基于离散载荷特征的即时通讯软件流量分类方法
2020-09-10崔弘蒋言郭士串汪洋
崔弘,蒋言,郭士串,汪洋
(烽火通信科技股份有限公司,江苏南京 210019)
1 引言
随着大数据时代的到来,在计算机网络方向的工程应用中,很多时候都需要对流量所属应用类型进行识别,软件流量识别分类是网络管理、网络安全和流量工程等网络研究和应用的重要组成部分,也是解决网络拥塞、安全监管、网络异常检测等研究的基础。
在互联网流量识别的历史中,经历了3个阶段:第一个阶段是通过端口来识别,但是后来由于动态端口和伪装端口等技术的出现导致这个方法不再适用;第二个阶段是采用深度包检测技术,基于应用层的流量检测和控制技术,当IP数据包、TCP或UDP数据流通过时,DPI系统通过深入读取IP包载荷的内容来对协议中的应用层信息进行分析读取,进而识别各类型应用[1,2];第三个阶段是通过机器学习的方法识别流量,通过统计一系列流量数据的外在特性来形成特征,例如流的持续时间和分组的数目等外在特征,然后采用机器学习的方法训练模型进行流量识别[3]。本文采用第二类和第三类相结合的方式,考虑到数据外在特征的抽取具有一定的迷惑性,同时在进行纯净数据提取时会损失大量的外在特性,所以本文首先对即时通讯软件流数据提取报文载荷,利用信息熵对获得特征进行离散化处理,结合离散载荷特征与XGBoost的方法进行流量数据量化与分类训练,该方法具有数据处理效率高、适应性强、流量分类精度高等优点。
2 流量载荷特征提取
本文所使用的数据来源于多个手机端即时通讯软件聊天流量数据,其中包括图片、语音、文字等不同形式数据。分别对每种类别通讯软件利用Wireshark抓取对应软件的聊天流量数据报文,由于在Wireshark抓取过程中无法避免噪音流量的数据的干扰,需要对抓取的每类报文数据进行提纯。
2.1 数据报文的提纯
为了能充分利用报文中所有信息,又能准确提取有价值数据降低数据维度,此次提纯的方式采用五元组(源IP地址、源端口、目的IP地址、目的端口、传输层协议)识别的方式进行,首先采用五元组对各流量数据进行聚类,然后对于聚类后的数据,剔除数据链路层、网络层、传输层数据维度,提取传输层有效净载荷构建识别模型[4~6]。通过这种方式获取到的报文基本只属于对应的通讯软件,由此获得纯净的输入数据。报文的示意图如图1所示。

图1 报文示意图
对每条报文去除五元组头部信息,只保留数据部分,为了防止心跳报文等空报文的影响,同时避免数据字段后续部分无用信息的影响,只保留每条报文前50个字节长度的数据,同时舍去小于9个字节的报文数据,对于大于9个字节不足50个字节的数据设置缺失值为0。同时以每条报文中每个字节为一个特征维度,将每个十六进制数转换为十进制数,对于每一条报文数据,这样可以得到一个特征维度为50的输入向量,每个特征均为正整数数值类型。为避免类别数量不均衡带来不良影响,设置获取的每种类别报文均为10,000条。数据准备过程示意图如图2所示。

图2 数据准备过程示意图
对所有的原始报文流数据,依据五元组特征对五元组进行聚类,通过报文提纯的方式对各五元组提取其中的有效载荷,具体聚类流程如图3所示。
2.2 载荷特征离散化

图3 五元组聚类示意图
谢宏和程浩忠等[7~9]人提出当训练数据的数量通常不足以使用连续特征来获得准确的模型时,使用离散特征而不是连续特征的算法的分类误差较低。由于网络流量中的IP地址、协议和端口等属性在分布特征上表现出较强的自相似性和重尾特性,各个属性在分布特征上存在明显的差异[10]。因此将信息熵应用于载荷特征离散化,用熵值量化网络流量载荷的不同属性。特征离散化就是在特定属性的取值范围内设定若干个划分点(即断点),将该属性的值域范围划分成一些子区间(离散化区间),每个子区间用一个符号或整数值代替[11]。本文采用信息熵方法对提取的五元组连续载荷特征进行离散化,分别计算每条报文流在这些有效载荷上的熵值。
(1)信息熵离散化原理
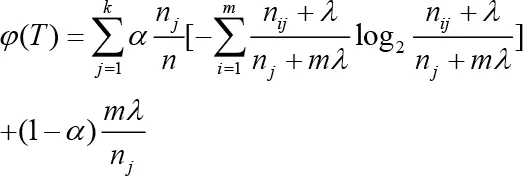
上式中、为可调参数,可用于控制属性X的离散区间数k。本文取,则准则函数简化为:。
猪伪狂犬病毒,除感染猪外,还可以感染多种家畜和野生动物,是一种急性传染性疾病。猪伪狂犬病发病没有季节性限制,春夏秋冬四季均可发生,但以冬春季节气温寒冷、外界应激因素多变造成的发病率和死亡率最高。患病猪和带毒猪可以通过体内分泌物、流产物、尿液、乳汁排毒,健康猪接触这些污染物质后,感染该种病毒的几率极大增加。近年,随着猪养殖产业不断向集约化和规模化方向发展,猪伪狂犬病已经成为严重损害猪养殖产业健康发展的主要病毒性疾病。因此,做好该种疾病的防控,具有重大现实意义。
(2)信息熵方法离散化算法
基于Shannon熵的准则函数,通讯流量的特征离散化算法步骤为:
步骤一:对报文载荷区间进行初始化。依次扫描各个报文,使单个取值的样本成为一个区间,记录每个区间的相关信息;
步骤二:对于单个报文,扫描所有载荷区间,按区间内样本值的大小对区间进行递增排序;
步骤三:对排序后的区间进行扫描,如果两个相邻区间内样本的分类情况对应相同,将这两个区间合并。每合并一次,区间数减1,合并结束后得到k个区间;
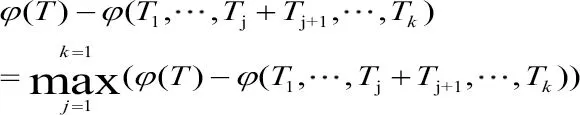
由于该算法只针对单个载荷特征,而实际报文中往往有多个载荷特征,因此需要按照以上步骤,对多个载荷特征分别使用该算法进行离散化计算熵值。
3 通讯流量分类模型构建
APP识别模型,本质上是一个多分类的问题。对于多分类问题,通常有两种实现模式,一是直接进行多种类别编码,二是划分为多个二分类问题。前者一次训练,耗时小、预测快,但不易于增量扩展;后者需要构建多个识别模型,训练耗时、预测总时间也长,但易于增量扩展。本项目采用第二种方法,即针对N个APP中的每个APP,分别训练N个二分类模型;测试时,对于任意一条(或一批)报文,同时丢入N个二分类模型,最后取N个模型得分最高者作为输出。多二分类器的流量识别模型如图4所示。

图4 多二分类器的流量识别模型
对通讯软件各批报文数据分别提取五元组中有效载荷的基础上,通过Shannon熵方法对各个有效载荷划分为离散化区间,并对离散区间计算有效载荷熵值。采用构建好的APP分类器分别对每个五元组的每个报文的五元组载荷特征熵值进行识别,再对每个五元组的识别结果,依据得分高低进行竞选投票,最后输出该五元组的流量归属类别,模型构建流程示意图如图5所示。

图5 模型构建示意图
4 实证分析
4.1 数据来源
本实验针对目前市面上常见的10种手机即时通讯软件(QQ、微信、Whatsapp、陌陌、COCO、易信、YY、阿里旺旺、微会、米聊),分别利用Wireshark抓取对应软件的聊天流量数据报文。由于在抓取过程中无法避免噪音流量的数据的干扰,对每类报文数据进行提纯,通过报文提纯的方式对各五元组提取其中的有效载荷,获得每种类别的五元组连续数据10,000条。为了描述载荷分布特征差异,提高分类准确率,对五元组加载荷连续特征离散化后,每种类别五元组报文数据均为10,000条,数据总量为100,000条。
对于每种通讯软件,设置训练数据:测试数据=0.7:0.3,因为训练模型为二分类模型,故针对每种训练模型,设置对应训练类别为正例,其余9种数据混合为反例,反例中保持9种数据数量相等,且正例数据量与反例数据量相等。针对每个分类模型的训练数据量和测试数据量为7,000条和3,000条,其中训练数据中3,500条为正例,3,500条为反例,测试数据中1,500条为正例,1,500条为反例。
4.2 实验环境
实验采用机器学习模型广泛使用的框架Scikit-learn,具体软硬件环境如表1所示。

表1 实验软硬件环境
4.3 XGBoost参数设置
XGBoost采用树模型,Silent采用默认值打印运行时输出信息,有助于模型的调参,Nthread为XGBoost运行时的线程数,基于实验室设备,在保证运行速度情况下设置为4;学习率eta是在更新过程中用到的收缩步长,决定着学习速度的快慢,一般设置为0.01到0.2之间,本次实验设置为0.02。Gamma默认值为0,max_depth表示树的最大深度,其设置得当可以防止过拟合,本次实验设置值为8。由于本次实验选取的数据类别平衡性良好,故max_delta_step、scale_pos_weight等参数使用默认值即可,对于学习任务和学习目标中的目标函数选定为multi:softprob,输出为类别数*训练数据量大小的矩阵,每行数据表示每个样本属于各个类别的概率。选取最大的概率对应的类别作为分类器对输入数据预测的类别。经过调整最终设置循环迭代次数为30次。
4.4 实验结果
分别采用离散载荷特征与连续载荷特征构建XGBoost分类模型,以测试模型的准确率与召回率作为比较依据。测试性能结果如表2所示,由于离散载荷考虑了流量数据的分布特征,量化了流量载荷的不同属性,所以采用离散化流量分类器比连续流量特征分类更有效。
4.5 与其他分类方法对比
分别与随机森林、SVM以及朴素贝叶斯进行对比。在相同数据的情况下其他分类算法的测试性能结果如图6所示,可以看出XGBoost在识别手机即时通讯应用具有较高的准确率和召回率,同时其比随机森林、SVM和朴素贝叶斯算法在大部分应用流量识别情景中的应用性能要高。

表2 XGBoost测试性能结果

图6 RF、SVM、MNB测试性能结果
5 结束语
本文提出一种基于离散载荷特征的即时通讯软件流量分类技术,一是基于信息熵对流量特征进行离散化,了解流量特征分布情况以便进行流量分类,二是采用了具有自学习、自适应功能的XGBoost算法提高了流量识别的准确率和识别速率。实验结果表明,本方法对即时通讯软件流量分类的准确率高达92.6%,较传统流量分类方法准确率提高4.3%,与采用连续特征分类相比分类准确率提高2.3%。综上所述基于离散载荷特征的即时通讯软件流量分类技术这项研究对市场手机通讯软件的使用分布,以及通讯软件的逆向追踪都有着极其重要的现实意义。
