针对高光谱端元提取的空谱联合预处理方法
2020-09-09吴银花王鹏冲吴慎将张发强
吴银花,王鹏冲,吴慎将,张发强
(1.西安工业大学 光电工程学院,陕西 西安 710021;2.中国科学院 光谱成像技术重点实验室,陕西 西安 710029)
1 引 言
高光谱遥感实现了遥感图像光谱分辨率的突破性提高,它利用很多较窄的波段成像,将观测到的各种地物与电磁波相互作用后的辐射信号以完整的光谱曲线记录下来,使得本来在常规全色、多光谱遥感中不能识别的地物,在高光谱遥感中能够得到有效的识别[1-9]。因此,高光谱遥感在军事、医疗、农业、海洋、考古等多个领域得到了广泛的应用,主要用于实现目标分类、目标识别、目标探测等。然而,成像光谱仪往往具有较大的瞬时视场角,使得获取的高光谱图像空间分辨率较低,导致存在大量的混合像元,即一个像元所对应的地面区域内往往包含两种或更多种类的特征地物。这严重阻碍了高光谱遥感应用精度的提高。而大部分高光谱目标分类、识别、探测算法的前提是假设每个像元所对应的地面区域内只包含一种特征地物。即每个像元是纯像元,又称为端元。因此,为了提高高光谱遥感应用的精度,就必须进行高光谱解混合,使高光谱遥感应用由像元级达到亚像元级[10-12]。
高光谱解混合通常分为两个步骤:端元提取和丰度反演。即先从整个高光谱图像中提取含某一种地物的比例较高的像元作为端元,再针对每个像元求解对应各端元的丰度系数。其中如何从高光谱数据中准确提取端元是高光谱解混合的关键,也一直是国内外学者的热点研究问题。目前已经有不少成熟的端元提取方法被提出和引用,其中利用高光谱数据凸面几何特性的方法由于符合光谱混合过程的物理原理,且形式简单、技术成熟,目前得到了非常广泛的应用,比较经典的算法有顶点成分分析(VCA)[13]、顺序最大角凸锥(SMACC)[14]等。然而,这些方法主要是从光谱特征角度出发,进行端元提取,而忽视了像元在空间上的相关性,易受噪声和异常点的干扰,端元提取精度不高,且每个端元的提取过程都需遍历图像中的所有像元,导致运行时间较长。后来也有一些结合光谱特性和空间特性的端元提取方法[15-16]被提出,然而这些算法大多未充分利用真实地物空间分布特性,要么仍然易受噪声和异常点的干扰,要么还需要为不同图像人为设定不同阈值来辅助完成端元提取,导致算法的鲁棒性较低。
为了提高高光谱端元提取效率,提出了一种空谱联合预处理方法。该预处理方法先采用文中定义的光谱纯度指数SPI,从光谱特征和空间特征两方面综合预估高光谱图像中每个像元成为纯像元的可能性;之后基于SPI值在高光谱图像中的分布,利用空间相关性,有效去除光谱纯度较低的冗余像元,从而形成精简的候选端元集。该候选端元集与常用端元提取算法结合,不仅可提高抗干扰性和端元提取精度,同时可大幅降低时间复杂度。
2 算法介绍
2.1 光谱纯度指数SPI
由于真实地物在图像空间分布的连续性,相邻像元间总存在一定的相关性,尤其是空间分辨率较高的高光谱图像。从像元的角度来说,某一地物对应的纯像元周围一般是同一地物对应的纯像元或者是含有该种地物成分的混合像元,而不同地物对应的纯像元一般不会是相邻像元。即纯像元分布在同质区域中,而同质区域显然是局部区域,局部区域内可认为同一地物的光谱特征一致。因此同质区域中相邻像元之间光谱特征往往比较相似,越靠近纯像元,越相似。
在给定的局部区域内,某一像元与其相邻像元的光谱特征越相似,说明该局部区域的同质性越高,从而该像元成为纯像元的可能性越高。而光谱特征主要体现在其光谱形状和幅值:(1)同一地物对应的两个纯像元,二者光谱形状和幅值均很相近,光谱特征相似度很高;(2) 不同地物对应的两个纯像元,二者的光谱形状和幅值均差异较大,光谱特征相似度很低;(3) 不同地物边界中的两个混合像元,由于两个像元中含有各种地物的比例不同,二者的光谱形状和幅值一般很难都相近,光谱特征相似度较低。
光谱角度填图法(SAM)是通过计算两个像元光谱之间的夹角θ来衡量二者的光谱特征相似度,如式(1)所示。θ值越小,说明二者越相似。θ值与光谱向量的模无关,因此SAM法主要测量光谱形状的差异。欧式距离法(ED)是通过计算两个像元之间的欧式距离d来衡量二者的光谱特征相似度,如式(2)所示。d值越小,说明二者越相似。与SAM法不同,ED法主要测量的是各波段幅值差异的累积。
(1)
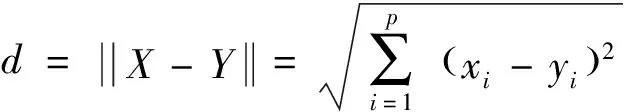
(2)
式中:X和Y分别表示两个像元的光谱向量,xi和yi分别表示X和Y的第i个波段幅值,p表示波段数,θ的取值范围是[0,π/2]。
综合考虑光谱形状和幅值,这里定义了一种新的参数s来测量像元间光谱特征相似度,进而给出了光谱纯度指数SPI的概念及其计算方法,用于表示每个空间像元称为纯像元的可能性。具体方法如下:
(1)新的参数s计算方法如式(3)所示。其中,θ′和d′分别是利用式(1)、(2)求出的θ和d经归一化后的值,以避免角度θ和距离d的数值差异影响。由于参数s既考虑了光谱形状差异,又考虑了光谱幅值差异,且将这两种差异视为同样重要,从而更能准确衡量光谱特征相似度。与θ和d类似,s值越小,说明两个像元光谱形状和幅值的综合差异越小,光谱特征越相似。
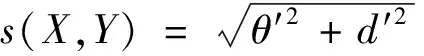
(3)
(2)在新的参数s基础上,定义了光谱纯度指数SPI的概念:当前像元Xi,j(i和j分别表示该像元在图像空间中的横坐标和纵坐标)与其为中心的N×N大小窗口T内相邻像元之间参数s的最大值定义为当前像元的光谱纯度指数SPIi,j,计算方法如式(4)所示。其中,i和k表示图像中像元的横坐标,j和l表示图像中像元的纵坐标,k的取值范围是[i-N/2+1,i+N/2-1],l的取值范围是[j-N/2+1,j+N/2-1]。
SPIi,j=max{s(Xi,j,Xk,l)}
.
(4)
可以看出,SPI值越大,说明对应像元的局部区域窗口同质性越低,也就是光谱纯度越低,从而成为端元光谱的可能性也越低;反之,SPI值越小,说明对应像元的局部区域窗口同质性越高,也就是光谱纯度越高,从而成为端元光谱的可能性也越高。
2.2 基于SPI的空间去冗余方法
进行光谱解混合时,对于每种地物,只需要此种地物中一个纯度最高的像元作为端元即可。如前所述,由于真实地物在图像空间分布的连续性,纯像元往往分布在图像的同质区域中,且越靠近纯像元,相邻像元间光谱特征越相似,像元的光谱纯度指数SPI值越小。即每个局部区域中,光谱纯度指数SPI最小值对应的像元成为纯像元的可能性最高,而其他像元由于光谱纯度指数SPI值较大,成为纯像元的可能性较低,可以认为是冗余像元。显然,这些冗余像元在端元提取过程中,不仅会提高时间复杂度,还会增加端元提取的错误率。因此,需要一种有效的去冗余方法,在保持光谱多样性不变的基础上,准确判断冗余像元,并将其去除,使得仅将成为纯像元可能性较高的像元参与端元提取,从而节省运算时间,也降低端元提取的错误率。
通过利用真实地物在图像空间分布的连续性,这里给出了一种基于SPI的空间去冗余方法。根据SPI值的空间分布,寻找每个局部区域中SPI最小值对应的像元,以此来判断每个像元是否为冗余像元,并将冗余像元去除,形成最终参与端元提取的候选端元集。具体方法如下:
(1)利用式(3)和(4),计算高光谱图像中所有像元的SPI值,并生成与图像同等大小的二维SPI矩阵,如式(5)所示,其中m和n分别表示图像中像元行数和列数。

(5)
(2)针对每个像元,以该像元为中心的Q×Q大小窗口L范围内,寻找SPI最小值。这一步可采用Q×Q大小窗口的最小值滤波器,对(1)中获得的二维SPI矩阵进行滤波的方式实现,既简单又快捷。
(3)如果某一像元的SPI值与其为中心的窗口L内SPI最小值相等,则认为该像元在窗口L内成为纯像元的可能性最高,判定为非冗余像元;反之,判定为冗余像元。由所有非冗余像元组成候选端元集。
由于候选端元集是由每个局部区域中SPI值最小的像元,也就是成为纯像元可能性最高的像元组成,从而有助于避免噪声和异常点的干扰,以提高端元提取精度。同时由于参与端元提取运算的像元数量有效减少,可大幅缩短运算时间。
2.3 基于本文预处理方法的高光谱端元提取
根据2.1~2.2节的描述,结合提出的空谱联合预处理方法,高光谱端元提取整体框架如图1所示,具体步骤如下:
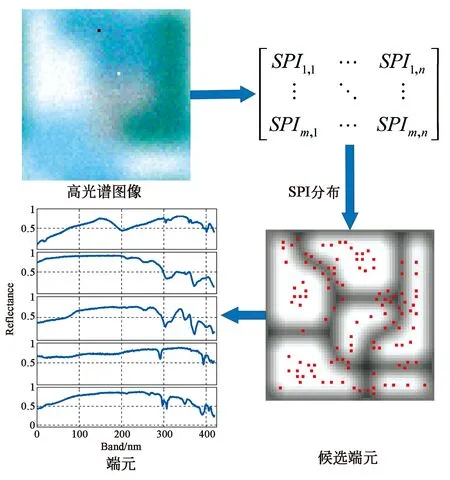
图1 基于预处理方法的高光谱端元提取框架Fig.1 Framework of the hyperspectral endmember extraction with the proposed preprocessing method
步骤1:根据2.1节中的方法,利用式(1)~(4),以5×5窗口大小,计算高光谱图像中每个像元的SPI值。
步骤2:基于步骤1中计算得到的SPI值空间分布,利用2.2节中的方法,以3×3窗口大小,进行空间去除冗余,并生成候选端元集。
步骤3:采用常用端元提取方法,在步骤2中获得的候选端元集范围内进行端元提取处理。
3 实验数据
为了验证该算法的可行性和有效性,本文将分别利用模拟高光谱图像和真实高光谱图像进行相关实验。
3.1 模拟高光谱图像
模拟高光谱图像是由USGS光谱数据库中任意选取的5条光谱曲线作为端元光谱,以一定比例线性混合生成的高光谱数据立方体,空间大小为60像元×60像元。作为端元选取的每条光谱曲线波长范围为0.395 1~2.56 μm,包含420个波段,光谱分辨率为5 nm。为了模拟真实地物在图像空间的分布特征,本文按以下步骤生成了模拟高光谱图像:
(1)将60像元×60像元大小的空间区域分割为25块12像元×12像元大小的子块,每个子块随机设定为某一种端元,此时对于每个像元,只有设定端元对应的丰度系数为1,其余端元对应的丰度系数为0。
(2)采用窗口大小为15×15、均值为0的高斯低通滤波器,对每一种端元对应的丰度系数图进行滤波,从而模拟混合像元。
(3)进行归一化,使得每个像元对应丰度系数之和为1。
(4)从USGS光谱数据库中另选取2条光谱曲线,同样波长范围为0.395 1~2.56 μm,包含420个波段,光谱分辨率为5 nm。
(5)在60像元×60像元大小的空间区域中,随机选择两个像元位置,并分别用步骤(4) 中选取的2条光谱曲线替换这两个像元位置所对应的原始混合光谱,从而模拟2个异常点。
(6)在步骤(5) 得到的模拟数据中,添加信噪比SNR为30 dB的零均值高斯噪声,以模拟实际数据采集时生成的各种噪声和干扰。
图2是按照上述步骤生成的模拟高光谱图像第30波段对应的二维灰度图,其中蓝圈里的红点表示添加的两个异常点,空间位置坐标分别是(8,28)和(23,35)。图3是模拟高光谱数据中端元和异常点对应的光谱曲线,其中5条实线对应端元光谱,2条虚线对应异常点光谱。

图2 模拟高光谱图像(第30波段)Fig.2 Simulated hyperspectral image (Band 30)
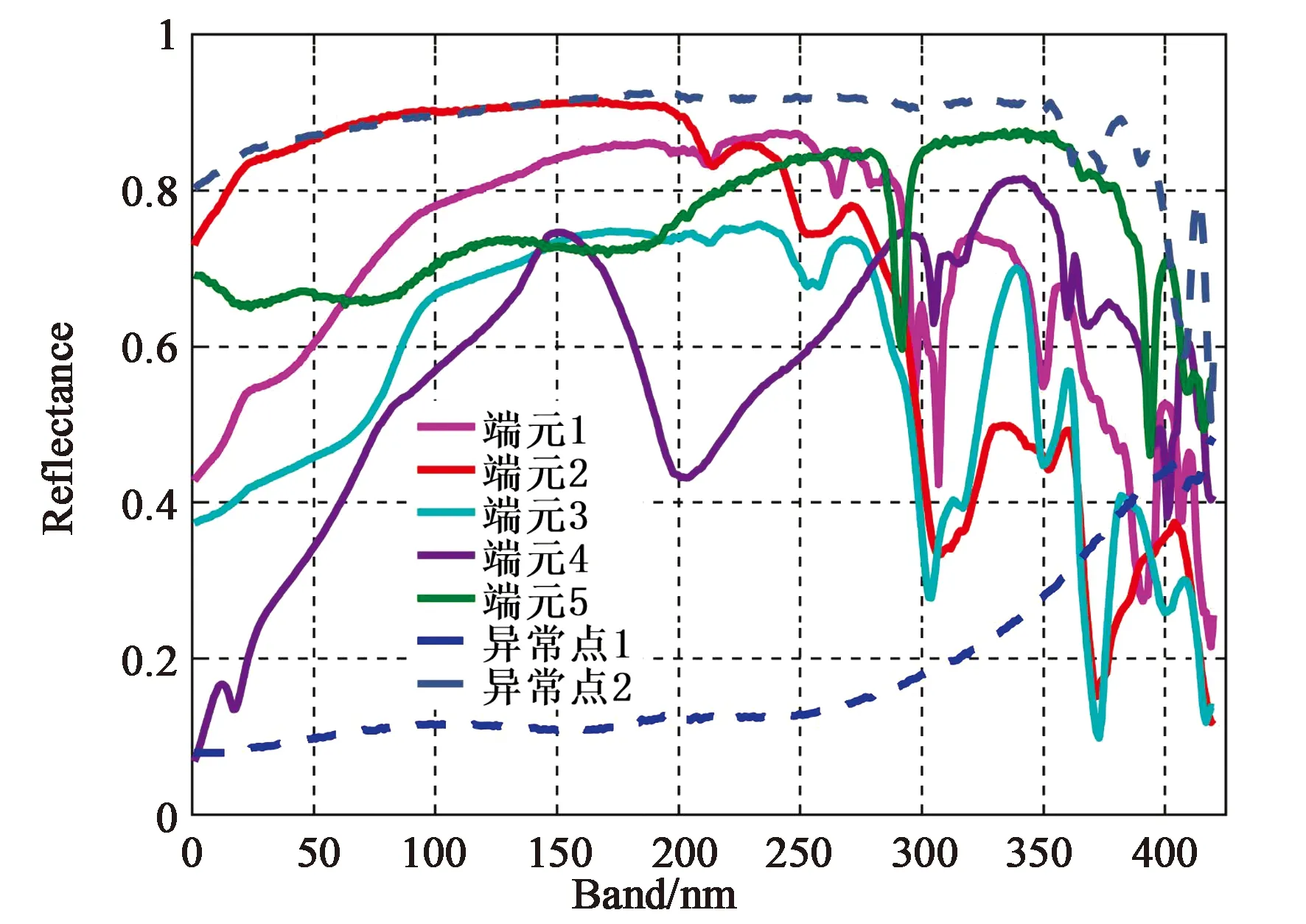
图3 模拟高光谱图像中端元和异常点的光谱曲线Fig.3 Spectral curves of the endmembers and outliers in the simulated hyperspectral image
3.2 真实高光谱图像
选用的真实高光谱图像是1994年采集的加州Jasper Ridge自然保护区,具有224个波段,波段范围为380~2 500 nm,光谱分辨率高达9.46 nm,移除受水蒸气和大气影响的26个波段(1~3 nm、108~112 nm、154~166 nm和220~224 nm)后,剩余198个有效波段数据。由于该高光谱图像比较复杂,截取以原始图像中第(105,269)像元为第一像元的100像元×100像元的子图像进行端元提取性能评估实验,该子图像对应空间区域主要由树、水、土壤和道路4种端元成分组成。图4是由该子图像的第50、75、125有效波段组成的伪彩色图。

图4 Jasper Ridge伪彩色图Fig.4 False color map of Jasper Ridge
4 实验结果与讨论
本文共进行了3组仿真实验,第1、2组是利用模拟高光谱图像,第3组是利用真实高光谱图像。第2、3组实验中采用经典方法VCA和SMACC进行了预处理之后端元提取,并分别用SPI+VCA和SPI+SMACC来表示。
4.1 第1组实验
为了验证候选端元集的有效性,针对3.1中模拟高光谱图像,先利用2.1的方法计算了其SPI值分布图,接着利用2.2的方法去除了空间冗余像元,实验结果如图5所示。
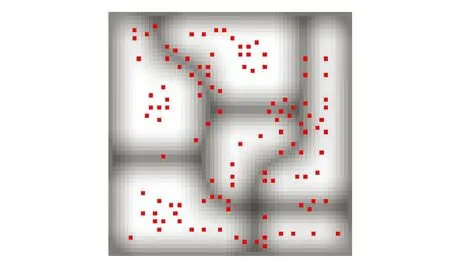
图5 候选端元分布图Fig.5 Distribution of candidate pixels
图5中红点表示经过2.1~2.2方法得到的候选端元;而背景灰度图中各像元的灰度对应其最大丰度系数值,用于表示实际光谱纯度,灰度值越大(越亮),表示该像元实际光谱纯度越高。
从图5可以看出:(1) 大部分候选端元分布在各端元对应的空间区域中光谱纯度较高的中心区域,且两个异常像素点均未被选为候选像元;(2) 仅小部分候选端元分布在不同端元对应空间区域的相邻边界,说明这些候选端元虽然实际光谱纯度低,但与相邻像元光谱相似度较高,因此一般都是多个端元均匀混合后的混合像元,进而后续在候选像元集范围内进行端元提取处理时,较容易去除;(3) 候选端元数量是116,远少于原始像元数量3 600,大幅减少了后续端元提取过程中时间复杂度。实验结果表明,提出的候选端元获取方法合理有效。
4.2 第2组实验
为了进一步验证候选端元集的有效性,比较了未经任何预处理时端元提取效果与采用提出的预处理方法时端元提取效果。分别利用VCA和SPI+VCA、SMACC和SPI+SMACC算法,对模拟高光谱图像进行了端元提取处理。不同算法提取的端元对应空间位置坐标如表1所示,对应光谱曲线如图6所示。

表1 提取的端元对应空间位置坐标Tab.1 Spatial coordinates of the extracted endmembers
从表1 可以看出,VCA和SMACC算法提取的端元中,端元1和端元5对应的空间位置坐标与模拟高光谱图像中添加的异常点坐标相同,即VCA和SMACC算法中,两个异常点被提取为端元光谱。而SPI+VCA和SPI+SMACC提取的端元中,没有包含异常点或者其空间相邻像元。这表明提出的预处理方法可有效避免异常点干扰。
图6表明,SPI+VCA和SPI+SMACC算法提取的5个端元光谱曲线均与对应原始端元光谱曲线一致。而VCA和SMACC算法提取的端元中,只有端元2、端元3、端元4的光谱曲线与对应原始端元光谱曲线一致,端元1和端元5的光谱曲线与图3中给出的异常点光谱曲线一致,这与表1的结果相符合。另外,由表1可知,SPI+VCA算法提取的端元2、端元4、端元5的空间坐标与SPI+SMACC算法提取的相应端元空间坐标相同,而图6中两种算法提取的端元光谱曲线之间却有所差异。相比SPI+SMACC算法,SPI+VCA算法提取的端元光谱曲线与原始端元光谱曲线更加一致,且更加平滑。这是因为VCA算法在端元提取过程中,采用数据降维算法PCA去除了图像中的噪声,而SMACC算法没有进行任何去噪处理。
为了定量评价不同算法的端元提取性能,采用SAD法计算了提取的各端元光谱与其对应的原始端元光谱之间的夹角,以衡量不同算法的端元提取精度,计算结果如表2所示。
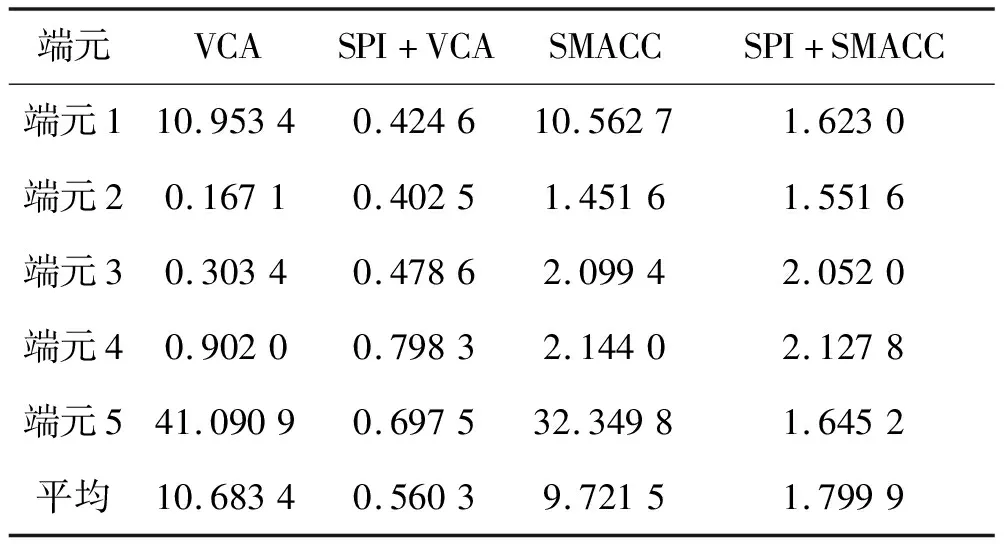
表2 提取的端元与对应原始端元之间光谱夹角Tab.2 Spectral angle between the extracted endmembers and original endmembers
由表2可以看出,SPI+VCA和SPI+SMACC算法提取的5个端元与其对应的原始端元之间光谱夹角均较小,且相比SPI+SMACC,SPI+VCA对应光谱夹角平均小1.23°,这与图6相符合;而VCA和SMACC算法提取的5个端元中,端元2、端元3、端元4与其对应的原始端元之间光谱夹角较小,端元1和端元5由于受异常点干扰,导致对应光谱夹角较大,这与表1结果相符合。VCA算法对应的光谱夹角比SPI+VCA算法对应的光谱夹角平均大10.1231°,SMACC算法对应的光谱夹角比SPI+SMACC算法对应的光谱夹角平均大7.921 6°。这表明经过预处理后端元提取精度得到了显著提高。
4.3 第3组实验
为了充分验证预处理方法的性能,针对3.2中真实高光谱图像Jasper Ridge进行了仿真实验。图7是SPI+VCA算法提取的Jasper Ridge中4个端元光谱曲线,与相应典型地物光谱曲线基本一致。在SPI+VCA算法中,参与端元提取的候选端元数量为726,远少于原始像元数量10 000。
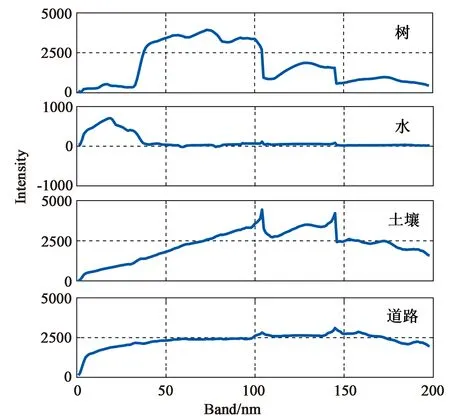
图7 Jasper Ridge的4个端元光谱曲线Fig.7 Spectral curves of Jasper Ridge’s four endmembers
然而,由于较难确定真实高光谱图像中精确的原始端元光谱,第3组实验对真实高光谱图像进行了光谱解混合处理,并比较了不同算法求解的丰度系数图,以验证预处理方法的性能。与第2组实验类似,第3组实验中仍分别比较了SPI+VCA和VCA算法,SPI+SMACC和SMACC算法。其中,对于SPI+VCA、SPI+SMACC、VCA算法,采用全约束最小二乘法FCLS[17]求解各端元对应的丰度系数;而对于SMACC算法,算法本身在提取端元的同时求解各端元对应的丰度系数。实验结果如图8所示。
通过对比分析图8(a)和图8(b)可知,SPI+VCA算法对应的各端元丰度图与真实地物分布是一致的,且相比VCA算法对应的各端元丰度图,显然更好地区别出了树、水和土壤,更清楚地识别出了道路线条,即每个像元的端元属性更加显著,各端元对应地物的区域性更加明显,空间连续性更好,这说明相比VCA算法,SPI+VCA算法提取的端元更加精确,且抗噪能力更强。

(a) SPI+VCA、VCA与原始端元(a) SPI+VCA vs.VCA vs.original endmember
通过对比分析图8(c)和图8(d)可知,SPI+SMACC算法对应的各端元丰度图与真实地物分布也是一致的,且相比SMACC算法对应的各端元丰度图,显然更准确、更清楚地识别出了各端元对应地物,尤其是水和土壤。SMACC算法中未能识别出水,且把土壤识别为两种地物。这说明相比SMACC算法,SPI+SMACC算法提取的端元更加精确,且抗噪能力更强。

图8 丰度图Fig.8 Abundance maps
5 结 论
本文针对高光谱端元提取,提出了一种空谱联合的预处理方法,先利用文中定义的光谱纯度指数SPI测量高光谱图像中每个像元的光谱纯度,并在此基础上,利用SPI的空间分布去除光谱纯度较低的冗余像元,从而形成精简的候选端元集。经过预处理后,采用常用端元提取方法,在候选端元集范围内提取端元。
实验结果表明,采用提出的预处理方法后,对于模拟高光谱图像,提取的端元与原始端元之间夹角平均减少了9.022 3°,候选端元数量少于原始像元数量的10%。即提出的预处理方法显著提高了抗干扰性,有助于有效提高端元提取精度;且大幅减少了参与端元提取的像元数量,明显降低了时间复杂度;另外,该预处理算法不需要设定任何与图像相关的阈值,因而具有较高的算法鲁棒性。
