基于堆叠式注意力机制的隐式篇章关系识别
2020-09-14阮慧彬徐扬孙雨洪宇周国栋
阮慧彬,徐扬,孙雨,洪宇,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
篇章关系识别是自然语言处理(Natural Language Processing,NLP)中的一项基础任务,对其他自然语言处理任务具有广泛应用价值,如情感分析[1]、事件抽取[2-3]、问答[4]、自动文摘[5]及机器翻译[6-8]等。篇章关系识别旨在判定两个连续的文本片段(即“论元”)Arg1和Arg2之间的语义关系。具体地,给定两个论元Arg1和Arg2,通过分类器判断两者间的篇章关系,其任务框架如图1所示。

图1 篇章关系识别任务框架Fig.1 Task framework of discourse relation recognition
作为篇章关系识别研究任务的重要语料资源,宾州篇章树库[9](Penn Discourse Treebank,PDTB)将篇章关系分为四大类:对比关系(Compa-rison)、偶然性关系(Contingency)、扩展关系(Expansion)、时序关系(Temporal)。此外,依据论元对之间是否存在显式连接词,PDTB将篇章关系分为两类:显式篇章关系(Explicit Discourse Relation)和隐式篇章关系(Implicit Discourse Relation)。
例1 [Arg1] The computer system was operating
(译文:电脑系统正在运行)
[Arg2] [Explicit=so] orders could be taken.
(译文:[所以]可以接受订单)
[篇章关系] Contingency.Cause.Result。
例2 [Arg1] I’m not so young anymore.
(译文:我已经不再年轻)
[Arg2] [Implicit=So] I won’t be throwing 90 mph.
(译文:我的抛出速度不会超过90英里/小时)
[篇章关系] Contingency.Cause.Result。
显式篇章关系指直接由连接词触发的篇章关系类型,其论元间的篇章关系可根据连接词来判定。如例1中的Arg2是Arg1的结果,其因果关系可通过连接词“so”推断得到。而如例2所示,隐式篇章关系缺乏连接词等直观推理线索,导致其难以被直接识别。因此,隐式篇章关系识别更依赖于深层的语义、句法以及上下文特征。本文主要研究隐式篇章关系识别。
传统的隐式篇章关系识别方法主要依赖于特征工程,如Pitler[10]等抽取论元对的词对、动词类型、动词短语长度及情感词的极性等作为分类特征,在PDTB的四大类关系上取得优于随机分类的性能。Lin[11]等在Pitler[10]等的基础上提出使用句法结构特征和依存特征构建分类器。Rutherford和Xue[12]使用布朗聚类特征替代传统的词对特征,一定程度上缓解了特征表示稀疏问题,同时,他们还使用指代消解获取实体级特征,以更好地对论元进行表示。Li[13]等进一步优化句法特征的表示方法,以解决特征表示稀疏问题。
近年来,由于分布式词表示[14]一定程度上缓解了表示稀疏问题,且神经网络模型在自然语言处理领域获得一定成果。越来越多的研究者们构建精巧的神经网络模型来进行隐式篇章关系识别。如 Zhang等[15]使用浅层卷积神经网络(Convolutional Neural Network,CNN)对隐式篇章关系进行分类,其在四种关系上的分类性能均有所提升。Qin等[16]通过同一个CNN提取两个论元的特征,在高速公路模型(Highway Network)的基础上引入新的门控机制,来约束论元特征的交互。Chen等[17]采用门控机制来表征论元词对之间的相关性。Guo等[18]对论元表示进行交互式注意力计算,以得到加权后的论元表示,作为张量神经网络(Neural Tensor Network,简称为NTN)的输入,并设计了包含L1和L2正则项的目标函数。Bai和Zhao[19]使用不同粒度的词向量对论元进行表示,并使用卷积和递归编码块捕获单个论元向量的信息,通过残差及注意力机制获得最终表示。Nguyen等[20]在Bai和Zhao[19]的基础上,将关系表示和连接词表示映射到同一空间中来实现知识迁移,从而提升隐式篇章关系识别性能。此外,为了缓解隐式篇章关系语料不足的问题,前人引入外部知识来辅助隐式篇章关系识别,如Liu等[21]融合了CNN和多任务学习(Multi-Task)的思想,以隐式篇章关系分类为主任务,显式篇章关系分类、连接词分类等任务为辅助任务,并引入了RST-DT、New York Times Corpus等外部语料扩充训练语料,从而提升分类器性能。Lan等[22]提出基于注意力机制的多任务学习方法进行隐式篇章关系识别,并引入外部语料BLLIP训练词向量。Wu等[23]利用中英文平行语料中显隐式不匹配的特性(即中文显式语料对应的英文语料中不存在连接词),从中挖掘隐式英文篇章关系语料用于扩充PDTB训练集。
在隐式篇章关系识别任务上,前人将基于注意力机制(Attention Mechanism)的神经网络模型作为捕捉论元关键信息的核心方法之一[17-22]。注意力机制能够捕捉词义信息间的关联性,借以对词义特征的重要性进行判定,如篇章领域最具代表性的上下文信息等特征。然而,相关研究仅仅关注论元之间交互特性对论元表示的约束,而忽略了论元自身的关键语义特征。针对以上问题,本文提出了一种基于堆叠式注意力机制(Stacked Attention)的神经网络模型,并将其用于隐式篇章关系识别。这一方法融合了自注意力机制(Self-Attention)和交互式注意力机制(Interactive Attention),不仅能够挖掘论元本身的有效特征,还融合了论元之间的交互信息。
本文在PDTB 标准数据集上对上述方法进行测试,实验结果表明融合两种注意力机制的方法在隐式篇章关系分类上表现优于基准模型,且其在扩展关系(Expansion)和时序关系(Temporal)上优于目前的隐式篇章关系识别模型。
1 基于堆叠式注意力的隐式篇章关系分类
1.1 总体结构
本文提出的堆叠式注意力机制模型主要分为四个部分:首先,通过双向长短时记忆[24](Bi-direc-tional Long Short-Term Memory,Bi-LSTM)分别编码Arg1和Arg2得到论元表示;其次,在论元表示上进行自注意力权重计算,借以得到自注意力分布式特征;然后,将其用于交互式注意力权重的计算,以得到堆叠式注意力表示;最后,拼接两个论元的堆叠式注意力表示,并将其输入全连接层进行非线性变换,然后送入softmax层得到关系分类结果。
图2展示了模型整体框架,其中,对于论元中的每个单词,我们先通过预训练好的词向量表将其映射为向量xw∈de,以初始化每个单词的分布式表示,并对其进行拼接得到论元Arg1和Arg2的向量表示:
(1)
(2)
其中,L1和L2分别为Arg1和Arg2的长度。
在此基础上,本文通过执行以下学习过程实现论元关系的分类。


图2 基于堆叠式注意力机制的模型框架图Fig.2 Framework of the stack-attention based model
藏状态表示H1和H2;
2) 自注意力层将论元的隐藏状态表示H1和H2作为输入,分别通过矩阵运算得到每个单词的自注意力权重分布,并以此获得论元的自注意力表示R-SelfArg1和R-SelfArg2。
4) 我们拼接R-StackArg1和R-StackArg2,作为全连接层(Fully Connected Layer)的输入,并将最终的向量表示输入softmax层进行篇章关系分类。
1.2 Bi-LSTM层
在输入序列长度较大时,传统的循环神经网络Recurrent Neural Network,RNN)存在远距离信息丢失和梯度爆炸等问题。针对RNN的不足,Hochreiter和Schmidhuber[24]提出长短时记忆神经网络,其采用输入门、遗忘门和输出门来控制网络结构中细胞状态的记忆程度,计算公式如下:
(3)
(4)
ht=ot⊙tanh(ct),
(5)
其中,it,ot及ft分别为输入门、输出门及遗忘门,ct为细胞状态,ht为当前时刻的隐藏状态,w∈4dh×(dh+de)为权重矩阵,b∈4dh为偏置,σ为sigmoid激活函数。

(6)
(7)
(8)
(9)
(10)
1.3 自注意力机制

(11)
α1=softmax(μ1),
(12)
R-SelfArg1=α1H1。
(13)
同理,根据式(11)(12)和(13),我们可计算得到Arg2的自注意力表示R-SelfArg2。
1.4 交互式注意力机制
在Ma等[26]工作的基础上,本文对其2.2节中每个单词的隐藏状态ht进行累加,以作为Arg1和Arg2的论元表示:
(14)
(15)
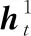
(16)
(17)
其中,γ(·)的计算公式如下(以Arg1为例):
(18)
其中,W∈2dh×2dh为权重矩阵,b∈2dh为偏置。基于论元的交互式注意力权重ρt,我们对论元中每个单词的隐藏状态ht进行更新,并对其内积结果进行累加,以得到论元的交互式注意力表示R-Inter。具体计算公式如下:
(19)
(20)
1.5 堆叠式注意力机制
为了对论元进行更好的表示,本文将1.3节提到的自注意力机制,堆叠于1.4节介绍的交互式注意力机制之上,以构建表示能力更强的堆叠式注意力机制。具体地,针对1.4节的式(16)和(17),本文用1.3节所获得的自注意力表示R-SelfArg1和R-SelfArg2,替换简单的论元表示RArg1和RArg2,以得到堆叠式注意力权重向量βt。具体计算公式如下:
(21)
(22)
基于论元的堆叠式注意力权重βt,我们对论元中每个单词的隐藏状态ht进行更新,并累加其内积结果得到论元的堆叠式注意力表示R-Stack。具体计算公式如下:
(23)
(24)
我们拼接论元的堆叠式注意力表示R-StackArg1和R-StackArg2,并使用全连接层对其进行降维,将降维后的特征向量送入softmax层进行分类,从而获得论元对的类别标签。
1.6 模型训练
在各个关系上,我们使用随机抽样的方法,来构造正负例平衡的训练集。对于每个类别的分类器,我们采用Momentum[27]优化器对参数进行更新,并通过交叉熵(Cross-Entropy)损失函数[28]度量每个样本的预测代价。在实际操作中,给定一个论元对(R1,R2)及其类别标签y,其损失函数定义如下:
访谈中得知,除部分对英语非常感兴趣的学生外,大部分学生以四、六级通过来“终结”英语学习,在通过四、六级考试后大大减少了花费在英语学习上的时间,加之大三之后学校没有开设公共英语课程,学生接触英语的机会越来越少,导致其英语水平随年级升高而退步。
(25)

2 实验
2.1 实验数据
本文在PDTB数据集上对模型的隐式篇章关系识别性能进行评估,并以F1值(F1-score)和准确率(Accuracy)作为性能评价标准。依据前人工作[16],本文采用Sec 02-20作为训练集,Sec 00-01作为开发集(又称为“验证集”),Sec 21-22作为测试集。其中,具体四大类篇章关系Comparison(Comp.)、Contingency(Cont.)、Expansion(Expa.)和Temporal(Temp.)的语料分布情况如表1所示。
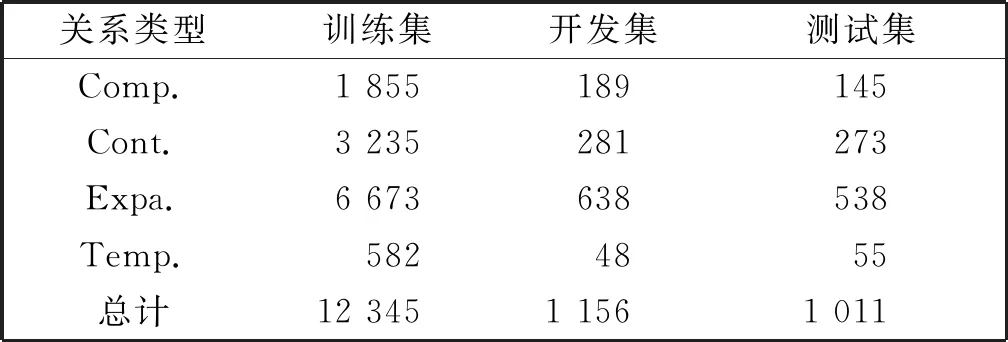
表1 PDTB隐式篇章关系数据分布
由表1可知,各个关系类别上的数据分布不均衡,其中,扩展关系(Expansion)的样本数量远多于时序关系(Temporal)。因此,直接用所有数据训练模型并进行测试的方法倾向于判定实例为样本数量多的类别。同时,在每个关系类别上,其训练集正负例分布不均衡(负例个数远多于正例)。所以针对每个关系类别,我们对负例随机抽样来构造平衡数据,并用其训练一个二分类器。这也是目前隐式篇章关系识别研究中通用的评测方法[18-22]。
2.2 实验设置
本节针对所提模型Stacked-Attention设计了消融实验,来展示所提模型不同部分对分类性能的影响。在实验过程中,所有对比模型的参数设置与本文所提模型保持一致。
1) Bi-LSTM(基准系统):将Arg1和Arg2的词向量表示分别作为Bi-LSTM的输入,以得到每个单词的隐藏状态,将其分别拼接作为论元的隐藏状态表示H1和H2。最后,拼接H1和H2并输入全连接层进行关系分类。
2) Self-Attention(自注意力机制):通过Bi-LSTM得到论元的隐藏状态表示后,使用式(12)计算得到论元的自注意力权重,并通过式(13)更新论元表示向量,以得到的自注意力表示。最后,拼接Arg1和Arg2的自注意力表示向量,作为全连接层的输入并进行分类。
4) Stacked-Attention(堆叠式注意力机制):通过Bi-LSTM编码得到论元的隐藏状态表示后,使用Self-Attention获得Arg1和Arg2的自注意力表示,并将其用于交互式注意力权重的计算(见式(21)和式(22)),以得到堆叠式注意力权重。在此基础上,使用权重向量更新论元表示,以得到Arg1和Arg2的堆叠式注意力表示,将其拼接作为全连接层的输入并进行关系分类。
2.3 参数设置
本文采用预训练好的Glove[14]向量来初始化论元词向量,并设定词向量维度de为50。在训练过程中,批(Batch size)大小为32, LSTM隐藏层的单元数dh为50,自注意力层的权重矩阵维度da为80。本文使用包含一个隐藏层的全连接层,其隐藏层神经元个数为80。为了避免过拟合,我们在全连接层之后使用了dropout,其比率设置为0.1。本文采用交叉熵损失[28]作为模型的损失函数,并使用Momentum[27]优化器对参数进行更新,其学习率设置为0.001。
2.4 实验结果和讨论
本文针对所提模型进行了消融实验。在PDTB四大类关系上,基准模型Bi-LSTM、基于自注意力机制、交互式注意力机制和堆叠式注意力机制的模型分类性能如表2所示。
实验结果表明,相较于基准模型Bi-LSTM,Self-Attention在F1值和准确率上都有所提升,其原因在于自注意力机制能够捕获论元表示中对自身较为重要的特征。同时,Interactive-Attention相较于Bi-LSTM在四大类关系上的分类性能也有所提升,其原因在于交互式注意力机制能够捕获论元之间的交互信息,并使用这一信息对论元表示进行更新,来得到含有交互信息的论元特征。而使用堆叠式注意力机制的模型分类性能优于单独使用自注意力机制或交互式注意力机制,其原因在于基于堆叠式注意力的方法有效地结合了两种注意力机制的信息,不仅关注了论元本身的特征,还融入了另一论元的特征信息。此外,堆叠式注意力机制在四大类关系上的分类性能均优于基准系统,尤其在Temporal关系上,其F1值和准确率相对于基准系统分别提高了6.57和3.82个百分点。
我们与前人工作进行了对比,具体性能如表3所示(表3中前人工作的性能来自原文献)。其中,Bai等[19]使用基于字符、单词、论元及论元对等不同粒度的特征表示方法,且在卷积神经网络和循环神经网络的基础上,使用了残差机制和注意力机制。相较之下,本文所提的Stacked-Attention在模型与论元的表示上较为简单,只使用了预训练好的词向量。尽管如此,本文所提方法仍能在Expansion和Temporal关系上超越该方法。Liu[21]等引入了RST-DT、New York Times Corpus等外部语料库训练多任务模型,以隐式篇章关系识别为主任务,显式篇章关系识别等为辅助任务。对于不同任务,Liu[21]等引入了词、词性、共现等人工特征以增加论元信息量。而本文只使用了标准PDTB隐式语料,并未引入外部特征,但在多个关系上的分类性能仍可超越其方法。

表2 消融实验结果
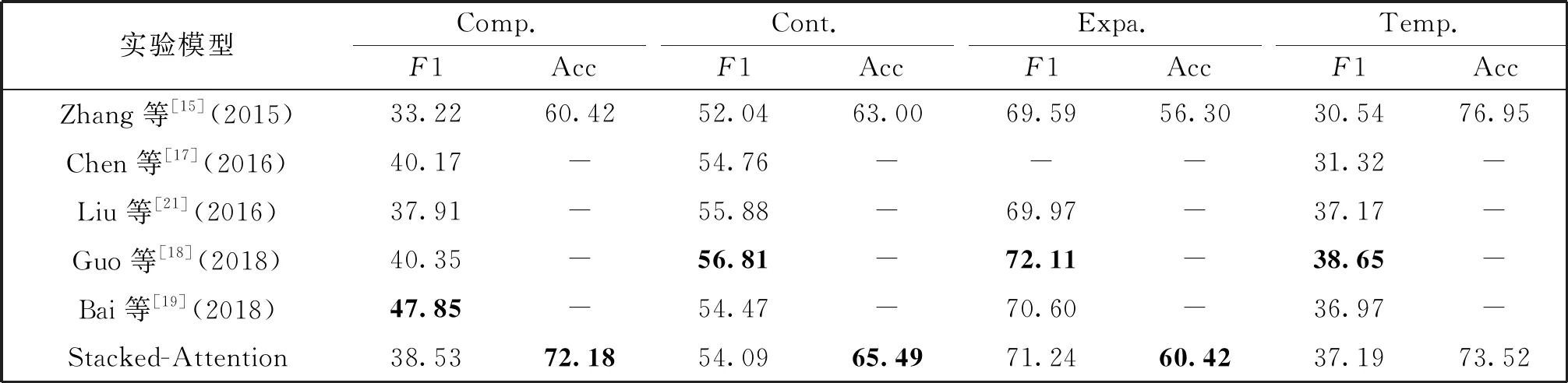
表3 与现有模型对比(%)
由表3可知,Guo等[18]的工作在所有关系上超越了本文所提模型,他们采用Bi-LSTM分别对两个论元进行编码,使用交互式注意力机制更新得到新的论元表示,将新的论元表示输入张量神经网络中得到论元交互特征矩阵。Guo等[18]采用了L1正则化对张量项进行约束,采用L2正则化对其他参数进行约束。为了更好地对比本文所提堆叠式注意力机制和Guo等[18]的工作,我们对其工作进行了复现,并使用堆叠式注意力机制代替他们原文中的交互式注意力机制来进行对比。由于Guo等[18]暂时没有公布其源码,且其原文中有些细节并未详细说明(如L1正则化项的系数等)。因此,本文的复现结果并未达到其原文中的结果。在复现Guo等[18]工作的过程中,本文采用的L1正则化项系数为0.01,L2正则化项系数为0.01,且在张量神经网络中采用的激活函数为tanh。
表4展示了本文复现的Guo等[18]工作的结果(即Guo*)和使用本文所提堆叠式注意力机制代替他们的交互式注意力机制的结果(即Stacked-Attention*)。由表4可知,堆叠式注意力机制在各个关系上的F1值超过了Guo等[18]使用的交互式注意力机制。
本文使用自注意力机制、交互式注意力机制以及堆叠式注意力机制分别编码例3中的论元对,以展示不同注意力机制对论元中各个成分的关注程度(见图3)。其中,每个单词对应的色块颜色越深,表示该单词获得的注意力权重越大。在通常情况下,权重越大的单词会直接影响最后的分类结果。
例3 [Arg1]Lastspring,thecomptroller'sofficecalledahalttoMr.Paul'sfling,givinghimsixmonthstosellthepaintings.
(译文:去年春天,检察官办公室制止了保罗先生的胡闹,给了他六个月的时间来卖这些画。)
[Arg2] [Implicit=Because]Theacquisitionswere"unsafe,unsoundandunauthorized".
(译文:这些对画的收购是“不安全、不健全、未经授权”。)
[篇章关系] Contingency.Cause.Reason。
由图3可知,自注意力机制的特征学习能力较差,对“a”和“the”这种无意义的单词也赋予较高的权重。同样地,交互式注意力机制为Arg1中的“lastspring”和“sixmonth”及Arg2中的“were”赋予了较高的权重,因此其很容易导致此句被误分类为时序关系(Temporal)。而堆叠式注意力机制对Arg1中“paintings” 及Arg2中的“unsafe”、“unsound”和“unauthorized”给予了较高的权重,其中,Arg2中的这三个词解释了Arg1中“sellthepainting”发生的原因,因而基于堆叠式注意力机制的方法能将这个样例正确地分类为偶然性关系(Contingency),但基于另外两种注意力机制的方法则无法对其正确分类。
3 结论
本文旨在研究隐式篇章关系分类任务,并为其提出了基于堆叠式注意力机制的篇章关系分类模型。实验结果表明,本文所提模型获得了比基准系统更好的性能,且其与目前最优的隐式篇章关系分类模型性能可比。但同时,隐式篇章关系分类任务仍然具有很大的挑战性。其主要原因在于训练数据的缺乏,所以目前的分类方法在Temporal等类别上的分类性能仍然不高。因此,在下一步的工作中我们将从两个方面展开研究,首先针对数据缺乏问题,将对PDTB语料进行扩充,从外部数据中筛选出优质的正负样例样本以扩充PDTB语料训练集;其次,将继续优化分类模型,借鉴目前先进的多任务、对抗学习等方法提高模型的判别能力。

表4 与Guo等工作进行对比(%)
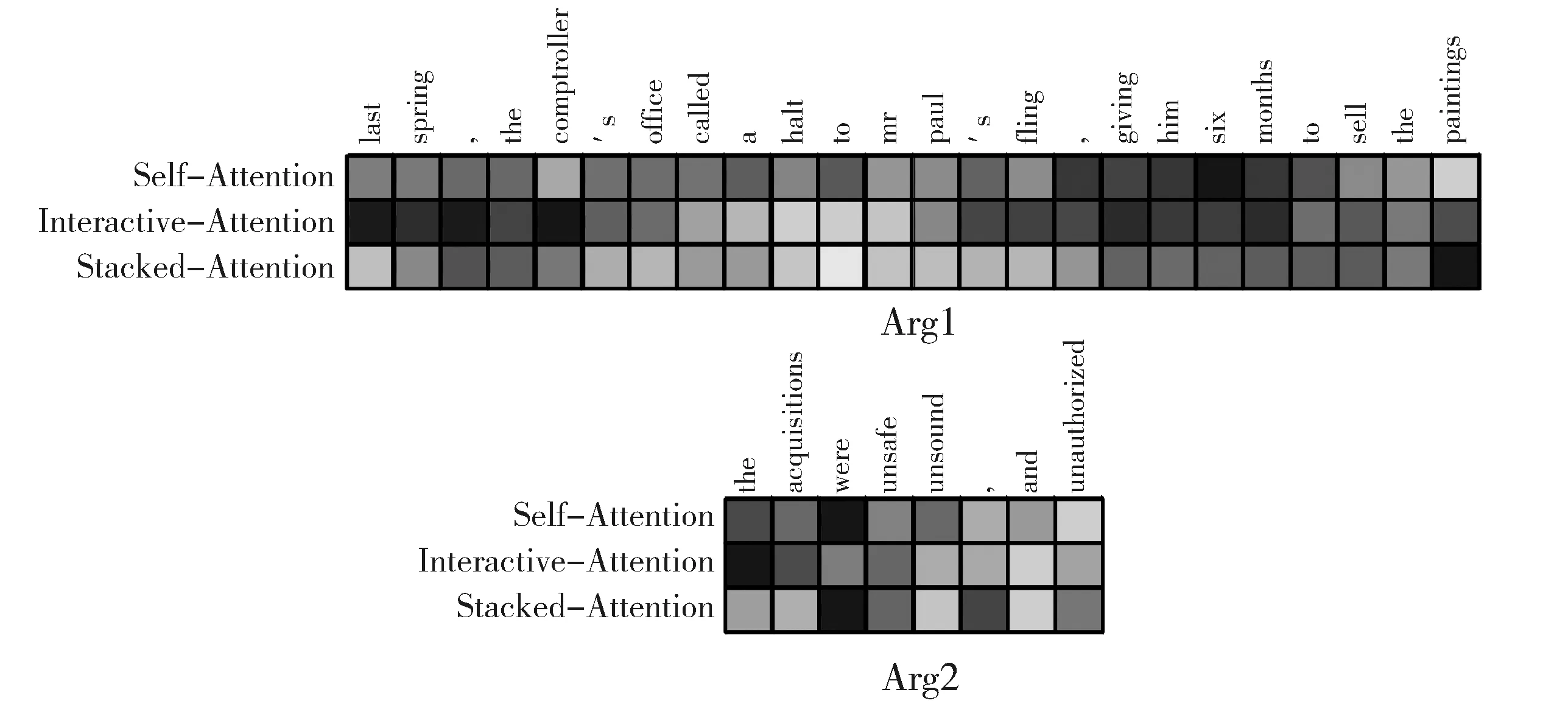
图3 例3在不同注意力机制下的注意力分布灰度图Fig.3 Grey-scale map for attention distribution of example 3 under different attention mechanisms
