运用NLP算法和BP神经网络系统分析商品评论数据
2020-09-03谢易宏
谢易宏
(上海师范大学,上海 200234)
1 新技术应用的必要性
随着科技的发展,网购已经成为人们主流的购物方式之一,据联合国贸易和发展会议(United Nations Conference on Trade and Development,UNCTAD)2019年3月29日发布的数据显示,2017年全球电子商务(Electronic Commerce,EC)交易额比上年增加13%,达到29.367万亿美元。通过网购独有的评级、评论、帮助性评级和评论时间等,来提出在线销售战略,确定潜在的重要设计特征,以增强产品的吸引力,成了公司线上销售部所必须要解决的问题之一。
自然语言处理在实体抽取,情感分析等任务上的准确度不断提高[1],为精确处理评论数据提供了可能。通过对评论的关键词提取以及情感分析,可以有效地从大量的评论数据中获取有效信息,从而获得对商品的有效反馈,可以针对性地改进产品质量,制定营销策略。
2 模型设计
2.1 模型概览
模型首先通过爬虫在电商平台上获取相应的评论数据,再利用自然语言处理工具(Natural Language Toolkit,NLTK)对数据依次进行清洗、分词,根据词频——逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)算法对关键信息进行抽取,最后同样利用NLTK对关键信息进行情感标注,获取情感倾向。对于时域上的评论数量的变化,利反向传播(Back Propagation,BP)神经网络对未来的数据进行预测,从而有效地对评论数据进行分析和预测,如图1所示。
2.2 数据来源
本数据集来自美国亚马逊电商平台,文章利用Python中的request包爬取了2004——2019年吹风机和奶嘴商品的11 417条评论记录。评论数据按照商品编号、购买时间、星级、评论文本存储在MySQL数据库中。
2.3 关键词提取
NLTK是一套基于Python的自然语言处理工具集,能实现分词、词性标注、词频分析、情感分析等丰富的功能[3]。将数据导入程序,进行文本清洗,分句和分词处理后,对相应的分词进行词形归一化,去除标点以及去除停用词,以最大程度地保留有用数据。随后采用TF-IDF算法进行关键信息提取。
TF指词频,表示在一段文本中单词出现的频繁程度。假设在一段文本W={w1,w2,…,wn}中,共n个词,其中单词x出现了m次,那么单词x的词频就是:
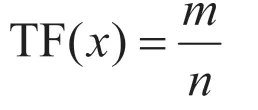
IDF指逆文档频率,表示在所有文本中单词出现的不频繁程度。假设N代表语料库中所有的文本,N(x)表示语料库中包含词x的文本总数,那么该词x的IDF为:
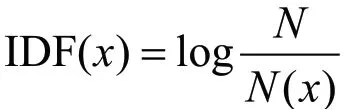
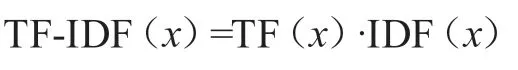
在得到TF和IDF之后,一个词x的TF-IDF值计算为:通过在scikit-learn中使用TfidfVectorizer实现TF-IDF,从而得到相应的文本关键词。
2.4 情感标注
情感分析或观点挖掘是通过计算来识别作者对某段文本的态度是积极、消极还是中性的过程[2]。此反馈可能很有用,比如在自然语言评论中挖掘对某款产品或服务的观点时。NTLK包含一个简单的基于规则的情感分析模型,其中组合了词汇特征来识别情感强度[3-4]。导入必要模块(包括Vader情感分析器),创建一个函数来接受某个句子并呈现情感分类。该函数首先对SentimentIntensityAnalyzer执行实例化,然后使用传递的句子来调用polarity_scores方法。结果是一组浮点值,表示输入文本的正或负价态。这些浮点值是为4个类别(正、中性、负和表示一个聚合分数的化合态)而发出的。该脚本最后调用传递的参数来识别情感,最终得到每一条评论对应的情感指数。
2.5 数据预测
BP神经网络具有任意复杂的模式分类能力和优良的多维函数映射能力,解决了简单感知器无法解决的排他性OR,XOR和其他一些问题。在结构上,BP网络有输入层、隐藏层和输出层。本质上,BP算法以网络的平方误差作为目标函数,采用梯度下降法计算目标函数的最小值[5]。
模型统计每一年的评论数量并绘制趋势图,再利用BP神经网络对数据进行拟合,从而可以对未来的数据进行预测。
3 实验部分
3.1 关键词提取
通过TF-IDF算法,得到了相应的关键词,从中抽去了20条并根据出现频率进行排序,命名后存入txt文档中,如图2所示。

图2 关键词提取
3.2 情感标注
针对每一条评论,分别给出其相应的情感指数,其中正数代表正向情感,负数相反。指数越接近1,说明倾向性越显著,如图3所示。
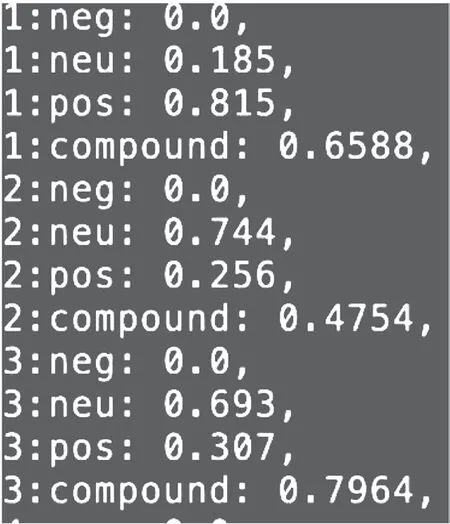
图3 情感标注
3.3 趋势预测
针对按年统计的评论数量,划分出训练数据和测试数据,并对数据进行了拟合,结果显示出不错的拟合效果,如图4所示。
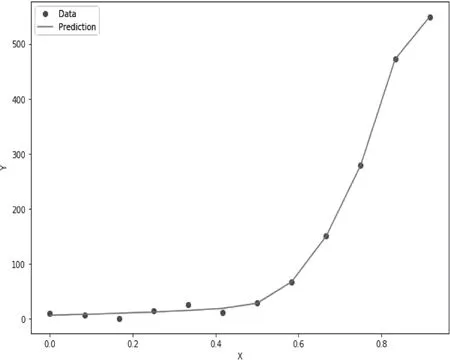
图4 拟合效果
4 结语
该模型较好地对商品评论数据进行了分析处理,同时也存在以下一些缺点:(1)情感分析的粒度相对粗糙,缺乏层次分析和对情感因素的深层探讨。(2)数据量相对较少,容易出现过拟合现象,难以对更长时间的数据进行准确预测。
