基于多元日志分析的智能安全感知研究
2020-08-26吴丽琼黄晓波肖建毅唐亮亮
吴丽琼,黄晓波,唐 乐,肖建毅,唐亮亮
(广东电力信息科技有限公司,广州 510000)
0 引言
随着科技的发展与网络的普及,社会中越来越多的工作能够通过网络应用实现。在这个过程中,网络管理员和系统管理员需要重点关注的是如何避免网络应用当中存在的安全漏洞被黑客所挖掘和利用,破坏网络连接或影响应用运行。结合系统运维实际工作可知,运维人员可通过日志记录系统和运行状态,定位和分析运行故障,审计和回溯操作记录。日志文件数据具有丰富而有效的信息量,但同时也具有巨大的信息体量。
在实际工作当中,日志类型丰富、存储格式多样、获取方式复杂,为了对日志数据进行关联分析以从大量繁杂的日志数据中提取有价值的信息,系统运维实现日志集中化管理、规范化清理和关键字搜索的需求日渐增长。同时,对于系统优化来说,用户增长分析、产品优化体验等也能够从业务日志数据中获取业务链关联分析数据和用户行为分析数据,能够有效地完善系统功能,提升用户体验。
针对以上问题,本文提出一种基于大数据日志智能分析模型的日志审计分析平台,从网络安全和系统运维的需求出发,提出基于多元日志分析的智能安全感知算法,拥有日志切割提取、可视化多维分析等核心功能,采用B/S 架构,通过JDBC及SSH采集提取网络、中间件、数据库、设备等机器的实时日志数据,通过前端WEB界面进行分析与展示,实现统一管理、隐患分析、故障定位、安全预警等分析功能,收集多元日志数据并充分利用IT设备基础结构日志和和安全日志进行数据分析和挖掘,给运维人员提供价值最大化的日志数据信息。
1 系统框架设计
1.1 日志的自动化识别和提取
针对操作系统和软件的差异这一问题,日志审计分析平台内置了识别算法,利用flume框架进行日志抽取的,该框架能够根据相关特征对不同系统以及不同的软件运行产生的日志文件进行智能识别,实现快速模版匹配,实现高效的字段切割提取。例如,自动识别库功能,保障日志自动识别入库,目前均已支持了常见的IT设备日志,具体如表1所示。
1.2 数据的快速检索
ElasticSearch 算法是一种基于Lucene 的开源分布式算法,可以实现实时的数据搜索与分析,基于ElasticSearch算法开发除了支持全文检索,还可以使用字段、数值范围检索,指定时间范围查询的大数据检索,使2亿条数据可以达到秒级响应。
日志审计分析平台为数据的快速检索设计了强大的搜索函数,可以支持复杂的统计语句及强大的管理搜索功能,利用文本高效的读写性能和大数据的分布式架构,实现对数十亿的数据、任意关键字的秒级搜索。支持在搜索结果界面直接展示分布图,对结果进行图形化的下钻展示和取样等操作。针对文本分析设计的函数搜索分析语言,支持相关逻辑表达式的关联运算,同时也支持聚合函数的运算(如count和sum)、字符串、数字、时间操作函数。提供业界强大的分析统计功能,同时系统还支持自定义的换行规则,包括自动,正则表达式、原始换行几种方式,支持大小写区分和不区分的短语搜索、多词搜索以及实时模式等功能,满足日志管理搜索查询的所有需求。可视化界面如图1所示。日志审计分析平台为了方便不同用户的搜索需求,开发了支持多种应用模式的信息检索功能。

表1 支持设备列表
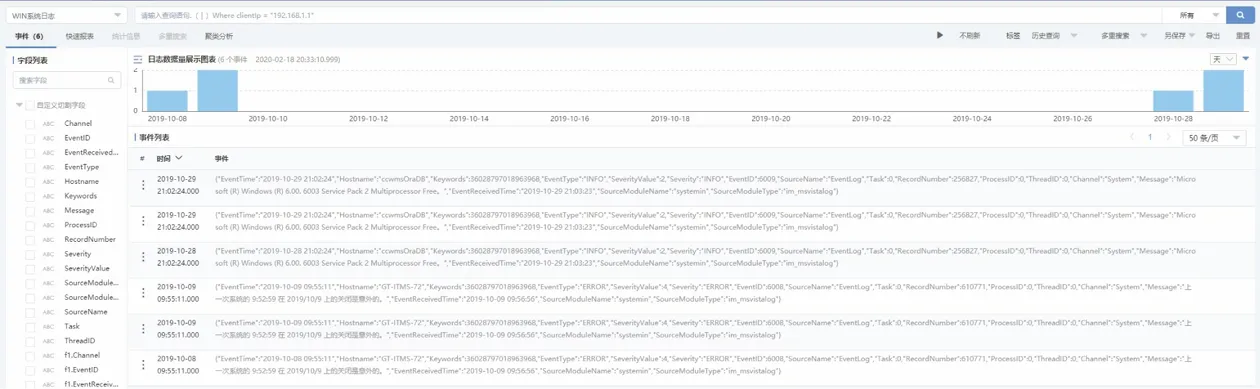
图1 搜索函数
1.3 可视化字段切割提取
日志审计分析平台可以根据特殊字符对存储的日志进行可视化切割,特殊字符包括空格、竖线或用户根据自己的需要自定义的字符等进行自动切割,也可以通过划词的方式自动生成正则表达式的方式对日志进行切割提取。此外,对于xml、json、API 接口等日志数据也可以实现自动快速的切割接入。日志审计分析平台采用的是自主研发的切割算法,支持随时自定义和二次切割,能够充分根据客户要求进行定制,实现特定需求。
1.4 其他功能
日志审计分析平台支持多维度日志分析,支持可视化拖拽组合报表生成。同时,平台支持对数据按多种不同维度进行切片,便于用户按需对数据进行抽取和分析处理。
系统支持通过字段进行配置报表功能,支持多种图形选择,并且可以对报表进行修改、分享给其他用户使用,可以将报表放置到仪表盘上进行大屏展示,通过执行计划可以定期将报表内容通过邮件的方式发送给用户。如图2所示。
支持对多个日志数据进行关联分析,通过配置关联字段进行展示分析,系统内置对日志按照时间轴的方式进行分析。除了针对日志的关键字进行搜索和分析外,用户还可以通过调用函数搜索语句中的函数实现各种灵活的逻辑判断和数据统计,为用户带来可以自定义的告警能力,满足企业级用户对各种特定场景的不同需求。除了最基础的阈值和关键字告警以外,还分别支持针对事件数、字段数、连续统计和基线对比等高级告警功能。
图2 报表
2 系统算法
2.1 阈值告警与基线告警
日志审计分析平台使用基线预测相关算法,涉及ARIMA模型,下面将展开阐述。一个完整的基线告警由基线计算,容忍线计算和产生警告的方法三部分组成。其中,基线的计算是整个流程的基础,基线计算的流程如图3所示。

图3 基线计算流程图
基线,即数据变化的基准线,用来描述某个数据的正常的变化范围和波动空间,如图4 所示。基线告警也称基线范围,用来设置判定异常的界限,同时它是以基线为基础,上下浮动所指定的值[1]。关于浮动值的设定,可选择百分比和绝对值。
基线的设置是以设备运行的过程中所产生的数据为标准,这个标准理论上是不会发生变化的,除非根据实际需求进行人为更改。但是基线也并非是一成不变的,比如某网站的访问量可能在其搞活动期间会大幅度上升,CPU 和内存的利用率必然会有所提升,如果利用同样的基线作为告警的标准,则可能会出现误判,引起不必要的人力和资源的消耗。所以根据实际情况,将告警的基线进行改进[3],改进后的基线如图5、6所示。

图4 某个数据正常的变化范围和波动空间
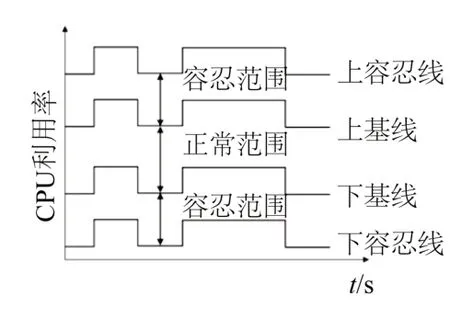
图5 基于告警线的改进图

图6 动态基线改进图
首先利用用户系统所产生的日志文件对要计算的样本进行数据采集,然后将采集到的数据进行降噪处理,除去多余的噪音,提高数据的纯度。根据数据的分布情况进行线性回归分析,最终得到的那条回归曲线即为基线[2]。
动态基线告警的实现为服务器、中间件及数据库的CPU、内存利用率提供了一种专门且高效的管理方法,提高了各类软件相互通信的支撑系统的可靠性,动态基线告警系统将传统1天2次的人工巡检升级为系统7天24 h全天候智能监控,故障监控平均发现时间由之前的1.5 h 缩短为1 min 以内,这样不仅增强了系统的可用性,也提高了运维人员的工作效率。
2.2 ARIMA模型
2.2.1 ARIMA模型简介
ARIMA 模型全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记 ARIMA),AR是自回归,p 为自回归项;MA 为移动平均,q 为移动平均项数,d 为时间序列成为平稳时所做的差分次数[4]。ARIMA模型在预测过程中不仅考虑了某一现象在时间序列上的依存性,又考虑了随机波动的干扰性,对于某一现象运行短期趋势的预测准确率较高,是应用广泛的时间序列预测方法之一[5-6]。
下面简单介绍一下ARIMA模型中涉及到的几个概念。
(1)平稳随机过程
若一个随机过程m 阶以下的矩的取值全部与时间无关,则称该过程为m 阶平稳过程。通常使用一阶平稳过程,即随机过程xt的均值mt不随时间变化。
(2)自回归过程

式中:φi为自回归参数,ut为白噪声过程。
则称xt为p阶自回归过程,用AR(p)表示。
(3)移动平均过程

式中:θi为自回归参数,ut为白噪声过程。
则称式(2)为q阶移动平均过程,记为MA(q)。之所以成为移动平均,是因为xt是由q+1 个ut及其滞后项加权构成的。
(4)自回归移动平均过程
如果一个剔除均值和确定成分的线性随机过程由自回归和移动平均两部分共同构成,则称其为自回归移动平均过程,记为ARMA(p,q),表示如下:

(5)差分
时间序列变量的本期值与其滞后值相减的运算称为差分:

其中Δ 称为一阶差分算子。
二次一阶差分表示为:

2.2.2 数据的平稳性处理和白噪声检验
ARIMA 模型在建立时通常会先用ADF(Augmented Dickey-Fuller)单位根检验来判断数据的平稳性。对于非平稳性的时间序列,可以采取取对数处理或者进行差分处理,然后再对修正后的数据进行平稳性的判断。也可以采取差分的形式,而差分的次数就是ARIMA(p,d,q)模型中的阶数d。差分的过程中的阶数的选择要适当,一般情况下差分的次数不会超过2次。处理完成的数据由原来的ARIMA(p,d,q)模型就转化为ARIMA(p,q)模型[7]。若采集到的数据为时间序列之间彼此无关联的平稳时间序列,应采取不同的方法。此时序列为纯随机序列,又被称为白噪声序列,它具有两个非常重要的性质:(1)纯随机性;(2)方差齐性。纯随机性是判断信息是否被提取完整的重要依据,方差齐性则是指数据序列当中所有的变量方差相等。只有当方差齐性成立的时候,用最小二乘法得到的未知参数估计值才会准确有效,否则无法准确的估计参数值。纯随机性通常采用构造检验统计量,一般为Q 统计量。异方差的检验方法采用怀特检验法[8]。
2.2.3 参数分析
分析确定ARIMA 模型参数p、d、q 的方法有两种:(1)方法一是通过分析人员对时间序列的充分了解,根据日志记录数据所呈现出的趋势确定差分次数d,使ARIMA 模型中的时间序列平稳化,然后再使用自回归函数图来确定滑动过程中平均的阶数q,用偏自回归函数图来确定自回归过程的阶数p;(2)方法二直接使用拟合得到的信息准则法确定阶数,这里的信息准侧有赤池信息准则(AIC,Akaike Information Criterion)和贝叶斯信息准则(BIC,Bayesian Information Criterion),它们的分析原理都是拟合残差最小的阶数p 和q 就是最合适的。
方法一确定模型参数p、d、q的方法要求分析者对时间序列的数据背景,以及对ARIMA模型原理都非常熟悉,才能够确定出合适的参数结果;方法二则可以借助SPSS等统计分析工具快速尝试各种p、d、q 的数值组合,然后比较AIC 或BIC两种信息准则,确定最终的ARIMA模型参数[8]。
对比两种方法,方法一需要操作人员对数据和ARIMA模型原理有十分深入的了解,因此结果一般都更为精准,但是时间成本相对较大,时间成本也相对较高;方法二则通过借助计算机软件辅助,快速得到结果,但是可能会遗漏一些重要信息,造成与真实结果的些许偏差。当然最好是在分析的过程将两种方法结合使用,先用计算机快速获得结果,再对该结果进行改进确认,以实现参数的最优解[8]。
3 结束语
日志审计分析平台使用基于多元日志分析的智能安全感知算法,并结合经典的ARIMA模型使平台能够对多种系统产生的多元日志从精准的分段切割,数据的检索分析到对未来的数据进行预测估计,可以以图表的形式形象地将结果呈现在用户面前,避免了原来纯文字或数据所带来的抽象。目前平台已经实现智能化的运维分析,进一步将日志审计分析平台继续研发优化,从智能和安全的角度出发,完善系统功能,以求满足广大用户多样的需求,进一步提升智能化运维和保障运维安全性。
