基于关联规则的数据挖掘算法分析
2020-09-10郝林倩
郝林倩
(福建船政交通职业学院 信息工程系,福建 福州 350007)
0 引言
随着数据时代来临,人们已不满足于海量数据存储、查询和显示,更关心海量数据背后的信息价值,目前人们对于数据信息掌握远远跟不上数据增长速度。如何在海量数据中挖掘有用的信息成为了当前关注的焦点,知识发现、数据挖掘等技术成为了学术界研究的热点。数据挖掘技术就是从海量的、包含噪声的、不完整的随机数据中挖掘出事先未知[1]的,但却存在潜在价值信息的过程。目前国内处于大数据大力发展时期,为数据挖掘提供了良好外部环境,但目前对于数据挖掘,特别关联规则算法研究论文及成果相对薄弱和单一,所以本文重点对关联规则Apriori和FP-tree经典算法进行分析研究,并对两者性能进行比照,提出性能优化建议,所以本文对于数据挖掘关联规则探讨研究具有重要的意义。
1 数据挖掘定义及应用
数据挖掘是集统计学、数据库、模式识别、高性能计算、专家系统等多种学科交叉的新学科。数据采集和数据存储技术的快速发展使得数据库中数据量飞速增加,数据挖掘为决策者及管理者的决策提供了参考。数据挖掘应用涉及到民用普通领域,例如商场超市交易数据分析、电子商务购物行为分析等,也涉及到天文图像分析、化学分子数据分析、医疗记录分析等[2]。数据挖掘处理流程包括问题定义、数据准备、挖掘算法执行、结果解析及评估等环节。
问题定义即数据挖掘人员与研究领域专家及最终用户协作确定数据挖掘要求及范围(如聚类、关联规则发现等),确定最优的挖掘算法,为后续环节定下基础及方向。
数据准备主要包括数据提取,数据预处理及数据转换。数据提取即按照挖掘任务需求,从海量数据中提取有用的目标数据(Target Data)[3]。
数据预处理对目标数据进行数据清洗,包括消除噪声,剔除重复数据,完善缺省数据或者数据类型转换(一般为离散型数据与连续型数据互转)。数据转换主要对目标数据进行降维处理,从数据初始特征中提取目标特征,减少不必要的输入参数,提升处理效率。
挖掘算法执行即根据挖掘问题定义的任务及目的选择适合的算法,包括聚类、分类、规则发现或者序号模式发现等,在选择合理的数据挖掘算法时必须依据数据的特征、用户和系统的任务要求。不同特点的数据适合不同的算法。而用户的要求可以分为易于理解型结果和精确预测型结果,所以选择的执行算法,根据实际情况来决定。
挖掘结果解析和评估即挖掘任务结果不一定符合挖掘任务预期,因此选择数据挖掘算法允许存在冗余模式。数据挖掘是一个不断迭代过程,通过结果解析和评估,往前一个环节推导,直接导致选择有用有价值目标数据及适合的数据挖掘算法,通过直观的挖掘结果,评估出有效的挖掘任务,从而得到有价值的挖掘算法。
数据挖掘关联规则算法,通过关联分析发现关联规则,即发现数据与数据之间隐藏的关联信息,包括数量关联、因果关联、时序关联等。把所有可能的联系或者模式全部抽取出来,然后再估算其重要性和正确性,通过支持度和可信度两个属性来定义所抽取的关联信息的重要性和准确性。
2 关联规则相关概念及定义
关联规则为数据挖掘领域重要研究分支,即研究数据间关系,如何提升数据挖掘效率,在海量数据信息中寻找到有用的数据信息。关联规则如下表示,X⟹Y,其中X⊆I,Y⊆I,且X∩Y≠φ。设I={I1,I2,I3,I4…Im}为所有数据项集合,其中Ik(1,2,3…,k)为项,而项的集合为项集。如果包括K数据项目集合,称之为K-项集。每一个事务为一个项集T(Transaction),不同的事务构成一个[4]事务集合D,即事务数据库。定义关联规则4个属性定义如下:
2.1 支持度(Support)

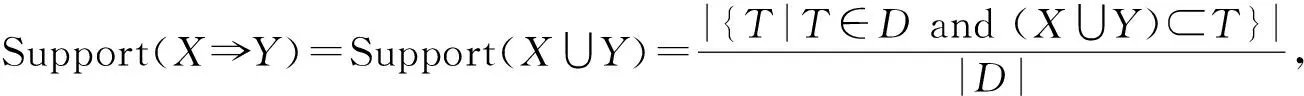
2.2 可信度(Confidence)
假设在事务集D中支持X项集的事务中,同时也k%的概率支持事务Y,则称之k为X⟹Y的可信度。按照公式表示如下:
2.3 期望可信度(Expected Confidence)
假设集合D中存在k%支持集合Y,则k%为支持X⟹Y的期望可信度,按照公式表示X⟹Y的期望可信度如下:
2.4 作用度(Lift)
所谓作用度为期望可信度与可信度之间的比值结果,即支持集合X对支持集合Y存在多大的影响概率,按照数学公式表示X⟹Y作用度如下:
在关联规则如上4个衡量标准中,可信度反应关联规则的准确性,而支持度反应关联规则的重要性。期望可信度反应其中在没有X项集影响下[5],Y项集的可信度情况。而作用度反应项集X对项集Y的影响度大小。如果作用度越大,说明项集X对于项集Y影响力越大,一般情况作用度大于1,说明项集X对于项集Y具有正面作用,从而说明项集X和项集Y相关性更强。
3 经典关联规则算法Apriori研究及优化
目前关联规则经典算法包括Apriori和FP-tree算法。Apriori算法为布尔关联规则所需频繁项集基本算法,该算法利用一个层次顺序搜索的循环方法来完成挖掘频繁项集的工作,即利用k-项集来产生(k+1)-项集。具体操作步骤如下:首先找到频繁1-项集,记为L1,然后利用L1挖掘L2,即2-频繁集,依此类推层层挖掘直到无法再找到更多的频繁集Lk,而其中每挖掘一层k都需要扫描一遍集合数据库。Apriori具有一个重要性质,即频繁集合任意子集都为频繁集合。所以Apriori算法处理过程描述如下:
第一步:在项集1-项集C1中,找出频繁项集1-项集L1。
第二步:在第一步基础上,利用Lk-1项集连接产生候选集合Ck。公式表示如下:
l1⊕l2={l1[1],l2[2],……,l1[k-1],l2[k-1]},由Lk-1中可连接的项集所连接的K-项集,即为Ck。
第三步:删除Ck中非频繁的子项集的候选集合[6]。
第四步:扫描整体数据库,并统计候选集合计数,从而得出最终的项集Ck。根据Apriori算法的伪代码实现通过层层挖掘找出频繁项集Lk,实现输入参数包括事务数据库D及最小支持度min-sup,代码输出结果频繁项集L[7]。
L1=find_frequent_1_itset(D);
for(k=2;Lk-1≠φ;k++){
Ck=apriori_gen(Lk-1,min _sup);
for eachT∈D{
CT=subset(Ck,T);
for eachc∈CTc.count++;
}
}
Lk={c∈Ck|c.count≥min _sup};
returnL=UkLk;
else returnFALSE
for eachl1∈Lk-1
for eachl2∈Lk-1
f(l1[1]=l2[1])&&(l1[2]=l2[2]&&…&&(l1[k-2]=l2[k-2])&&l1[k-1]=l2[k-1])
{
c=l1⊕l2
fhas_infrequent_itemset(c,Lk-1)
deletec;
elseCk=Ck∪{c};
}
returenCk;
procedure has_infrequent_subset(c,Lk-1);
for each(k-1)subsetsofc
fs∉Lk-1return TRUE
else return FALSE
利用如上伪代码获取频繁项集所有的相关关联规则的子集合Ck。此算法利用数据特质任何频繁项集的子集都是频繁集合,反向定理若集合存在非频繁集项,则包含此数据项的超集合都不是频繁集合,从而优化Apriori算法的查找效率,在进行层层挖掘任务中剔除非频繁集合项,根据如上伪代码完成Apriori算法优化[8]。
4 总结
本文着重分析了数据挖掘技术及其关联规则模式下的Apriori算法,并研究了基于算法的频繁集合特质,在进行层层挖掘过程中剔除非频繁集合项目,从而提升了Apriori算法挖掘效率,继而再提升挖掘功效。
