不平衡数据集下的水下目标快速识别方法
2020-09-04刘有用张江梅王坤朋冯兴华杨秀洪
刘有用,张江梅,王坤朋,冯兴华,杨秀洪
西南科技大学 信息工程学院,四川 绵阳 621010
1 引言
目前,在海洋牧场建设及渔业领域,海参、海胆、贝类等海珍品的捕捞方式主要依靠拉网式捕捞和人工捕捞两种。拉网式捕捞效率高,成本相对低廉,但会对海底生态造成极其严重的破坏;而人工捕捞比较环保,但存在效率低、成本高及危险性高等问题[1]。随着机器人技术的应用发展,人们期望利用水下捕捞机器人实现海珍品的捕捞,而实现机器人捕捞的关键在于能够准确、快速地识别水下目标。
由于海洋水下成像环境复杂,会导致光视觉系统获取到的图像出现颜色衰退、对比度低以及细节模糊等现象,严重退化的水下图像由于缺少用于目标识别的有效信息,导致水下目标检测识别难度提升[2]。传统的水下目标识别方法包含图像预处理、目标提取、特征描述和分类器设计等步骤[3]。目标提取方法有阈值分割和边缘检测等,如Otsu的类间方差最小化全局阈值分割方法[4]和Canny 的基于双阈值和边缘跟踪的边缘检测算法[5]。人工提取的特征包括形状、尺寸、纹理和基于频谱的特征等。之后再通过支持向量机、K-近邻、神经网络等方法训练分类器以实现水下目标的识别[6]。受水生动植物、水流扰动的影响,传统方法在目标提取时会提取出大量非目标区域和边缘,且基于人工选取的特征进行分类,方法鲁棒性差,目标识别效果不理想。
近年来,伴随着人工神经网络[7(]Artificial Neural Network,ANN)技术与计算机技术的快速发展,各国学者将人工神经网络运用到水下目标识别这一领域。由于计算能力的提升及神经网络训练、优化算法的改进,深度学习方法[8]被逐渐应用到水下图像处理与目标识别中。Kamal 等人提出了一种用于水下目标识别的深度学习架构,使用深度置信网络(Deep Belief Network,DBN)结构来进行预训练[9]。文献[10]将卷积神经网络与迁移学习相结合用于鱼类的自动分类。文献[11]将层叠自动编码器(Stacked Auto-Encoder,SAE)作为一种深度学习方法,用于获取高级特征,并结合softmax分类函数进行水下目标分类,达到了较高的分类精度。
上述方法能够提取目标的深层次特征,解决传统方法鲁棒性差、识别精度低的问题。但仍存在两方面的不足:一方面,由于水下图像采集设备要求高、技术难度大等特点,导致采集到的样本数量少及类不平衡问题[12],对于目标数量多、信息丰富的类别识别精确度高,而目标数量少的类别则识别精确度低。另一方面,水下成像环境复杂导致图像质量下降,训练样本不能包含丰富的有效目标信息,严重限制了模型识别精确度的提升。
为解决训练样本少的问题,传统方法通过对图像进行翻转、对比度和饱和度调整等操作扩充训练样本,增加了训练样本的多样性,从而能在一定程度上提升识别精确度。Alexnet 在分辨率为256×256 的数据集图像中遍历地选取224×224大小的图像,并对图像做了水平翻转操作,从而将训练集扩充了2 048倍[13],但此类操作增加的图像仅是对原始图像质量的改变,对于降质的水下图像不能有效地丰富待识别目标信息,识别精确度提升不明显。文献[14]提出了一种基于度量指标优化的不平衡数据Boosting算法,在一定程度上提高了正类分类性能。文献[15]利用一种改进的中值滤波算法对鱼类图像进行噪声抑制,然后利用图像识别数据库imagenet的图像对卷积神经网络进行预处理,最后利用预处理的鱼类图像对训练好的神经网络进行微调,获得了良好的鱼种识别能力。该方法采用迁移学习的思想为解决小样本情况下的识别任务提供了一种有效的方法,通过简单地调整在一个问题上训练好的模型即可得到适用于新问题的新模型,但在实际水下目标的识别过程中很难找到具有相同特征的预训练数据库。
2014年Goodfellow等人受博弈论中二人零和博弈思想的启发,开创性地提出了生成对抗网络[16(]Generative Adversarial Network,GAN),使得利用已有图像生成新图像的设想成为可能。因此,针对水下目标样本数量有限及类不平衡问题,本文提出一种基于生成对抗网络的训练样本扩充方法,通过截取训练样本中数目少的类别目标图像,利用生成对抗网络生成大量异构的目标图像并融合到背景图像中作为训练样本,丰富目标信息,有效扩充训练样本集。最终结合端到端的YOLO(You Only Look Once)[17]目标识别算法训练识别模型,实现水下目标的准确、快速识别,并通过实验验证该方法的有效性和适用性。
2 图像生成与目标识别模型
2.1 基于GAN的水下样本生成
生成对抗模型是一种无监督的深度学习模型,模型框架中包含两个模块:生成模型(Generative Model)和判别模型(Discriminative Model),通过两个模块的互相博弈学习,分别使模型G的生成能力和D的识别能力越来越强,最终达到稳定状态。
在训练过程中,输入训练样本图像和一组随机噪声,生成网络G的目标是通过随机噪声的分布学习训练图片的数据分布,而D的目标则是对G生成的图片和真实图片进行识别,D和G的优化过程是一个二元极小极大问题,模型目标函数如下:
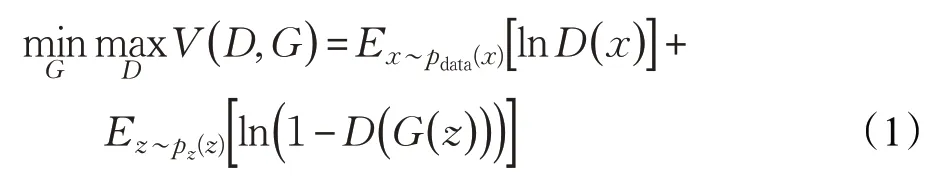
式中,x为真实数据,pdata(x)是真实数据分布,z表示输入G网络的噪声,pz(z)是噪声分布,G(z)表示G网络生成的数据;D(x)表示D网络判断真实数据是否真实的概率,而D(G(z))是D网络判断G生成的数据是否真实的概率。训练判别器D时,使用梯度上升算法,使目标函数的值增大;同理,当训练生成器G时,使用梯度下降算法训练生成器参数,使目标函数的值减小。
本文采用生成对抗网络生成目标图像从而达到扩充训练样本的目的,与图像翻转、饱和度及对比度调整等传统方法扩充的样本不同,生成对抗网络通过训练目标图像生成区别于原始图像的异构目标图像,并与背景融合得到新的训练样本,能够获得更加丰富目标特征信息。样本生成方法流程如图1所示。
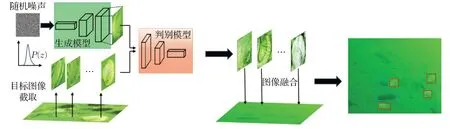
图1 训练样本生成流程图
生成对抗网络中使用CNN实现类似于深度卷积生成 对 抗 网 络[18(]Deep Convolutional Generative Adversarial Network,DCGAN)的全卷积网络,通过批规范化处理提升训练速度,也在一定程度上改善了D网络分类能力;在G网络和D网络中使用ELU 作为激活函数,加快了模型收敛速度,缓解了梯度消失的问题。利用原始样本中截取出的目标图像作为生成对抗网络的输入样本,训练后生成异构目标图像,截取的目标图像和训练后生成的目标图像如图2所示。由图2(b)可知,生成的图像不是对原始输入图像的直接复制,也不是对输入图像的旋转或对比度、饱和度等调整,生成对抗网络生成的图像为全新的目标图像,且包含目标完整轮廓和细节信息,有效地丰富了目标图像特征信息的多样性。

图2 水下目标图像生成
生成对抗网络生成的图像仅为单个目标图像,需要与背景图像融合后才能作为有效训练样本。为了符合实际目标分布规律,生成目标在背景图像中随机分布,且不能覆盖背景中的原始目标。由于生成图像的宽高已知,只需要计算出图像在背景中的中心坐标即能确认其位置,生成图像在背景中的中心坐标为:

式中,U为生成目标与背景目标的重叠率,θ为重叠率阈值,L和H为背景图像宽高,l和h为生成图像宽高,(x′,y′)为背景图像像素点坐标,(xi,yi)为背景中第i个目标的中心坐标,n为背景中目标的个数,包括已经融合到背景中的目标。
若目标图像边界与背景融合的宽度为r,则融合权重ω表示为:

对目标图像左边界融合,融合后的图像像素值为:

式中,g(x,y)表示融合后图像像素值,g′(x,y)表示背景图像像素值,g″(x,y)表示目标图像像素值。同理,对图像右边界、上边界和下边界进行融合。
原始背景图像和融合后生成的样本图像如图3 所示,在图3(b)中,融合后的样本图像中包含原始背景目标和生成目标,图像中的待识别目标数量增多,且生成的目标在图像中随机分布,符合水下目标的真实分布情况,将融合后的图像作为扩充的训练样本,可以有效地增加待识别目标信息。

图3 原始背景图像和融合后图像
传统方法通过对图像进行旋转、饱和度和对比度调整后扩充的训练样本集图像如图4所示。图4(b)中,图像进行了180°旋转,增加了目标在背景图像中的位置信息;图4(c)和图4(d)中,只改变了图像的对比度和饱和度,而目标的形状及在图像中的位置等信息没有增加。由图3 和图4 可知,本文的样本扩充方法区别于传统样本扩充方法,利用生成对抗网络生成形状及轮廓各异的目标图像,并随机融合到背景图像中,可增加训练样本的丰富性和多样性。

图4 传统图像调整方法扩充的样本图像
2.2 目标识别模型
水下目标的实时、准确检测识别是实现水下机器人抓取、捕捞作业的前提。目前,基于深度学习的目标检测方法主要包括基于候选区域的算法(R-CNN[19]、Fast R-CNN[20]、Faster R-CNN[21]等)和基于回归方法的目标检测算法(LOYO、SSD[22]等)两类。主流算法中,Faster RCNN 识别精确度高且对小目标的检测效果好,但目标检测速度慢,不能达到实时检测的要求;SSD 算法检测速度快,但对小物体的识别效果较差;YOLO 算法采取了前两种算法的部分优势,实现了目标的实时检测,且识别精度高,对图像中的小目标仍具有较好的检测效果。为实现水下目标的快速检测且对图像中的密集型小目标具有较高的识别精确度,本文采用YOLO算法进行水下目标识别。该算法是一种端到端的目标检测识别算法,利用卷积神经网络同时预测目标位置和类别,算法模型结构简单,将输入图像分成S×S个网格,每个网格利用Nb个初始候选框预测可能的目标边界框及Nc个类别概率,每个边界框的信息为(x,y,w,h,p),其中(x,y)为边界框中心位置坐标,w和h为边界框宽和高,p为置信度,反映预测边界框包含目标的概率和边界框的预测精确度,测试时每个边界框的类相关置信度pi为:

式中,Pr(O)反映边界框包含目标的概率,Pr(Ci|O)表示在边界框包含目标的条件下为某类目标的概率,i=1,2,…,Nc,为预测边界框与Pr(Ci)真实边界框的交并比。
YOLO算法借鉴了ResNet的残差结构,解决因网络层数增加后出现的退化问题;通过预测边界框中心点相对于网格左上角的相对坐标来确定边界框中心坐标;为提高对小目标的检测准确率,融合多级特征图,在不同尺度的特征图上进行检测,构成YOLOv3[23]网络。使用K-means方法对训练集中目标边框的宽高维度进行聚类,确定初始候选框的数目和尺寸,对于本文训练数据集,不同聚类数目k对应的目标边框平均交并比如图5所示。
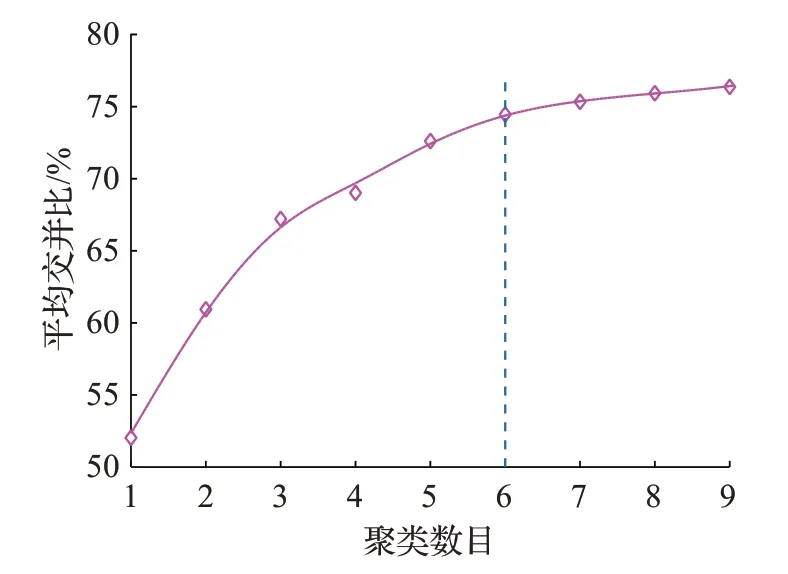
图5 K-means目标边框聚类结果
由图5可知,目标边框平均交并比随着聚类数目的增加而增大,当k大于6 时平均交并比逐渐稳定,权衡模型复杂度和识别召回率后选择k=6,将聚类得到的6个初始候选框平均分配到3 个不同尺度的特征图上进行检测。每个网格预测2 个边界框,每个边界框包含5个参数信息及4个类别的概率,因此每个网格检测输出张量大小为18。为保证目标的识别精确度,同时满足实时检测的要求,本文用于水下目标检测的YOLO模型调整输入图像大小为480×480,模型最大降采样倍数为32,最终不同特征图的输出张量分别为15×15×18、30×30×18和60×60×18,检测模型结构如图6所示。

图6 检测网络结构图
3 实验结果与分析
为了验证生成对抗网络生成的图像对水下目标识别的有效性,设计实验测试传统图像调整方法和本文样本生成方法的样本扩充性能及其用于水下目标识别的效果,并对实验结果进行显著性差异分析。
3.1 水下图像目标识别实验
本文实验基于 Intel®Xeon®Silver 4114CPU 和NVIDA Quadro GP100 硬件条件,生成对抗网络使用Tensorflow架构,目标识别模型使用Darknet53框架。分别利用图像调整方法和样本生成方法扩充原始图像样本集后进行目标识别模型的训练和测试。本文原始数据样本为2018 水下机器人目标抓取大赛官方提供的3 151张水下图像,所有图像均在真实海洋环境下拍摄,图像质量呈现不同类型、不同程度的下降;图像包含海参、海胆、贝壳和海星四类目标,所有目标在图像中非均匀分布,部分目标出现遮挡和覆盖。考虑原始样本中海参、海胆和海星目标数目多,而贝壳目标数量少的特点,将原始样本训练集和验证集图像中的1 015个贝壳目标截取出来,作为生成对抗网络的输入,训练后生成1 402张异构的贝壳图像,通过与不同背景融合生成1 000 张有效样本图像。实验的数据设置如表1 所示,实验1 中随机对原始样本进行旋转、饱和度和对比度调整,旋转角度为180°,饱和度的调整比率为0.75,对比度的调整比率为1.5。
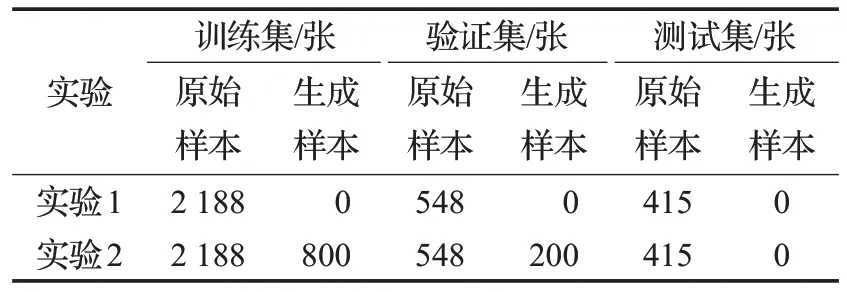
表1 实验数据设置
在模型训练过程中,每迭代一定的次数,动态调整输入图像大小,让模型可以适应不同输入尺寸,最终同一个网络对不同输入维度都能进行很好的预测。利用测试集对训练后的模型进行测试,基于平均精确度(Averge Precision,AP)指标比较两种方法的识别结果,并对几种YOLO 算法模型的水下目标检测速度进行实验对比。
(1)水下目标识别平均精确度
模型使用生成样本训练后对几类目标识别的平均AP(mAP)提升结果如图7所示,样本生成方法在不同迭代次数下的mAP 均高于传统图像调整方法的mAP,当迭代次数为4 100 次时,几类目标的平均识别精确度提升了2.5%。利用图像调整方法扩充样本集的情况下,在迭代3 000次后模型达到最高mAP值,而加入生成样本训练模型的mAP 继续增加。随着模型继续迭代训练,由于训练数据集中存在类不平衡问题,模型出现过拟合现象,识别召回率下降,导致识别平均精确度降低,而使用生成对抗网络生成贝壳图像并与背景融合后作为训练样本,减小了训练集中几类目标的数量差异,有效提高了水下目标识别精确度。

图7 识别精确度提升结果
两种方法对几类目标的识别精度如图8 所示。由图8 可知,两种方法对海参、海胆和海星三类目标的识别结果基本一致,模型对海胆和海星两类目标的识别精确度较高,平均精确度在0.8以上。对于贝壳类别,由于训练图片中该类目标数目少、图像质量差等因素,模型识别精确度低;而加入生成样本训练的模型对贝壳的识别精确度提升了7.8%,生成对抗网络生成的贝壳图像能改善网络对贝壳的识别效果。

图8 几类目标识别平均精确度对比
为了验证生成样本的数量对目标识别结果的影响,继续增加样本集中生成样本的数量,以4∶1的比例加入训练集和验证集,然后训练目标识别模型,检测贝壳目标的识别精确度如表2 所示。当生成样本数量为1 000张时,贝壳的识别精确度提升了7.8%,随着生成样本数量继续增加,贝壳的检测精确度呈下降趋势。当生成样本数量为1 500 张时,生成图像的数量多于原始图像数量,样本的丰富性和多样性受到限制,识别精确度的提升不明显,甚至出现过拟合。因此,在不平衡数据集中,通过生成对抗网络扩充训练样本的方法可以有效平衡数据集,提升目标识别精确度,但过多的生成样本会增加冗余的待识别目标信息,导致模型出现过拟合。

表2 不同数量生成样本的贝壳检测精确度
在目标识别任务中,图像集的质量是影响目标识别精确度的一个重要因素,因此,随机调整生成图像的饱和度和对比度,改变图像质量,训练网络后进行测试,结果表明,此类方法图像质量的改变对水下目标的识别效果没有明显改善。高质量的图像包含更丰富的目标特征信息,对目标的识别越有利,对于生成的图像,其质量越接近原始图像,对水下目标的识别结果就越好。由图2可知,生成的图像在轮廓和纹理上与原始图像相近,但部分细节信息仍没有原始图像清晰,因此,生成质量更高的图像也是下一步的研究工作。
(2)水下目标检测速度
在目标检测识别过程中,YOLOv3算法初始候选框的数目k、输入图像尺寸的大小调整等都会对目标检测速度产生影响。k值增大,能在一定程度上提高目标检测的召回率,但会增加模型的复杂度;算法检测目标时需要重新调整输入图像尺寸的大小,调整为不同尺寸后检测速度不同。为确定初始候选框的数目和图像尺寸大小对水下目标检测精确度和速度的影响,分别在不同k值和图像尺寸下进行测试,根据415 张测试图片的平均耗时计算出检测帧率(Frames Per Second,FPS)。
由于模型将聚类得到的k个初始候选框平均分配到3个不同尺度的特征图上进行检测,因此分别在k值为3、6和9的条件下测试算法对水下目标的检测精确度和检测速度,输入图像的尺寸调整为608×608,实验结果如表3所示。
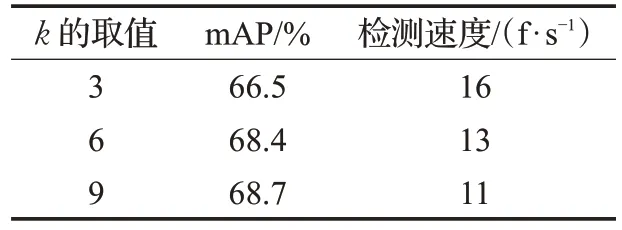
表3 不同k 值下水下目标检测速度
由表3 可知,随着k值增大,每个检测尺度上的候选框数目增多,目标检测召回率增加,检测精确度增大,但模型的复杂度也逐渐增加,检测速度下降;当k值达到6 后,检测速度降低而检测精确度的提升不明显,与图2 的结果一致。为确定输入图像尺寸大小对检测精确度和速度的影响,在k为6的情况下,对4种YOLOv3模型的水下目标检测速度进行测试,测试包含4种不同的检测图像尺寸,分别为608×608、544×544、480×480、416×416,测试结果如表4所示。
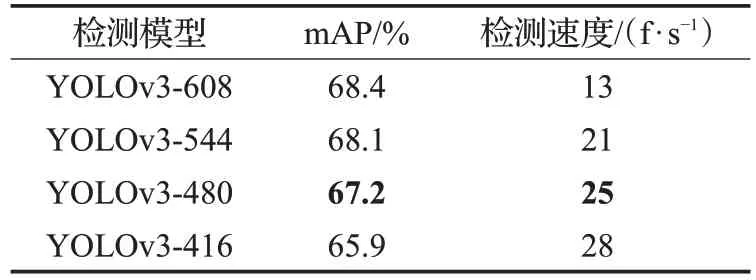
表4 不同输入图像尺寸的水下目标检测速度
由表4 可知,YOLOv3-608 达到68.4%的识别精确度,其检测速度为13 f/s,随着检测图像尺寸减小,目标识别精确度随之降低而检测速度增加,YOLOv3-480 和YOLOv3-416检测速度均大于24 f/s,满足实时检测的要求。综合目标识别精确度和检测速度,YOLOv3-480模型在保证较高识别精确度的基础上可以实现水下目标的快速检测。
3.2 显著性差异分析
通过Paired t-test检验两种方法对几类目标的识别结果之间是否存在显著性差异,确定在统计意义下本文样本生成方法的识别结果是否显著优于传统图像调整方法的识别结果,即采用生成对抗网络扩充样本的方法能显著改善目标识别结果。
Paired t-test 的原假设为两种方法的识别结果没有差异,若N为测试次数,c1i(i=1,2,…,N)为传统方法不同迭代次数下的识别精确度,c2i为本文方法在不同迭代次数下的识别精确度,di=c2i-c1i,计算t统计量:

在本实验中,计算海参、海胆、贝壳和海星的t统计量分别为th=0.110 8、te=0.659 7、ts=9.787 9、tf=0.166 5,当N=13,显著性水平α=0.05 时,临界值为2.178 8。对于海参、海胆和海星三类目标原假设被接受,而贝壳目标原假设被拒绝,即加入生成图像训练的方法与图像调整的样本扩充方法具有显著的差异,本文基于生成对抗网络的水下目标识别方法能显著改善目标识别效果。
4 结束语
基于生成对抗网络的水下目标识别方法结合生成图像和原始图像训练目标识别模型,能有效扩充训练样本集,解决小样本及类不平衡问题,相比于直接利用原始图像训练模型的方法,提高了目标识别精确度。采用生成对抗网络生成单个目标图像,调整大小后随机分布到背景图像中,并通过边界融合算法使其与背景融合,最终作为目标识别模型的训练样本,这是一种简单实用的样本扩充与目标识别方法,适用于水下、空中等特殊环境图像的目标识别,特别是针对训练样本图像数量少、质量差等情况,能够有效改善识别效果。下一步的工作将研究如何生成更高质量的图像,同时,研究如何在水下机器人嵌入式处理平台上实际使用本文提出的目标识别算法。
致谢感谢国家自然科学基金委主办、大连理工大学等单位承办的水下机器人目标抓取大赛提供的水下目标真实图像数据,本文在该数据的基础上完成了实验。也感谢此次大赛,在参加比赛过程中对水下目标识别与抓取问题的思考,是本文创新与研究思路的出发点。
