基于深度学习的无人驾驶视觉识别
2020-09-02李嘉宁刘杨胡馨月刘建恬陈宗文
李嘉宁 刘杨 胡馨月 刘建恬 陈宗文

摘 要: 大数据技术的发展,以及基于图像处理单元(GPU)并行计算能力的提升,共同促进了深度学习算法在无人驾驶视觉识别等领域的应用。在Ubuntu 16.04操作系统上,搭建Python实验环境,开展基于卷积神经网络——Mask R-CNN的无人驾驶视觉识别实验。使用VIA 3.0工具,实现图像与视频的标注与分类;采用GTX 1080Ti GPU、cuDNN显卡加速包等软硬件,實现模型训练和测试;引入混淆矩阵和平均精度等指标对卷积神经网络模型进行性能评估。结果表明:视觉识别效果较好、可靠性较强,展现了深度学习技术在该领域具有很高的应用价值。
关键词: 深度学习;无人驾驶;卷积神经网络;视觉识别;性能评估
中图分类号:TP2 文献标识码:A 文章编号:2095-8412 (2020) 04-054-04
工业技术创新 URL: http://gyjs.cbpt.cnki.net DOI: 10.14103/j.issn.2095-8412.2020.04.010
引言
近年来,深度学习技术促进了人工智能在学术界和工业界的推广应用。深度学习算法起源于人工神经网络,为多层神经网络在各个大规模计算领域中的应用提供了一种有效的途径。大数据技术的发展,以及基于图像处理单元(GPU)的并行计算能力的提升[1],正在同步促进深度学习算法的深度应用,如无人驾驶智能系统的研究。
道路环境智能感知是无人驾驶技术的重要组成部份,主要依赖于高分辨率摄像头、超声波雷达、激光雷达、GPS定位仪等设备及时、准确获取的路标、坑洼、路障、行人等行车环境信息。传统视觉识别算法鲁棒性差,泛化能力弱,一般而言检测精度最多达到93%(人类约能达到95%),无法达到无人驾驶所的预期标准[2]。理论与实践表明,深度学习算法具备对复杂环境进行感知的强大能力,且检测精度可达到95%以上。
本文首先介绍基于深度学习的图像处理理论;其次借助一种得以改进的卷积神经网络——Mask R-CNN,进行无人驾驶视觉识别实验;最后对实验结果进行分析和评价。
1 基于深度学习的图像处理理论
1.1 卷积神经网络
卷积神经网络(CNN)的基本结构包括输入层、卷积层 、池化层 、全连接层及输出层。
卷积层和池化层一般有若干个,二者通常交替设置,即一个卷积层连接一个池化层,这个池化层后再连接一个卷积层,依此类推。卷积层由多个特征图(Feather Map)组成,每个特征图由多个神经元组成。卷积层的作用是借助卷积操作提取图像特征。卷积层数越多,其提取的特征层次越高。由于卷积层中输出特征面的每个神经元的输入值是通过与其输入进行局部连接,对应的连接权值与局部输入进行加权求和,再与偏置值相加而得到的,而该过程等同于卷积过程,因此这一算法称作卷积神经网络。
池化层同样由特征图组成,旨在通过降低特征面的分辨率来获得具有空间不变性的特征,有二次提取图像特征的作用。
全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息,其后连接的输出层用于逻辑分类[3]。
1.2 Mask R-CNN
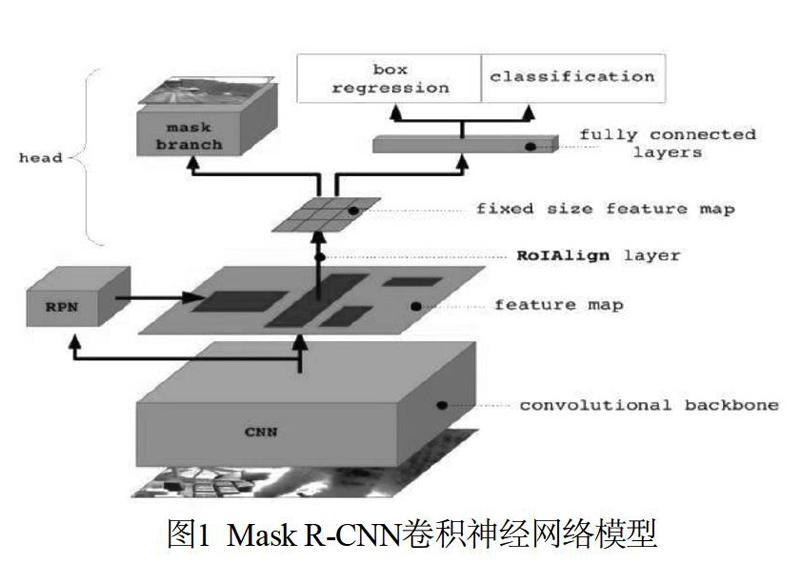
Mask R-CNN是一种卷积神经网络,其模型示意如图1所示。Mask R-CNN脱身于Fast R-CNN,并进行了诸多改进。
1.2.1 特征提取
Mask R-CNN通过ResNeXt提取特征,并通过特征金字塔网络(FPN)构成骨干网络。经过第一阶段的特征提取,给出固定大小的感兴趣区域(RoI)[4]。
1.2.2 检测与实例分割
在感兴趣区域上,Mask R-CNN一方面进行二值分类给出候选框,另一方面结合后续介绍的RoI Aligh操作,将随后的一个网络分支用于分类和回归,另一个网络分支用于分割生成掩膜(mask)。
1.2.3 RoI Aligh
RoI Aligh是一种用于增加检测精度的技术手段,用于RoI的给出阶段。在之前的检测算法中,RoI的提取会因为特征图大小和检测图像大小不匹配的原因,进行像素点取整操作,进而出现细微的位置偏差。而RoI Aligh利用双向线性差值的原理,将像素点定位规范到浮点小数级别,将位置偏差降到最低。
1.2.4 损失函数
Mask R-CNN采用多任务的损失函数,在一定程度上加快了卷积神经网络的训练效率。
综上,Mask R-CNN是一种可以同时进行目标识别和物体实例分割的卷积神经网络[5],可以有效地作为无人驾驶的视觉感知模型。
2 基于Mask R-CNN的无人驾驶视觉识别实验
2.1 数据集处理
2.1.1 图像与视频的标注与分类
VGG Image Annotator(VIA)可用于图像与视频目标的人工标注与分类[6]。本文采用VIA 3.0。标注完成后,可为数据集生成相应格式的标注信息文件(.csv/.json),以解决深度学习任务的数据集标注问题。
2.1.2 数据集制作过程
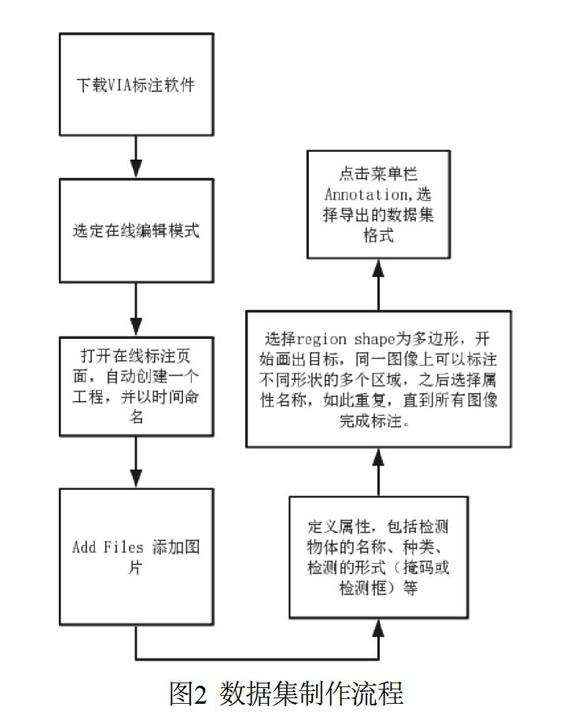
使用长春市中心360行车记录仪记载的视频,作为数据集的数据来源,并用VIA工具进行标注。数据集制作流程如图2所示。
实际操作的数据集标注界面如图3所示。
2.2 实验调试
2.2.1 实验配置
本实验在Ubuntu 16.04操作系统进行,实验环境为Python 3.5.2,实验工具为GTX 1080Ti GPU。
2.2.2 实验调试
(1)环境的搭建
首先,在Python官方网站下载Python 3.5.2版本,并在系统环境变量的路径中增加Python路径;安装成功之后,使用自带工具包pip,进行所需科学计算工具包的下载。
然后,下载Nvidia CUDA-linux显卡驱动,以及cuDNN显卡加速包,为下一步的GPU训练做准备。
(2)模型的訓练和测试
首先,将制作好的数据集放置在系统的具体目录下;其次,下载COCO2012数据集,并对Mask R-CNN网络进行预训练,得到网络初始权重;之后,在系统终端输入训练指令,使用自制数据集对网络进行训练,训练后的网络权重;最后,使用训练后的Mask R-CNN模型对未标注的360行车记录仪视频进行测试。
3 结果与讨论
3.1 评价标准
针对实验结果,引入混淆矩阵[7]和平均精度[8](Average Precision,AP)进行驾驶道路感知模型的性能评估。混淆矩阵在图像目标识别与分割任务中是最常用的评价指标之一,它以矩阵的形式,对数据真实的类别和判定生成的类别之间的对应关系作出归纳,并以此为基础,计算模型对输入数据处理的准确率、召回率、特异度以及精确度等性能指标。混淆矩阵如图4所示。
其中,在混淆矩阵的基础上,准确率P和召回率R的计算公式分别为:
(1)
(2)
在计算得相应的准确率和召回率后,便可通过生成坐标曲线的方式,计算得到平均精度AP。平均精度的计算结果还受到置信率阈值的影响。例如,若置信率阈值设定过高,置信率评分较低,则得到正确判断的阳性数据容易被过滤;若置信率阈值设定过低,则难以保证所有归纳结果的准确性[9]。因此,本实验分别取置信率阈值[10]为0、0.5和0.75进行评估,并且将相应得平均精度记为AP0、AP1和AP2。
3.2 评价实施
对自制数据的测试集进行驾驶道路环境自动感知模拟实验,效果示例如图5所示。
由混淆矩阵理论计算得到该部分实验相应的平均精度如表2所示。
3.3 讨论
视觉识别过程由训练后的Mask R-CNN实现。整体来看,实验结果具有较好的识别效果,对道路上的车辆、交通标志、行人的识别率较高,对可行驶区域、当前行驶区域的分割结果较好。
另一方面,模型对路边停靠车辆的识别效果相对较低,从而影响了整体的识别率;从原理角度分析,路边停靠车辆角度多为车头与道路垂直,而数据集中车辆标注多为车辆与道路平行,因此识别率较低是由数据集样本不够导致的,如果再此基础上增加车辆标注的角度与数量,识别效果可以更好。
综合而言,本项目依托卷积神经网络对图像特征提取的优势,在自行制作的数据集基础上较好地模拟实现了无人驾驶的视觉识别,展现了深度学习技术在各个领域的实用性、适用性。
4 结束语
使用深度学习技术,在无人驾驶领域实施视觉识别,具有较高的识别率。本文采用卷积神经网络Mask R-CNN作为视觉识别的模型,对道路行人、交通标志、道路车辆识别情况较好,对可行驶区域分割效果清晰。深度学习技术在无人驾驶领域有很高的应用价值。
基金项目
城市环境下无人驾驶中目标识别和可行驶区域分割
致谢
感谢吉林大学通信工程学院玄玉波老师的指导,同时感谢编辑、审稿专家的意见与指正!
参考文献
[1] 周开利. 神经网络模型及其MATLAB仿真程序设计[M]. 北京: 清华大学出版社, 2005.
[2] 汪榆程. 无人驾驶技术综述[J]. 科技传播, 2019, 11(6): 147-148.
[3] 周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229-1251.
[4] 陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 杭州: 浙江工商大学, 2014.
[5] 张沁怡. 基于深度卷积网络的人车检测及跟踪算法研究[D]. 北京: 北京邮电大学, 2019.
[6] VGG Image Annotator[OL]. http://www.robots.ox.ac.uk/~vgg/software/via/.
[7] Townsend J T. Theoretical analysis of an alphabetic confusion matrix[J]. Perception & Psychophysics, 1971, 9(1): 40-50.
[8] 赵琛, 王昱潭, 朱超伟. 基于几何特征的灵武长枣图像分割算法[J]. 计算机工程与应用, 2019, 55(15): 204-212.
[9] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative Adversarial Networks[J]. Advances in Neural Information Processing Systems, 2014, 3: 2672-2680.
[10] Li Z, Dekel T, Cole F, et al. Learning the Depths of Moving People by Watching Frozen People[C]// IEEE International Conference on Computer Vision and Pattern Recognition, California, USA, 2019.
作者簡介:
李嘉宁(1999—),男,山东泰安人,在读本科生。研究方向:图像处理。
E-mail: jnli2021@163.com
(收稿日期:2020-06-12)
Vision Recognition of Unmanned Driving Based on Deep Learning
LI Jia-ning, LIU Yang, HU Xin-yue, LIU Jian-tian, CHEN Zong-wen
(College of Communication Engineering, Jilin University, Changchun 130012, China)
Abstract: The development of big data technology and the improvement of parallel computing capability based on Graphical Processing Unit (GPU) jointly promote the application of deep learning algorithm in the field of visual recognition of unmanned driving. On the Ubuntu 16.04 operating system, the Python experimental environment is built, and the visual recognition experiment of unmanned driving based on convolutional neural network, i.e. Mask R-CNN is carried out. The software and hardware of training and testing are realized by using the GTX 1080Ti GPU and cuDNN video acceleration card. The confusion matrix and average accuracy are introduced to evaluate the performance of the convolution neural network model. The results show that the visual recognition effect is good and the reliability is preferable, which shows that the deep learning technology has high application value in such fields.
Key words: Deep Learning; Unmanned Driving; Convolutional Neural Network; Visual Recognition; Performance Evaluation
