基于机器学习的波束搜索算法设计
2020-08-23侯嘉智刘高路
侯嘉智,梁 晶,刘高路
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
毫米波通信作为解决频率资源紧张,提供更大带宽和更高传输速率的一项关键技术,在5G移动通信中得到了广泛的应用[1-2]。然而,毫米波波长短,在传输时路径损耗极大,传输距离很短。为了克服这一难题,5G移动通信中采用了大规模多输入多输出(Multi-Input Multi-Output,MIMO)技术来实现毫米波信号的远距离传输[3],改善信号传输质量,提升信号传输速率。
在波束搜索时,通常把信噪比或数据速率作为评价波束好坏的性能指标[4]。目前最常用的波束搜索算法为穷举搜索,即对发射机和接收机的所有波束进行遍历,选择最佳的波束接入[5]。这种波束搜索算法的时间复杂度很高。目前对波束搜索算法的研究大多集中在码本设计[4-6]和稀疏信道估计[7],且多为单基站单用户下的波束搜索,很少考虑多基站的场景。
针对上述问题,本文首先设计了一种符合城市密集基站和用户分布的系统级模型,然后在此基础上提出了一种基于机器学习的波束搜索算法,最后,通过仿真实验验证了该算法具有较高的搜索精度和较低的时间复杂度。
1 系统模型
系统模型生成了一个蜂窝状的网络布局,可根据需要配置不同的基站距离、基站和用户数量的参数,以适用于不同的信道场景[8]。用户在系统模型中服从均匀分布,根据基站和用户的位置坐标,可以得到用户与基站间的距离和方向等信息,用于后续计算。蜂窝网络的用户与基站位置分布如图1所示。
系统中的每个基站都由天线数目为8×8的均匀天线面阵(Uniform Planar Array,UPA)组成,用户端采用一根全向接收天线,基站向360°方向上依次发射64个定向窄波束,用户端通过全向天线搜索接收到的波束。
由表6的估计结果可知,在2002—2016年期间,我国地价和房价之间的作用关系存在明显的时序差异,而房价与物价之间的作用关系并无太大改变,其影响系数仅由0.0187降为0.0126,变动幅度不到0.01。2002—2010年期间,地价对房价的影响系数在1%的显著性水平下显著为正(0.1581),且房价对地价的影响系数也在1%的显著性水平下显著为正(0.9213);2010-2016年期间,地价对房价的影响系数在10%的显著性水平下显著为负(-0.1795),且房价对地价的影响系数也在10%的显著性水平显著为负(-0.0667)。
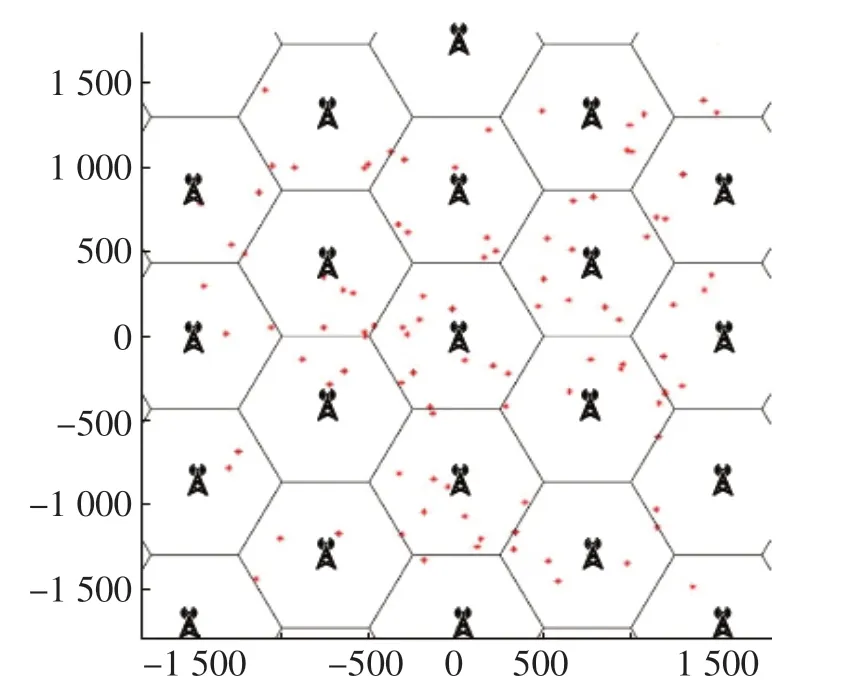
图1 用户与基站位置分布图
1.1 信道模型
在本算法的NN中,给定训练集D={(X1,y1),…,(Xk,yk)},Xk=)为第k条样本波束的特征向量,yk为第k条波束的样本标签,由0/1表示。因此,第1个隐含层第h个神经元的输入为=,νih为输入层与隐含层之间的权重,输出层的输入为βk=,wh为第3层隐含层第h个神经元到输出层的权重为经过3层隐含层后的输出。因此,NN的输出为
农村经济管理工作应采用信息化技术,创建电子商务平台,对外公开财务信息,人们可随时查询所需数据。电子商务平台有利于会计人员掌握财务处理技术,提高工作效率,使得农村财务管理更加规范化与高效化。
对于小尺度信道模型,采用Saleh-Valenzuela(S-V)毫米波信道模型[9]。毫米波信道是一种簇信道,信道由多个簇组成,每个簇l生成了一条信号的传播路径。本模型中,假设用户端使用了一根全向天线,因此接收端信道系数为1,信道矩阵H为
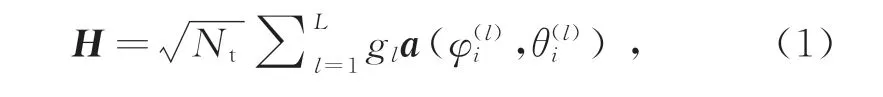
式中:Nt为发送端天线数目;gl为第l簇的小尺度信道增益,服从独立同分布的高斯分布;a)为发送端平面阵的阵列导向矢量,与分别为基站到第i个用户的第l条路径的水平方位角和垂直俯仰角。
1.2 波束模型
本节我们生成了一组波束样本,并用这组波束样本分别测试了随机森林(Random Forest,RF)模型、线性判别分析(Linear Discriminant Analysis,LDA)模型、K-近邻(K-Nearest Neighbor,KNN)算法、分类和回归树(Classification and Regression Tree,CART)、朴素贝叶斯(Naive Bayes,NB)模型、支持向量机(Support Vector Machine,SVM)及神经网络(Neural Network,NN)等分类模型的训练精度。图3所示为几种常用的机器学习模型训练精度的箱线图,由图可知,RF模型虽然存在异常值,但整体的训练精度最好。图4所示为使用NN模型进行500次迭代的训练精度曲线,可见NN损失函数在梯度下降到0.1时达到了最优值,NN模型要略优于其他机器学习模型。
方向性函数Dk(θi)表明用户处于第k条波束范围内,其值大小表示用户i相对第k条波束的法线偏离程度。图2所示为用户方向性示意图。
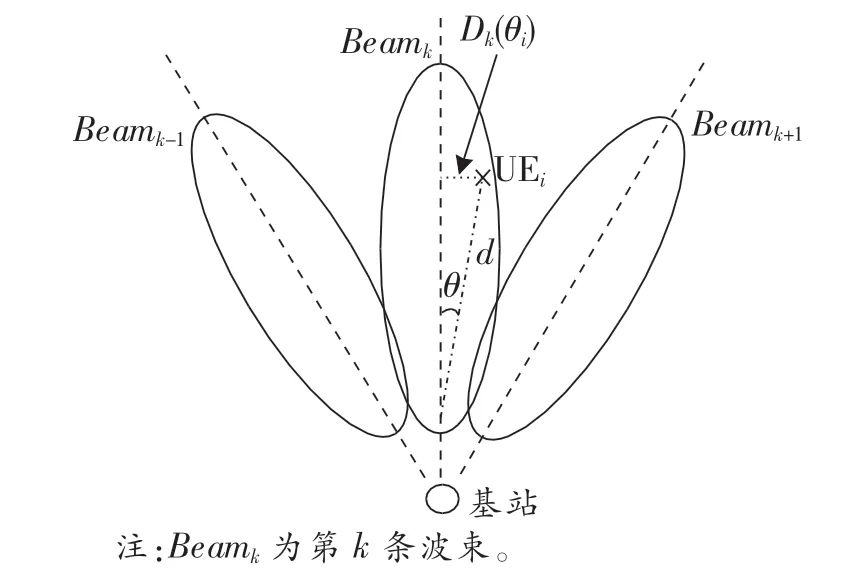
图2 用户方向性示意图
式中:Fk(θ)为方向图函数;θ为用户的方位角;分母积分为阵列波束覆盖范围。Fk(θ)表达式为
村落是中国传统乡村社会的基本单位。中国乡村延续了五千年的中华文明,是中华文化传播的有形物证和稳定载体,是中国传统农耕文化的发生地,是中华民族走向伟大复兴的自信之根、复兴之本。而当前我国城乡发展不平衡,城乡居民收入差距大,城乡基础设施建设差距明显,教育、医疗资源分配不均衡,农业农村发展总体滞后,这一现状已成为制约经济社会健康发展的短板。
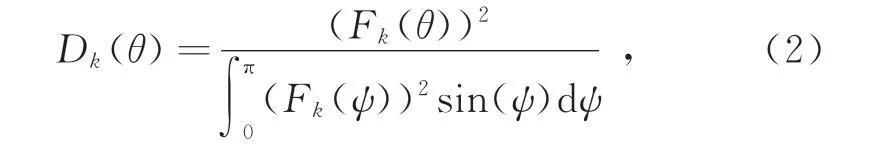
如图所示,在第k个波束Beamk的覆盖范围内存在一个用户UEi,UEi与当前服务波束的法线的夹角为θ,用户到基站的距离为d,由此可得任意波束k的方向性函数为
在本节中,我们将评估所提出的基于机器学习的波束搜索算法的性能。首先,介绍仿真参数设置;然后,比较所提出的基于机器学习的波束搜索算法和穷举搜索算法的性能差异,证明该算法在搜索精度接近于穷举搜索算法的同时,能大幅度降低算法复杂度。
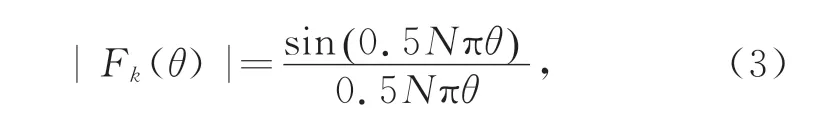
式中,N为天线的阵元数量。
通过上文对信道和波束的建模,我们得到了用于波束搜索算法的系统模型。本文中的波束搜索算法选择数据速率作为衡量波束性能好坏的性能指标,通过选择数据速率最优的波束来完成波束搜索[12-13]。
第k条波束的数据速率R(k)表示如下:
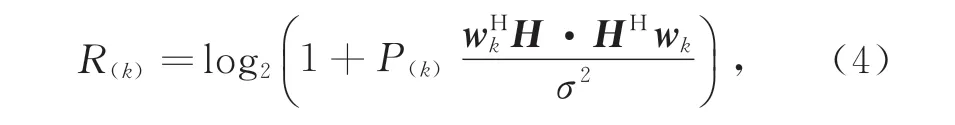
式中:P(k)为第k条波束的接收功率;wk为波束码本矩阵W中第k列的列向量,即第k列波束码本;σ为加性高斯白噪声的方差。用户选取数据速率R(k)最大的波束接入,完成波束搜索。
(2)假设零售商向制造商的产品订购量Q可以完全满足客户需求,即不考虑客户需求的不确定性。且Q=D-kPr+θS,其中D为市场规模,即当零售价格为零且没有物流服务提供时的市场需求规模;k为零售价格敏感系数,θ为物流服务水平敏感系数,当k>θ时,即客户对产品价格比对物流服务水平更敏感;当k<θ时,则含义相反。
2 基于深度学习的波束搜索算法
紫地榆活性成分对致龋菌生长和产酸影响的体外研究…………………………………王丽梅,杨晓珍,蓝 海(73)
基于机器学习的波束搜索分为两个阶段。第1阶段为训练阶段,采用留出法将波束样本分为训练集和测试集,划分比例为80%训练集和20%测试集。使用训练集对学习器进行训练,并通过测试集验证模型的性能,得到一个训练好的机器学习模型。第2阶段为预测阶段,使用训练好的模型对输入的波束进行分类预测,将其分为候选波束和非候选波束,对候选波束进行遍历搜索即可找到最佳波束。当使用训练好的模型进行波束预测时,主要的时间复杂度为对机器学习算法选出的候选波束进行遍历搜索的复杂度。可通过调整训练波束的样本标签来降低算法复杂度,具体过程如下文所述。
2.1 波束样本生成
我们根据系统模型生成的数据生成用于机器学习的波束样本。本文设计的系统模型包含19个基站,每个基站发射64条定向窄波束。因此,一组波束样本由19×64条波束组成,波束索引从1~1 216按顺序排列。提取了用户坐标、基站坐标、用户与基站间距离d、用户与波束夹角θ和波束码本矩阵W作为波束样本的特征。我们选择数据速率R前10%的波束作为好波束,其他作为坏波束,为波束样本添加标签,用于机器学习的分类训练。波束样本的波束标签会直接影响机器学习模型分类预测出的候选波束数目,进而影响波束搜索算法的精度和复杂度,因此,可以根据训练结果动态调整样本标签的划分,以达到算法精度和复杂度的平衡。
2.2 机器学习分类器选择
系统中采用了固定的离散傅里叶变换(Discrete Fourier Transform,DFT)波束码本,对于基站全向发射的64个定向窄波束,不同离开角的波束对于用户的增益也是不同的,如用户处于波束边缘和波束中央时所获得的接收功率不同。因此本文增加了波束的方向系数Di(θ),用于衡量波束对用户位置的方向性增益[10-11]。
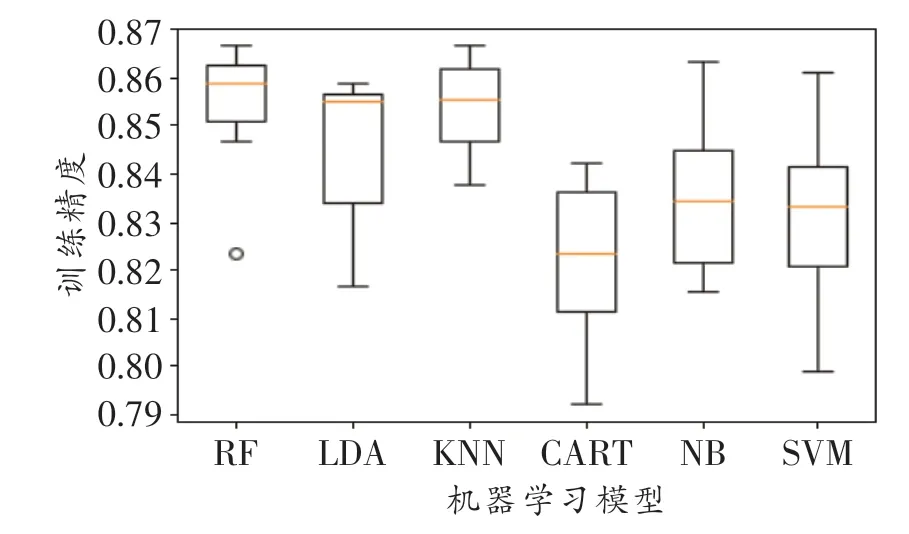
图3 几种常用机器学习分类模型的训练精度
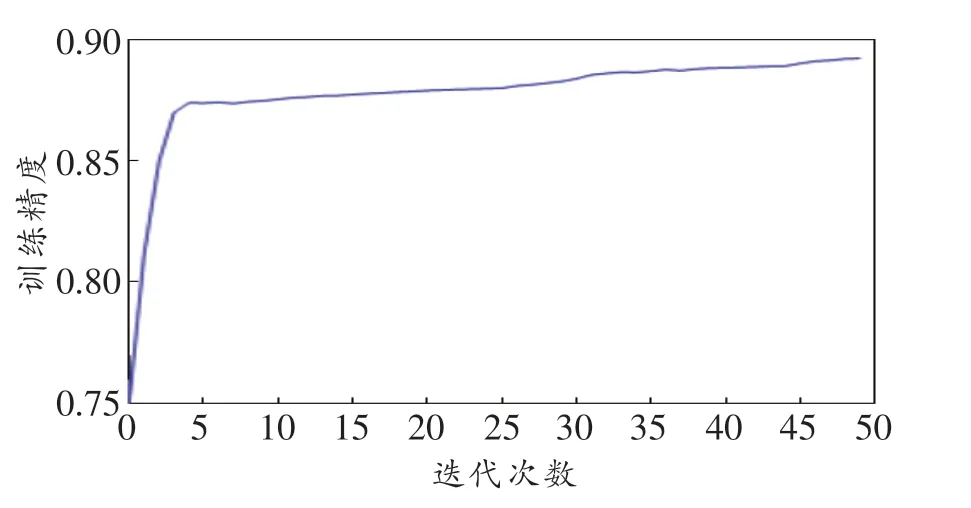
图4 NN模型训练精度
表1所示为使用相同训练样本得到的各分类器的平均训练精度。由表可知,NN模型的性能略优于其他机器学习模型,且NN对样本数据有更高的容错率,不需要进行繁琐的数据预处理,因此,我们选择NN模型作为该波束搜索算法的分类器。
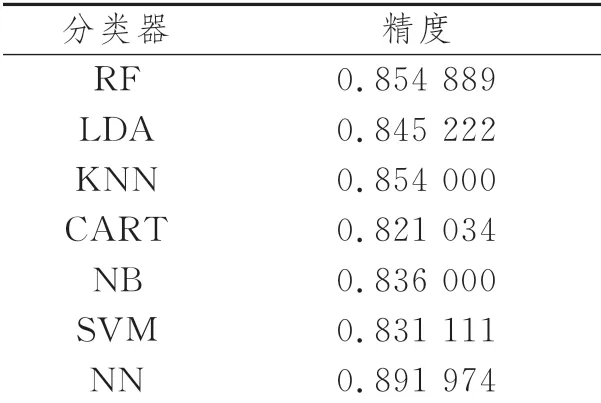
表1 各分类器的平均训练精度
2.3 输入的归一化
上文中我们测试了多种机器学习模型的性能,选择了NN模型。由于我们选取的训练样本特征包含多种不同类型的数据,其量级差别很大,因此首先需要对样本数据进行归一化。归一化的训练样本可以使用更高的学习率,并且模型受NN权重的初始化和训练样本异常值的影响较小,能提升模型的收敛速度[16]。
2.4 NN结构
为了避免过拟合问题,NN模型需要大量的训练样本。因此,我们随机生成了10组波束样本,即样本波束由1 216个增加为12 160个,其中8组作为训练集,2组作为测试集,采用Dropout算法来降低过拟合的问题。当训练样本较小时,选择过多层数的NN对性能的提升不明显,却降低了算法的收敛速度,所以我们采用了包含3层隐含层的反向传播(Back Propagation,BP)NN架构。图5所示为神经元及阈值判别,NN的隐含层为全连接层,每层都有q个节点。输入层和隐含层使用tanh激活函数,输出层使用sigmoid激活函数。每层全连接层后面都有一个Dropout,以确保正则化并避免NN过度拟合[17]。
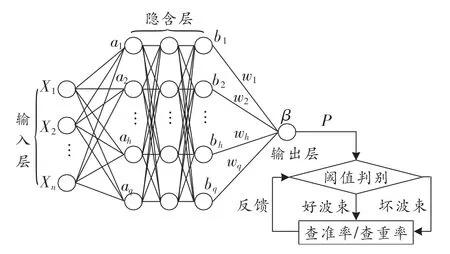
图5 神经元及阈值判别
系统中信道模型包括大尺度衰落和小尺度衰落。大尺度衰落主要包括路径损耗和阴影衰落,小尺度衰落主要是由多径传播和信道时变特性引起的。根据基站和用户网络布局可以计算路径损耗。系统模型可以配置农村宏蜂窝(Rural macro,Rma)、城市宏蜂窝(Urban macro,Uma)和城市微蜂窝(Urban micro,Umi)这3种场景下的视距(Line of Sight,LOS)/非视距(Non Line of Sight,NLOS)路径损耗及阴影衰落模型,以验证不同场景下的波束搜索算法性能。
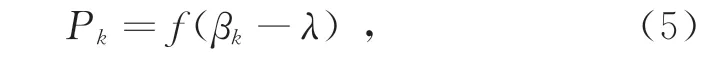
式中:λ为输出层神经元的阈值;f(·)为激活函数。
输出神经元的梯度为
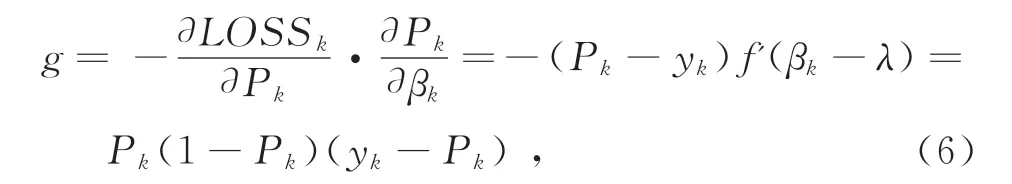
式中,LOSSk为NN输出Pk与实际值yk的均方误差。
目前,机器学习在图像处理等领域有着广泛的应用,它能够实现对数据准确的统计分类和回归分析[14-15]。因此,本文结合机器学习中的分类算法思想,设计了一种基于机器学习的波束搜索算法。该算法核心思想是通过环境参数(用户/基站位置、房间家具、街道建筑物和树木等)、码本信息及发送波束的初始角度信息对候选波束进行分类预测,以此搜索出最佳波束。
根据下降梯度g和设置的学习率η,可更新每次迭代后的NN各层权重及阈值,并通过均方误差损失函数计算训练精度。本算法设计的BP NN结构如图5所示,输出神经元使用sigmoid激活函数。图中x1~xn为输入层的神经元;a1~aq、b1~bq为各隐含层的神经元;w1~wq为隐含层到输出层的权重;β为输出层神经元的输入值;P为输出层神经元的输出值。对于训练样本Xk,NN的输出为一个在0~1之间分布的数,因此本算法设计了一个阈值δ来划分波束类别,若Pk≥δ,则该波束判别为好波束;否则为坏波束。对于NN的预测结果,我们引入了查准率和查全率作为性能度量,动态调整门限阈值δ,使NN的性能达到波束搜索算法要求的精度-复杂度平衡。查准率/查全率定义如表2所示。

表2 查准率/查全率定义
3 仿真结果
王祥一打听,原来老道这次也是下了不少本钱,不仅自己出钱帮忙租了这个摊位,而且还筹备了一批廉价的玉器用来打马虎眼。
在对企业创始人和高管团队的访谈过程中发现,产品上市前后的资源拼凑模式有所不同。通常,在产品上市前,企业面临着很大的市场风险,只能拼凑现有的手头资源,利用自身优势研发产品,开辟市场。在产品上市之后,企业自身的资源禀赋难以满足市场拓展的需要,急需外部资源的支持,并且随着企业的发展,积累的良好信用记录也为其通过社会关系网络获取外部资源提供了可能。因此,按照产品上市前和上市后两个阶段,进一步将涉及到资源拼凑模式的资料进行编码,如表6所示。
11月14日上午9点,在洪峰进入云南之际,云南电网公司召开紧急视频会议,传达了南方电网公司总经理曹志安“要把困难估计得大一些,把方案准备得多一些,做到有备无患。”的要求,并再次强调,相关单位和部门要做到认识到位、组织到位、措施到位、人员到位,进一步做好灾情监测、人员撤离、应急保电、抢修复电、灾后重建等工作。
3.1 仿真参数设置
本节中我们将分别验证算法在Umi和Uma场景下的波束搜索性能,Uma场景部署了7个基站,基站间隔为500 m,其余参数与Umi场景参数相同,参数配置如表3所示。
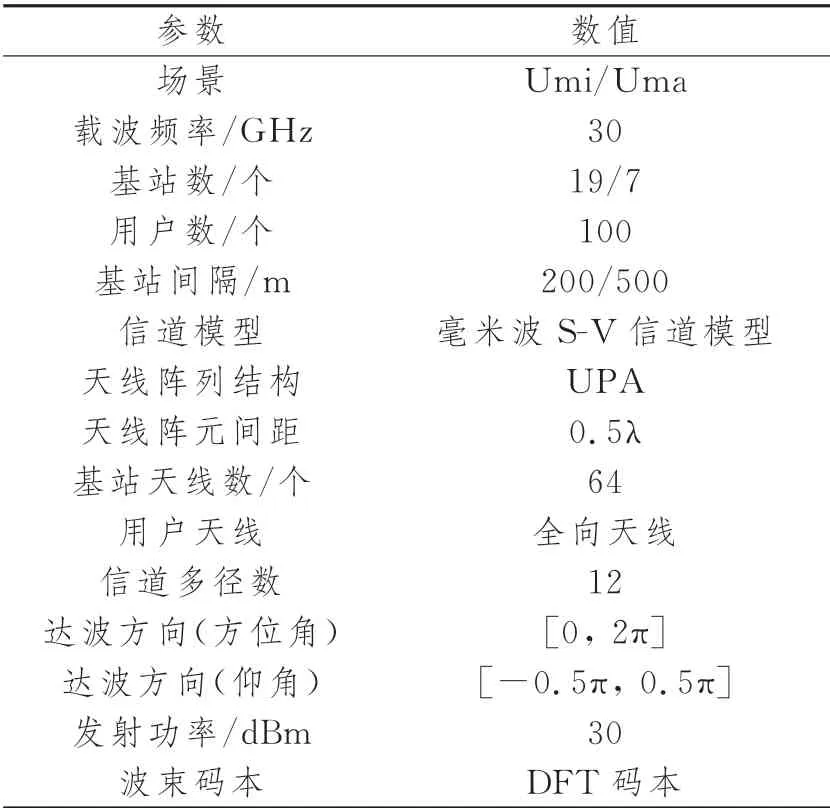
表3 仿真参数配置表
NN模型有3个全连接层,全连接层使用tanh激活函数,每层后面都有一个Dropout,Dropout rate:10%。为了训练NN模型,训练集使用了10组数据集,每组数据集包含1 216个波束数据,训练样本总数为1 216×10。在NN建模中,我们使用了Tensor Flow软件库[18]。
根据血管性痴呆(波动期)[1]的特点,临床主要表现为以脸上没有表情,感到头晕,喜欢睡觉并且不愿意动,痰和口水量变大,流口水,睡不着觉,也有大便困难,舌头发白或者是发黄等,痰变得浑浊,心血淤积且流通不顺畅,实邪慢慢变得很旺盛。也可能是时而头晕时而头痛,情绪不稳定容易生气,口水变的很多或者是说话不利索,身体经常发麻又或者是舌头黏腻这些现象。发现此期常见肝肾阴亏、风痰瘀阻等证候。临床灵活运用辨证论治,予益肾补髓化瘀涤痰汤,医治的结果很好,可以看到的就是变得聪明的一点,自理能力也变强了。现报告如下。
3.2 算法性能分析
本节对基于机器学习的波束搜索算法进行仿真,并与穷举搜索算法的性能进行比较。我们进行了50次独立的仿真实验,每次搜索1 216条波束,并根据样本标签调整候选波束的尺寸,分析不同候选波束尺寸下的搜索精度。图6所示为在Umi场景下,波束搜索算法在不同候选波束尺寸下找出最佳波束的概率,其结果为50次仿真实验的平均值。由图可知,算法找出最佳波束的概率随着候选波束的增加而增大,在候选波束为100时,找出最佳波束的概率趋近于1,此时算法精度已近似于穷举波束搜索算法的精度,而搜索的波束大小仅为穷举搜索算法的1/10。
机电一体化技术专业具有较强的专业特色,它是以实践为主的工科专业,在我们高职院校的课程设置中,有机械方面的基础知识,也有电气自动化控制等方面的专业知识。在新旧动能转换的经济形势下,创新和转型升级将成为中国现阶段经济发展的主旋律。企业也需要大量的能够在生产第一线从事现代机电设备安装、调试、维护、运行和管理工作的高技能型人才。这种高技能型人才的培养,就需要学校和企业共同参与,只有采用现代学徒制的培养模式,才能让同学们在校期间就能够有机会参与实践,将课本知识吃透并领悟并应用到生产实践中。也可以在生产实践中发现问题,利用所学知识进行解决和创新。
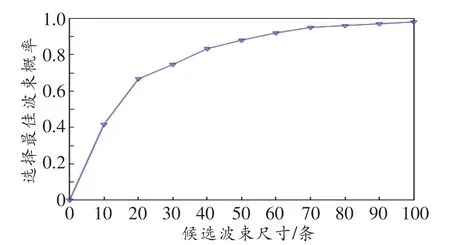
图6 基于机器学习的波束搜索算法在不同候选波束尺寸下找出最佳波束的概率曲线
图7~8所示为算法在不同场景下,基于不同候选波束尺寸的数据速率,其结果为50次仿真实验的平均值。由图7可知,本文提出的波束搜索算法在候选波束为10时,数据速率已接近于穷举搜索算法,并随着候选波束的增加而逼近于穷举搜索算法。由图8可知,算法性能在Uma场景下要优于Umi场景。因为Uma场景只有7个基站,仿真中每次最多需搜索448条波束,且基站间隔较远,临近小区的基站对用户的影响更小,所以在候选波束较大时,数据速率已达到了最大可达数据速率。对比图7与图8可知,本研究设计的波束搜索算法可以适用于不同的信道场景。
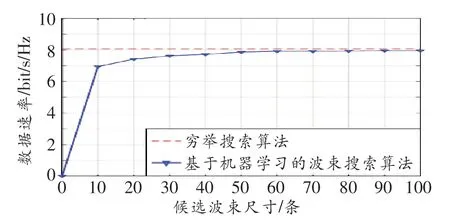
图7 Umi场景下算法在不同候选波束尺寸下的数据速率
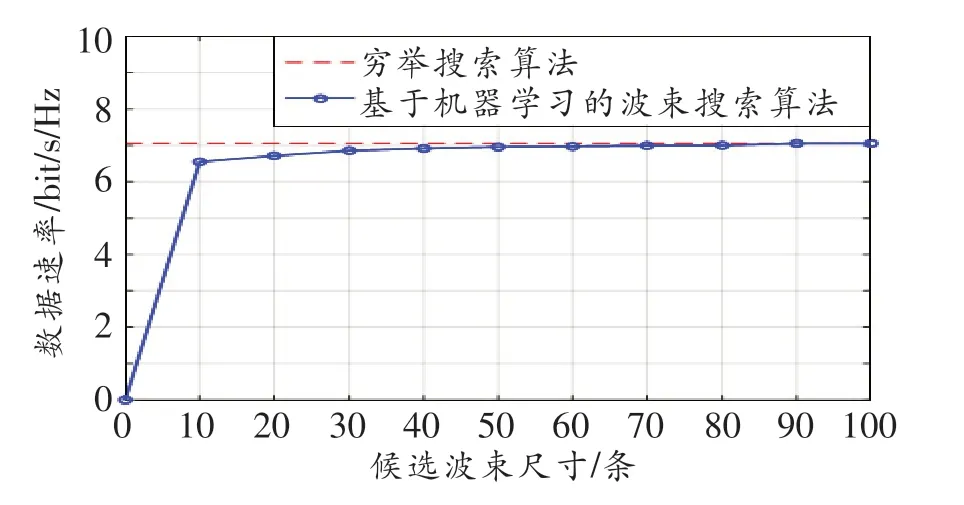
图8 Uma场景下算法在不同候选波束尺寸下的数据速率
由图6~8可知,本研究设计的波束搜索算法不仅在性能上接近于穷举波束搜索算法,同时还显著降低了算法的复杂度,而且适用于不同的信道场景。
4 结束语
目前,机器学习广泛应用于图像处理和人工智能等领域。由于在5G通信中很难获取满足于机器学习算法要求的大规模数据样本,机器学习在通信领域应用较少。因此,本文设计了一种多基站场景下的系统模型,用于提供机器学习所需的训练样本。在此基础上,本文介绍了一种基于机器学习的波束搜索算法,该算法通过NN对用户接收到的波束进行分类预测以找出最佳波束。研究结果表明,本文提出的基于机器学习的波束搜索算法在大大降低了算法复杂度的同时,算法性能接近于穷举搜索算法。由此可见,机器学习可以在解决5G通信中一些关键难题时提供一种全新的思路。我们目前只研究了配置一根全向天线的静态用户场景,在接下来的探究工作中,我们将进一步研究用户配置多天线且在运动场景下的波束搜索算法。
