基于三角函数迭代的视频数据特征提取
2020-09-02于万波范晴涛
于万波,范晴涛
基于三角函数迭代的视频数据特征提取
于万波,范晴涛
(大连大学信息工程学院,辽宁 大连 116622)
在计算机视觉研究中,基于视频数据进行图像对象识别逐渐增多。针对视频数据的特征提取,提出了一种基于三角函数迭代提取视频三维迭代轨迹特征的方法。该方法是考虑视频数据的时间空间维度,利用三角函数构造三维动力系统,整体一次性进行视频段数据特征的抽取,提取出一种近似混沌吸引子的三维特征点集,这种视频数据迭代特征实际上是迭代轨迹点集合。以VidTIMIT数据集进行人脸识别实验,发现增加初始迭代值的个数,减少迭代次数后,提取出的特征点集合具有更好的效果。当VidTIMIT的43组559个视频全部参与实验,识别率达到88.16%,与现有文献中记载的其他方法相比,具有识别率高、计算时间少的特点,初步证实了该三维视频迭代轨迹特征具有实用性,同时也值得进一步研究验证与分析。
动力系统;迭代;视频;人脸识别
计算机视觉相关研究在实际工作领域具有广泛的应用,同时有重要的理论研究价值。研究人员给出了图像的多种特征提取与处理方法,取得了大量的研究成果。文献[1-8]选自最近出版的不同期刊,具有一定的代表性。如,FRIED等[1]基于文本的视频编辑,给出了特写镜头的编辑方法;TRUJILLO等[2]研究连续的运动信号在语义理解中的作用,强调了视频在语义理解中的作用;XIE等[3]基于非线性扩展在线多实例学习的早期表达式检测,认为非线性在其研究中具有重要的意义;ZHAI等[4]提出了一种基于双稀疏先验的会议视频联合注视校正与人脸美化方法;LIU等[5]利用单幅图像以人为中心的轨迹分割,使用了细粒度方法,取得了较好的效果;LIU等[6]基于bag-of-neighbors的多视图拉普拉斯特征映射进行RGB-D人类情感识别,在人脸图像库中得到了实验验证;YU等[7]在图像分类时,使用了稀疏矩阵的投影学习方法,在实例中应用了稀疏逼近的图像分类方法;LIANG等[8]给出了一种面部和身体表情的网络表示方法,利用多变量连接模式获取分类的证据,进行了实验验证与理论分析。
另外,关于混沌吸引子、动力系统与迭代的研究包括:文献[9]研究了三角函数的混沌特性;文献[10]利用三角函数与人脸图像构造动力系统提取图像特征,进行人脸识别研究。该特征也称为迭代轨迹、图像迭代吸引子等,其初步表达能力得到确认。其特征获取方法简单,运算速度快,与人脑的视觉机制可能存在某种联系。文献[10]分别利用正弦函数和小波函数作为辅助函数构造非线性迭代系统,对相同的图像进行迭代得到不同的吸引子特征点集,但其实验发现三角函数更容易产生混沌吸引子特征点集,且质量较高,所以在后续的人脸识别实验中使用了正弦函数作为辅助函数。同时,对图像进行灰度调整以提高吸引子特征点集的质量,然后使用Euler方法进行迭代,得到图像的特征点矩阵进行人脸识别实验,在Yalelfaces数据集上其识别率达到了87.33%。文献[11]将双二次有理贝塞尔曲面函数与图像构造非线性动力系统进行迭代,对迭代得到的3组人脸图像特征点集进行Radon变换,考虑到噪声等因素的影响,进行拟合处理得到拟合曲线,对其中一幅图像与其他3组33幅图像计算相关系数,结果显示相似图像的相关系数较大。文献[12]使用离散余弦变换(discrete cosine transform,DCT)基函数作为辅助函数与人脸图像迭代得到近似混沌吸引子特征点集,并对二维的特征点集进行傅里叶变换,其中吸引子特征点集小的进行变换后识别率得到了提升。
本文在这些已有方法基础上,将二维图像识别拓展为三维视频识别,给出了一种利用三维动力系统提取视频数据特征的算法,该方法作为一种新的视频数据处理操作方法,有待于进一步分析。
1 相关工作
目前,文献发表的联系紧密的相关工作都是基于二维灰度图像进行的[10-12],其本质上均是利用式(1)进行迭代,即
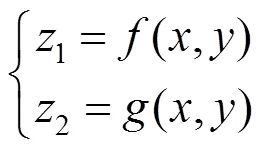
其中,(,)为辅助函数;(,)为一个灰度图像;2为图像在(,)位置处的灰度值。(串行)迭代方法为,给定一个初始值点(,),代入式(1),即可得到二维点(1,2),并记载下该点(1,2);然后将1,2的值分别赋值给,,再代入式(1),可以得到一个新的二维点(1,2),再记载这个新的二维点(1,2),如此重复,得到个二维点,作为这个灰度图像(,)的特征。实验与理论分析均证实:相近似的图像其迭代轨迹的相关系数较大,所以,迭代轨迹可以作为图像识别的特征。
还有一种(并行)迭代方法就是,同时给定多个初始值,例如,图像的所有像素点,均作为初始值点,只迭代1次或2次。实验与理论分析均证实[13]:系统的混沌特性越强,这2种方法(串行与并行)得到的轨迹越接近。文献[9]通过实验方法得到的结论是,三角函数构造动力系统,其混沌特性较强,参数的混沌区间较大,所以文献[10]与文献[12]均使用了三角函数作为辅助函数。
不论是串行方法,还是并行方法,该迭代方法获取的轨迹点序列(特征点集合),本质上是对图像的一种“截取”,特征点集合可以作为一种特殊的“截面”。这个特征“截面”与图像有关,也与辅助函数有关;当辅助函数一定时,图像的近似程度大,截面的近似程度就大。所以,原有文献利用特征点集合计算相关系数,进行人脸图像识别,取得了一定的效果。
图1是使用文献[10]的方法提取的图像轨迹点集,并可看出,同一个人的特征点集合近似程度较大,实际上通过数学计算可以证实这一点。
这种方法将图像与辅助函数交织在一起,然后提取图像特征。辅助函数本质上是一种载体,其与该运作方法是有效的,可进一步研究。文献[9-12]不只是研究图像识别,还设想从识别方法入手,改进数据的存储机制,探索新的表达方法。

图1 图像及其迭代特征点集
2 系统构造与算法设计
本文方法是将二维系统改造为新的三维系统,提取视频的特征。从已有的工作经验看,使用三角函数作为辅助函数有很多优势,并继续使用三角函数作为辅助函数。
2.1 利用三角函数与视频图像构造系统
(灰度)视频图像数据对应着三维数组或三元函数,所以在构造三维非线性动力系统时,采用了余弦函数作为辅助函数。如式(2),系统由2个余弦组合函数与一个视频函数构成。选择2个余弦函数线性组合作为辅助函数,其频率、导数等选择上具有可控的差异化,这样便于在迭代过程中得到视频图像(曲面)上不同位置的特征点。
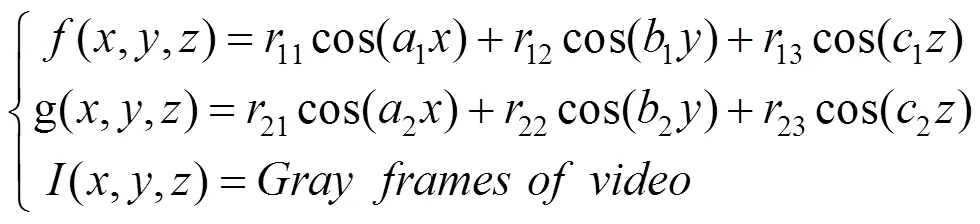
其中,,,Î,Î[1,],Î[1,],Î[1,];r与a,b,c为参数。
首先研究提取视频图像的迭代轨迹特征。目前研究结果表明:式(2)中的组合三角函数与(不同系数的),具有极强的“混沌化”功能,即该类函数与其他函数构成动力系统后混沌的概率极大[13]。例如,用这样的三角函数与其他(收敛)函数构造系统,随机生成系数,当与的系数平均值大于2时,混沌的概率可以达到99%。理论分析与实验结果显示,混沌特性强的函数作为辅助函数,更有利于迭代轨迹作为图像特征。所以本文使用该三角函数作为辅助函数。
式(2)中的函数与虽然形式上相同,但是因为参数不同,所以其周期不同,局部振幅不同,高低错落,差异很大。随机生成系数,其周期基本均达到1 000以上,非常适合于作为辅助函数。
在自变量值域的选择上,,与视频的分辨率与帧数(维度)大小一致,的选择上,要根据选取的视频帧数来确定,这是为了保证迭代过程中不会漏掉视频的某个区域。视频段中每幅图像大小为×,一共幅(帧)。为了实现迭代,并减少计算量,所以在迭代前,将整数点位置的三角函数值(也变成整数后),存储在三维数组中。即计算(,,)与(,,)得到的三维矩阵元素值要调整成为[1,],[1,]之间的整数,并进行系统迭代获取人脸视频的迭代特征点集合,具体步骤如下:
算法1.视频迭代轨迹特征提取
输入:帧图像(视频按照时间先后分割得到);
输出:存储迭代轨迹特征的三维矩阵IteratMFeature (其元素为0或者1)。
2.2 视频图像迭代轨迹提取
以图2视频为例(截取18帧),根据算法1的迭代方法提取该视频的迭代轨迹点集合。取60帧图像进行实验,每帧图像的大小是450×800。
(1)辅助函数的频率决定迭代序列周期的大小以及遍历的范围,根据算法1中第5和6步的迭代方法,只用一个迭代初始值(取Num=1,串行迭代)进行试验,从一个随机点出发,迭代600次后得到的轨迹点,如图3所示(其参数r;a,b,c分别取表1和2中的数值),结合图与数值可归纳得到:辅助函数频率较大时轨迹点较多,反之较少。

图2 一段视频节选

图3 迭代600次得到迭代点图((a),(b)的参数rij 取表1中的数值,参数ai,bi,ci分别取表2中的数值)

表1 参数rij的数值
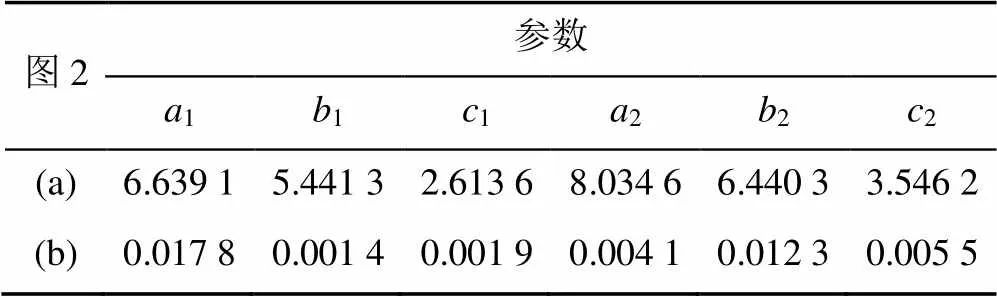
表2 参数ai,bi.ci的数值
(2) 将迭代初始值增多(并行迭代),迭代次数减少;比如=1∶20∶450,=1∶40∶800,=1∶3∶60,共计8 800个迭代初始值,迭代次数分别采用1,2,30进行迭代(算法1中取1,2,30),得到的轨迹如图4所示。
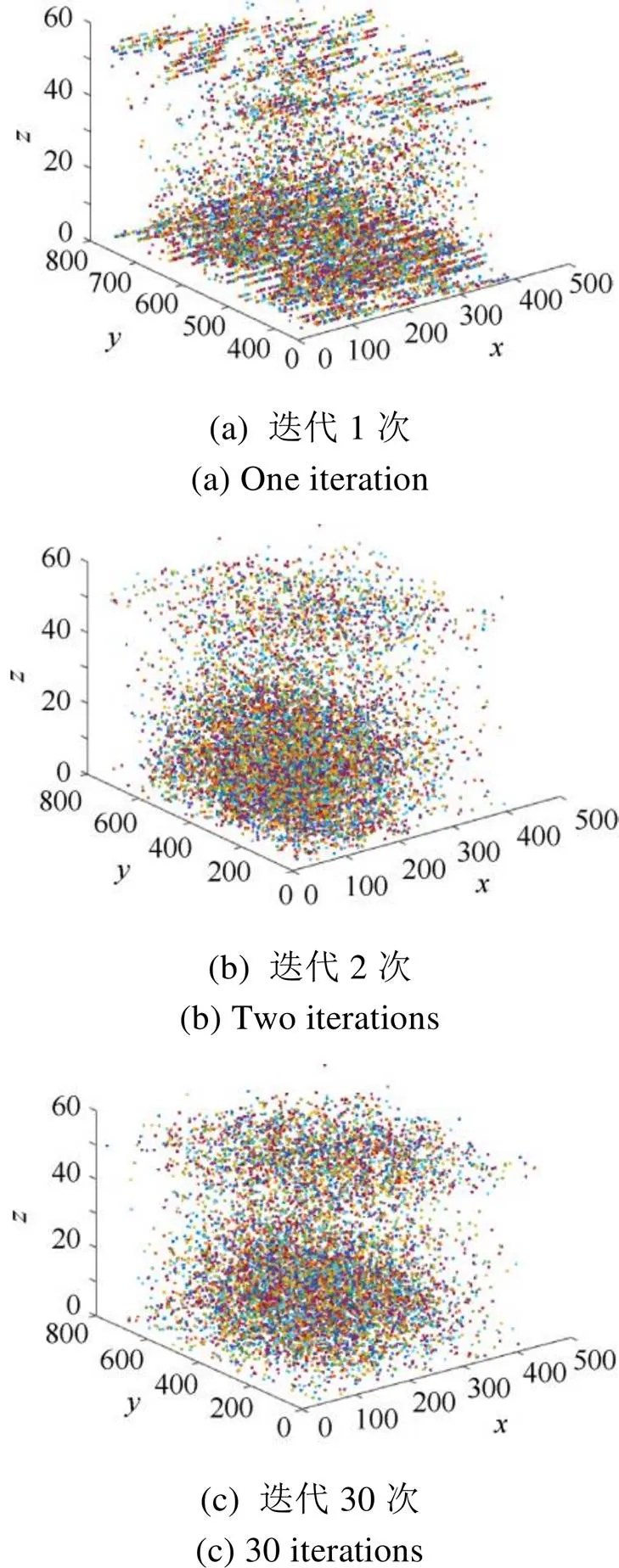
图4 不同迭代次数的迭代轨迹点图
根据图4可以看出,迭代初始值相同时,随着迭代次数增加,得到的轨迹点数减少,但是逐渐稳定,这是动力系统的迭代轨迹特性。如果迭代次数足够多,将会得到最终的系统稳定状态即吸引子。每个吸引子都代表着这段视频的一种本质的特征,当辅助函数频率比较小时,曲面振荡的比较小。当训练的样本数少时,对于人脸识别有一定的优势。
2.3 人脸视频迭代轨迹特征提取
在很多场合,视频可以看作是由图像组成的具时序关系的特殊序列,因此基于视频的人脸特征提取,实际上就是从多帧图像中提取特征。该实验将采用VidTIMIT数据集,数据集有43个人,每个人有13段视频,共计559段视频;在每个人的13段视频中,有3段视频为上下左右大幅度摇头,其余10段均为对话视频。人脸识别的本质是提取面部特征,然后将其与其他面部图像特征比较。在识别之前,人脸通常会被检测到并被切割。鉴于此,需对该数据集的556个视频,超过十万帧的图像进行人脸检测,得到每一帧的人脸图像并将其进行保存;然后在预处理后的人脸视频上应用算法1提取人脸视频迭代特征,如图5所示。

图5 人脸视频迭代特征提取((a)原视频分离为每一帧图像;(b)视频的每一帧图像仅有人脸;(c)经过算法1得到的人脸视频迭代轨迹特征,其参数为a1=0.00756; b1=0.00036; c1=0.00600; a2=0.00062; b2=0.00674; c2=0.00732; r11,r12, r13均取值0.01; r21,r22,r23均取值0.01753)
3 人脸视频识别
3.1 识别算法设计
使用算法1提取人脸视频迭代特征,不同的人提出的特征具有差异性(图6),利用其差异性就可进行人脸识别。VidTIMIT数据集经常被用于人脸分割、识别等[14-15],其含音频数据和视频数据,本实验仅使用其中的视频数据,再进行预处理后,对人脸视频随机抽取54帧进行特征提取,并将其储存在矩阵中,储存过程参见算法1;之后,利用图6展示的迭代特征差异性,并通过算法2进行人脸视频识别。

图6 人脸视频迭代特征对比((a)人脸视频每帧图像;(b)随机抽取54帧得到的人脸视频迭代特征;以上迭代特征参数取a1=0.00756; b1=0.00036; c1=0.006; a2=0.00062; b2=0.00674; c2=0.00732; r1i=0.01, r2i=0.01753, i=1,2,3,可以看出同一个人的视频迭代特征是相似的)
算法2.人脸视频识别
输入:一共组视频,以及待识别的视频Vid;
输出:识别结果。
在实验中提取的迭代轨迹特征是稀疏矩阵,在使用Matlab中的corrcoef 函数计算相关系数。计算相关系数耗费的时间占据了整个识别过程的大部分时间,因此为了降低时间消耗,使用Matlab中的imresize3函数将视频数据迭代轨迹特征调整大小为64×64×64,采用最近邻插值法;实验结果显示,识别率并未降低,这可能因为特征矩阵是稀疏矩阵的原因。
3.2 实验分析
实验环境是在Windows 10操作系统下,处理器为Inter(R) Core(TM) i7-7700 CPU @360 GHz,RAM 8 G,使用的仿真软件为MATLAB;实验首先是在10、20组样本的基础上进行,分别选取每个组视频中的1~5个视频进行训练,实验结果见表3,结果显示总体识别率均很好,其中训练视频数=2时识别率最高,因此在实验中选取=2得到特征IteratMFeature (:,:,:)进行实验。

表3 不同训练视频数q下的识别率(%)
采用每组取2个视频作为训练集提取对比特征的实验结果见表4,实验样本为10组,20组,30组,43组,识别率分别为94.55%,93.64%,91.82%和88.16%;实验结果表明,在训练样本比例不变的情况下,随着实验样本增大,识别率未出现大的下降;说明本文给出的视频迭代轨迹特征的鲁棒性强。与其他特征相比,人脸视频的迭代轨迹特征提取没有复杂数学计算过程,具有采集简单、快速的特点,实验证明,人脸视频迭代轨迹特征在人脸视频的识别上是有效的。
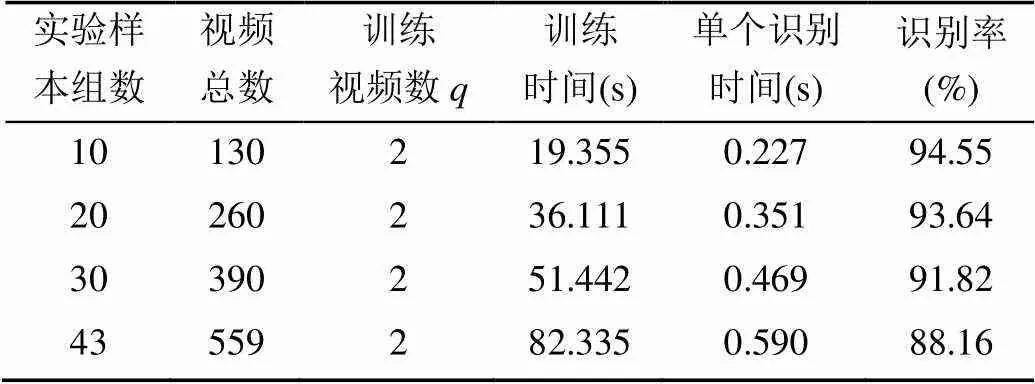
表4 VidIMIT数据集上的实验结果
在文献[15]中,选取VidTIMIT数据集中30个人的视频数据作为实验样本,选取10%~50%,以步长10%选择样本作为训练样本,分别使用AlexNet,GoogLeNet与ResNet-18的3个深度学习模型在30人的样本上进行了人脸识别实验;根据文献[15]的实验方法,将同样选择30组样本,取300个视频,按照相同的训练样本比例再次进行试验;结合文献[15]中的实验结果,给出图7的识别率对比图。由图7可以看出,在训练样本比例为10%和20%时,本文算法的识别率是高于其他3个模型的,在30%,40%,50%时,识别率高于AlexNet,GoogLeNet模型,略低于ResNet-18模型,并且训练样本在20%的情况下,识别率高于ResNet-18模型在30%的训练样本,略低于ResNet-18模型在40%和50%训练样本的识别率,证明了本文算法不需要很多的训练集就可以得到有效的视频迭代轨迹特征,这相对于深度学习模型是一个优势。

图7 本文算法与AlexNet,GoogLeNet,ResNet-18识别率对比
视频的三维迭代轨迹特征作为一种新的视频数据特征,类似于吸引子。吸引子是动力系统稳定后的一种稳态,而迭代轨迹特征并不是稳态,在前人的研究中很多都是构造动力系统,得到吸引子,但是在实际应用中且未必需要得到系统最后的稳态。在人脸识别方面,如果将吸引子作为图像的识别特征,无疑需引入大量的计算,并耗费大量的时间,通过实验分析结果可知,迭代次数2次和30次的迭代轨迹差别并不大,因此本次实验采用的是迭代2次的方法,实验结果显示,视频的迭代轨迹就可以达到识别效果,因此不需要大量迭代去得到吸引子特征,可以节约大量的时间。
4 结论与展望
本文考虑视频的时间维度,将视频作为三维函数,与三角函数构造动力系统,提取人脸视频迭代轨迹特征,作为一种新的视频特征进行人脸识别研究。该特征提取相较于其他的特征提取没有复杂的数学计算,也无需深度学习的多层网络结构,具有特征提取方法简单、计算时间较少的优点,该方法已经超过目前一些较好的人脸识别方法[15]。本实验证明了视频迭代轨迹特征的实用性,对比分析其他深度学习研究成果,该算法在训练样本比例小的情况下可以得到与其相比较好的识别率。下一步工作是在更多的视频集上进行实验,验证并改进该方法,同时进行深入的理论分析。
[1] FRIED O, TEWARI A, ZOLLHÖFER M, et al. Text-based editing of talking-head video[J]. ACM Transactions on Graphics, 2019, 38(4): 1-14.
[2] TRUJILLO J P, SIMANOVA I, BEKKERING H, et al. The communicative advantage: how kinematic signaling supports semantic comprehension[J]. Psychological Research, 2019, 5: 1-15.
[3] XIE L P, TAO D C, WEI H K. Early expression detection via online multi-instance learning with nonlinear extension[J]. IEEE Transactions on Neural Networks and Learning Systems,2018, 30(5): 1486-1496.
[4] ZHAI D M, LIU X M, JI X Y, et al. Joint gaze correction and face beautification for conference video using dual sparsity prior[J]. IEEE Transactions on Industrial Electronics, 2019, 66(12): 9601-9611.
[5] LIU S, REN G H, SUN Y, et al. Fine-grained human-centric tracklet segmentation with single frame supervision[J/OL]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. [2020-05-19]. https://doi.org/10.1109/TPAMI.2019.2911936.
[6] LIU S L, GUO S, WANG W, et al. Multi-view laplacian eigenmaps based on bag-of-neighbors for RGB-D human emotion recognition[J]. Information Sciences, 2020, 509: 243-256.
[7] YU Y F, REN C X, JIANG M, et al. Sparse approximation to discriminant projection learning and application to image classification[J/OL]. Pattern Recognition, 2019, 96: 106963. [2020-05-19]. https:// doi.org/10.1016/j.patcog.2019.106963.
[8] LIANG Y, LIU B L, JI J Z, et al. Network representations of facial and bodily expressions: evidence from multivariate connectivity pattern classification[J/OL]. Frontiers in Neuroscience, 2019, 13: 1111. [2020-05-19]. https://doi.org/10.3389/fnins. 2019.01111.
[9] 于万波. 截面的几何形状决定三维函数的混沌特性[J]. 物理学报, 2014, 63(12): 26-34. YU W B. Geometric shape of cross section determines chaotic properties of three-dimensional functions [J]. Acta Physica Sinice, 2014, 63(12): 26-34 (in Chinese).
[10] 于万波, 王大庆. 曲面迭代的混沌特性及其在人脸识别中的应用[J]. 计算机辅助设计与图形学学报, 2015, 27(12): 2264-2271. YU W B, WANG D Q. Chaotic characteristics of surface iteration and its application in face recognition[J]. Journal of Computer-Aided Design & Computer Graphics, 2015, 27(12): 2264-2271 (in Chinese).
[11] YU W B. Application of chaos in image processing and recognition[C]//2017 International Conference on Computer Systems, Electronics and Control (ICCSEC). New York: IEEE Press, 2017: 1108-1113.
[12] 于万波, 王香香, 王大庆. 基于离散余弦变换基函数迭代的人脸图像识别[J]. 图学学报, 2020, 41(1): 88-92. YU W B, WANG X X, WANG D Q. Face image recognition based on iteration of discrete cosine transform basis functions[J]. Journal of Graphics, 2020, 41(1): 88-92 (in Chinese).
[13] 于万波. 混沌的计算分析与探索[M]. 北京: 清华大学出版社, 2016: 162-186. YU W B. Computational analysis and Exploration of Chaos[M]. Beijing: Tsinghua University Press, 2016: 162-186 (in Chinese).
[14] LE T H N, SAVVIDES M. A novel shape constrained feature-based active contour model for lips/mouth segmentation in the wild[J]. Pattern Recognition, 2016, 54: 23-33.
[15] BANERJEE S, CHAKRABORTY S. Deepsub: a novel subset selection framework for training deep learning architectures[C]//2019 IEEE International Conference on Image Processing (ICIP). New York: IEEE Press, 2019: 1615-1619.
Feature extraction of video data based on trigonometric function iteration
YU Wan-bo, FAN Qing-tao
(College of Information, Dalian University, Dalian Liaoning 116622, China)
In the research of computer vision, the recognition of image objects based on video data is on an increasing trend. Focusing on the feature extraction of video data, a method based on trigonometric function iteration was proposed to extract 3D iterative trajectory features of the video. Considering the time and space dimensions of video data, this paper constructed a three-dimensional dynamic system by using a trigonometric function, obtained the features of video segment data as a whole in one extraction, and extracted a set of three-dimensional feature points similar to chaotic attractors. This iterative feature of video data is an iterative set of track points. Face recognition experiments using VidTIMIT datasets of face videos show that increasing the number of initial iterations and reducing the number of iterations could lead to a better effect of the extracted feature points set. After 43 groups of 559 videos of VidTIMIT were all experimented with, the recognition rate could reach 88.16%. Compared with other methods recorded in the existing literature, the method proposed in this paper is characterized by high recognition rate and short computing time. It is proved that this 3D video iterative trajectory feature is of great practical significance and requires further research, analysis and verification.
dynamic system; iteration; video; face recognition
TP 391
10.11996/JG.j.2095-302X.2020040512
A
2095-302X(2020)04-0512-08
2020-03-29;
2020-05-19
19 May,2020
29 March,2020;
于万波(1966-),男,吉林长春人,副教授,博士,硕士生导师。主要研究方向为图形图像处理、人工智能。E-mail:yu_wb@126.com
YU Wan-bo (1966-), male,associate professor, Ph.D. His main research interests cover graphic image processing, artificial intelligence. E-mail:yu_wb@126.com
