基于深度强化学习的文本相似语义计算模型
2020-08-25陈观林侍晓龙翁文勇
陈观林, 侍晓龙, 周 梁, 翁文勇
(1. 浙大城市学院 计算机与计算科学学院 浙江 杭州 310015; 2. 浙江大学 计算机学院 浙江 杭州 310027; 3. 杭州市大数据管理服务中心 浙江 杭州310020)
0 引言
语义相似计算是机器进行语义理解的一种手段[1-2],通过相似类比从而让机器能间接地理解问题。语义相似计算应用十分广泛,比如百度问答系统、新闻推荐领域等。
相比于传统的基于统计的语义相似计算模型,基于机器学习和深度学习的语义相似计算模型能更加细致地表达句子的语义特征和结构特征,比如词向量[3]、长短时记忆网络(long short-term memory, LSTM)模型[4]。这些语义特征模型存在一些深度学习模型的通病,比如长短时记忆模型虽然是专门用来处理时序模型的,这种模型可以较好地表达句子的结构信息,但是它在处理长句子过程中会因为反向传播算法而带来梯度消失问题,从而丧失很多语义信息,尤其是句子靠前部分的词语信息,因为梯度很难传到靠近前面词语的位置。
深度学习的快速发展促进了词义、语义理解方面很大的进展,比如Word2vec[5]、LSTM等对语义特征提取有很好的表达方式。词向量模型的出现很好解决了词义级别上的表达,通过收集大量语料库可以很好训练出词与词之间的关系表达,词义关系通常体现在其词向量的空间距离上的关系。LSTM模型主要是循环神经网络的改进模型,用来解决具有时序相关性的问题。通过使用LSTM模型提取句子语义信息,可以很好地表达句子结构上的信息,然后映射到固定向量特征中,通过计算向量的距离来表示相似程度,这是比较主流的处理方式。卷积神经网络(convolutional neural networks, CNN)在图像处理领域取得了巨大成功,很多研究人员把CNN当作语义特征抽取的一种方式,将句子的词向量拼接成句子矩阵,使用CNN网络卷积转化为语义矩阵,通过池化等方法从语义矩阵抽象出语义向量,计算向量的余弦距离或者欧氏距离等。注意力模型对图像和自然语言处理的深度学习模型有重要的影响,注意力模型可以用于LSTM等模型当中,缓解模型的语义丢失现象。
深度学习的语义计算模型一般是基于Siamese[6]模型,Siamese网络本质上也是解决降维问题,将句子的语义映射到一个低维的向量空间。LSTM Siamese Network网络[7]是Siamese 网络的一个实例框架,以单个字符作为输入单元,用LSTM网络来代替Siamese网络的函数,通过LSTM来提取特征得到一个固定长度向量,然后通过全连接层后抽取两个样本的最终特征作为计算距离的向量,采用余弦距离表示语义相似程度。Siamese LSTM模型[8]最大的亮点是使用了曼哈顿距离来衡量句子语义相似程度。最近在斯坦福数据集中表现较好的是DRCN[9]模型,该模型将前层的特征拼接到下一层,从而可以长时间保留前层的信息。
Information distilled LSTM(ID-LSTM)[10]模型将强化学习算法和LSTM结合用于文本分类任务,通过训练一个蒸馏网络将句子中非重要词蒸馏出去。为了判断蒸馏网络模型好坏,引入强化学习的策略梯度算法,LSTM抽取后的语义特征输入到分类网络当中进行文本分类,并且使用分类网络输出的结果作为回报值来更新蒸馏网络模型。
本文基于Siamese Network模型,加入强化学习的方法,通过一系列句子词语蒸馏的方法,将句子中不重要的词语蒸馏出去,从而可以改善LSTM进行语义提取过程中对重要的词语学习不到的问题,实验结果表明该方法对中文句子有不错的效果。
1 DDPG算法
深度确定性策略梯度算法(deep deterministic policy gradient,DDPG)[11]是一种强化学习算法,使用策略梯度方法[12-13]来更新神经网络的参数。DDPG算法有策略网络Actor和估值网络Critic两个部分组成:Actor是动作执行者,输入的是环境特征,输出的是动作;Critic输入的是环境特征以及策略网络输出的动作,而输出的是评判该Actor最终能获得总回报值的期望。同时为了解决策略更新过程中神经网络收敛不稳定情况,DDPG算法在更新梯度的时候使用了软更新的策略,在训练过程中定义在线网络和目标网络,并不是直接将在线网络复制给目标,而是以微小的更新量更新给目标网络,这样可以使训练过程更加稳定。DDPG网络算法步骤如下。
1) 初始化Actor和Critic的在线网络和目标网络。
2) 将在线网络参数拷贝给目标网络。
3) 循环以下步骤:
① 在线的Actor会根据传入的环境st执行动作at;
② 执行动作以后获得一个回报值rt,并且更新新的状态st+1;
③ 将这个过程中的st、at、rt、st+1存储到一个缓冲区中;
④ 互动多个过程后,从缓冲区采样然后训练Critic网络,采用传统Back Propagation的更新方式;
⑤ 采用策略更新的方式更新Actor;
⑥ 采用软更新的方式将在线的参数更新到目标网络当中。
2 算法设计
2.1 模型总体结构
本文将强化学习算法和Siamese LSTM模型进行融合,训练出具有一定自动蒸馏句子能力的语义相似计算模型,模型的整体结构如图1所示。

图1 模型整体结构Figure 1 The overall architecture of the model
模型的整体结构是一个强化学习的模型,类似于DDPG算法模型,有两个组成部分,最外围的策略网络是句子蒸馏网络模块,该网络使用多层深度神经网络模型,可以看成是一个Actor网络。内层的整体架构是一个Siamese LSTM模型,可以看成是一个Critic网络,Multi-LSTM使用了两层的LSTM模型叠加,并且在第二层LSTM模型的隐藏层输出加入Attention模型来加权语义,最终将提取的语义向量用曼哈顿距离来表示语义相似度。模型的训练模式也和DDPG算法相似,Actor网络部分和Critic网络部分分别训练,内部的环境模型通过反向传播算法(back propagatio,BP)[14]来更新,外部的策略网络根据环境的损失值使用策略梯度来更新。
2.2 句子蒸馏网络模型
句子蒸馏网络是由策略网络和Multi-LSTM网络组成的结构,Multi-LSTM是环境模型的一个组成部分,用于句子的语义抽取,是环境和Actor交互的唯一接口。Policy Network模型就是Actor网络,模型的详细表述如图2所示。

图2 句子蒸馏网络模型Figure 2 The network model of sentence distillation
图2(a)是Multi-LSTM模型,包含两层的LSTM网络,图2(b)是Policy Network模型,是一个两层的神经网络模型,其中{w1,w2,…,wt,…,we}表示每个时刻输入句子的词向量,{S1,S2,…,St,…,Se}表示每个时刻细胞的状态,初始时刻将LSTM细胞初始化为0,{h1,h2,…,ht,…,he}表示每个时刻LSTM的隐藏层输出,{a1,a2,at-1,an}表示每个时刻Policy Network的输出动作值,当词向量输入到LSTM模型当中的时候,都会先将LSTM细胞当前的状态和隐藏层的输出以及词向量合并成状态St,St=St-1⊕ht-1⊕wt。
将第一层LSTM细胞当前状态和隐藏层输出以及词向量合并成状态St后,将状态传入句子蒸馏网络判断当前传入词是否应该被保留,如果判断保留就将词向量传入第一层LSTM模型当中进行计算,如果判断不保留则跳过当前词。同时将采用两层的LSTM模型来进行语义特征提取,通过句子蒸馏网络可以将一个长句子中的非关键词去掉,从而保留句子的核心词语,使得语义相似判断效果更好。
2.3 协同注意力加权模型
协同注意力是一种相互加权的机制,是一种软注意力的加权方式。LSTM的第二层输出每个时刻的语义信息。将这些语义信息进行相互加权,其中两个多层的LSTM模型的权重可以根据输入的文本类型来决定是否共享参数。模型的结构如图3所示。第二层的{H1,H2,…,Ht,…,He}输出状态传入加权模型当中进行加权。协同注意力模型的内部加权方式有很多种,比如可以直接将两个多层LSTM模型的最高层生成的每个时刻语义矩阵直接进行相乘,然后经过Softmax函数来生成权重信息,也可以用额外的语义矩阵进行加权,如图4所示的加权方式,其中H1和H2表示LSTM的第二层隐藏层输出拼接成的语义矩阵,Ws是一个L×L加权矩阵,H1是一个L×n形状的矩阵,H2是一个L×m形状的矩阵,进行矩阵操作运算:

图3 Co-Attention加权模型Figure 3 The Co-Attention weighted model
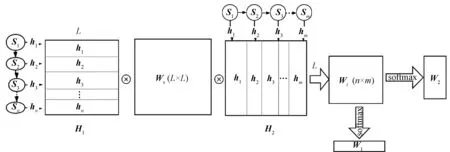
图4 Co-attention加权方式Figure 4 The Co-attention weighted method
经过运算可以获得一个n×m的权重矩阵,然后将每行的参数同样相加,并将每列的参数相加,经过Softmax函数进行归一化后,可以分别获得H1语义矩阵和H2语义矩阵的每个时刻分别对应的语义权重向量,最后将各自的权重向量和语义矩阵相乘可以获取最后句子的语义向量。
单个的加权矩阵往往会加权语义矩阵中的某一个方面,我们为了获取语句更丰富的语义信息,使用多个加权矩阵来对LSTM每个时刻输出的语义进行加权,生成多个权重向量。为了避免多个权重矩阵最终生成的权重矩阵相同从而失去丰富性,在最终的函数当中会定义一个正则项,正则项的推导如下。

2.4 损失函数设计

2.5 模型训练设计
算法整体的流程和DDPG算法流程类似,有在线和目标网络两个部分,依据策略更新的方式更新网络。模型在训练过程中不容易收敛,会因为参数大小或者参数的递减策略设置不正确等原因使整个模型达不到理想的效果。为了使训练过程更加稳定,我们将使用高策略的更新方式来更新网络。高策略更新方式定义在线和目标两组网络,两组网络的结构完全相同,但是更新时间不同。在每个批量训练之前要将目标网络的参数赋值给在线网络,然后用在线网络作为训练网络来参与整体的训练,并且在一个批量当中进行每个样本的更新,当一个批量训练完毕后,要将在线网络当中的参数更新到目标网络上,更新方式使用的是软方式,即设置一个参数β,则最终更新到目标网络上的参数为Targetθ=(1-β)Targetθ+βOnlineθ。
最后在下个批量训练开始之前,将目标网络的参数再次赋值给在线网络进行下一轮的训练,同时本文将采用曼哈顿距离来表示句子之间相似性,损失函数采用对比损失值作为训练。
在训练过程中还用到一些训练技巧,比如在强化学习训练过程中,当要学习的环境很复杂的情况下,开始训练收敛过程会很慢,或者很可能不会收敛,因此会有一个预训练的过程。预训练过程可以认为是模型学习环境的一个初始的合理参数的设置过程。对于句子蒸馏网络的预训练部分,由于本文后续实验采用数据的中文词汇特殊性(句子的前几个词非常重要),一般将句子的前几个词组保留,后面的词组以一定的概率随机蒸馏出去。
3 数据与实验分析
3.1 实验数据
本论文的实验数据使用的是网络爬取的数据,包括一整套汽车名称数据、汽车的配件信息以及售后信息等,用户同样会提供他们收集的汽车信息的数据库,我们要将这两个数据库的信息进行整合,使得相同型号的汽车信息能被整合到一起。但是用户提供的汽车名称和本文数据库中的汽车名称不完全相同,如表1所示,该表是部分本文标注好的数据,右边是本文数据的命名标准,左边是用户的数据库。可能会有型号上的描述不一样,通过语义相似计算的方法将用户提供的名称和数据库中的车辆名称做一个相似性匹配,从而确定是我们数据库当中的哪个型号的车,然后将所有的数据进行整合。实验数据有6万多对已经标注的配对的数据,训练和测试数据集比例为5∶1。在生成训练数据过程中要1∶2随机生成负样本,对于每一对标注的语句对,随机从样本数据中选择非配对的句子作为负样本。

表1 数据命名标准Table 1 The standard of naming data
3.2 词向量训练
本文使用gensim工具来训练Word2vec的词向量,gensim是一个python库,能实现很多常用自然语言处理的算法,比如latent semantic analysis(LSA)、latent dirichlet allocation(LDA)等,首先使用数据库当中的所有汽车作为语料库来训练词向量,总量大概有1 000多万条数据。对数据库当中的词进行一些特殊符号及格式除杂后,使用jieba分词工具对汽车描述名称进行分词,然后使用gensim工具进行中文的词向量训练。
3.3 多加权模型实验与结果分析
3.3.1模型的训练 本次实验是验证多加权协同注意力模型有效性,该模型主要在Siamese LSTM上实现,加权方式会定义额外的加权矩阵进行语义的加权,具体结构参考2.3节。首先是3个Co-attention模型,3个模型的不同点是加权矩阵的数量不同。训练的两个模型的参数如表2所示。

表2 Co-attention模型参数Table 2 The parameters of the Co-attention model
两个模型都使用Siamese LSTM架构和两层的LSTM来计算输入句子的语义信息。输入句子长度大于30的句子将被采用截断处理。输入句子的长度小于30的句子使用特殊字符填充。每次输入一个Batch进行训练。句子之间的相似度采用曼哈顿距离来表示,损失函数使用对比损失函数来计算。最后使用Adam优化算法[15]来调整参数。
3.3.2实验结果分析 本次实验主要是验证多加权的注意力模型效果。试验结果表明:当加权矩阵从1个矩阵变成3个矩阵,并且使用一定正则项来训练以后,准确率有明显提升,从0.85提升到0.87;但是从3个加权矩阵上升到10个加权矩阵的时候,实验效果提升的幅度明显小很多。由此我们可以看出,多加权的注意力模型相比于单个加权模型来说有一定的提升效果,但是当加权矩阵过多的时候,提升就很小,同时也会增加很多计算量。
3.4 基于句子蒸馏语义计算模型实验分析
本次实验选取测试数据中用户数据库命名的数据作为原始数据,设置阈值为0.5,对于每个用户的汽车名称,和我们数据库的汽车名称作相似性计算,大于0.5的作为相同车名备选项,然后把相似值排序后选出最相似的一个作为最终的相似车型名称。本次实验使用Siamese LSTM模型作为对比模型,最终试验结果在测试数据集下,我们提出的基于强化学习的模型相较于Siamese LSTM模型准确率从91%上升到95.7%。
由于训练数据不够充分,所以训练出来的蒸馏模型对于部分句子蒸馏出的信息比较多,比如必要的汽车名称或者一些车型的具体型号被蒸馏出去,导致相同车型的车名称计算相似性时值会很小,从而被丢弃,所以召回率会有一些损失,从100%下降到96%。但是蒸馏模型能够蒸馏出去一些非必要的词语,比如像“商务型”等修饰词,可以使得语义抽取更加简练,能够突出重点信息。而非蒸馏的模型,可能会受汽车名称中过多的无效或者是错误的修饰性词语的干扰,比如我们用户数据库有一个汽车为“骏捷SY7182UZ 1.8T AT(200603) 骏捷1.8T AT舒适型轿车”,我们的车型库的数据里有“中华SY7182UZ轿车 骏捷1.8T 自动挡 尊贵型”和“中华SY7182US轿车 骏捷1.8T 手动挡 舒适型”,在Siamese LSTM模型计算下后一个会比前一个相似性还高,这样的情况在样本数据中大量存在。但是判断是不是同一辆车一般只需要车名和紧接着车名后面的车型号就能唯一识别出来,因此蒸馏模型可以一定程度地将后面修饰的蒸馏出去,因此会增加模型判断的准确率。
表3为句子蒸馏前后的效果,其中第1列是原来的汽车名称,第2列是经过分词工具分词后去除特殊符号后的模型输入数据,第3列的是蒸馏后的效果。虽然训练数据不足,但是可以看出句子蒸馏模型会对句子中一些不太重要的修饰性词语蒸馏出去,基本上会保留主要的汽车名称以及必要的汽车统一型号名称,这些信息是识别汽车唯一性的充要条件。但也会导致比如排量、年份等信息丢失,这与具体的训练数据不足有关。

表3 句子蒸馏效果Table 3 The sentence distillation results
4 总结
本文将深度学习算法和强化学习算法结合起来研究,通过使用强化学习算法来改善LSTM模型提取语义时可能的语义丢失现象,在语义相似计算模型Siamese Network上取得了很好的效果。但是本文的模型仍然存在一些问题:由于模型是采用强化学习方式训练,LSTM提取的语义很复杂,模型要想收敛比较好就需要大量的采样,从而大大增加训练的时间,否则很容易陷入局部最优;另外,测试使用的场景和数据有限,只是在比较小的项目数据集上测试,对于很多其他场景的应用没有测试。
