一种用于中文微博情感分析的多粒度门控卷积神经网络
2020-08-25左敬龙朱兴统
陈 珂, 梁 斌, 左敬龙, 朱兴统
(1.广东石油化工学院 计算机学院 广东 茂名 525000;2.哈尔滨工业大学(深圳) 计算机科学与技术学院 广东 深圳 518055)
0 引言
随着社交媒体的日渐繁荣,社交文本已成为人们在生活中发表意见和观点的最重要信息来源[1-2]。文本情感分析可以从微博文本中挖掘用户的情感表达,能有效帮助人们学习和判断事物的好坏。如何从微博文本中挖掘用户的情感表达,是自然语言处理领域的研究热点之一[3]。和普通文本分类不同,文本情感分析任务需要考虑文本的情感表达以及文本中包含的不同极性的情感词语,并有效利用这些信息[4]。近年来,越来越多学者开始将深度学习方法应用在自然语言处理任务中,并且在文本情感分析任务中也得到了广泛利用。文献[5]提出一种使用卷积神经网络模型应用在文本分类任务中,并验证了该模型在文本分类任务中的有效性。文献[6]基于LSTM网络提出一种短文本情感分析网络模型,并验证了LSTM网络在短文本情感分析任务中的有效性。文献[7]基于卷积神经网络提出了一种使用自适应卷积滤波器的深度网络模型,该模型在文本分类任务中取得了令人瞩目的成功。在结合情感信息的研究工作中,文献[8]使用不同通道接收文本信息的输入,可以从短文本中挖掘更深层次的情感特征。但是,这类方法往往无法充分挖掘文本的深层次词语特征信息,并且在分词错误时会造成情感信息的缺失和噪声的引入。因此,在中文微博情感分析任务中效果不佳。
基于目前深度学习在短文本情感分析任务中的成果,本文从词语和单字两个层面来分析短文本的情感特征,并通过带有门控操作的卷积神经网络来结合不同粒度的特征信息,从而可以控制信息的更新和传递,完成短文本的情感极性判断。本文提出的多粒度门控卷积神经网络(MG-GCNN)模型思路如下:1) 使用一个作用在词语层面的卷积神经网络来获取文本的词语信息,从而学习文本的词语层面抽象化特征。2) 由于微博文本中往往会存在很多新兴的网络用语,而传统的分词方法无法将这类词语正确分词。因此,在词语层面信息的基础上,使用单字来表示文本信息,并通过卷积神经网络来获取文本的抽象化单字特征。3) 使用一个门控操作来结合词语和单字粒度的特征信息,从而使抽象化特征能够有控制地更新和传递,更好地挖掘短文本深层次的情感特征。在微博文本数据集上的实验结果表明,MG-GCNN模型取得了较好的情感分类效果。
1 多粒度门控卷积网络
在以往研究的基础上使用词语和单字层面来构建卷积神经网络的输入,并通过门控操作来控制信息的传递和调整,所提出的MG-GCNN模型的结构如图1所示。

图1 MG-GCNN模型的结构Figure 1 The structure of MG-GCNN model
1.1 任务定义
中文微博文本情感分析需要模型从有限的文本资源中获取文本的情感特征信息,并通过学习提取到文本特征信息,对文本进行情感极性的判别。对于句子s={c1,c2,…,cr}和s={w1,w2,…,wn},其中wi和ci表示词语和单字,分别代表文本的词特征和字特征。通过将文本的词特征和字特征映射为一个多维的连续值向量,可以得到文本的特征表示ei∈Rd和xi∈Rd,其中d为词特征或者字特征向量的维度,在实验中将词向量和字向量映射为相同维度的特征向量。
1.2 词语粒度卷积神经网络
将输入句子表示成一个词语序列来获取输入文本词语层面的特征信息。对于包含n个词语的输入句子,输入矩阵可以表示为
e1:n=e1⊕e2⊕…⊕en,
(1)
式中:⊕为拼接操作;e1:n∈Rd×n。卷积神经网络通过对句子进行卷积操作来完成输入句子的词语层面特征提取。对于窗口大小为h的卷积核,可以把输入句子分为{e0:h-1,e1:h,…,en-h+1:n},然后对每一个分量进行卷积操作,得到的卷积特征图可以表示为
Ai=ei:i+h-1·W+b,
(2)
式中:Ai为卷积操作得到的特征信息;ei:i+h-1∈Rd×h为长度为h的卷积窗口包含的词语向量信息;W为权重矩阵;b为偏置向量。
1.3 单字粒度卷积神经网络
由于中文微博文本的长度往往较短,同时文本中会包含大量无法正确分词的网络用语。因此,文本使用单字序列表示输入句子来获取文本更深层次的特征信息。对于单字序列s={c1,c2,…,cr},单字向量卷积神经网络输入矩阵可以表示为
x1:n=x1⊕x2⊕…⊕xr,
(3)
式中:x1:n∈Rd×r。与词语粒度卷积神经网络操作相同,通过不同大小的卷积核来对输入信息进行卷积操作,获取单字层面的情感特征信息。对于窗口大小为h的卷积核,卷积操作可以表示为
Bi=xi:i+h-1·W+b,
(4)
式中:Bi为卷积操作得到的特征信息;xi:i+h-1∈Rd×h为长度为h的卷积窗口包含的单字向量信息;W为权重矩阵;b为偏置向量。
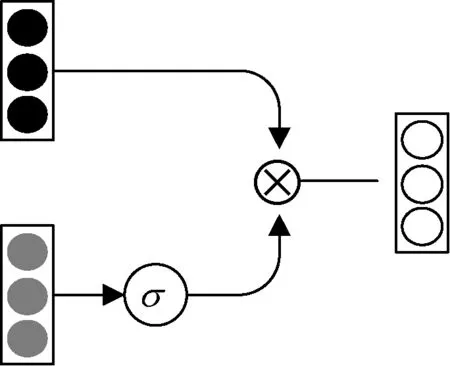
图2 门控卷积网络Figure 2 Gated convolutional networks
1.4 门控卷积网络
虽然词语层面的信息包含了输入文本最重要的特征,但是当输入文本分词不恰当、新型网络用语使用较多时,单从词语层面将无法挖掘输入文本的情感信息。针对该问题,使用一个门控操作来结合不同粒度的特征信息,使模型可以更充分地挖掘文本的情感特征,门控卷积网络如图2所示。
使用门控操作连接不同粒度的特征信息,可以表示为
Hi=A⊗σ(B),
(5)
式中:A为词语粒度特征信息;B为单字粒度特征信息;σ为Sigmoid激活函数;⊗为对应元素相乘。通过卷积操作,模型在训练过程中可以有选择地使用和学习不同粒度的特征信息,完成模型参数的调整,从而可以挖掘更准确的情感特征信息。
1.5 隐藏层网络
为了提取句子中最重要的特征信息,采用max-over-time pooling对门控操作得到的特征信息进行池化操作,提取特征向量图中最重要的特征信息,即Ho=max{Hi}。然后通过一个全连接层来完成特征信息的向量化映射,输入文本的向量化表示为
H=Relu(Ho·W+b),
(6)
式中:H∈Rm为输入文本的向量化表示,m为向量维度;W和b为全连接层的权重矩阵和偏置向量;Relu为全连接层激活函数。
1.6 模型训练
通过一个Softmax函数输出分类结果,即
y=Softmax(X·W+b),
(7)
X=H∘r,
(8)
式中:r∈Rm为下采样层输出的正则项限制;∘为对应元素相乘;W∈R|X|为全连接层权重矩阵;b∈R为全连接层偏置向量。使用反向传播算法来训练模型,通过最小化交叉熵来优化模型,交叉熵代价函数可以表示为
(9)

2 实验及结果分析
从COAE2014数据集中标注6 000条带有极性的数据,其中积极情绪样本2 864条,消极情绪样本3 136条。此外,从不同领域微博语料中随机爬取5 000条带有极性的中文微博文本,作为微博语料数据集(micro-blog dataset, MBD),其中积极情绪样本和消极情绪样本各2 500条。使用ICTCLAS分词工具对语料进行分词,词向量和字向量采用Google的word2vec工具的skip-gram模型进行训练,维度设置为300维。对于未登录词,采用均匀分布U(-0.01,0.01)来随机初始化词向量。在实验中使用多窗口、多卷积核对句子进行卷积操作,其中窗口大小分别为2、3、4、5,每种窗口的卷积核个数均为100。为了防止过拟合,使用了dropout机制和权重的正则化限制,训练过程采用Adadelta更新规则[9]。
2.1 实验介绍
在COAE2014和MBD数据集上,将所提出的MG-GCNN模型和目前取得突破性成果的传统方法、深度学习方法进行对比实验。对比实验所用的模型具体包括:1) MG-CNN为本文提出的多粒度信息输入卷积神经网络,但仅使用简单拼接来结合不同输入粒度的特征信息;2) MG-GCNN为本文提出的多粒度门控卷积神经网络的完整模型;3) SVM[10];4) CNN[5];5) WFCNN[11];6) EMCNN[12];7) MCCNN[8];8) AC-CNN[7]。
2.2 实验结果与分析
在COAE2014和MBD数据集上进行实验,不同模型的情感分类结果如表1所示。

表1 不同模型的情感分类结果Table 1 Sentiment classification results of different models
从表1可以看出,所提出的MG-GCNN模型在2个数据集上的分类效果都优于对比实验,其中在分类效果最好的MBD数据集上,F1值比以往研究中取得最好效果的MCCNN模型分别提升了0.42%和1.01%,从而验证了本文提出方法的有效性。加入情感序列的WFCNN模型在COAE2014和MBD数据集上的分类效果都优于CNN模型,相比CNN模型分别提升了2.57%和3.05%。这表明在情感分析任务中,结合情感特征的模型能更好地学习句子的情感倾向,根据情感特征信息,使模型可以有效地学习句子的情感极性。对比使用门控操作的MG-GCNN模型和不使用门控操作的MG-CNN模型,可以看出,MG-GCNN模型在2个数据集上的分类效果比MG-CNN模型分别提升了2.19%和4.02%。这表明使用门控操作的MG-GCNN模型在训练过程中,可以通过门控操作来控制不同粒度特征信息的传递和更新,同时也能保留输入文本信息的序列化情感依赖;在分词不恰当的情况下,也能通过门控卷积操作挖掘单字层面上信息的提取和学习,完成输入文本的情感极性判别。此外,相比COAE2014数据集,MBD数据集保留了中文微博的原始文本特征,并且从不同领域的数据中随机选取训练集和测试集,在最大程度上保留了中文微博的特征。对比两个数据集的实验结果可以看出,MG-GCNN模型在MBD数据集上的分类效果优于COAE2014,表明MG-GCNN模型在更一般性的中文微博语料中能有更好的效果,从而验证了MG-GCNN模型在中文微博情感分析任务中的有效性。
2.3 门控操作有效性验证
为了进一步验证所提出的MG-GCNN模型的有效性,分析了MCCNN、MG-CNN和MG-GCNN模型在2个数据集上的召回率和F1值的分类效果,对比结果如图3和图4所示。

图3 召回率对比结果Figure 3 Comparison results of recall

图4 F1值对比结果Figure 4 Comparison results of F1-score
从图3可以看出,MG-GCNN模型与以往研究中取得最好效果的MCCNN模型进行对比,MCCNN模型在积极样本数据集上的分类效果都略优于MG-GCNN模型,表明结合文本多样化特征表示的MCCNN模型能通过不同类型特征信息来挖掘文本的隐藏特征,完成文本的情感极性判别。而在消极样本数据集上,MG-GCNN模型的召回率都高于MCCNN模型,表明结合门控操作方法能使模型在训练过程中学习不同粒度的文本特征信息,并通过门控操作保留文本的特征信息依赖关系。因此,在其他模型表现欠佳的消极样本数据集上也能取得更优的情感分类效果。此外,从图4的对比结果可以看出,MG-GCNN模型在4组实验中的F1值都取得了最优的效果,表明MG-GCNN模型在不同极性数据集上的分类有效性比其他模型都平均,从而验证了MG-GCNN模型在微博文本情感分析任务中的有效性。
2.4 经典样例分析
为了进一步分析所提出的MG-GCNN模型在微博文本情感分析任务中的有效性,从数据集中抽取一些经典样例进行对比分析,实验结果如表2所示。

表2 经典样例分析Table 2 Analysis of typical sentences
如表2所示,样例1和样例2属于情感表达明显、结构简单的句子,这类句子是用户表达情感的常用句子结构,所以3种模型都能正确识别这类句子的情感极性。样例3属于含有网络用语的句子,这类句子通常包含分词工具无法正确分词的网络用词,结合多粒度特征输入的MG-CNN和MG-GCNN模型都能有效利用这类词语的情感信息正确识别文本的情感极性。样例4也属于微博文本中用户表达情感的常用类型,这类句子往往包含有积极情感词,但句子本身表示消极情感。不使用门控操作的MG-CNN模型因为无法保留句子中上下文的依赖关系,所以无法正确识别文本的情感极性。而使用多样化信息输入的MCCNN模型和结合门控操作的MG-GCNN模型通过对文本信息依赖关系的学习,都能正确识别文本的情感极性。样例5属于具有反问表达的句子,这类句子结构普遍比较复杂,所以MCCNN和MG-CNN模型都无法正确识别这类句子的情感极性。而MG-GCNN模型通过多粒度的信息输入,可以挖掘更深、更细腻的情感信息表达,从而可以有效判别文本的情感极性。
3 结束语
基于卷积神经网络和门控操作,本文提出一种MG-GCNN模型应用在中文微博情感分析任务中。在不使用外部特征的情况下,所提出的MG-GCNN模型在不同数据集上的多组实验中都取得了最好的分类效果,从而验证了该方法的有效性。同时通过对经典样例的对比分析,进一步分析了MG-GCNN模型在中文微博情感分析中的优势。本文在实验中仅使用了词语和单字粒度的特征信息,没有考虑文本中的情感词语特征,在后续研究工作中将进一步研究如何将所提出的模型和情感信息相结合。
