针对视频运动向量隐写的深度神经网络检测方法
2020-09-11黄雄波胡永健王宇飞
黄雄波 胡永健,† 王宇飞
(1.华南理工大学 电子与信息学院,广东 广州 510640;2.中新国际联合研究院,广东 广州 510700)
在各种数字隐写载体中,视频由于数据量大、载密程度高而受到了研究者的重视,视频隐写也成为应用最为广泛的一类隐写方法。视频隐写可通过修改视频中的不同内容嵌入密信,如压缩编码中的变换系数[1]、帧内预测模式索引值[2]、分块方式索引值[3]、二进制码流标志位[4]等。目前最常见的视频隐写方式主要是通过修改帧间预测的运动向量来进行嵌密,相关成果已大量见于各种学术期刊及会议论文集[5- 6]。
因基于运动向量的视频隐写方法最为常用,针对该类隐写的检测或称隐写分析方法也最为重要。目前经典的视频运动向量隐写分析方法主要针对运动向量的统计特性[7- 8]、校准方法[9- 10]及局部最优性[11- 12]等。上述方法均通过传统手工设计的视频特征进行隐写判断。
近年来,利用深度神经网络进行隐写分析成为研究的热点之一。现有基于深度神经网络的隐写分析方法主要针对数字图像[13- 16],其中SRNet[17]是目前深度隐写分析的基准网络,其检测性能超过传统的富模型方法[18]。然而,主流的视频隐写大都通过修改压缩域的编码参数或变换系数完成,对视频内容的影响被分散到空域帧图像上的多个像素,反映在每个像素值上的影响细微,这种隐写上的良好性能使得针对空域像素值的隐写检测难以奏效。直觉上可知,若直接以编码参数或变换系数作为深度神经网络的输入,检测效果将会更好,但其实现与直接输入帧图像像素的方法存在较大的差异,因此难以直接将深度学习方法用于隐写分析,具体困难包括:
(1)与图像隐写以像素为嵌入对象相比,每帧上的嵌入对象数量少。具体而言,对于分块变换系数的嵌入,由于存在大量的0值系数,导致嵌入对象少;而对于修改运动向量和预测索引值等编码参数的隐写算法,嵌入对象的数量就更少。
(2)每帧上的嵌入对象分布不均匀。由于在图像纹理区非零分块变换系数多,而在平坦区非零分块变换系数少,使得不同帧图像的嵌入位置在空间上没有对应性;而这种情况对于运动向量和预测索引值更为严重,因为纹理区的分块更加精细,且大小不一,故运动向量和预测索引值的分布更为复杂,导致不同帧图像上的嵌入位置差异更大。
(3)由于存在帧间和帧内编码,而帧内预测块不存在运动向量,使得针对编码参数的嵌入对象在不同帧上的数量差异很大。
另外,在深度神经网络的设计方面,与图像隐写分析网络不同,视频隐写分析网络必须考虑两点:
(1)由于视频不仅含有单帧图像的空间信息,还含有帧与帧之间的关联信息,即时域信息,因此深度神经网络的输入数据必须能够同时反映空域和时域的信息。
(2)视频压缩的码率直接决定了编码参数与变换系数的数值大小,对隐写分析方法性能的影响很大,因此在设计视频隐写分析网络时必须考虑输入数据在不同码率下的表征能力。
上述困难导致尚未在文献中见到直接针对压缩域参数(例如运动向量、预测索引值等)进行隐写检测的深度神经网络。为此,本文以H.265视频的运动向量隐写为例,利用运动向量构造输入矩阵,进而设计对视频码率变化不敏感的深度神经网络检测器。
1 运动向量信息输入矩阵的构造
图1为示例视频连续两帧的局部截图,其大小为256×576,共包括36个64×64的编码树单元。本文以图1为例,介绍如何利用运动向量构造符合深度神经网络输入要求的数据矩阵。
目前构造输入矩阵存在如下问题:
首先,由于运动向量描述的是分块的运动特征,若以运动向量(图1(a)中的箭头)直接作为输入,则深度神经网络将由于数据量不足而难以提取有意义的特征。
其次,图1(a)显示,单个64×64编码树单




图1 H.265视频的运动向量及PU划分Fig.1 Motion vectors and PU partition of H.265 video
元的运动向量差异巨大,个数从不足10个到超过50个不等,分布极为不均匀,难以构造合理有效的深度神经网络输入形式。
此外,帧内预测块没有运动向量。传统运动向量仅存在于帧间预测分块,而在H.265标准中,使用帧间预测的P帧或B帧中的预测单元亦可使用帧内预测模式。图1(b)中的橙色区域使用了帧内预测模式,不存在运动向量。
最后,在视频中,其邻近帧的运动向量必然存在紧密联系。例如,图1(a)中的两帧记录了视频中的同一物体,因此其运动向量也较为相近,在视频隐写分析中如何很好地反映时空域信息也是输入矩阵需要解决的问题。
为解决运动向量数据量不足及分布不均匀的困难,本文根据H.265编码中4×4为最小预测单元划分的特点,提出以4×4像素分块作为运动向量的最小表示单元,以解决每帧图像上运动向量的数量不一致以及不同帧的运动向量空间位置上没有对应关系的问题。此外,这种方法所构造的输入矩阵尺寸仅缩减为原帧图像的1/16,仍可提供充足的输入数据量供深度神经网络提取特征。
考虑到运动向量由水平分量和垂直分量构成,本文分别将其作为输入矩阵的两个通道。如图2所示,编码树单元中白色方格表示帧间预测单元,括号内的数字依次表示该单元运动向量的水平分量、垂直分量及参考帧索引值。以图2左上角红框的16×16分块的帧间预测单元为例,其水平分量为4,垂直分量为1,参考帧索引值为1。在构造输入矩阵时,令水平分量通道中左上角4×4分块取值均为4,垂直分量通道中左上角4×4分块取值均为1。其余帧间预测单元按此方法进行处理。
图2中的阴影方格表示不存在运动向量的帧内预测单元。为解决帧内预测块不存在运动向量的问题,本文利用运动向量的参考帧索引来构建输入矩阵的另一个通道。当运动向量存在时,参考帧索引表示参考帧与当前帧的距离,其索引值为一个正整数;当运动向量不存在时,参考帧索引值为-1。如图2所示,左上角红框内16×16分块的帧间预测单元运动向量参考帧索引值为1,则令参考帧索引通道左上角4×4分块取值均为1。而对于编码树单元中部蓝框内16×16分块的帧内预测单元,则在构造输入矩阵时令水平分量和垂直分量通道中部4×4分块取值均为0,而参考帧索引通道中部4×4分块取值均为-1。依此方法可处理所有帧内预测单元。本文提出的这种处理方式可确保在没有运动向量的帧内预测单元仍可构造网络输入矩阵。
为解决深度神经网络的时空域特征信息输入问题,本文提出了选择K帧连续的帧间预测帧(P帧或B帧)组成1个单元进行运动向量信息输入。以K帧连续P帧为例,由其构造得到的运动向量矩阵具有3K个通道,其中通道0,3,6,…,3K-3分别表示各帧4×4分块运动向量的水平分量,通道1,4,7,…,3K-2分别表示各帧4×4分块运动向量的垂直分量,通道2,5,8,…,3K-1分别表示各帧4×4分块参考帧的索引值。
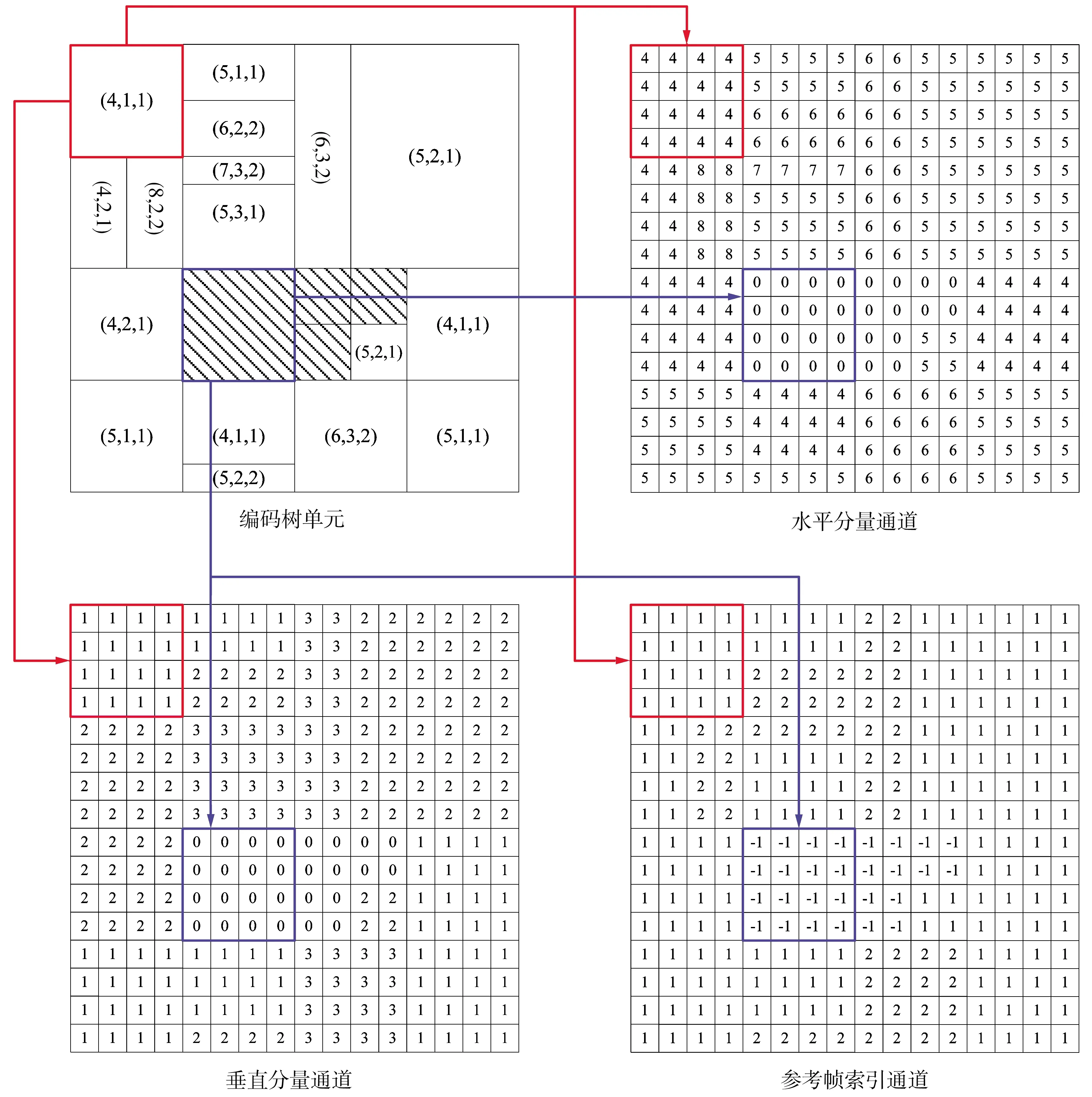
图2 运动向量的输入矩阵构造示例Fig.2 Example of the input matrix construction with motion vector
需要指出的是,载密视频与载体视频的运动向量之间差异十分细微,若简单地对输入运动向量矩阵进行归一化,将进一步缩小载体与载密视频的差异。根据作者的实验,本文对所有输入样本均不采用归一化预处理,而是直接保持原始数据的形式输入网络。
2 视频运动向量隐写分析网络设计
针对视频运动向量隐写的特点,本文以目前性能优异的图像隐写分析网络SRNet[17]为基准网络,提出了一种改进的视频隐写分析残差网络(VSRNet)。
2.1 网络设计分析
设计隐写分析网络首先必须考虑如何准确提取隐写特征,而提取特征必须考虑输入数据的特征表达能力。由于运动向量与视频的压缩程度有密切关系,即与视频的码率有关,因此所设计的隐写分析网络必须能够适用于不同的码率,这一点与图像隐写分析网络有明显的不同。
在低码率下视频运动向量的长度往往小于对应的高码率下视频运动向量的长度。当低码率视频嵌密后,由于其运动向量长度较短,向量的变化比例要大于高码率视频的情况,因而嵌入操作对运动向量的修改更为明显。对于高码率视频,情况则刚好相反。这种由不同码率引起的输入数据表征能力差异会直接影响深度神经网络的隐写检测能力。
为了减轻码率对网络性能的影响,本文在设计网络时,引入了与视频运动向量相应块在空域上所对应的像素值预测残差作为网络的另一路输入。隐写算法修改运动向量会破坏视频原本的最优预测,进而使得像素值预测准确度下降,预测残差增大。低码率视频的像素值预测残差通常大于对应的高码率视频。当低码率视频嵌密后,由于其像素值预测残差较大,像素值预测残差变化比例要小于高码率视频的情况,隐写对像素值预测残差引起的变化更不明显。对于高码率视频,情况则刚好相反。此趋势与运动向量信息相反,两者形成互补,故将两路同时输入可以更好地反映隐写嵌入所带来的形变。本文利用运动向量和像素值预测残差在不同码率下的互补表征能力,可以有效地改善深度神经网络的检测性能。
由于密信嵌入通常只发生在亮度分量,本文构建的网络输入也只考虑亮度分量的残差信息。为避免削弱载体与载密视频间的差异,与1.2节中处理运动向量类似,预测残差样本也不进行归一化处理。为利用时域信息,同样将K帧连续帧间预测帧组成1个单元,从视频码流中提取的亮度分量预测残差图像按次序堆叠,构成通道数为K的预测残差信息矩阵,作为VSRNet的另一路输入。
2.2 网络结构
VSRNet包含4种基本的模块,与原始的SRNet基本相同,分别为Layer Type 1、Layer Type 2、Layer Type 3及Layer Type 4,其结构如图3所示。图中Conv 3×3及Conv 1×1分别表示尺寸为3×3及1×1的卷积核,Stride 1和Stride 2分别表示滑动步长为1和2,BN代表批量正规化层,ReLU代表ReLU激活函数,Avg Pooling 3×3代表滑动窗口尺寸为3×3的平均池化层,Global Avg Pooling代表全局平均池化层。Layer Type 1和Layer Type 2保持特征图分辨率及通道数不变,Layer Type 3输出特征图宽高均缩减一半且通道数也按需进行了调整,Layer Type 4输出维度为输入特征图通道数2倍的特征向量。
如图3(e)所示,VSRNet的双路输入及信息融合是对基准网络的重要改进。结构图中的L1-L12代表网络的基本模块序号,T1-T4分别代表Layer Type 1、Layer Type 2、Layer Type 3和Layer Type 4模块,MV和RE分别代表运动向量和预测残差的输入分支,括号中的数字表示模块输出的特征图通道数。由于预测残差矩阵的宽高均为运动向量矩阵的4倍,因此在预测残差输入分支中的最后2个Layer Type 2模块之后,分别添加一层卷积核尺寸为3×3、滑动步长为2的卷积层,将输入特征图的宽高均缩减一半。经过2层该种卷积层的处理,预测残差分支的特征图分辨率将变得与运动向量分支的特征图一致。其后两分支的特征图按通道维度拼接,并通过卷积层将各通道进一步融合。网络提取得到512维的特征向量,最后通过全连接层及Softmax激活函数,输出载体视频和载密视频的二分类结果。
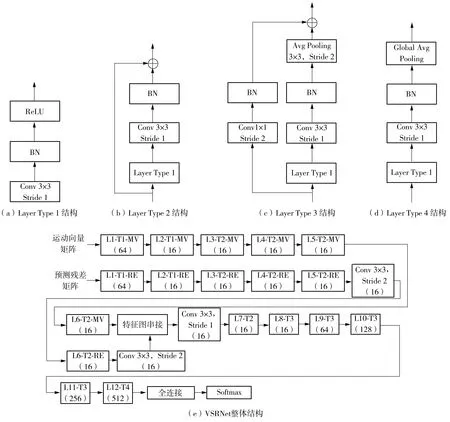
图3 VSRNet结构图Fig.3 Structure of VSRNet
3 实验与结果分析
基于H.265视频运动向量修改的隐写算法相对较少,为验证文中提出的深度神经网络的隐写分析性能,将2种针对H.264视频运动向量修改的经典隐写方法(Aly方法[5]和Xu方法[6])平行推广到H.265视频。选取14段经典的CIF分辨率(352×288)实验视频(akiyo、city、coastguard、container、crew、deadline、foreman、harbour、highway、mobile、news、paris、soccer及students),截取其前300帧用于实验。首先将部分载密和载体视频作为训练样本,对VSRNet进行训练。然后将剩余部分的载密和载体视频作为测试样本,利用训练好的VSRNet网络进行隐写分析检测。
3.1 样本数据生成
样本数据的生成按如下步骤进行:
(1)从3种码率(100、250及750 kb/s)中选定一种。
(2)利用H.265标准,根据选定码率对14段实验视频进行编码,生成载体视频。编码时设定I帧周期为32帧,且只使用P帧,则对于300帧的YUV视频,在编码后将含有10帧I帧和290帧P帧。
(3)从Aly方法和Xu方法中选定一种作为视频隐写嵌密方法。
(4)利用选定的隐写方法,以随机生成的二进制码流作为密信,以0.2 b/mv的嵌入率对14段载体视频进行嵌密。
(5)返回步骤(3),选择另一种隐写方法,直至全部隐写方法都被使用过。
(6)对步骤(2)至步骤(5)生成的42段压缩视频中的每一段,利用一个K帧长度的滑动窗口,以1帧为步长,在视频中从前往后滑动,每次取出连续的K帧。若K帧全为P帧,则从该K帧组成的单元中提取出运动向量及预测残差作为输入样本,否则将该K帧组成的单元舍弃。
(7)返回步骤(1),选择另一种码率,直至3种码率都被使用过。
3.2 网络训练参数
对应载体与载密视频相同位置的样本将组成样本对,其后通过输入样本对来训练VSRNet,训练的具体参数介绍如下。
由于VSRNet进行的是载体和载密视频样本二分类的问题,因此在进行网络训练时采用交叉熵作为损失函数,即
L=-ylnp-(1-y)ln(1-p)
(1)
式中:L为一个样本的交叉熵损失;y为样本的实际标签,取值为0或1;p为网络预测样本是标签1的概率。
对于训练中送入网络的同一批N个样本,其整体的交叉熵损失Lbatch为批内各样本损失的平均值,即
(2)
其中,Li为批内第i个样本按式(1)计算所得的交叉熵损失。实验使用Nvidia的GTX1080Ti显卡,其显存为11 GB。考虑到硬件的限制,实验中批量样本的数量设定为N=24,即为12对载体载密样本。另外,根据硬件限制及编码参数设置,设定样本中连续帧的数量K=4。
训练过程中采用的优化方法为Adam算法,初始学习率设为0.001。训练过程中对预测准确率进行监控,当连续15个epoch后准确率仍无提高,则将原学习率乘以0.9,作为下一个epoch的学习率。当连续100个epoch后准确率仍无提高,则认为训练已趋于稳定,进而结束训练,获得最终模型。
3.3 训练测试流程
对于同一码率下由相同隐写方法生成的样本,采用交叉验证的方式来训练测试,具体步骤如下:
(1)根据原始视频,将样本随机分为7份,每份包含2段原始视频对应的载体和载密样本。
(2)选择其中1份样本作为测试样本,1份测试样本包括2段载体视频和2段载密视频,4段视频的长度和编码结构均相同。
(3)其余6份样本按3.2节设定的参数对VSRNet进行训练。
(4)用训练好的VSRNet对测试样本进行测试,获得检测准确率。设测试样本中一段视频含有M个样本,则1份测试样本共含有4M个样本,该份样本的检测准确率R为
(3)
其中,Mc为得到正确分类的样本个数。
(5)返回步骤(2),选择另一份样本作为测试样本,直到所有7份样本都被用作过测试样本,得到7次测试的检测准确率。
(6)计算7次检测准确率的平均值,得到VSRNet在此码率和隐写方法条件下的隐写分析检测准确率。
按照上述步骤,得到VSRNet在3种码率(100、250及750 kb/s)和2种隐写方法(Aly及Xu方法)组合而成的6种条件下的隐写分析检测准确率。
3.4 2种隐写方法的检测结果及分析
按照3.3节所描述的流程进行训练测试,Aly和Xu方法的样本检测准确率如表1所示,表中视频一列中每两段视频组成一份测试样本,按3.3节步骤(4)计算得到样本的检测准确率,最后计算7份测试样本检测准确率的平均值。从表中可以看到:VSRNet的检测性能总体上随视频码率的增加而提高,这与其他传统隐写分析方法类似,说明本文输入矩阵的设计是有效的;在不同视频码率下VSRNet检测性能的波动总体较小,说明所设计的双路输入是合理的;VSRNet对于Xu方法的样本检测性能要弱于Aly方法的样本,造成这一现象的原因在于Xu方法在嵌密时对视频运动向量的修改程度更小,故对视频造成的失真更小,安全性更高。

表1 不同视频码率下两种方法的样本的检测结果
3.5 与经典视频隐写分析方法的性能比较
为了更全面地展示VSRNet的检测性能,将VSRNet与2种经典视频隐写分析方法AoSO[11]和IMVRB[10]进行了比较。图4给出了VSRNet、AoSO和IMVRB对于Aly和Xu方法在不同视频码率下的平均检测准确率,其中VSRNet的平均检测准确率为表1中准确率的平均值。
由图4可以看到:在100和250kb/s码率下,VSRNet对2种隐写方法的检测性能均超过了AoSO和IMVRB,说明本文隐写方法对视频压缩有良好的稳健性;当视频码率为750 kb/s时,本文隐写方法的检测性能略有提高,但AoSO和IMVRB的检测性能改善更大,超过本文方法。
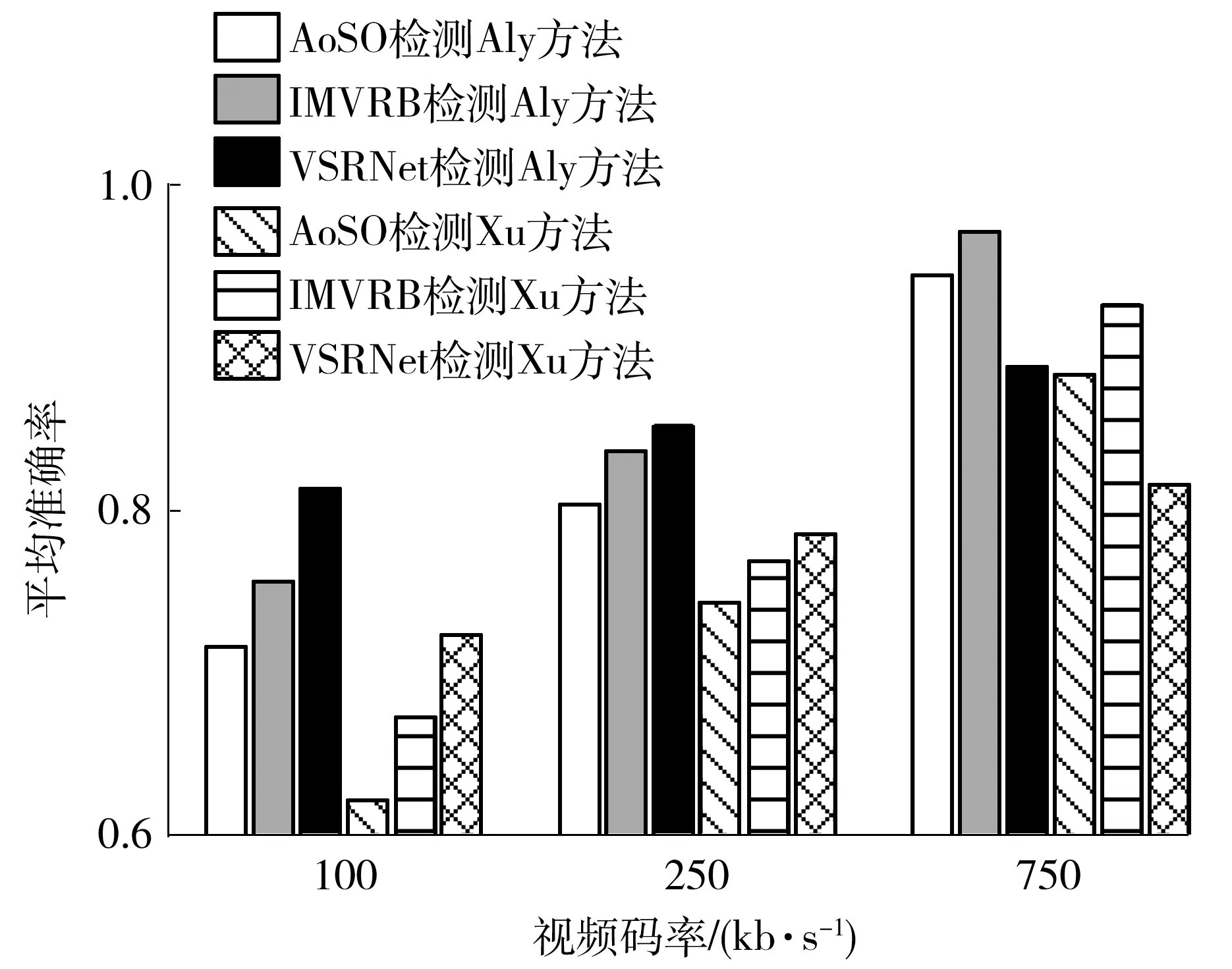
图4 3种隐写分析方法在不同视频码率下的检测准确率比较
造成上述现象的原因在于:AoSO和IMVRB为专用隐写分析方法,针对局部的运动向量来提取特征时灵敏度高但稳健性不够强;而VSRNet则是采用连续数帧来提取一般性时空域特征的深度学习方法,灵敏度稍低但稳健性更强。具体而言,AoSO将可用于嵌密的运动向量进行水平或垂直分量的+1或-1修改,然后把修改后向量对应的编码块预测像素与实际像素的绝对误差和(SAD)作为特征;IMVRB则是将待测视频解码后按照相同的参数重新编码,再从重编码后可用于嵌密的向量变化及其对应编码块的SAD中提取特征。AoSO和IMVRB都集中从可嵌密的运动向量及其对应编码块中提取特征,舍弃了H.265视频中大量无法用于嵌密的skip模式编码块和merge模式编码块,而且IMVRB进一步考虑了运动向量的变化,故其检测性能要优于AoSO。当视频码率较高时,视频预测更为准确,细节保留更多,修改运动向量嵌密后导致编码块的SAD变化显著,因此针对局部检测的专用方法检测性能较好。相比之下,VSRNet的全局特征受到无法嵌密的向量及其对应编码块的影响,检测性能略低于专用方法。然而,随着视频码率的下降,视频的细节丢失增多,载体与载密的SAD差异减小,只针对局部特征检测的传统方法的性能下降严重,而VSRNet因利用了全局特征,可将修改运动向量导致预测误差扩散的差异囊括其中,从而使得载体与载密视频区分度更大,保证了检测性能不会快速下降,而且优于对比的2种传统方法。
以上分析结果表明,采用运动向量与像素值预测残差双路输入的设计能增强VSRNet对不同码率视频的稳健性。
4 结语
由于主流视频隐写算法大多通过修改压缩域的编码参数来实现信息隐藏,嵌入对象与空域图像像素存在较大的差异,导致无法直接将常规用于图像隐写分析的深度神经网络推广到视频隐写分析。本文针对在视频隐写分析中应用深度神经网络存在的难点,重点解决了以运动向量为嵌入对象的视频隐写分析中数据输入矩阵的构造以及减弱码率影响的深度神经网络结构设计问题,并基于目前性能最好的图像隐写分析网络SRNet,提出了一种改进的深度神经网络检测器。实验结果表明,文中提出的方法对中低码率的视频检测准确率明显高于两种传统的视频隐写分析方法,且对不同码率的视频检测性能平稳。
本文提出的方法对其他修改压缩域编码参数的视频隐写检测网络设计具有很好的参考价值,为利用深度神经网络解决嵌入对象少、分布不均匀且特征提取受码率影响大的视频隐写检测提供了极为有意义的尝试。
