基于动态文本窗口和权重动态分配的中文文本纠错方法
2020-08-25黄改娟王匆匆张仰森
黄改娟, 王匆匆, 张仰森,2
(1. 北京信息科技大学 智能信息处理研究所 北京 100101; 2. 网络文化与数字传播北京市重点实验室 北京 100101)
0 引言
随着人们从纸质书写转变为键盘输入,写作效率不断提升,但产生的中文文本错误影响了人们对语言的理解效率。在中文文本错误中,虽然大多数人能根据自己的经验去推测原来正确文本的含义,但是对于那些刚开始学习汉字的人群以及对文字准确度要求很高的出版社来说,这种细微的错误不仅体现了人们对工作的态度,还体现出人们对文字的重视程度。因此,中文文本的纠错不但具有丰富的需求背景,而且它还是自然语言处理领域中重要的基础问题。目前,依靠人工纠错文本不但费时费力,还可能导致二次错误。实现中文文本的自动纠错将会节约编辑或审稿人的时间,从而实现更精准的人工文本纠错,对教育出版行业以及办公自动化将产生深远影响。在文本错误类型的分类上,当前研究者们主要从字词的拼写错误、词语搭配不当以及文本语义准确度入手,文本的自动纠错方法则是基于N元文法、散串和语义检测的纠错方法。本文模拟人工纠错时的阅读过程,提出了基于动态文本窗口的文本自动检错算法。此外,在已有词典的基础上,使用基于最小编辑距离并具有权重动态分配功能的纠错算法体现了纠错词语选取的合理性。
1 相关工作
1.1 中文文本错误类型
中文文本错误类型可分为字词层面的错误[1]、语法层面的错误、语义层面的错误。在这三个层面中,字词层面最为基础,语法层面其次,语义层面最接近语言的思维表达形式。另外,这三个层面的联系可体现为:字词层面错误会导致整个词语的词性变动或者产生错词,从而使语句在语法层面不符合语法规则,进而引起语义模糊的问题。因此,字词层面的错误也会牵扯到语法和语义层面,可见字词层面的纠错是文本纠错的基础。文献[2]将字词层面的错误分为错字、多字和漏字三类。此后,文献[3]定义了“真多字词错误”和“非多字词错误”。“真多字词错误”的定义源自于语句的分词结果中没有任何错词,但是这些词语会与相邻词语产生搭配不当的关系;“非多字词错误”即分词结果中包含了由单字组成的词语所引起的文本错误。
1.2 中文文本纠错方法
1.2.1基于N元文法的文本纠错 基于N元文法的纠错方法根据Markov随机过程理论,针对字词的参数空间过大而产生的数据稀疏问题[4]简化N的大小,即当前状态仅与前面有限数量的状态有关,以此类推,判断整个语句的通顺程度。由于中文句子的书写规范常常受字词之间搭配习惯的影响[5],因此基于N元文法的纠错方法主要利用了字词的前后接续程度[6]、互信息[7]、共现频率[8]等文本的相关信息提供纠错建议。
1.2.2基于散串的文本纠错 散串是指文本经分词后连续出现的零散字符串,文献[9]把散串区间作为错误的初始范围。文献[10]统计了基于散串的查错效果,指出错误文本被分词后所产生的单字、双字以及多字串的概率为90.3%。文献[11]使用散串纠错文本,纠错过程分为错误定位和错误矫正两步。错误定位采用了统计字词搭配度和统计句子语法架构的方法定位错误位置,其中统计搭配度的错误定位方法主要针对五笔字型和拼音两种类型的输入法,统计语法架构的错误定位方法则是将统计法获取的错误位置再使用语法规则进行精准定位。错误矫正则采用传统的人机交互法,由系统提供候选纠错词供用户选择。
1.2.3基于语义检测的文本纠错 文本语义错误的自动纠错属于文本纠错研究领域较难解决的问题[11]。在语义错误查找方面,一般方法是通过词语搭配知识库进行查错。文献[12]统计了大量语义搭配实例,并构建语义搭配规则库用以检查语义级错误。文献[13]首先以《现代汉语实词搭配词典》和知网为基础建立了语义搭配知识库,然后结合证据理论解决了纠错词选取的模糊性问题。文献[14]认为,真词错误存在的原因主要是词语语义表达不符合词语搭配习惯,因此提出了专门面向真词错误的易错词集、在特定词语语境下词语的泛化模型和常用语言模型结合词语使用规则的真词错误自动纠错方法。
2 基于动态窗口的文本查错方法
2.1 基于动态窗口的文本查错思路
人们在阅读文本时,注意力的视野集中范围是不断向后移动的,尤其是在精读的情况下大都在看文本中的几个字,有时还会向前面观察一遍再联系后面的文字体会文本的语义。依据这种阅读特点,首先采用动态文本窗口的方法来模拟人们在阅读时注意力的变化范围,然后在此范围中,从中心向前展开计算文本搭配的合理程度,再将文本窗口不断地向后移动以检测后面的文本。在文本查错过程中,距离更近的字词则是依靠缩小窗口的方法检测字词方面的正误。随着窗口的缩小,文本里真正的错误又可能是由后面文本所导致的,于是采用拓展窗口的方法确定具体错误的位置。
2.2 动态窗口的相关定义
2.2.1动态文本窗口 假设文本语句可被T={c1,c2,…,ci,…,cn-1,cn}表示为一种文本的窗口,语句长度为N,最小为1。以某个字ci(i=1,2,…,n)为中心,在它左右相邻的n个字符上建立一个宽度为2n-1的动态文本窗口,表示为Winn(ci)={ci-n+1,…,ci-1,ci,ci+1,…,ci+n-1}。当ci的i=0时,Winn(ci)={ci,ci+1,…,ci+n-1};当ci的i=n时,Winn(ci)={ci-n+1,…,ci-1,ci}。
2.2.2动态窗口缩小 当窗口大小从N缩小为N-1时,表示为Winn-1(ci)={ci-n+2,…,ci-1,ci,ci+1,…,ci+n-2}。当ci的i=0时,Winn-1(ci)={ci,ci+1,…,ci+n-2};当ci的i=n时,Winn-1(ci)={ci-n+2,…,ci-1,ci}。
2.2.3动态窗口后移 窗口为N,中心字符为ci时,窗口后移表示为令ci=ci+1。
2.2.4动态窗口拓展 窗口为N,中心字符为ci时,经拓展后的窗口表示为WinnExt(ci)={ci-1,ci,ci+1,ci+2}。
2.2.5动态窗口包含文字的前项概率 窗口为N,中心字符为ci时,ci的前项概率表示为
式中:N(ci-n+1,…,ci-1,ci)表示在训练语料中字符串{ci-n+1,…,ci-1,ci}出现的次数;N(xi-n+1,…,xi-1,xi)为任意n长度的字符串{xi-n+1,…,xi-1,xi}在训练语料中出现的次数。
2.2.6动态窗口包含文字的后项概率 窗口为N,中心字符为ci时,ci的后项概率表示为
式中:N(ci,ci+1,…,ci+n-1)表示在训练语料中字符串{ci,ci+1,…,ci+n-1}出现的次数;N(xi,xi+1,…,xi+n-1)为任意n长度的字符串{xi,xi+1,…,xi+n-1}在训练语料中出现的次数。
2.3 基于动态窗口的文本查错算法
基于动态窗口的文本查错算法的具体步骤如下。
Step 1: 将文本分句,去除标点及特殊符号。
Step 2: 若仍有句子未被检测,算法继续。否则,算法结束。
Step 3: 以待查字符c为中心,构造大小为3的动态文本查错窗口Win3(ci)={c-2,c-1,c,c1,c2}。
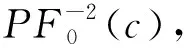
Step 6: 如果左侧相邻字符串{c-2,c-1,c}存在易混淆词库中,则选择易混淆词集处理,然后转向Step 5。否则,转向Step 7。
Step 7: 使用大小为2的窗口检查{c-2,c-1}是否存在错误。如果是,则输出错误字符,转向Step 8。否则,转向Step 10。
Step 10: 缩小查错文本窗口大小为2,Win2(ci)={c-1,c,c1},重复Step 11~14。
2.4 用于查错的聚类词平滑策略
聚类词的概念是把近义词、同义词和一些可以互换使用的字词作为同一个词来对待。将这类可以在同样语境下使用的词语当作同一种词,不但符合文本的常用表达方式,而且减少了查错模型因数据稀疏而导致的误报率。表1列出了部分聚类词。聚类词库的使用方法为:假设待检测动态文本窗口的文本出现次数小于常用文本阈值,并且该动态文本窗口内的文本包含某些在聚类词库的词语,于是将词库中与待检测词语聚为一类的词在当前窗口内文本语境下所出现的概率累加到待检测动态文本窗口,然后再次检测此处动态文本窗口内是否包含错误。

表1 部分聚类词Table 1 Partial clustering words
3 基于权重动态分配的纠错方法
3.1 纠错词集的构建思路
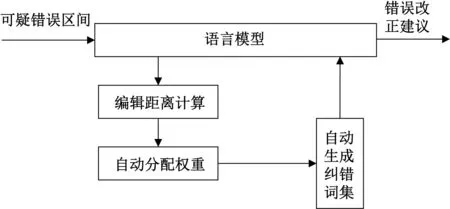
图1 基于权重动态分配的纠错策略示意图Figure 1 Schematic diagram of error correction strategy based on dynamic weight allocation
考虑到语料库中99.48%的字为常用中文字符,约有3 700多个,因此本文构建了基于常用高频字集的候选纠错词集。假设动态文本窗口的大小N,考虑到计算纠错词集所需的时间复杂度和空间复杂度较高,因此设定动态文本窗口长度为3,采取促使局部文本出现概率最大化的方式获取纠错词。在纠错词集的权重分配方面,采用动态文本窗口内疑似错误和前后文本的词语组合长度作为纠错词的权重,建立基于最小编辑距离的纠错词集。图1为基于权重动态分配的纠错策略示意图。首先对文本中的疑似错误词语建立相应的纠错词集,然后计算每个纠错词与系统词典的最小编辑距离,将系统词典中与纠错词编辑距离最小的系统词的长度作为纠错建议的权重。
3.2 基于纠错词权重动态分配的纠错算法
基于纠错词权重动态分配的纠错算法的具体步骤如下。
Step 1: 设动态窗口的文本为T={…,c-2,c-1,c0,c1,c2,…},系统词典为D。
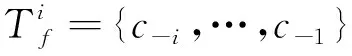
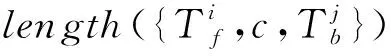
4 实验结果与分析
4.1 中文文本错误的查错
从日常报纸杂志的100篇文章中收集了500个人工校对好的标准句子,其中包含220个文本错误。表2为多种文本检错策略的实验结果。当仅使用窗口大小为3的检错方案时,检测文本错误的召回率为68.2%,准确率为58.5%。当添加窗口缩小策略改进检错方案后,检错的召回率下降了8.2%,准确率提高了12.4%。主要原因是对文本采取更加细粒度的检错方案降低了原本较大窗口产生的文本数据稀疏的出现概率。当使用添加窗口缩小和窗口拓展策略的检错方案时,检错的准确率又上升了13.7%。主要原因是窗口下文的内容也被转移进来,相当于进一步考虑了上下文的语句搭配合理度。最后,综合前两种策略和聚类词平滑策略后,检错的准确率再次上升了3.3%,F值达到77.9%。实验结果表明,基于动态窗口的文本查错算法在很大程度上提高了文本自动检错的效率和可行性。

表2 多种文本检错策略的实验结果Table 2 Experiment results of multiple strategies for error detection
4.2 中文文本错误的纠错
在本文构建的数据集下比较了三种自动纠错方法,分别为本文的基于权重动态分配的纠错模型、传统的黑马校对系统以及文献[15]所提出的权重均分的纠错模型,通过人工鉴定这些方法所生成的纠错建议的合理度,并统计合理纠错建议的数量,纠错性能结果比较如表3所示。可以看出,传统的黑马校对系统首先检测出178个文本错误,被人工鉴定为合理的纠错建议有169个;文献[15]模型检测出170个文本错误,被人工鉴定为合理的纠错建议有155个;本文模型发现了193个文本错误,被人工鉴定为合理的纠错建议有177个,纠错准确率最高且耗用资源比最低,其中纠错准确率达到78.1%,比黑马校对系统和文献[15]模型分别提升了9.7%和15.8%,在实际应用上表现良好。

表3 纠错性能结果比较Table 3 Comparison on error correction performance results
5 结束语
本文以动态文本窗口对人们阅读文本时的注意力集中范围进行建模,实现了注意力集中范围的放大与缩小,并以中文词语的构词长度自动分配纠错建议的权重,实现了文本自动纠错模型。虽然目前的文字编辑工作中使用文本自动纠错技术能有效地降低一些文本错误所产生的不良影响,但是在文本的自动查错与纠错方面仍然需要进行更加深入的研究。在检错时,一方面还可以考虑语法和语义知识,另一方面还需要考虑语义知识库的建立与使用方法。除了基于知识库的方法外,还可以建立自动获取错误文本特征的模型。纠错建议生成方法可以全面地从篇章、段落、整句上使用自然语言推理技术推理出原文内容,这样能更加体现出纠错方法的科学性。
