集成学习在高误码率下AOS协议识别中的应用研究
2020-09-11王春梅姚秀娟
朱 明 王春梅 姚秀娟 李 雪
(1.中国科学院国家空间科学中心,北京 100190;2.中国科学院大学,北京 100049)
1 引 言
随着空间通信服务需求多样化发展,空间业务种类不断增多,实现卫星星座异构网络的融合,构建天地一体化的通信系统成了未来卫星通信网络技术发展的必然趋势[1,2]。由于卫星星座异构网络是由面向不同通信需求、采用不同接入方式及应用不同通信协议的多颗卫星组成,面对天地一体化通信系统中天基网络高误码率的传输特点,为实现天基网络及地基网络的融合,并保证各个异构网络之间的数据能够高效可靠的传输,星上需要具备快速且适应高误码率的协议识别功能。
协议识别是采用一定算法和工具,通过特征分析,确定目标信息所采用的协议类型[1]。由于识别算法的好坏直接决定协议识别的性能[3],所以对识别算法的研究极为重要。文献[3]中利用频繁项集挖掘的算法对CCSDS协议中的数据链路层协议进行识别。而基于机器学习的方法是根据比特流所表现出的统计特征,达到对比特流自动分类目的[4]。文献[4]中对模式匹配和机器学习的识别技术进行了深入研究。集成学习作为机器学习的一个分支,随着集成学习的不断发展,已经被广泛用于解决各种实际的分类和回归问题,例如:天气预测、医疗疾病诊断、遥感数据分析、时间序列分析、蛋白质结构分类、网络异常入侵检测等[5]。此外,目前空间链路层协议识别方法在较高误码率的情况下还不能保持较好且稳定的识别效果。
鉴于此,通过对AOS协议和集成学习模型算法的研究,使用集成学习模型,设计一种基于集成学习的AOS协议识别方法,构建该AOS协议识别系统,从而达到对AOS协议有效识别的目的,并通过对比实验,验证该AOS协议识别系统的识别准确率、识别效率以及在高误码率情况下的稳定性。
2 AOS协议及其帧格式
为了适应航天任务对空间科学卫星数据处理系统的更高要求,CCSDS提出了AOS协议。目前,AOS协议系统已经成为各国航天任务使用的标准系统,也是在航天任务中被广泛采用的数据链路层协议。AOS协议与OSI模型的对应关系如图1所示[6]。从图1中可以看出,AOS协议处于CCSDS分层中的数据链路协议子层,对应着OSI分层的数据链路层。为了在信噪比较低的空间链路实现稳定可靠的传输,AOS协议采用固定长度的数据传输数据[7]。AOS协议的数据帧结构如图2所示[6,8],主帧头的帧结构如图3所示[6]。

图1 与OSI模型的对应关系框图Fig.1 Correspondence between AOS protocol and OSI model
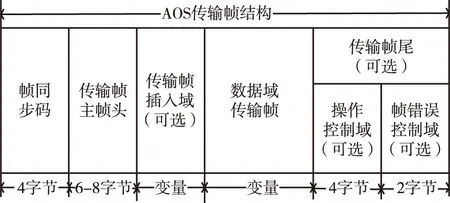
图2 AOS传输帧结构图Fig.2 AOS transmission frame structure
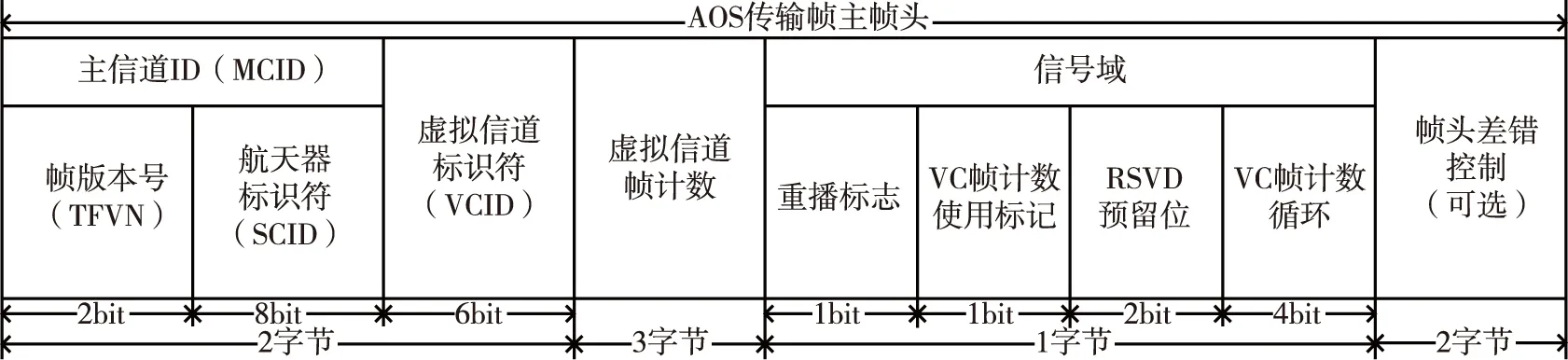
图3 AOS协议主帧头结构图Fig.3 Main frame header structure of AOS protocol
3 数据集仿真
仿真的数据集共包含两部分,分别是训练集与测试集。每种数据集均由正例AOS协议数据和负例TM与HDLC协议数据组成。为了更好的体现正例AOS协议数据的识别评价指标,在实验数据集中应含有与正例数量相当的负例数据,本实验的正、负例实验数据数量均为62768帧。由于传输帧长度主要区别在数据域部分,对协议的分类没有影响,因此本章实验部分的帧长度均以CCSDS-TM同步与信道编码蓝皮书中Turbo编码的要求块长度223字节为例。由于本文的实验为两部分,因此本文也仿真了两种测试集。第一部分实验的测试集误码率为10-7,共125536帧数据。第二部分实验的测试集误码率分别为10-1,10-3,10-5,10-7,每个误码率均有125536帧测试数据。噪声方式均采用高斯白噪声。
3.1 正例数据仿真
本文正例AOS协议的仿真数据传输帧结构如图4所示,其中数据传输帧数据域部分为213字节。

图4 正例数据结构图Fig.4 Positive example data structure
a)帧同步码(SYN,4字节):CCSDS协议体系标准建议数据固定为“0x1ACFFC1D”;
b)帧版本号(TPVN,2bit):这2bits字段将把数据单元标识为推荐标准定义的传输帧,CCSDS标准建议的值是固定为“01”,表示虚拟信道数据单元。但是该字段包含两位,因此会出现4种情况;
c)航天器标识符(SCID,8bit):表示航天器的标识,每次任务中固定;
d)虚拟信道标识符(VCID,6bit):最多标识64个;
e)虚拟信道帧计数(VCFC,3字节):最多224个;
f)信号域(Signal,8bit):该域是由1位的重播标记、1位的VC帧计数使用标记、2位的RSVD预留位和4位的VC帧计数循环组成;
g)传输帧数据域(Data,213字节):数据域填充为正弦。
3.2 负例数据仿真
仿真的负例数据包含两种协议数据,一种是TM协议[9],另外一种是HDLC协议[10]。TM协议的仿真结构如图5所示[9],其中传输帧数据域部分占213字节。

图5 负例TM数据结构图Fig.5 Negative example TM data structure
a)帧同步码(SYN,4字节):CCSDS协议体系标准建议数据固定为“0x1ACFFC1D”;
b)帧版本号(TPVN,2bit):CCSDS协议体系标准建议数据固定为“00”,其他同3.1节该字段说明;
c)航天器标识符(SCID,10bit):表示航天器的标识,每次任务中固定;
d)虚拟信道标识符(VCID,3bit):最多标识8个;
e)OCF标记(OCFF,1bit):该位标记用来表示OCF标记是否使用。根据CCSDS协议体系标准建议,“1”表示使用该字段;“0”不使用该字段;
f)主信道帧计数(MCFC,1字节):最多256个;
g)虚拟信道帧计数(VCFC,1字节):同上;
h)传输帧数据域状态(TFDFS,2字节):此部分共包含5个字段,分别是:1)传输帧副导头标识(TFSHF,1bit):该标识位用来显示传输帧中此字段是否使用。根据CCSDS协议体系标准建议,“1”表示使用,“0”表示不使用,并且在整个任务过程中保持不变;2)同步标识(SF,1bit):插入传输帧数据域部分的数据类型在该标识位显示;3)包顺序标志(POF,1bit):若SF为“0”,则包顺序标志为“0”,表示数据包顺序标志保留供CCSDS将来使用。若SF为“1”,包顺序标志的使用未定义;4)段长标识符(SLI,2bits):若SF为“0”,则段长标识符为“11”。若SF为“1”,则段长标识符未定义;5)首导头指针(FHP,11bits):如果SF设置为“0”,则首导头指针应包含从传输帧数据字段开始的第一个分组的第一个八位字节的位置,如果SF设置为全“0”,则首导头指针未定义。特殊的,如果在传输帧数据字段中没有数据包开始,则首导头指针应设置为“ 11111111111”。如果传输帧的传输帧数据字段中只包含空闲数据,则首导头指针应设置为“111111110”;
i)数据域(Data,213字节):数据域填充为正弦。
HDLC协议的仿真结构如图6所示[11],其中传输帧数据域部分占217字节。
a)起始标志(StartFlag,8bit):数据固定为0x7E;
b)地址数据(AdressData,8bit):数据填充方式为递增序列;
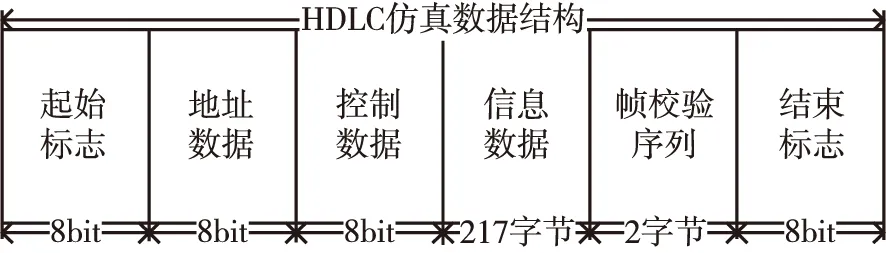
图6 负例HDLC数据结构图Fig.6 Negative HDLC data structure
c)控制数据(ControlData,8bit):可为信息帧、监控帧和无编码帧[11];
d)信息数据(Data,217字节):数据填充方式为正弦;
e)帧校验序列字段(FrameCheckSqquence,2字节):对起始标志字段“0x7E”和结束标志字段“0x7E”之间的所有内容进行校验;
f)结束标志(OverFlag,8bit):数据固定为0x7E。
4 集成学习的AOS协议识别系统
基于集成学习的AOS协议识别流程如图7所示。数据预处理的主要任务是生成并转换成完整的可用数据,其包括数据规整、数据集成、特征选取及数据标准化四部分。模型构建的主要任务是通过调用一些简单的基分类学习模型,从而获得多个不同的基学习机,然后按照集成方法将基学习机组合成一个强分类学习器作为最终的集成学习机[5],最后达到协议识别的目的。
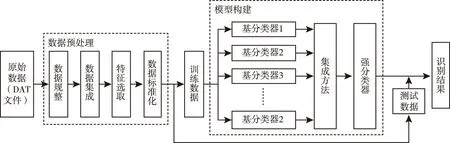
图7 集成学习识别流程图Fig.7 Ensemble learning identification process
4.1 数据预处理
原始仿真数据存储在二进制的DAT数据文件中,为了得到规整的结构化数据集,因此需要规整原始数据。本文根据第3节中正例AOS协议与负例TM与HDLC协议数据结构对原始正例AOS协议数据与负例TM与HDLC协议数据分别进行截取,从而获得具有结构化的正负例数据。数据规整操作共包含判定同步头、判定帧长度、验证帧长度和传输帧截取四个操做。
首先是判定同步头,即将原始的数据文件采用模式串匹配的方法匹配同步头。为了防止数据不完整对训练的影响,匹配完成后将进行冗余剔除操作,即剔除首个同步头之前的冗余数据。然后,进行判定帧长度,判定帧长度的方法是比较相邻两个同步头之间的差距长度。接下来进行验证帧长度,验证帧长度的方法是根据连续判断几个传输帧帧长度,然后对比每个帧长度的判定结果是否相同,若大部分相同,则表明长度判定准确。最后是传输帧截取,即根据传输帧长度截取每个传输帧;根据字段长度截取传输帧字段。最终获得截取后的结构化数据。
从图4、图5及图6可知,正例与负例的数据结构是不相同的。为了防止正负例的数据结构不一致影响模型的训练,本文据根据字段的类别将正例数据和负例数集成成为具有统一结构的数据集。详细的数据集成内容为:
1)将负例HDLC数据的StartFlag与负例TM、正例AOS数据的SYN集成为SYN;
2)负例HDLC数据的AdressData与负例TM、正例AOS数据的VCFC集成为VCFC;
3)负例HDLC数据的ControlData、负例TM数据的TFDFS与正例AOS数据的Signal集成为Signal;
4)负例HDLC、TM数据的Data与正例AOS数据的Data集成为Data。
集成后的数据集结构如图8所示,英文标识含义详见第二节。其中OCFF为OCF标记,MCFC为主信道帧计数,FCS为帧校验序列,OF为结束标志,这四部分均为负例的结构,详见3.2节负例数据仿真。若数据不含该特征,则填“0”占位。y为数据标签,正例为1,负例为0。

图8 数据集结构示意图Fig.8 Dataset structure
数据集成完成后,接下来对图8所示的数据集的特征进行分析及选取。根据第3节的字段含义可知,Data是一个必选字段,表示传输数据。但是传输的数据信息对协议的分类并没有实际的意义,因此在对模型训练时,不选取Data特征作为训练特征。
对于同一特征,不同样本中的取值可能相差非常大,一些非常小或者非常大的数据会影响模型的正常训练。因此本文通过标准化处理来避免极值对训练的影响,标准化处理计算公式如式(1)所示
(1)
式中:X'——新生成的特征值;X——原始特征值;Mean——该特征所有值的均值;StandardDeviation——该特征的标准差。
经过数据预处理以后,即可得到可使用的结构化和标准化的数据集。
4.2 模型构建
由图7可知,模型构建是由基分类器、集成方法和强分类器三部分组成。其中,本文的基分类器为CART树。
模型构建的关键环节在于模型所采用的集成方法。目前,集成学习已经形成了Bagging和Boosting两种方法。
Bagging方法的过程如下:
过程:
1:Fort= 1 toT
2:ht=C(D,Dbs),依据Bootstrap分布,随机建立子集训练基分类器;
3:E=E∪Ct,将训练完的基分类机集成;
4:end For
输出:强学习机E及预测结果。
该方法的主要思想是对原始训练集通过有放回的随机抽样,为每个CART树都构造出一个大小相同但训练个体不同的训练集,从而训练出有分类差异的CART树模型[12]。在对新个体进行预测的时候,将每个基分类器预测的结果采取多数投票的方式最终确定[12]。通过Bagging方法形成的典型的强分类器算法为随机森林(Random Forests)算法。该方法的解释性较强,并且由于决策结果是由多棵树共同决定,因此该方法对异常值、缺失值都不敏感。除此之外,它还能够处理高维数据且不需要特征选择。
而Boosting方法的过程如下:
过程:
1:Fort= 1 toT
2:ht=C(Dt),训练基分类器;
3:θ(t)=P(ht(x)≠f(x)),计算ht误差;
4:Dt+1=Adjust(Dt,θt),调整样本分布;
5:E=E∪Ct,将训练完的基分类机集成;
6:end For
输出:强学习机E及预测结果。
该方法的主要思想是首先在已有的样本集上开始训练基分类器(即分类回归树),之后在下一轮迭代过程中,将打破基分类器在已有样本上的优势,提高错误样本的关注度,即提高每一轮训练过程中错误样本的权重,迫使下一个基分类器更加关注错误样本[13]。与此同时,该算法还是用了加权投票的策略,即为准确率较高的基分类器提高权值,进而提高整个强分类器的分类准确率[13]。采用该思想典型分类算法是Adaboost算法。而同是基于Boosting方法的梯度提升决策树(GBDT)算法的主要思想是使用下一颗CART树去拟合本轮CART树产生的残差,使每轮的残值逐步减小[14]。这两种方法均不需要复杂的特征工程。此外,它对缺失值鲁棒,因此预测的结果比较稳定。
5 模型的评价指标
本文采用F1-score和AUC(Area Under ROC Curve)作为评价指标。对于AOS协议识别结果有四种情况,分别是真阳性TP即预测为正,实际也为正;假阳性FP即预测为正,但实际为负;假阴性FN即预测为负,但实际为正;真阴性TN即预测为负,实际也为负。
5.1 F1分数
F1-score是统计学中用来衡量分类问题中二分类问题准确度的一种评价指标,其计算公式如式(2)
(2)
式中:precision——被预测的正例中真实也为正的比例,即准确率;recall——被预测的正例占总正例的比例,即召回率。
其中,
(3)
(4)
它能够综合考量精确率及召回率,其值的范围是0-1,该值越大,说明该AOS协议识别系统的识别准确率越高。
5.2 ROC曲线
ROC曲线是以假阳性率,即FP的概率为横轴,范围为0-1;以真阳性率,即TP的概率为纵轴,范围为0-1。两种概率构成坐标轴形成曲线图,但是从ROC曲线图中很难对多种模型进行量化的比较,因此本文引入了AUC作为本实验的评价指标。AUC是ROC曲线下的面积,反映的是模型对样本的排序能力,其值的范围是0-1,且该值越大,说明该AOS协议识别系统的识别准确率越高。
6 实验验证与结果分析
为了验证基于集成学习的空间链路层AOS协议识别系统在识别AOS协议的识别准确率、识别效率和高误码率情况下的稳定性。本文的实验分为两部分,第一部分是集成学习模型与其他非集成学习模型的对比实验;第一部分实验将三种集成学习模型:Adaboost、GBDT及RandomForest模型与三种非集成学习算法:基于径向基核函数的支持向量机(SVM_rbf)、基于平均权重的K邻近(KNN_uni)、基于距离加权的K邻近(KNN_dis)模型进行对比。各模型参数均采用默认参数,测试数据集的误码率为10-7。
根据以上两种评价指标,6种协议识别模型的识别结果见表1。通过对表1分析可以看出,在F1-score和AUC两种评价指标情况下,Adaboost、GBDT及RandomForest三种集成学习模型的识别准确率与KNN_uni、KNN_dis、SVM_rbf等单学习模型的识别准确率相当,表明了该系统的可行性。但是,从测试运行时间上看,Adaboost、GBDT及RandomFroest三种集成学习模型的运行时间远好于KNN_uni、KNN_dis、SVM_rbf等单学习模型的运行时间,且集成模型最差的Adaboost方法运行时间比非集成学习模型最优的SVM方法的运行时间提升95.94%,表明了该系统具有更好的运行效率方面的优势。
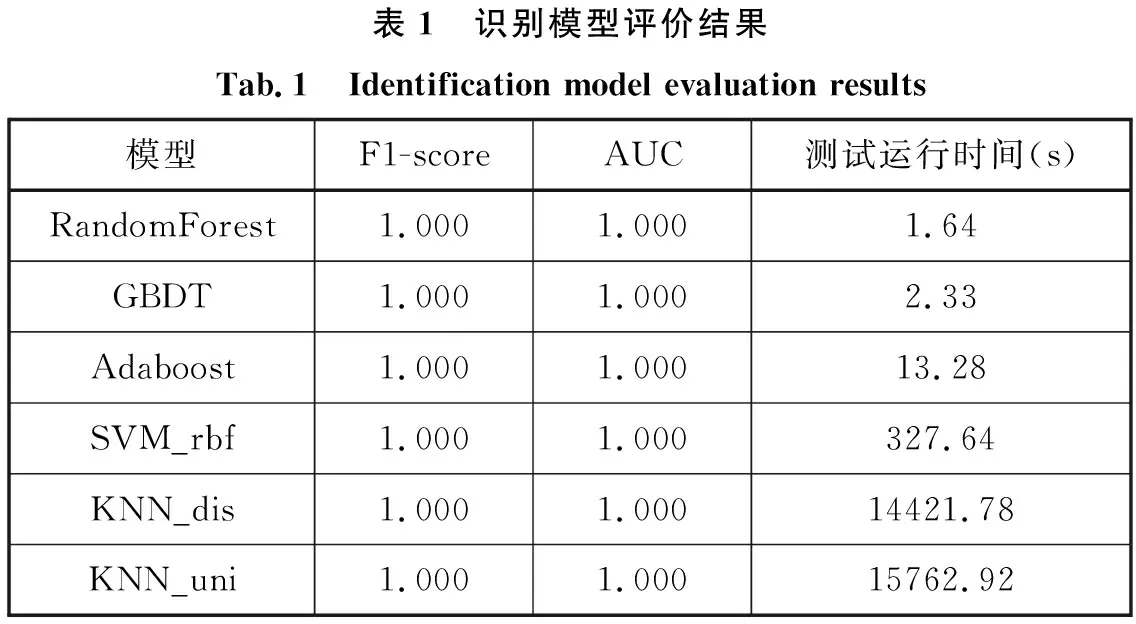
表1 识别模型评价结果Tab.1 Identification model evaluation results模型F1-scoreAUC测试运行时间(s)RandomForest1.0001.0001.64GBDT1.0001.0002.33Adaboost1.0001.00013.28SVM_rbf1.0001.000327.64KNN_dis1.0001.00014421.78KNN_uni1.0001.00015762.92
由于在航天任务中,传输数据是在带噪声的环境下进行传输。第二部分实验是为了验证各该系统在不同误码率的情况下的稳定性。该部分实验数据采用的误码率分别是10-1,10-3,10-5和10-7。评价指标采用F1-score时,在不同误码率的情况下,基于集成学习的AOS协议识别系统的识别结果见表2。评价指标采用AUC时,在不同误码率的情况下,基于集成学习的AOS协议识别系统的识别结果见表3。

表2 不同误码率的结果(F1-score)Tab.2 Results of Different Bit Error Rates(F1-score)模型10-110-310-510-7RandomForest1.0001.0001.0001.000GBDT1.0001.0001.0001.000Adaboost0.9781.0001.0001.000
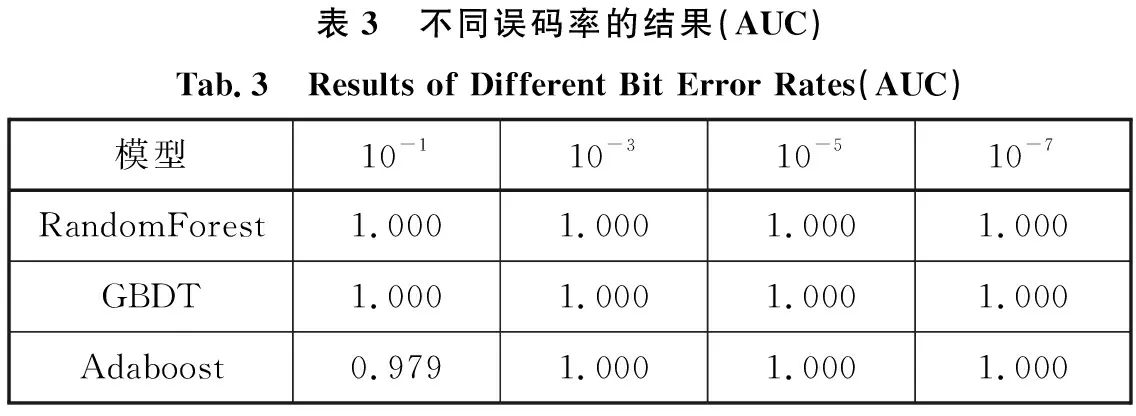
表3 不同误码率的结果(AUC)Tab.3 Results of Different Bit Error Rates(AUC)模型10-110-310-510-7RandomForest1.0001.0001.0001.000GBDT1.0001.0001.0001.000Adaboost0.9791.0001.0001.000
通过对三种集成学习算法的分析,对于基于Bagging思想的随机森林算法而言,由于新的训练子集是由其有放回的采样方式产生的,因此一些样本重复采样,而一些样本被忽略。这导致基分类器对被重复采样的样本空间样本有很高的分类精度,而对于被忽略的样本则有较大误差。但是,由于最终结果是由多个基分类器共同投票产生,所以当基分类器识别精度越高且基分类器之间的差异越大时,该算法的识别效果也就越好。因此,该方法对高误码数据依然能保持较好的识别效果且稳定。对于基于Boosting思想的Adaboost算法和GBDT算法来说,下一个基分类器的出现都是对上一个基分类器的修正,因此这样可以有效的降低模型的偏差。但是随着继续训练,识别精度在不断提高同时也导致了整体方差的变大。在训练过程中,就可以通过特征的随机采样来降低各个基分类模型的间的相关性,从而降低整体模型的方差[15]。当主分类器无法对误码样本进行准确分类时,将会把该数据传输到新的辅助分类器,并将其辅助分类器加入到模型当中,提高模型的识别准确率,保持识别稳定性[16]。通过表2及表3看以看出,在不同误码率的情况下,三种基于集成学习模型的识别系统依然保持较高识别准确率,且在高误码率10-1时依然保持了较好的识别效果,表明了该系统在高误码率情况下具有较好的稳定性。
7 结束语
本文通过对集成学习方法和空间链路层协议研究的基础上,设计一种基于集成学习的空间链路层AOS协议识别方法,搭建该AOS协议识别系统,该系统对空间链路层AOS协议在高误码率情况下进行有效的识别。通过实验对比了三种非集成学习模型,实验结果表明该系统在空间链路层协议识别方面具有较好且稳定的识别效果,识别效率也得到显著提升。此外,在高误码率10-1时两种评价指标下均能保持较好且稳定的识别效果。
