基于分段熵分布的VPN加密流量检测与识别方法
2020-09-10唐舒烨程光蒋泊淼陈子涵郭树一
唐舒烨,程光,4,蒋泊淼,陈子涵,郭树一
〔1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京 211189;3.网络通信与安全紫金山实验室,江苏南京 211111;4.教育部计算机网络和信息集成重点实验室(东南大学),江苏南京 211189〕
1 引言
虚拟专用网(Virtual Private Network,VPN)技术作为加密网络流量的主要使用技术之一,依靠加密隧道等手段,向用户提供便利、隐秘的远程访问等操作。然而,被VPN工具掩盖下的流量,失去了原有流量的报文头部信息、流量侧信道特征信息,也给网络监管带来了新的挑战。
因此,针对VPN加密流量测量分析已经刻不容缓。本文对使用V2Ray工具的VPN加密流量信息熵分布特性进行研究,提出了一种基于分段熵分布的VPN加密流量检测与识别方法,实现VPN加密流量的检测与识别,加强对VPN流量的有效监管。
2 相关工作
目前,主流的加密流量检测识别技术一般是根据加密流量数据均匀随机分布[1]的特点进行研究。而现有专门针对VPN流量的研究,则大多基于Gerard Draper-Gil提供的ISCX VPN-nonVPN公开数据集[2]展开。
借助于该公开数据集,Bagui Sikha[3]和王琳[4]使用了6种传统机器学习分类模型进行检测。同时,一些深度学习[5]方法也被运用于VPN流量检测识别研究,如基于注意力机制的长短期记忆网络[6](Attention-based Long Short-Term Memory)、胶囊神经网络模型[7](Capsule Neural Networks)、立体变换神经网络[8](Stereo Transform Neural Network)等。然而,现有的VPN加密流量识别方法拘泥于机器学习方法的改进和应用,并未针对流量本身特性进行研究。
3 分段熵分布检测与识别方法
3.1 VPN流高熵低熵区域划分方法
目前,主流使用的VPN工具是V2Ray工具,V2Ray工具使用私有协议VMess实现数据的随机化加密传输,VMess协议是一种基于TCP协议的无状态协议,协议本身没有握手过程。然而,普通的加密流量在传播过程中包含协议握手和数据传输两个过程,其中协议握手过程通常存在随机性较低的明文字段,包含未加密的双方通信协商的参数及公钥信息;加密数据传输过程中的报文内容主要是加密后的数据以及头部少量的会话标识、加密数据长度等信息,也存在有少量不可或缺的明文头部。
鉴于此,VPN加密流量的检测识别可以根据VMess协议下VPN加密流量呈现高度均匀随机分布,且不含明文头部的特点,围绕VPN流量的信息熵分布特性展开研究。
信息熵(Entropy)是反映能量分布均匀程度的测度。给定一个概率分布:

其包含元素的集合为:

则该分布 的熵可以表示为:

然而在实际需求中,需要在欠采样条件下利用熵的估计值实现对目标数据的随机性的准确判断以提高识别效率。因此本文引入N-截断熵的概念,N-截断熵被定义为根据概率分布P产生的所有长度为P的样本序列的熵的平均值,当P为均匀分布U时,可以得到长度为N的随机序列的N-截断熵为:
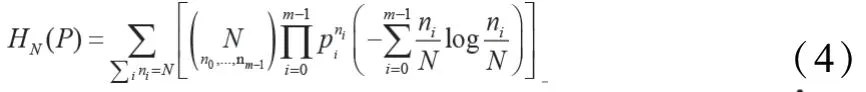
VPN加密流量加密化程度整体较高,因此可以针对VPN流量报文中的高熵低熵区域进行划分,以大小为N的滑动窗口的形式以固定步长τ在流序列中遍历每一窗口内序列的熵值,当滑动窗口遍历完流序列时,对每个序列分段计算其有效载荷。接着,本文依据N-截断熵理论对高熵区域的判别原则,对每个序列分段的有效载荷进行判定。根据蒙特卡洛算法,通过对多组长度为N的随机字段求其发现,的取值符合正态分布,绝大部分的值在的区间范围内,为标准偏差,以此进行高熵区域的判别,从而将序列分段标记为高熵或低熵区域,接着研究其分布情况,以此作为单条流量报文的流量特征。本文的流量特征是报文数据熵值特征而不是具体的报文数据,不存在特定报文序列检测,同时也不受数据包时空特性影响,具有方法上的普适性。
3.2 VPN加密流量检测识别方法
在对VPN加密流量的高熵低熵区域分布情况进行研究之后,采用胶囊神经网络模型(CapsNet)进行VPN加密流量检测识别。常见的神经网络大多使用数据包空间特征或是时间序列特征进行加密流量检测,而忽视了报文数据内部的相对位置,如前文提及的高熵低熵区域分布的位置特征等。胶囊神经网络正可以弥补这一缺陷,它使用向量代替标量作为神经单元,向量可以有效利用流量特征之间的逻辑关系,学习流量特征的属性,尤其是VPN加密流量分段熵之间的位置与顺序关系等。且与卷积神经网络相比,胶囊神经网络可以有效减少学习所需的训练数据量。因此,胶囊神经网络更适合于VPN加密流量检测与识别。
基于胶囊神经网络的VPN加密流量检测识别方法首先对前文的结构化流量数据特征进行提取,并统一转换成可供胶囊神经网络模型使用的特征矩阵文件,然后对特征矩阵执行多次卷积运算和加权运算,生成多个子向量,其中向量长度表示VPN加密流量存在的概率,向量方向表示各实例化的参数,此时每个子向量即是一个子胶囊神经单元,同时每个子向量选择一个上层节点作为父胶囊神经单元。
3.腹痛的视觉模拟评分法(VAS):使用视觉模拟评分量表判定腹痛程度,0分为无痛,1~3分为轻度疼痛,4~6分为中度和重度疼痛(阵发性疼痛4分,持续性疼痛5分,持续性加重的疼痛6分),逐渐剧烈的疼痛且无法忍受7~10分。
接着该方法通过动态路由协议,将子胶囊神经单元的预测结果在向量网络结构中向上表征并传递给父胶囊神经单元,最终随着路由机制的不断迭代,将所有子向量封装成一个高维向量,由归一化的Softmax回归模型分类器对高维向量进行VPN加密流量识别分类,并输出识别分类结果。该方法可以通过增加卷积层数与调整动态路由协议迭代次数的方式进行胶囊神经网络模型调优,有效提高流量识别分类准确率。
实验所使用的胶囊神经网络结构如图1所示,分为输入层、预处理层、第一胶囊层(Primary Capsules)与第二胶囊层(Digit Capsules)。其中,输入层为K维特征向量,预处理层使用卷积核大小为1的1-d卷积层对输入层输入的K维向量进行处理,得到有个通道的张量,并将得到的输出张量作为第一胶囊层的输入。第一胶囊层使用个卷积大小为1的1-d卷积层将输入张量从个通道压缩到个通道,得到组通道数为的张量并将其进行合并,最终得到个长度为的胶囊,并使用非线性压缩函数squash对这些胶囊进行处理。完成后使用动态路由算法(迭代轮数为L)将第一胶囊层得到的个胶囊映射到第二胶囊层中,第二胶囊层一共包括C个长度为的胶囊,其中C为最终分类的类别数量,最终输出每一个类别的分类结果。

4 实验与分析
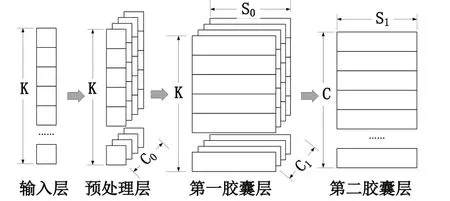
图1 胶囊神经网络结构
实验所用机器CPU为i7-6700HQ,GPU为GTX1060,软件环境Python版本为py3.7,Pytorch版本为15.1。
4.1 高熵与低熵区域划分实验
为研究VPN报文与普通加密报文的高熵与低熵区域划分差异,以大小为32B的滑动窗口的形式以固定步长32B在每一条流量数据中遍历每一窗口内序列的熵值,即N=τ=32,此时。使用蒙特卡洛算法对标准偏差 进行计算,模拟长度为32B的随机序列求其对应的并进行统计。由于N-截断熵是用于对较短字节序列的随机性进行衡量,所以本文使用随机生成的字节序列而非真实加密报文进行计算,完成随机性指标的计算后,再对加密报文有效载荷字段的随机性强弱进行分析,一共进行106次模拟实验,求得,则当序列分段熵值在区间内时被定义为高熵分段,当序列分段熵值不在这个区间内时则被定义为低熵分段。
4.2 VPN流量检测与识别实验
报文熵值特征提取主要是为了对报文中的有效载荷的高熵低熵字段分布特征进行提取。为保证数长度的一致性方便输入到网络中进行处理,首先使用相同的字节0将报文有效载荷填充至1472B。接着,为便于计算,同样按照32B进行划分,每一段求出一个作为这一段的熵值特征。最终得到46组分段的熵值特征,对于每一段有效载荷还计算一个总熵值特征。最终一共得到47组熵值作为特征。

表1 实验使用的51组特征汇总
Br51报文的其他特征包括报文方向、报文长度、TCP Flag中PUSH报与ACK的取值,共计51组特征。本文使用图1所示的网络结构对VPN流量进行识别,输入为表1中提到的51维特征向量。由于VPN流量识别是一个二分类问题,第二胶囊层仅包含两个胶囊,同时多次实验表明,胶囊 长度为16时,分类准确率最高。第一胶囊层与第二胶囊层之间所使用的动态路由算法迭代轮数设置为3轮,在保证算法分类精度的同时减少过拟合的可能性。本文所用到的与胶囊神经网络训练相关的参数如表2所示。
4.3 实验结果
本文在实验室环境下实际采集得到的VPN加密流量数据集与ISCX VPN-nonVPN公开数据集分别进行了实验。其中,实际流量采集使用Wireshark抓取使用V2Ray vmess协议的VPN流量,包含视频播放、网页浏览、文件传输流量等用户行为。
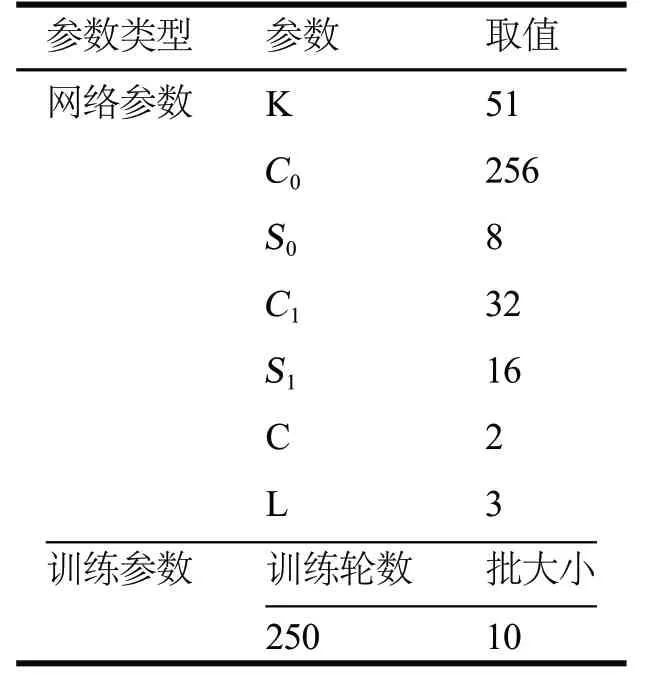
表2 胶囊神经网络参数设置
VPN流量和普通加密流量有效载荷的高熵低熵区域划分使用实际采集的流量进行实验,实验结果如图2所示。由于存在明文头部字段,普通加密流量的有效载荷第一段中的熵值较低,为低熵区域,而之后字段为高熵区域,而VPN流量的有效载荷均为高熵区域,特征较为明显。
使用胶囊神经网络进行VPN流量识别的实验结果如表3所示。

图2 有效载荷熵值分布图
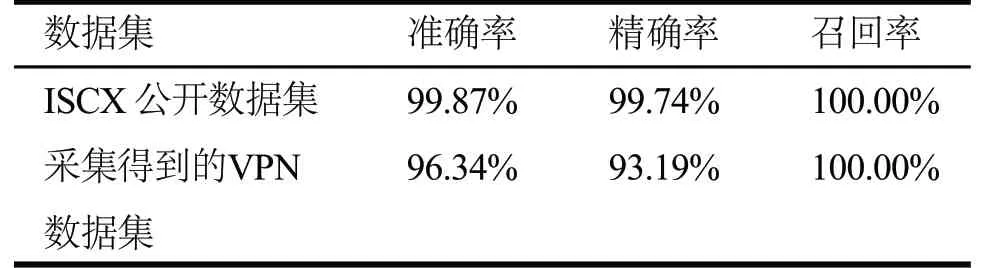
表3 不同数据集上的测试结果
本文还在采集得到的VPN加密流量数据集上使用四种分类模型:随机森林、C4.5决策树、支持向量机、卷积神经网络,进行对比试验。其中支持向量机的惩罚系数C=10,并使用sigmoid核函数;决策树每次选择最优的切分特征和切分点进行切分,最大深度设为8防止出现过拟合的情况;随机森林由64棵前述的决策树构成;卷积神经网络将报文使用随机字段填充或截断生成大小为28×28的灰度图,并使用LeNet5网络进行分类。对比实验结果如表4所示。
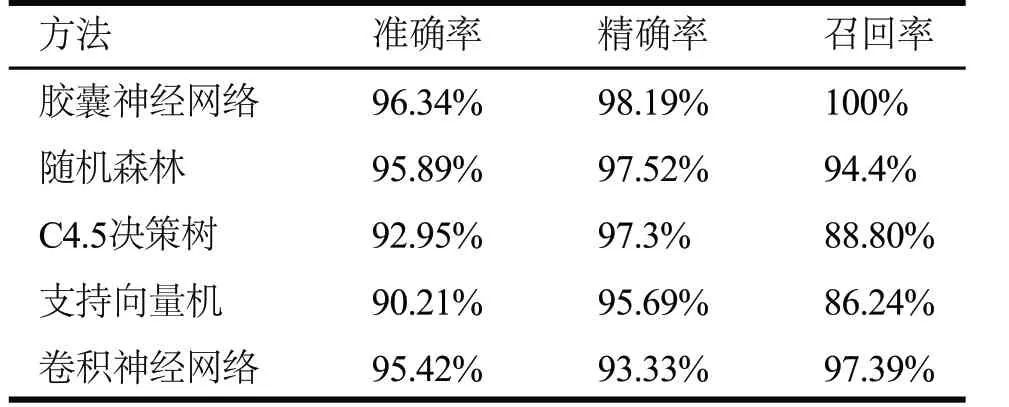
表4 不同机器学习方法的测试结果
实验结果表明,本文提出的基于分段熵分布的VPN加密流量检测与识别方法,在ISCX公开数据集与实际采集得到的VPN数据集上分别达到了99.87%和96.34%的识别准确率,具有极高的识别准确率,同时该结果也优于随机森林、C4.5决策树、支持向量机、卷积神经网络四种分类方法,可以用于VPN加密流量检测识别。
5 结束语
本文内容打破了传统VPN加密流量检测方法的局限性,提出了一种基于分段熵分布的VPN加密流量检测与识别方法,利用滑动窗口方法对VPN加密报文序列高熵、低熵区域进行划分,并使用胶囊神经网络模型实现VPN加密流量的精准检测与识别。对比实验表明,该方法具有更高的识别准确率。
