拖拉机作业载荷数据平台设计与旋耕作业质量预测
2020-08-27温昌凯李若晨宋正河韩建刚刘江辉
温昌凯 谢 斌 李若晨 宋正河 韩建刚 刘江辉
(1.中国农业大学工学院, 北京 100083; 2.中国农业大学现代农业装备优化设计北京市重点实验室, 北京 100083;3.洛阳西苑车辆与动力检验所有限公司, 洛阳 471000)
0 引言
农业与大数据良好结合是未来农业发展的必然趋势。农业大数据涉及地区范围广、地形差别大、作物品种多、作业工况多,并且受限于各地区农业结构复杂、农耕环境以及气候多样等因素,因此,农业领域大数据具有高实时、多维度、离散化、难综合分析等特点[1-3]。
随着全球农业现代化、智能化、信息化的不断推进,畜牧业、渔业、农产品加工、气象等农业相关领域数据呈指数规律不断积累[4-8]。但在农业机械领域,由于农业机械载荷复杂、测试成本较高以及数据平台架构不易统一等问题,数据系统性积累与平台规范化构建难以实现,农业数据测试以及积累研究相对滞后,基于大数据的农业机械数据融合与分析预测相对缺乏。
本文研究拖拉机作业载荷数据平台系统构建和基于大数据的拖拉机田间旋耕作业质量评价与预测。探索拖拉机多传感器车载测试终端分布格局、作业参数与结构体系;研究基于全国范围田间作业试验的拖拉机作业载荷数据平台系统,并构建相应的数据库结构;基于农机农艺要求,采用遗传算法与BP神经网络相融合的方法对数据平台基础作业载荷进行分类融合处理,预测评价拖拉机田间旋耕作业质量,以验证平台系统的可行性。
1 样机测试终端结构体系
1.1 测试终端布局
此次全国范围的测试样机布置以涵盖水稻、小麦、玉米等优势作物的全国农业战略格局为出发点,主要考虑优势主产区的作物差异性、地理环境差异性以及作业载荷差异性,在一定程度上兼顾其他具有代表性的地块地域[9-11]。
因此,综合考虑测试终端地区分配合理,兼顾各地区作物、地理、气候等多个因素,测试样机车载终端布置选择主要集中在东北平原、黄淮海平原、长江流域、汾渭平原以及新疆地区,总计6辆测试样机。
1.2 测试终端功能架构
测试样机车载终端硬件以基于 ARM335x 微处理器的 ARM 硬件开发平台作为主控制器,使用分布式布置的传感器,对拖拉机多地区、多工况、多载荷进行数据采集。田间作业载荷采集测试终端采用OK3355xD工业级开发板和FET335xD工业级核心板,配置LCD触摸液晶屏、WiFi模块、SD卡、USB键盘鼠标接口、多接口模块,测试终端硬件结构设计如图1所示。
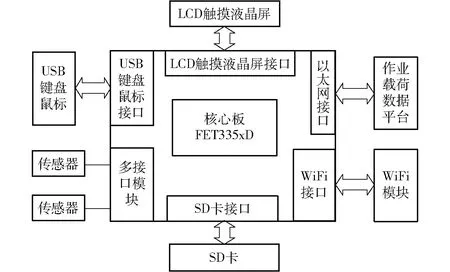
图1 测试终端硬件结构框图Fig.1 Hardware structure design of test terminal
测试样机车载终端的测试工况包括拖拉机犁耕作业、旋耕作业、深松作业以及联合耕整作业,待测关键零部件包括发动机、实时地理位置、电液悬挂下拉杆、动力输出轴、前万向传动轴、前转向驱动桥、变速箱、后驱动桥、驾驶室等,测试参数以及配套传感器如表1所示,传感器布置位置如图2所示。
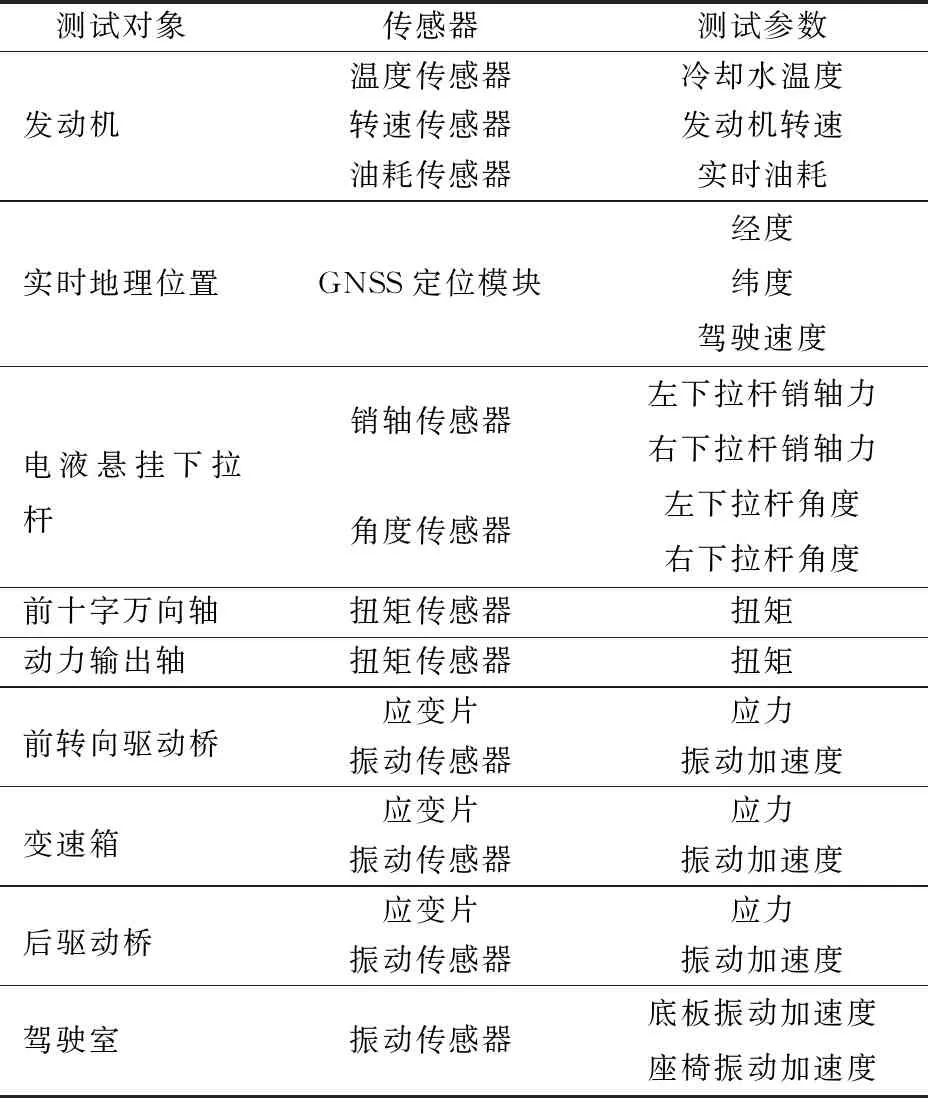
表1 测试终端测试参数与传感器Tab.1 Testing terminal test parameters and sensors

图2 测试终端传感器布置图Fig.2 Sensor layout of test terminal
各测试样机正常田间作业,测试终端开启后可自动采集作业载荷,按照拖拉机作业载荷传输协议实时或分段工作数据打包等多种形式发送传输至作业载荷数据库,实现拖拉机多样工况、恶劣环境条件下的田间作业载荷数据的自动采集与传输。
2 拖拉机作业载荷数据平台系统分析
2.1 需求分析
参考国内外现有机械行业数据平台,结合农业机械田间作业多工况、变环境、高载荷的特点,设计基于B/S网络结构模式的拖拉机作业载荷数据库系统。本系统包括系统管理机制、载荷数据库基础平台、载荷数据实时采集系统以及拖拉机田间旋耕工况作业质量评价与预测模块等部分,在此基础上,形成的系统总体方案如图3所示。
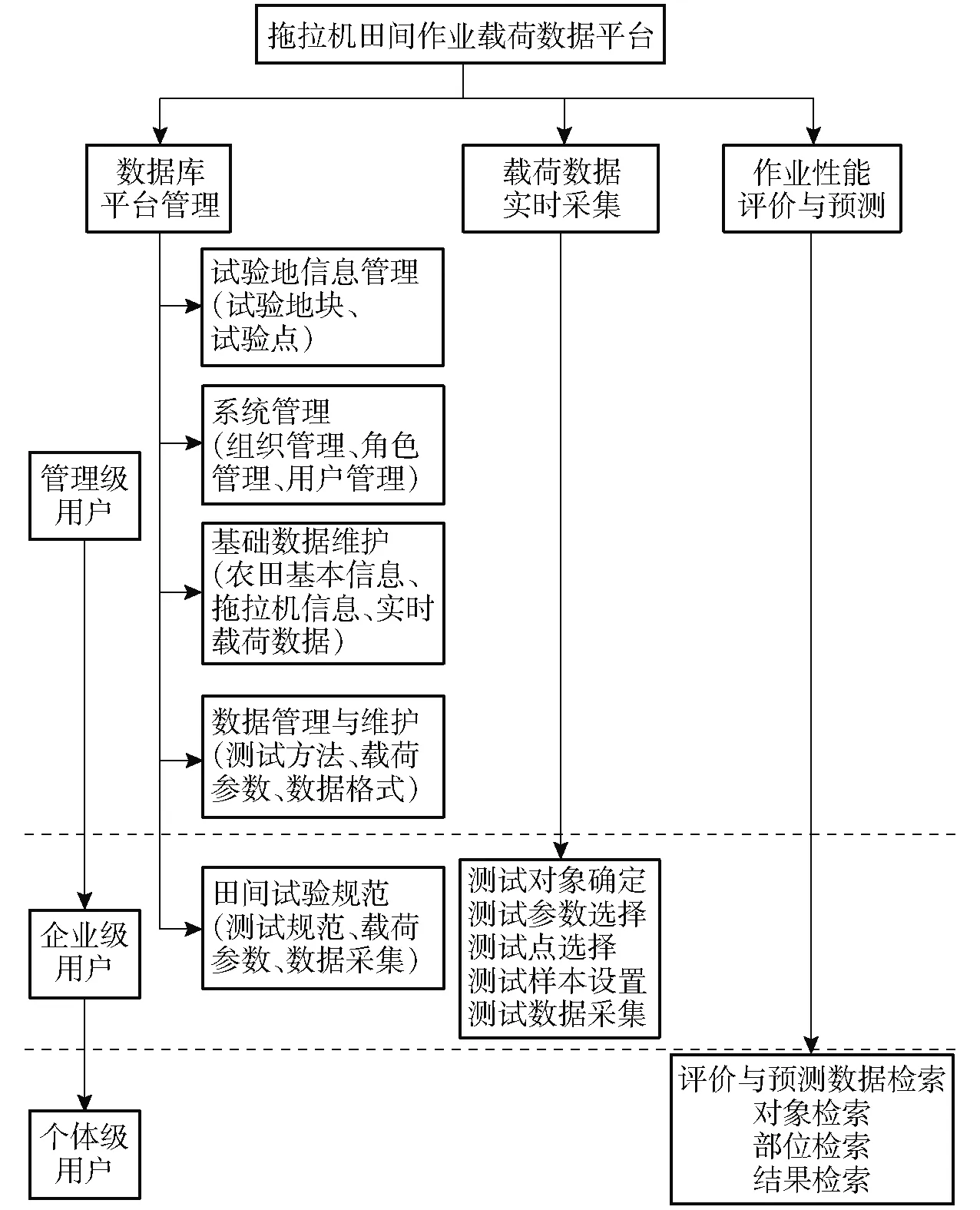
图3 作业载荷数据平台总体结构与方案Fig.3 Overall structure and scheme of work load data platform
2.2 管理机制分析
系统管理机制包括用户权限管理、试验地信息管理、拖拉机信息管理、测试终端信息管理、作业信息管理以及平台信息管理等功能。用户权限管理包括对用户的基本信息、登录密码、访问权限级别进行管理。试验地信息管理包括对作业试验田的所属地区、基本环境的管理。拖拉机信息管理包括对拖拉机基本参数、配套作业机具的管理。测试终端信息管理包括对采集设备以及工作状态的管理。系统管理机制的有效运行可保证拖拉机作业载荷数据平台的正常运行。
2.3 网络结构分析
该数据平台作业载荷实时采集系统主要由全国范围内各主产区负责单位统筹管理,由主产区各试验测试站分别负责执行试验田以及测试样机的管理以及作业运行,考虑到我国农业主产区地域差别大、农业机械作业载荷复杂,有必要全面监控从试验地到测试终端的内在联系,以获得全国范围内拖拉机田间作业载荷的全面基础数据[12-15]。
作业载荷实时采集系统由各农业主产区管理单位、分布的各级试验站(省、市、县/区)和测试环节的基层测试站点构成。具体分层结构如图4所示。
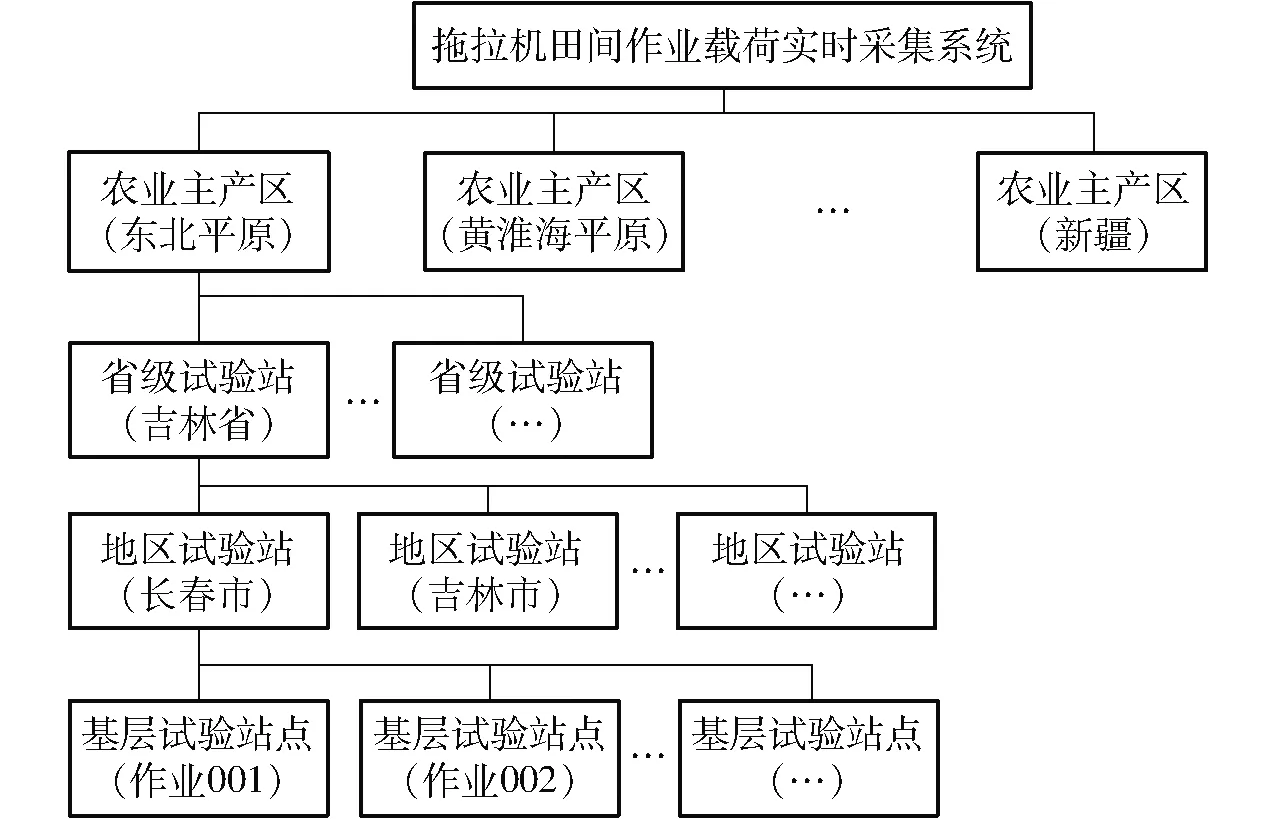
图4 作业载荷实时采集系统分层结构Fig.4 Hierarchical structure of real-time load acquisition system
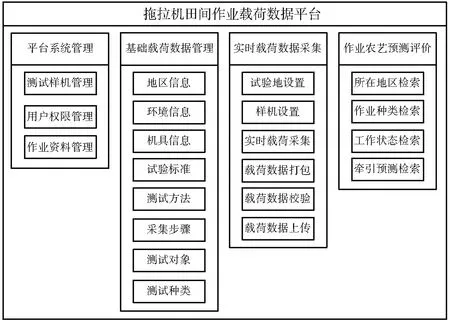
图5 作业载荷数据库系统功能结构Fig.5 Functional structure of work load database system
2.4 功能结构
基于用户群体需求导向,进一步完善拖拉机作业载荷数据库系统结构,明确数据库系统各模块部分的功能以及结构,如图5所示。平台系统管理包括测试样机管理、用户权限管理以及作业资料管理。基础载荷数据管理包括地区信息、环境信息、机具信息、试验标准、测试方法、采集步骤、测试对象以及测试种类。实时载荷数据采集包括试验地设置、样机设置、实时载荷采集、载荷数据打包、载荷数据校验以及载荷数据上传。作业农艺预测评价包括所在地区检索、作业种类检索、工作状态检索以及牵引预测检索。
3 拖拉机作业载荷数据平台设计与构建
3.1 概念结构设计
基于数据平台多样性、包容性、全面性以及系统性特点需求,结合E-R概念设计的实体、属性和联系三要素,构建全国范围拖拉机作业载荷数据平台的概念模型。该数据库包括4个实体、若干属性以及各项必要的联系。各实体环环相扣,构建了数据平台的基本框架,各实体属性以及联系建立数据平台潜在逻辑,进一步丰富数据平台功能、提高可用性。E-R结构框图如图6所示。
3.2 逻辑结构设计
根据作业载荷数据平台系统需求,剖析拖拉机田间作业载荷测试、采集、传输以及入网的全过程。基于作业载荷数据库E-R概念结构设计的数据字典,进行数据库逻辑架构设计,数据库系统主要由终端表、农机表、传感器表、作业表、数据表等11个数据组成,其中主数据表与基础数据表相关联,以测试终端为主键,实时采集、传输、存储测试基础数据以及结果。形成的数据表关系如图7所示。

图6 作业载荷数据库E-R概念结构框图Fig.6 Design of E-R conceptual structure of work load database
3.3 系统开发与构建
基于作业载荷数据库概念结构与逻辑结构,结合使用人员多样性、操作级别多层次、终端节点分布广以及作业环境复杂性等系统特点,进行数据平台基本框架设计以及服务器软件系统开发。
作业载荷数据库系统基于Web2.0架构,采用微服务技术结构体系开发,前端部分采用HTML5/CSS3/JavaScript等技术开发,数据库采用MY SQL 5.7.27.0版本,并且采用RESTful API架构作为方便前、后端通信的统一机制。
数据采集服务基于C#.NET技术开发,测试样机车载终端与平台服务器之间基于TCP传输方式,采用私有二进制协议即拖拉机机组作业载荷传输协议进行数据传输,关键数据采用RSA加密验证机制保护,可确保高吞吐量和高安全性。
关联数据库结构设计采用基础数据与不易变化数据结构化处理、易变化数据非结构化处理相结合的方式,可确保数据库的稳定性、灵活性以及兼容性;针对系统传感器多、数据量大以及采样频率范围广的特点采用分库分表方式处理数据,即按照需求业务不同将数据分库储存,按照时间维度不同将低频、高频数据分表储存。此外,通过数据库约束机制保证数据完整性,通过数据校验机制确保逻辑正确性,通过数据库备份确保数据高可用性。
基于以上内容,完成拖拉机作业载荷数据平台的设计与构建,田间试验以及试验数据等部分界面效果如图8所示。
4 基于遗传算法与神经网络的旋耕作业质量评价与预测
基于拖拉机作业载荷数据平台以及农业大数据融合技术,结合农机农艺要求,筛选部分实测数据研究拖拉机田间旋耕工况作业质量评价与预测的智能算法,并验证其可行性。
4.1 基于遗传算法的BP神经网络算法
针对BP神经网络预测模型连接权重随机赋值导致收敛速度过慢和结构模式不确定导致训练过拟合及学习能力不足的问题,本文提出基于遗传算法的BP神经网络算法,利用遗传算法全局搜索最优特性对 BP 神经网络进行优化,降低神经网络陷入局部最优解而无法稳定准确预测的风险,提升网络的收敛速度和系统预测精度,进一步提高BP神经网络的可行性[16-19]。遗传算法优化BP 神经网络方法主要由BP 神经网络结构确定、遗传算法优化BP神经网络权阈值权重矩阵、 BP 神经网络预测3部分组成[20-22]。其核心是采用遗传算法将神经网络函数计算的损失误差作为个体适应度,对权值、阈值进行选择、交叉和变异操作,使个体适应度尽可能地小,从而得到最佳的神经网络权值和阈值权重矩阵。基于遗传算法的BP神经网络算法流程如图9所示。
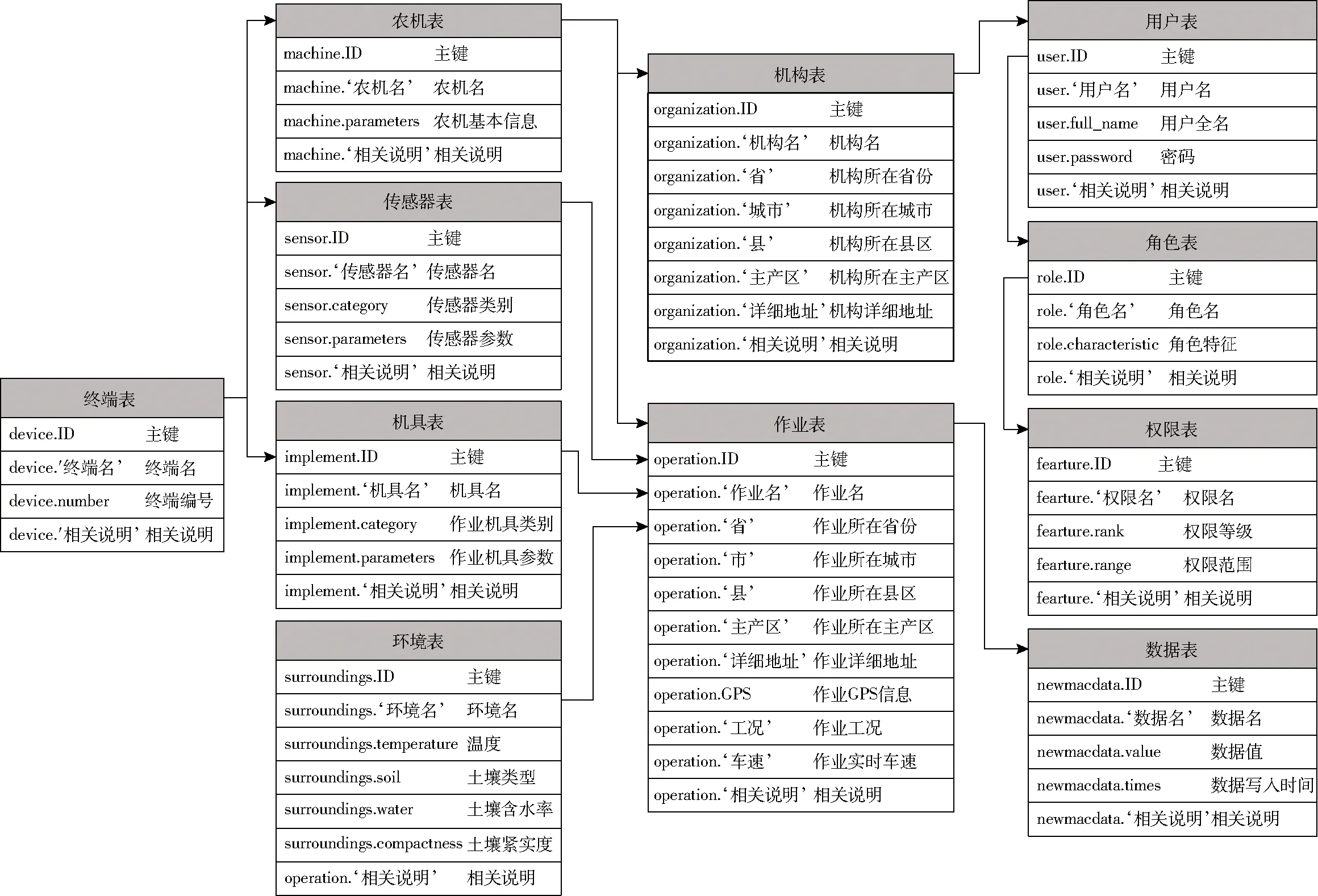
图7 作业载荷数据库主要数据表关系Fig.7 Maindata table relations of job load database
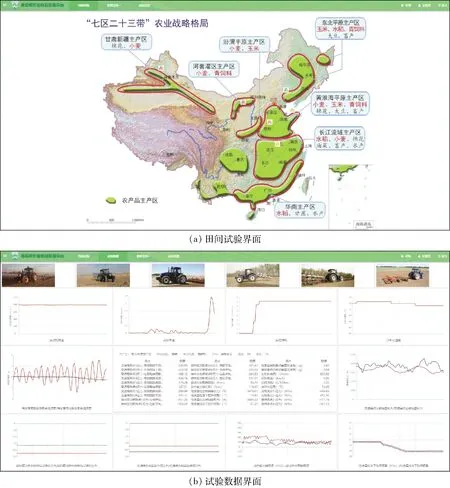
图8 拖拉机作业载荷数据平台界面Fig.8 Interfaces of tractor working load data platform
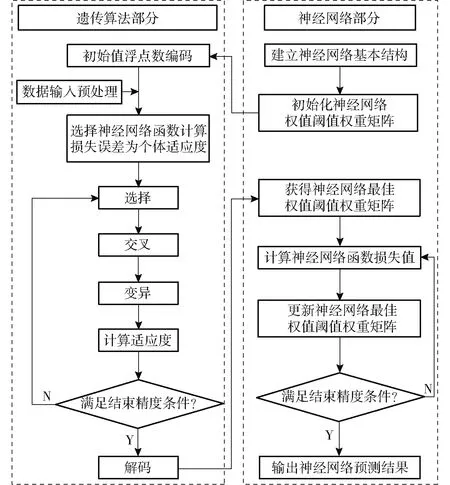
图9 基于遗传算法的BP神经网络算法流程图Fig.9 Flow chart of BP neural network algorithm based on genetic algorithm
4.2 基于遗传算法的BP神经网络预测模型
4.2.1BP神经网络模型
BP神经网络即误差反向传播神经网络,一般由输入层、隐含层和输出层构成,可以有效地解决各个输入指标之间的非线性关系,步骤如下:
(1)网络拓扑结构选择
拖拉机工作在土壤-机器-植物复杂系统,考虑其田间旋耕工况作业质量受到多因素耦合作用以及3层神经网络可以完成任意n维到m维的映射,本文选择3层BP神经网络结构。
(2)输入、输出层参数确定
为了建立简洁有效的BP神经网络模型,基于农机农艺要求,本文所采用的BP神经网络输入层参数为拖拉机电液悬挂左、右下拉杆销轴力,电液悬挂左、右下拉杆角度,动力输出轴扭矩以及行驶速度,输出层参数为优、中、差3种拖拉机田间旋耕工况作业质量水平。
本文神经网络模型的输入层参数存在量纲难以统一的问题,为减少拖拉机田间旋耕工况作业质量评价与预测的误判概率,对输入输出层参数进行归一化处理,即
(1)
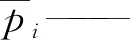
pi——第i个原始特征值数据
pmax——原始特征值数据的最大值
pmin——原始特征值数据的最小值
(3)隐含层节点数确定
隐含层节点数作为BP神经网络的重要组成部分,直接影响网络的非线性映射能力。隐含层节点数计算公式为
(2)
式中n——输入层节点数
m——输出层节点数
计算可得该神经网络隐含层节点数范围为[3,13],对比多次试验以及神经网络训练误差,当隐含层节点数为10时,神经网络预测性能最佳。
构建具有1个隐含层的3层BP神经网络结构,隐含层节点数为10,具体BP神经网络预测模型结构如图10所示。
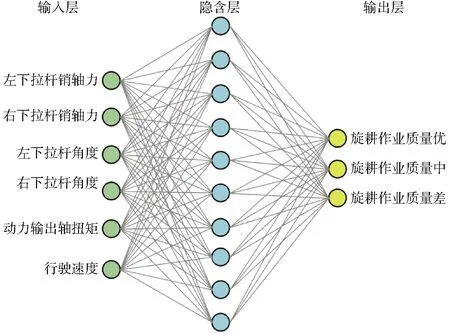
图10 拖拉机旋耕作业性能预测的BP神经网络模型Fig.10 BP neural network model for performance prediction of tractor rotary tillage
(4)网络函数选择
考虑到预测模型非线性特征明显以及预测收敛快、误差小等要求,BP神经网络的隐含层传递函数选择sigmoid函数,训练函数选择trainlm函数,学习函数选择learngdm函数,网络性能函数选择mse函数,仿真函数选择sim函数。
(5)权值阈值更新确定
权值阈值更新确定是BP神经网络采用的误差反向传播算法的核心部分,其主要工作是依次计算隐含层输出和输出层输出,进一步求得神经网络输出值与实际作业真实值之间的预测误差,最后根据公式实时更新神经网络隐含层与输出层的权值阈值。神经网络权值阈值更新确定过程包括隐含层输出、输出层输出、误差计算以及权阈值更新4个步骤,计算公式为
(3)
式中f(x)——隐含层激励传递函数
x——输入变量
Hj——隐含层输出变量
wij——隐含层权值
aj——隐含层阈值
Ok——输出层输出变量,即预测值
bk——输出层阈值
i——输入层节点数
j——隐含层节点数
k——输出层节点数
Yk——实际值
ek——神经网络预测误差
η——神经网络学习速率
wjk——输出层权值
4.2.2预测网络模型的遗传算法优化
基于遗传算法的BP神经网络模思想是:通过遗传算法优化BP神经网络的初始权值阈值,对初始值进行编码和选择、交叉和变异等操作,获取最优参数并对神经网络进行赋值与训练,使优化后的神经网络能提高网络收敛速度以及预测准确性。基于遗传算法的BP神经网络模型实现过程主要包括种群初始化,适应度函数选择以及选择、交叉、变异操作[23-25]。
种群初始化主要采用浮点数编码方式,编码长度为神经网络所有权值个数(nm+lm)和阈值个数(l+m)之和,计算可得此种群初始化编码长度为61。
适应度函数选择与计算是遗传算法的核心部分,将BP神经网络的预测输出值与真实作业值之间的误差平方和作为个体适应度,因此适应度函数为
(4)
式中n0——训练样本总数
yi——作业真实值
f(xi)——神经网络预测值
选择操作采用最优个体最优保存和其余个体轮盘赌法选择的并存策略。交叉操作采用实数交叉法,变异操作采用实值变异法。其中因为涉及神经网络收敛速度,基于适应度需求选取交叉概率与变异概率遗传算子,计算公式为
(5)
(6)
式中pc——遗传算法交叉概率
pch——遗传算法交叉概率上限
pcl——遗传算法交叉概率下限
pm——遗传算法变异概率
pmh——遗传算法变异概率上限
pml——遗传算法变异概率下限
f′——交叉染色体较大适应度
favg——染色体平均适应度
fbest——染色体最佳适应度
因此,本文构建了基于遗传算法的BP神经网络预测模型,计算并设置遗传算法参数:进化代数为200,种群规模为20,交叉概率为0.5,变异概率为0.1。并选取均方根误差(RMSE)作为模型评价与预测性能的评价标准。
4.3 作业质量评价与预测分析
4.3.1田间作业试验数据
作业载荷数据平台可实时获取多拖拉机、多工况、多地区的作业数据,但若考虑整个时间段、整个覆盖范围,数据总量会过大、不利于建模与分析。因此,基于2019年3月东北某区域某拖拉机某时间段内数据平台的田间作业数据,平均随机选取旋耕工况作业质量优、中、差3种情况,每种情况3 000组数据,总计9 000组数据作为训练集,其他任意一段时间总计4 000组旋耕工况作业数据作为测试集。根据训练集与测试集数据,对拖拉机旋耕工况作业质量性能进行评价与预测。
4.3.2评价预测结果分析
应用遗传算法优化BP神经网络初始权值阈值,其中适应度函数变化曲线如图11所示。由图11可知,当迭代次数不足20次时,即迭代前期平均适应度和最佳适应度均呈快速下降趋势,随着迭代次数的不断增加至60次时,迭代后期整体趋于平缓,其中虽然略有波动,但整体起伏不大。表明遗传算法迭代次数选择合理,遗传算法可以快速准确有效地优化神经网络权值阈值。
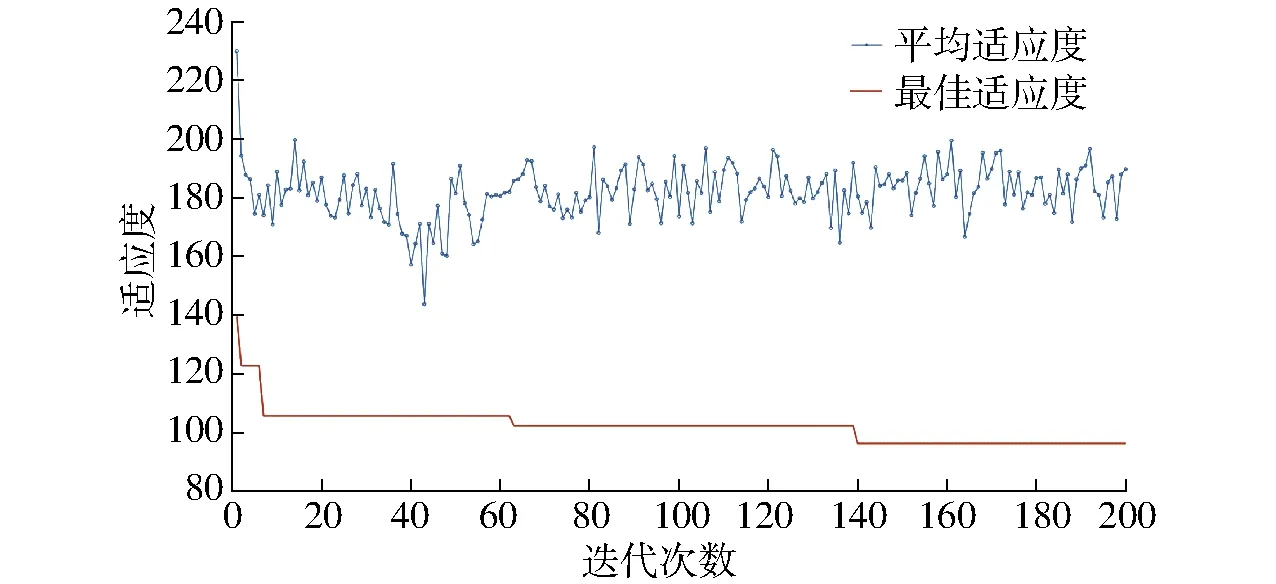
图11 遗传算法适应度曲线Fig.11 Fitness curves of genetic algorithm
均方根误差(RMSE)是衡量神经网络性能的最常用参考标准,RMSE越小,表示此神经网络预测性能越好。由图12可知,随着样本训练次数的不断增加,均方根误差由初始值0.6不断减少,在样本训练次数达到10次时,均方根误差已减至0.01,表明基于遗传算法的BP神经网络预测模型能够准确快速拟合输入数据,预测结果接近真实情况。
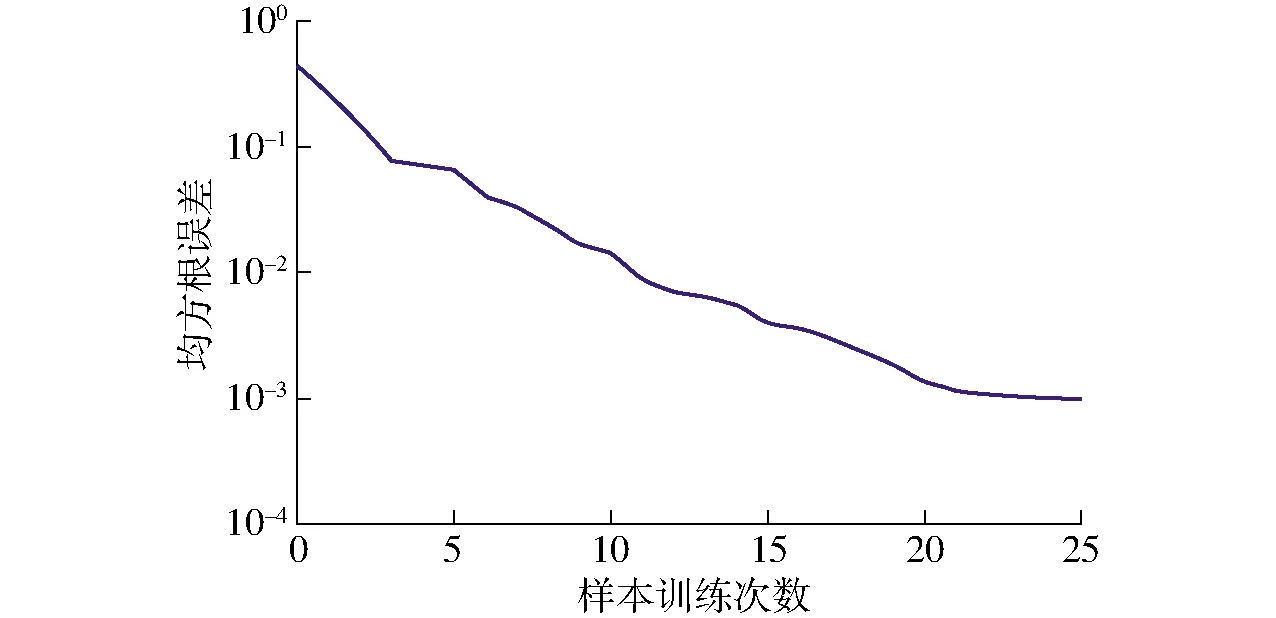
图12 基于遗传算法的BP神经网络训练误差曲线Fig.12 BP neural network training error curve based on genetic algorithms
利用9 000组数据训练的基于遗传算法的BP神经网络模型在预测4 000组测试数据时,正确组数为3 871,正确率为96.77%。由此可见,基于遗传算法的BP神经网络模型预测结果与实际作业情况基本一致,错误率为3.23%,可准确有效评价拖拉机田间旋耕工况作业质量。
5 结论
(1)基于我国“七区二十三带”农业战略格局,建立了全国范围的拖拉机测试终端布局,完成了测试终端硬件、测试工况以及测试系统功能架构。
(2)分析了拖拉机作业载荷数据库系统需求、管理机制、网络架构以及功能结构,设计并搭建了拖拉机作业载荷数据平台系统,可实时获取、存储拖拉机各关键零部件的田间作业载荷数据。
(3)研究了神经网络与遗传算法的融合算法,并基于拖拉机作业载荷数据平台对拖拉机田间旋耕作业质量进行实时预测与评价,预测精度达96.77%,均方根误差(RMSE)小于0.01,说明采用基于遗传算法的BP神经网络算法的拖拉机作业载荷数据平台预测评价拖拉机田间旋耕作业质量可行。
