基于敏感权限和API的Android恶意软件家族分类方法
2020-08-25于媛尔张琳琳方文波胡英杰王晨跃
于媛尔, 张琳琳, 赵 楷, 方文波, 胡英杰,宋 鑫, 王晨跃
(1. 新疆大学 信息科学与工程学院 新疆 乌鲁木齐 830046; 2. 新疆大学 网络空间安全学院 新疆 乌鲁木齐 830046; 3.新疆大学 软件学院 新疆 乌鲁木齐 830091)
0 引言
自2007年面世以来,Android系统迅速发展为移动终端应用最广泛的操作系统。相比于个人计算机,移动设备与用户的隐私信息和财产安全联系更为密切。此外,由于系统的开源性与市场开放性,Android操作系统更加容易被恶意软件利用。2019年8月13日,360互联网安全中心最新发布《2019年上半年中国手机安全状况报告》[1]。报告显示,2019年上半年,360互联网安全中心共截获安卓平台新增恶意程序样本约92.0万个,平均每天截获新增手机恶意程序样本约0.5万个。恶意软件样本数量的增长速度远远超过了恶意软件检测系统分析的速度。
大多数新型恶意软件样本都是已知恶意软件的多态变体[2-3],由于同源恶意软件家族很大程度上都共用了祖先的大部分代码,具有内在关联性,因此,同一家族的样本可能执行类似的恶意行为。将恶意软件样本分类到各个已知的家族中,不仅可以减少这些恶意软件变体的分析时间,还可用于预测未知恶意软件样本的行为。这对于恶意软件的检测和分类具有重要意义。
本文依据恶意家族继承性与衍生性的本质特征,结合静态分析方法,提出一种基于敏感权限和API的Android恶意软件家族分类方法,并结合随机森林算法实现对Android恶意软件的家族分类。
1 恶意软件家族分类现状
目前,通过对Android不同家族的特征进行研究,总结出119个家族的恶意行为,例如,数据窃取、恶意下载、将信息窃取到远程服务器等。恶意软件家族之间的区别微不可察,恶意行为的大量重叠使得区分家族变得异常困难。国内外学者针对Android恶意软件家族分类提出了多种方法。分类方法大致可以分为静态分析方法和动态分析方法。
静态分析方法是在不运行程序情况下,需要先对应用程序进行反编译或反汇编处理,通过处理过后的代码来分析Android应用程序的行为,并根据这些行为来判断应用程序是否具有相似性。文献[4]通过多个签名条目(字符串、方法名、方法体等)评估不同样本间的相似性,进而归类同家族样本,使得检测变体成为可能。Dendroid[5]利用数据挖掘的方法分析Android恶意软件家族样本的代码结构,通过静态分析,提取与应用程序片段关联的代码结构CFG来进行恶意软件的相似性计算。DroidSieve[6]是一种基于静态分析的Android恶意软件分类器,该分类器快速、准确且对混淆具有弹性。Fan等[7]为了识别Android恶意软件的多态变体,采用聚类算法和社区结构方法,从家族样本的敏感API调用子图中提取频繁子图作为恶意软件的家族行为特征,并利用该家族特征识别未知恶意软件,检测率达到94.5%。文献[8]定义了Android软件基因,从代码段、资源段和配置清单文件三个方面对基因进行了提取,并进行检测与分类,有较高的检测率和分类正确率。文献[9]提出了一种用于发现不同数量大小的Android恶意软件家族的新算法,通过在Drebin[10]和最近的Koodous恶意软件数据集上进行实验,得到良好的分类效果。文献[11]提出了一个两级行为图模型DroidMiner,并提取敏感路径来表示恶意软件的行为模式。但是敏感路径可能出现在合法部分和恶意组件中,从而导致高误报率。DroidSIFT[12]提取加权上下文API依赖图作为程序语义来构造特征集,确定应用程序是否属于恶意应用程序,以及恶意应用程序所属的家族,其依赖于一组良性子图来删除恶意软件中的常见子图。不足的是,确保良性子图集的完整性往往是困难的。文献[13]提出了MassVet,它将应用程序的UI建模为有向图,其中每个节点都是一个视图,每个边描述它们之间的导向关系。通过不同应用程序中的类似视图结构,MassVet可以有效地识别重新打包的应用程序。
动态分析方法主要是通过运行Android应用程序发现应用漏洞,常见的方式是通过在沙箱中运行应用程序,观察应用程序所表现出的行为,分析其中是否存在恶意行为,如是否泄漏用户隐私、是否含有诱骗信息等。文献[14]提出了一种自动提取Android恶意软件家族签名的方法,通过识别使用相同(或类似)恶意代码搭载在不同的良性应用程序上,对产生的恶意软件的签名进行家族匹配,但该方法的重点明确放在搭载和重新打包的应用程序上。DroidScribe[15]使用机器学习方法将Android恶意软件样本自动准确分类到各个家族中,同时仅观察其运行时的行为。
由于静态分析只需要反编译提取文件的相关特征就可以进行分析,相比于动态分析,不会对系统运行产生影响,所消耗的系统资源与时间较少,效率更高。因此本文提出一种基于静态分析的方法,进行恶意软件的家族分类。
2 本文方法
2.1 Android理论基础
任何Android应用程序的后缀都是.apk,即Android application file package。APK文件是一个压缩包,主要包括Java源代码编译后的文件、资源文件、签名证书和配置文件等,本文所提取的API在classes.dex文件中,采用dex2jar工具进行反编译,可得到.jar后缀的文件,用jd-gui工具将.jar文件反编译为.java文件,最后通过python代码提取其中的API。
APK文件经过工具APKTool(http:∥ibotpeaches.github.io/Apktooll)反编译可以生成一种smali格式的数据包。smali语言是Davlik的寄存器语言,语法上和汇编语言相似。smali文件前三行的通用模式如下:
.class<访问权限[修饰关键字]><类名>,用于说明目前的类名;
.super<父类名>,说明目前类的父类名称;
.source<源文件名>,说明目前类的源文件名称。
剩下的是类的主体部分,一个类包括多个字段或方法。
2.2 恶意软件家族分类框架的搭建
整个系统的框架如图1所示,首先收集各个家族的恶意软件样本,通过Android逆向工程技术提取权限与API,将提取过后的Android权限通过权值分配,对比不同权值的结果,选取结果最优的权限组作为敏感权限。通过Android官方声明文档中对敏感权限所对应的API进行提取,并与通过权值筛选提取的API相结合,将这些API定义为敏感API,将敏感API与权限相结合构成特征集,最后通过随机森林算法对Android恶意软件家族进行分类。
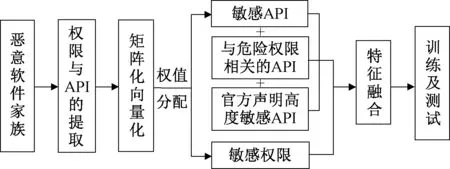
图1 恶意软件家族分类框架图Figure 1 Malware family classification framework
2.3 特征提取
2.3.1敏感权限的提取 普通权限是指那些不会威胁到用户安全和隐私的权限,这部分权限系统会自动进行授权,不需要手动操作。敏感权限则表示那些可能会触及到用户安全隐私或者对设备安全造成影响的权限,如获取手机联系人信息等权限,这些权限必须由用户点击授权才可以使用,否则程序无法使用相应的功能。本文采用APKTool工具对Drebin数据集[10]中的APK文件进行反编译。由于反编译过后的AndroidManifest.xml文件中声明了所有权限,要筛选出所需要的敏感权限,还需要进一步处理。因此对20个家族4 664个样本的权限信息进行提取,并根据提取结果与目前官方发布的151个权限进行对比,采用权值计算公式(1)对各家族权限赋予权重,
(1)
其中:p(s,f)代表家族f中某个权限调用样本数s;allnum代表所有家族的总样本数;totalnum代表家族f的样本数。选用w>0.3、w>0.2和w>0.1的三组权限进行对比,最终选取w>0.1的权限作为本文的敏感权限,共31个。
2.3.2敏感API的提取 通常,恶意软件的实现需要调用特定API来完成,如恶意计费软件会调用发送短信的API、隐私窃取软件会调用访问通讯录的API等,此类API被称为敏感API。本文的敏感API主要分为三个部分。第一部分是通过将Drebin数据集中选取的4 664个APK进行解压,对其中的classes.dex文件采用dex2jar和jd-jui工具得到java源码,从java源码中提取出API,并进行统计筛选,通过权值计算公式(1),选用w>0.2、w>0.1和w>0.05的三组API进行对比,最终选取w>0.05的共30个API作为敏感API的一部分。第二部分通过查阅Android5.1.1版本的官方文档,提取出8个危险权限所对应的87个API。最后一部分为官方声明重度敏感的11个敏感API。删去重复部分,最后一共提取121个API作为敏感API。将每个APK反编译过后,从中提取.smali文件与敏感API进行匹配。
2.3.3敏感权限与API特征融合 由于单一特征难以充分地反映恶意软件的恶意行为,例如权限虽然可以证明敏感资源的使用情况,但是不能提供可疑应用程序意图的详细描述,而与权限相关的API更能反映恶意软件的行为。因此本文将31个敏感权限与121个敏感API结合后共152个敏感特征,作为分类器的输入。
2.4 分类算法
随机森林(random forest,RF)是一种常见的机器学习分类算法,通过集成多个决策树生成分类器,且其输出的类别是由个别树输出的类别的众数而定[16]。在样本训练阶段,通过有放回抽样的方式抽取子样本集,对每组子样本集进行决策树建模,由多棵决策树构成随机森林。在样本预测阶段,先统计每棵决策树的预测结果,再通过投票形式给出最终的分类结果。
随机森林算法有许多优点,例如,既可以用于回归也可以用于分类任务,易于查看模型输入特征的相对重要性等。特别是在处理多种类型数据时准确度较高,且可以平衡不平衡数据集的误差,适用于恶意家族数据集的分类。所以,本文实验选用随机森林算法作为分类算法,并与K近邻(K-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)、逻辑回归(logistics regression,LR)、反向传播(back propagation,BP)、决策树(decision tree,DT)进行对比。
3 实验结果与分析
3.1 实验数据
本文的数据集来源于Drebin数据集,包含5 560个恶意软件样本,共179个家族。由于大多数家族的样本个数较少,不具有代表性,因此选择样本数量排名前20的家族作为本实验的数据集,家族分布情况如表1所示。

表1 数据集样本列表Table 1 Dataset list
3.2 结果分析
为了评估该模型对于Android恶意软件家族分类的效果,主要采用的指标为:精确度(precision)、召回率(recall)、F1值及正确率(acc),其中:precision代表预测正例正确占所有预测正例的比值;recall代表预测正例正确占全部实际为正例的比值;F1是precision和recall加权调和平均;acc代表分类器正确分类的样本数与总样本数之比。以上指标计算为
其中:TP(true positive)为真正例,代表将正例正确预测为正例的样本数;FP(false positive)为假正例,代表将负例错误预测为正例的样本数;FN(false negative)为假负例,代表将正例错误预测为负例的样本数;TN(true negative)为真负例,代表将负例正确预测为负例的样本数。采用随机森林算法得到的实验结果如表2所示,除了ExploitLinuxLotoor家族的F1值较低之外,其他家族的平均F1值都高于90%。对恶意软件家庭分类的平均精确度为98.4%、平均召回率为95.9%、平均F1值为97.1%。表明该方法对于恶意软件家族分类有较好的效果。
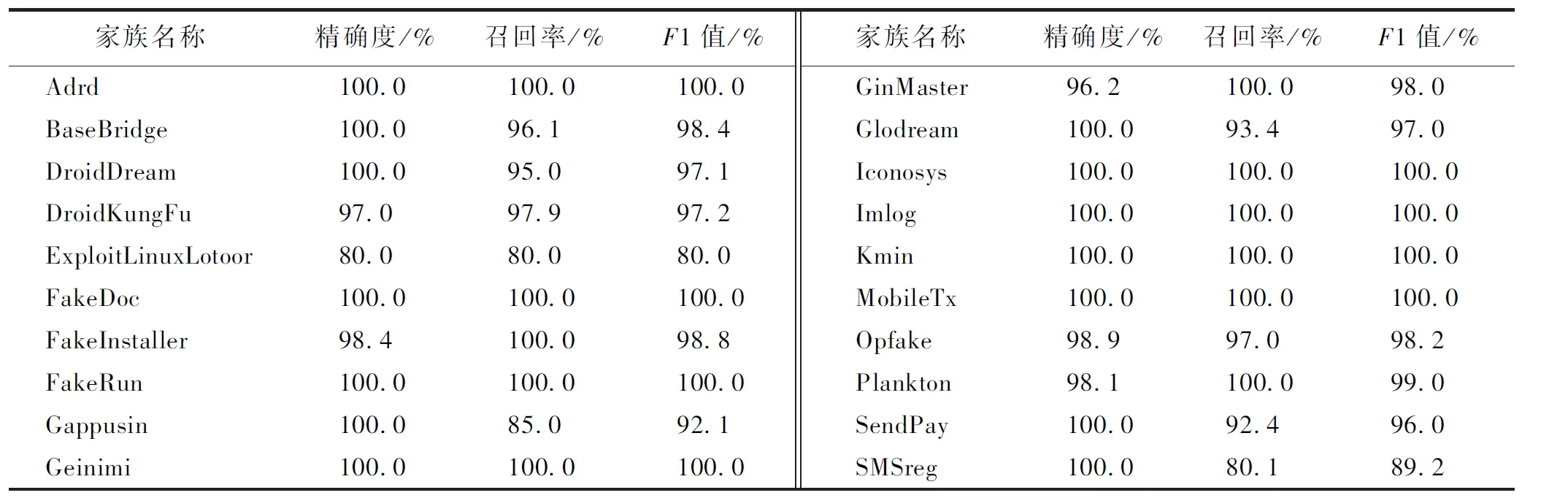
表2 随机森林分类算法实验结果Table 2 Experimental results of RF classification algorithm
为了证明随机森林方法分类的准确性,本文采用其他5种分类算法进行实验结果对比分析,如表3所示。实验结果表明,随机森林算法优于其他5种基线算法。
4 结束语
恶意软件变体数量的快速增长,为恶意软件的检测及分类带来极大挑战。为了缩短恶意软件检测及分类的时间,将其分类至所在的家族显得格外重要。本文提出一种基于敏感权限和API的恶意软件家族分类方法,利用逆向工程技术提取Android应用程序的权限和API特征。通过权重分配,定义并提取敏感权限和敏感API,同时进行特征融合,构建出特征库,最后采用随机森林算法进行分类。实验结果表明,该方法能够有效地进行恶意软件的家族分类,达到了较高的精确度。下一步工作,将抽取或挖掘更多特征(如增加intent、opcode、string等特征)对恶意软件进行全面描述,并利用深度学习模型研究更多恶意软件家族的衍变规律。
