为有效集水区面积、主沟长度、集水区平均坡度、累计雨量、峰值雨量与崩塌率。其中,累计雨量与峰值雨量可以反映研究区域的降雨条件;有效集水区面积与主沟长度和区域的地形有关,可以反映出研究区域的地形地貌条件;崩塌率和平均坡度则反映出研究区域的地质条件。
为便于与传统ELM算法和其他算法进行对比,泥石流预测采用文献[12]中的33组数据,见表1。选取23组作为训练集,其余10组数据作为预测集。
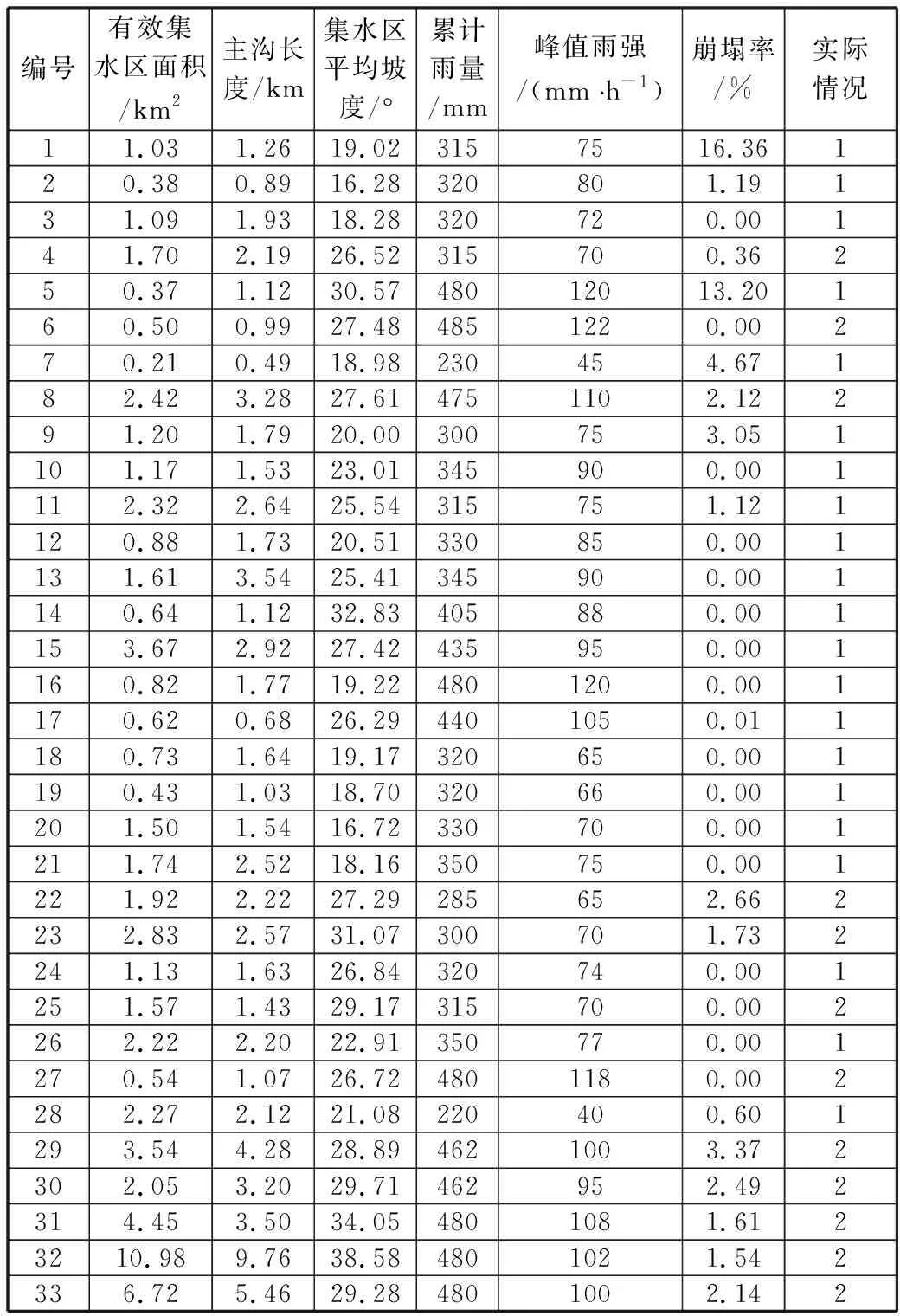
表1 泥石流相关数据
3.2 结果及分析
在ELM算法当中,选取Sigmoid函数作为激活函数,输入权值w和隐含层偏置b随机初始化。为了获得最佳的聚类效果,选择区分度最高的集水区平均坡度和主沟长度作为聚类依据,为了保证获得正常数目的类别数并且区分出噪声点,设置最少点数量MinPts=2;分别对邻域Eps=1、Eps=1.5、Eps=2和Eps=2.5的情况进行聚类,结果分别如图1~图4所示。
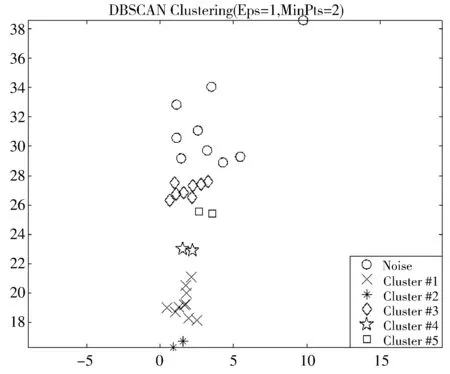
图1 邻域为1时的聚类
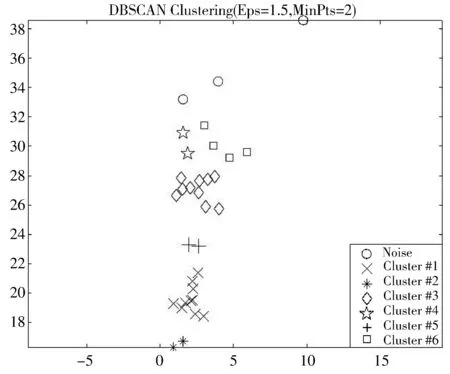
图2 邻域为1.5时的聚类

图3 邻域为2时的聚类
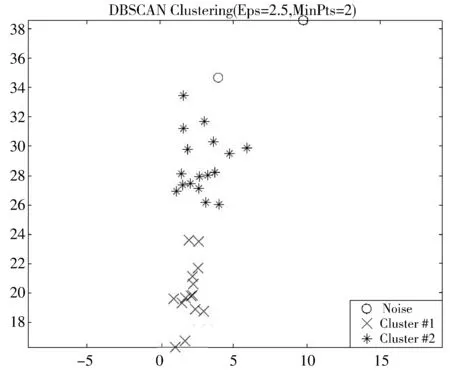
图4 邻域为2.5时的聚类
从图1~图4分析可得,当Eps增大时,类簇数和噪声点逐渐减少。Eps取1时,有5个类簇,9个噪声点存在;Eps取1.5时,有6个类簇,3个噪声点存在;Eps取2时,有2个类簇,3个噪声点存在;Eps取2.5时,有2个类簇,2个噪声点存在。随着邻域的增大,类簇数先增大后减小至不变,当类簇数在一定邻域范围内保持2类不变时,说明根据数据特征将数据分为2类,对应为泥石流与非泥石流,此时聚类良好;从图1~图4中可看出,当Eps增加,噪声点慢慢减少,说明随着Eps的增加,数据的特征逐渐消失,但过多的噪声点对训练器分类产生干扰性大,所以,选择Eps=2的聚类结果时,聚类良好且保持原有的特征。
将上述聚类所得结果类别分别训练,得到2个ELM分类器。分析2个不同类别中的数据,将预测集分别代入各自对应的分类器中进行判别分类。对于剩余的3个噪声点,将训练集中的数据进行统一训练得到训练集分类器,并将噪声点数据代入训练集分类器中进行类别判定,3个ELM分类器所得结果与实际结果进行比较,结果如图5所示。
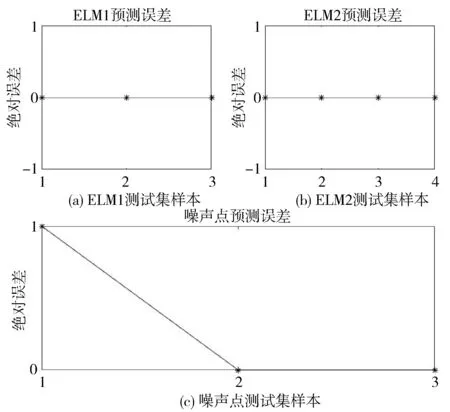
图5 ELM处理结果
对相同的训练集和预测集采取传统的ELM分类方法,与本文方法进行对比实验,为比较改进的ELM算法与传统ELM算法的差异,将每个分类器的隐含层神经元个数都设置为200;为排除实验偶然性,对相同数据进行50次实验,统计实验平均精度,如图6所示。由图6可知,改进的ELM算法的精度和稳定性相比于传统的ELM算法得到了大幅提升。
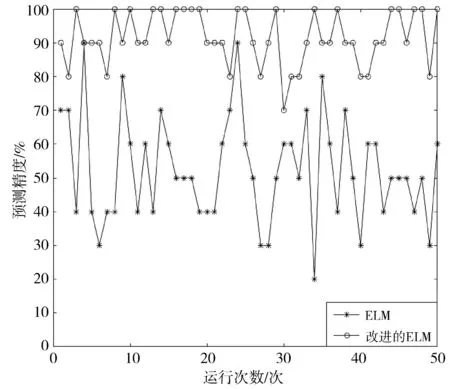
图6 改进的ELM与传统ELM实验精度对比
为分析本文方法对于泥石流发生预测的普适性,对相同数据集建立BP神经网络模型并与文献[12]的Fisher判别模型的精度进行对比,所得结果如表2所示。从表2可以看出,改进的ELM方法的预测准确率达到91.6%,对泥石流的发生预测精度有了较大的提升。
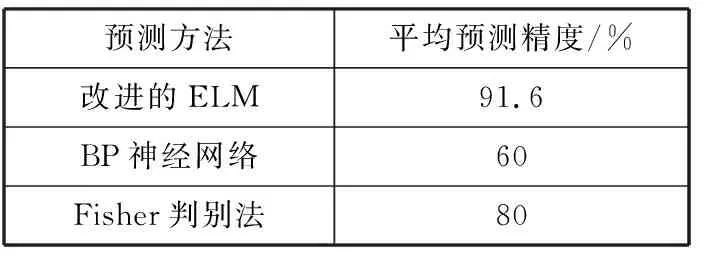
表2 不同方法的预测精度
4 结束语
本文将DBSCAN引入到极限学习机中,综合泥石流发生影响因子提出了一种基于改进极限学习机的泥石流发生预测方法。通过分析与验证,可以得出以下结论:
1)在极限学习机训练过程中,利用DBSCAN算法对ELM训练集进行聚类处理,将所得类簇分别训练得到不同的ELM分类器,提高了算法的分类准确率。
2)通过分析聚类结果,选用合理的邻域值,提高了算法的稳定性。
3)与传统ELM方法相比,改进的ELM算法的稳定性和平均精度均有大幅度提升;对比BP模型与Fisher判别法,本文方法的预测准确率有明显提高,对预测样本的平均预测精度可达91.6%,对泥石流发生的预测具有良好的应用前景。
