基于政策文本计算的突发公共事件下中小企业扶持政策供需匹配研究
2020-08-19盛东方尹航
盛东方 尹航
摘 要:[目的/意义]突发公共事件中的政策需求方,是应急管理活动的重要构成角色之一。相应的政策供给是否与政策需求相匹配,关系着应急管理的成效。政策供需匹配研究拓展了政策文本研究的分析视角,为优化应急管理政策的科学设计,提升突发公共事件治理的精准度提供参考。[方法/过程]以新冠肺炎疫情为例,基于主题分布分析和关键词共现分析两条路径,采用融合了主题挖掘、文本分类和共现分析的政策文本计算方法,探究突发公共事件下中小企业扶持政策供需匹配问题。[结果/结论]金融支持类政策供需较为平衡,信息化征管和税费优惠类政策尚需加强舆论宣传,政务服务和物资保供类政策有待进一步增加政策供给。
关键词:政策文本计算;政策供需匹配;突发公共事件;新冠肺炎;中小企业
Abstract:[Purpose/Significance]The policy demander in public emergency is one of the important roles of emergency management.Whether the corresponding policy supply matches the policy demand is related to the effectiveness of emergency management.The research on policy supply-demand matching expands the analysis perspective of policy text research,and provides reference for optimizing the scientific design of emergency management policies and improving the accuracy of public emergency management.[Method/Process]Taking Novel Coronavirus Pneumonia as an example,based on the two paths of theme distribution analysis and co-word analysis,this paper used the policy text computing method which integrates topic mining,text classification and co-word analysis to explore the matching of supply and demand of minor enterprises support policies in public emergencies.[Result/Conclusion]The supply and demand of financial support policies were relatively balanced,public opinion publicity needed to be strengthened by the information collection and management policies and tax preferential policies,and policy supply needed to be further increase by the government service policies and material guarantee and supply policies.
Key words:policy text computing;policy supply-demand matching;public emergencies;Novel Coronavirus Pneumonia;minor enterprises
新型冠狀病毒感染的肺炎(以下简称“新冠肺炎”)疫情,给我国的经济社会生活带来了一定的冲击和影响。中小企业作为我国国民经济的重要支柱,囿于自身规模小、业务单一、盈利能力弱、抗风险能力低,其生产经营遭遇到严峻的挑战。为了切实缓解当前中小企业生产经营所面临的困难,确保经济的平稳健康发展,中央及地方政府积极寻求并密集出台了若干中小企业扶持政策,形成了一系列涉及财税、金融、社保等领域的政策文本。这为突发公共事件下的政策研究提供了资料。
政策文本指因政策活动而产生的记录文献,包括官方文献(如法律、法规、部门规章)、公文档案(如研究、咨询、听证或决议)、政策舆情文本[1]。从方法上来看,以往的政策文本研究存在着重规范分析、轻实证研究,重定性分析、轻定量研究的倾向[2]。随着自然语言处理、数据挖掘、知识可视化等数据处理技术的发展,大样本、细粒度的政策文本分析成为可能。因此,近几年兴起的计算社会科学的理念被引入到政策研究领域,发展出政策文本计算、政策语义分析、政策情感分析等新的研究视角[3]。
从研究问题来看,国内外政策文本的研究多集中在政策界定与比较、体系构建、演变发展等主题,而政策实施效果及其与需求的匹配度等问题的探究却相对缺乏,尤其是鲜有针对这一问题的实证研究[4]。政策的需求方作为应急管理的参与者和对象,是关系着突发公共事件治理成败和效果的关键角色。近几年,我国政府一直积极倡导并努力推进国家治理体系和治理能力现代化,特别是提出了“社会治理共同体”的创新社会治理理念,强调“科技支撑”和“公众参与”要素[5]。因此,有必要在政策研究中纳入需求方的视角,挖掘政策需求方的实际诉求,从而评估政策供需匹配度。基于此,本研究探索以新型冠状病毒感染的肺炎疫情为例,基于政策文本计算的方法研究突发公共事件下中小企业扶持政策供需匹配问题。本研究一方面将丰富政策文本研究的分析框架,拓展政策匹配研究的分析视角;另一方面,研究结果将为优化应急管理政策的科学设计,提升突发公共事件治理的精准度提供参考。
1 相关研究
政策文本计算是一个涉及计算机科学、情报学、政治学、信息学等学科的新兴交叉研究方向。基于上述学科的理论和方法,政策文本计算研究尝试构建从政策文本到政策语义的自动解析框架,并进一步关注政策文本及其内涵分析[1,6]。有学者从研究方法与范式的角度将政策文本计算分为基于数理统计的内容分析类、文献计量类、社会网络分析类、文本挖掘类和综合方法类[7]。基于数理统计的内容分析类研究一般遵循传统的文本分析框架,采用人工或半人工半机器的方式识别和提取概念。如黄如花等采用内容分析和描述性统计分析方法进行我国政府数据开放共享的政策框架构建与主题分析[8];裴雷等采用内容分析法对中国智慧城市政策文本展开研究[9]。文献计量类研究则从政策文本的总体特征出发,量化分析政策文献的结构属性[10]。如王芳等在进行农村信息化政策计量研究时,探索了政策文本的主题分布、发布单位与时间变化趋势等问题[11]。相比文献计量类研究,社会网络分析类更关注挖掘政策文本中的关系網络、语言关联、行动关系[7]。如郝冰冰等通过构建国家扶贫政策共词网络揭示扶贫政策阶段性演变规律[12]。
尤为值得关注的是,近几年,国内外学者积极探索利用文本挖掘技术识别政策文本中的隐含知识,旨在拓展政策量化研究的广度与深度。一些研究探索通过机器的方式提升信息抽取和特征识别的效率,为政策主题分析和热点识别等提供支持[13]。如Quinn K M等采用无监督学习方法对参议院演讲资料进行分类[14];Loren C等则使用有监督学习方法,将一个政策议程主题编码框架应用于联邦法规和国会法案的研究中[15];张涛等提出一种融合了关键词抽取法、主题分析法和共现分析法的政策文本计算框架[16]。一些学者尝试基于深层潜在语义的知识发现展开政策情感、政策立场和政策倾向研究。如Yu B等采用机器学习的方法基于国会演讲数据分类政党的倾向[17];Barbera P使用Twitter的选民数据来估计政治人物、政党和选民的政治主张[18]。
2 研究设计
2.1 数据采集与预处理
2.1.1 数据采集
为探索新冠肺炎疫情发生以来,我国中小企业扶持政策供给和政策需求情况,揭示二者的匹配度,本研究尝试采集相关政策文本数据作为政策供给的文本挖掘资料,采集新闻报道数据作为政策需求的文本挖掘资料。具体地,基于最大努力采集原则,获取了国家及地方针对中小企业生产经营的扶持性政策123份(时间截止到2020年2月5日),政策文件涉及草案、条例、决定等多种形式;以百度资讯为新闻数据来源,以“中小企业”+“疫情”为搜索关键词,检索疫情发生以来关于中小企业生产经营问题的报道以及中小企业扶持性政策的实施评价,考虑到新闻报道的时滞性,检索截止日期为2020年2月8日,最终利用Python爬虫技术结合人工筛选的方法获取278份新闻报道文本。
2.1.2 数据预处理
对文本资料进行预处理。考虑到政策文本的特殊性,首先利用NLPIR-Parser对文本进行新词发现与挖掘,并导入词库以提高分词效果。采用四川大学机器智能实验室停用词库和百度停用词词表进行停用词处理。完成分词后,对整体文本和单篇文本展开计量,获得权重、词频、信息量等多项统计值。
2.2 分析方法与框架
2.2.1 分析方法
1)主题挖掘
主题挖掘是文本挖掘的常用手段,旨在基于一系列文档中发现抽象主题。考虑到政策文本的多主题特性和词项的高维特性[7],本研究采用LDA(Latent Dirichlet Allocation)模型进行政策文本主题分析。LDA是一种文档生成模型,常用来作为文本分析的主题建模。它的原理基础是词袋模型,基于Dirichlet分布和贝叶斯分类器完成[19]。LDA认为每篇文章是由多个主题所构成,并将每一个词视为向量,而每个主题又是由多个词语所代表的,因此每一篇文本被制成词频向量,最终将文本信息构建成数字信息。LDA的核心公式为式(1):
2)文本分类
文本分类的主要任务是将给定的文本集合划分到已知的1个或者多个类别集合中,其核心问题是文本表示与分类模型[20]。主要的实现方法有两类:一种是基于传统机器学习的文本分类;另外一种是基于深度学习的文本分类。前者是人工特征工程和浅层分类模型的结合;后者则采用分布式词向量表示文本,并依赖深度学习模型实现分类,提升了分类的准确率。然而在监督学习中,多层神经网络容易陷入局部极值点从而导致文本聚集于单个局部主题;在非监督学习中,又缺乏有效的方法构建多层网络。为了平衡这一问题,Hinton提出在非监督数据上建立神经网络的算法,分为前向传播和后向传播两个方向,并且基于Logistic回归和极大似然估计进行运算,将文本向量化,建立深层神经网络。
3)共词分析
共词分析是对一组词两两统计它们在同一篇文档中出现的次数并做聚类分析,从而反映这些词的亲疏关系。这种亲疏关系可以用共现强度来计算,如式(2)[21]。共现分析可以帮助理解文档的主题结构,并且当文档具有相同或类似主题时,往往会包含大量相同的共现词[22]。因此可以借助共现分析反映政策主题和新闻报道主题之间的关系。在共词分析之前,需要采用关键词抽取法获得文本中的有效词语,本研究采用K值关键词筛选的方式提取关键词,如式(3)。
2.2.2 分析框架
本文在张涛等学者[16]提出的政策内容分析方法的基础上,构建了一套融合主题挖掘、文本分类和共现分析的分析框架(如图1所示),主要通过主题分布分析和关键词共现分析两条路径实现政策供需匹配评估,具体流程如下:
1)主题分布分析路径
首先,对预处理后的政策文本进行LDA建模和主题抽取,确定政策文本的主题分类,依据LDA的极大似然估计,将政策文本根据主题进行分类;然后,利用LDA分类后的政策文本作为训练集,采用基于深度神经网络的文本分类方法对预处理后的新闻文本进行主题分类;最后,对比政策文本和新闻文本的主题分类结果,从文本分布、波动差异、偏好性等指标方面对政策供给和政策需求的匹配度进行分析。
2)关键词共现分析路径
首先,采用K值关键词抽取法对预处理后的新闻文本进行关键词提取;其次,利用共现分析法对政策文本的主题关键词和新闻文本的关键词进行共现强度计算;最后,从词汇对的共现强度角度对政策供给和政策需求的匹配度进行分析。
3 数据分析
3.1 政策文本主题挖掘
3.1.1 文本摘要提取
在LDA主题分析之前,对政策文本进行摘要处理,通过摘要可以形成对中小企业扶持政策的整体结构性理解,并为LDA的主题数确定提供参考。本研究利用NLPIR-parse实现文本摘要,摘要率为0.2,最大摘要长度为250,关键词为Top20,并呈现地名、机构名,生成的摘要信息如表1所示。
从政策涉及机构来看,来自中央及各地市财政部门的政策文件占总文件数的54%,其次是省级与地市级政府办公厅(室)和人社部门(如图2)。反映出在应对新冠肺炎疫情对中小企业的冲击问题上,已形成了中央與地方联动、部门与部门协作的形势。且由部门职能占比推断,目前的政策主题可能多围绕财税、社保等话题。
3.1.2 基于LDA建模的主题识别
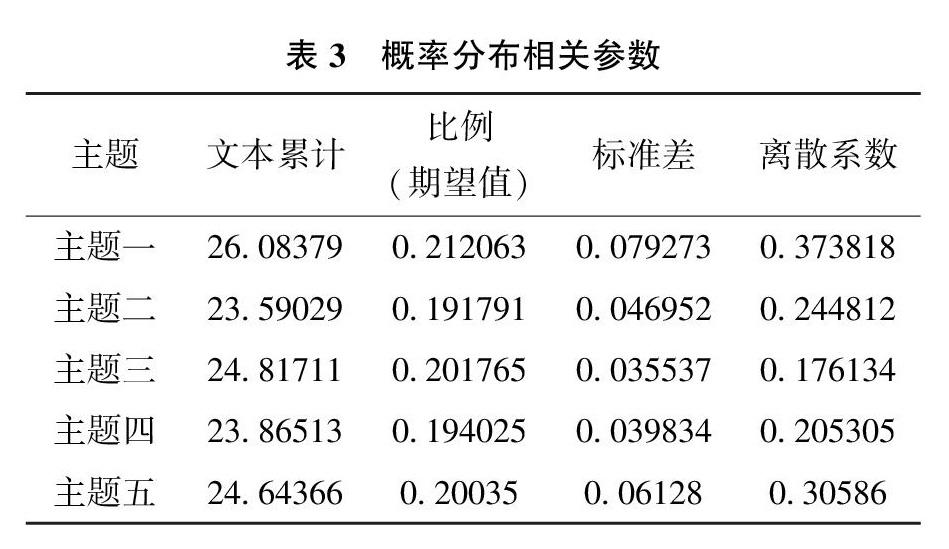
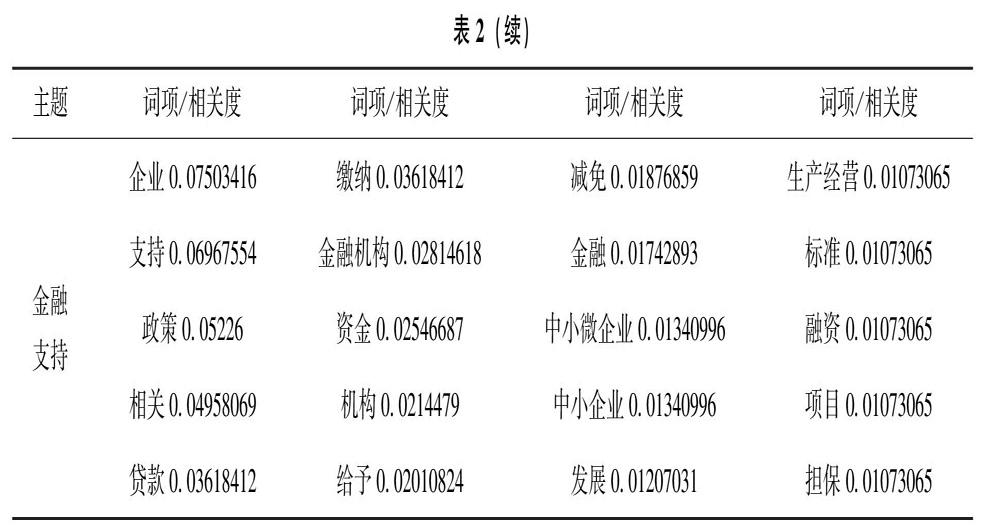
采用LDA模型对政策文本主题进行挖掘。关于LDA的主题数如何确定,目前学术界尚未形成一套公认的准则。本研究基于政策文本摘要形成的整体认识,将主题数确定在4~7种。反复实验后发现,4种主题无法充分展现信息,7种主题则容易导致缺少意义,最终将主题数确定为5。α值选取50/k+1,其中k为主题数,β值选择0.01,迭代次数为5 000次。表2展示了5类主题按相关度排序的特征词词项(Top20)。将抽取的主题结果与摘要信息结合进行政策文本主题分析。
3.2 政策与新闻文本分类分析
3.2.1 政策文本分类
进一步基于主题对政策文本进行分类,首先在LDA建模的基础上获得每个文本的归属概率,计算5个主题下文本的标准差和离散系数(见表3)。结果显示,主题二(税费优惠)、主题三(政务服务)和主题四(物资保供)的离散系数较小,而主题一(信息化征管)和主题五(金融支持)的离散系数较大。表明政策文本大多为复合主题,其中,信息化征管和金融支持的话题多出现在其它主题的政策文本中。采用极大似然估计LDA方法,将文本的概率最大的主题类型视作该文本的类型,并通过了F检验,得到的结果如图3所示。可以看出,围绕主题一(信息化征管)和主题五(金融支持)的政策文本数量较多,与上述采用文本概率计量离散系数的结果较为相符。
3.2.2 新闻文本分类
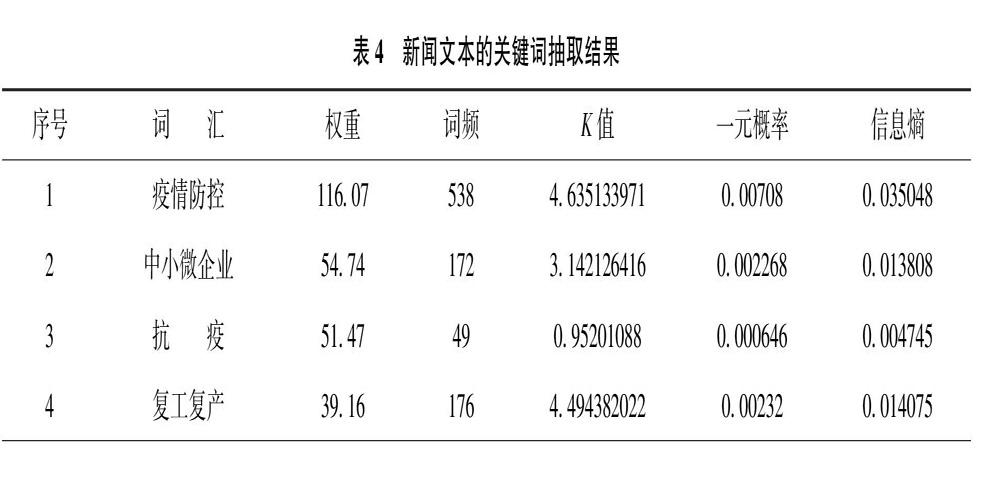
在进行新闻文本分类之前,先通过有效核心词语反映新闻文本的热门话题。采用K值关键词抽取法对预处理后的新闻文本进行关键词提取,借助NLPIR-parse实现。删除无意义词,合并意义重复词,得到的关键词平均词频为10.32。选取词频大于11,k值大于0.75的关键词,按权重排序展示(见表4)。可以看出,新闻文本聚焦于疫情防控,以中小微企业为主体,围绕“复工复产”“贷款利率”“稳定职工队伍”“生活物资”“绿色通道”等话题展开。值得注意的是,多数核心关键词与政策文本的重要特征词一致,但“复工复产”“稳定职工队伍”“援企稳岗”等则是新闻报道关注的特殊问题。
将LDA分类后的123篇政策文本作为训练集,采用基于深层神经网络的文本分类方法对278篇新闻文本进行主题分类。使用NLPIR-parse的机器学习分类方法实现,对句子的每一个词生成一个实值的词向量,然后按照句子合并成词向量矩阵,得到的结果如图4所示。可以看出,新闻报道对主题三(政务服务),主题四(物资保供)和主题五(金融支持)的关注较多,而关于主题一(信息化征管)和主题二(税费优惠)的探讨则相对较少。
3.3 政策供需匹配分析
3.3.1 基于主题分布的政策供需匹配分析
从宏观的主题视角出发,对比政策文本和新闻文本在5类主题上的分布差异,分析中小企业扶持
政策的供需匹配情况。政策文本分类分布选取自LDA分布结果,依据文本—主题概率矩阵,计算求和分布;新闻文本分类则采用深层神经网络分类结果。以主题文本数目除去总文本数目,获取文本类型占比(图5)。可以发现,政策供给和政策需求在5类主题上存在以下特点:
1)相比其它主题,金融支持(主题五)在政策文本和新闻文本中的分布占比相当,且均占比较高。反映了金融帮扶既是中小企业在疫情冲击下的重要政策诉求,也是当前政府为中小企业纾困的主要手段。金融支持相关的政策供给和政策需求呈现出较为平衡的关系。
2)信息化征管(主题一)和税费优惠(主题二)在政策文本中的占比明显高于新闻文本,特别是信息化征管主题在政策文本中热度最高,而税费优惠主题在新闻文本中热度最低。表明尽管政府基于这两套帮扶策略已经快速、密集地制定了政策方案,短期内尚未获得市场足够的关注和探讨。
3)与之相反的是,政务服务(主题三)和物资保供(主题四)在新闻文本中的占比明显高于政策文本,其中,政务服务主题在新闻文本中热度最高,而物资保供主题在政策文本中热度最低。推测一方面可能是已推出的这两类政策吸引了市场极大的关注,另一方面可能是企业对这两类政策的需求呼声较高。
3.3.2 基于关键词共现的政策供需匹配分析
进一步地从微观的关键词视角出发,揭示特定主题关键词下政策供给与需求的差异,对部分政策文本和新闻文本的词语展开关键词共现强度分析。基于政策文本的主题分析及特征词提取结果和新闻文本的关键词抽取结果,选取恰当的词汇对:信息化征管主题关键词“电子税务局(线上)”和“缴费”,税费优惠主题关键词“缓缴”和“××税”,政务服务主题关键词“绿色通道”和“审批”,物资保供主题关键词“生产”和“生活物资”,金融支持主题关键词“降”和“(贷款)利率”。上述关键词在政策文本、新闻文本、政策+新闻文本中的共现强度如图6所示,其中每组柱状图从左到右分别代表政策文本、新闻文本、政策+新闻文本。由图可知,不同的关键词在政策文本和新闻文本中的共现表现差异较大,具体地:
1)在上述几组词汇对中,电子税务局(线上)和缴费在政策文本中的共现强度最高,而在新闻文本中共现强度较低。一定程度反映出财税部门通过各项政策方案的制定,大力推广疫情期间的信息化、“非接触式”征管服务,而这些现代化的安全、高效的办税手段,仍有待更大力度的新闻宣传和推广。
2)绿色通道和审批在新闻文本中共现强度最高,在政策文本中共现强度也较高。表明一方面,政府积极重视开通“特事特办”“容缺受理”“随时约办”的绿色审批通道,为企业做好服务;另一方面,这些政策和举措也获得了市场的广泛关注,形成了较好的舆论影响。
4 结论与建议
本文以新型冠状病毒感染的肺炎疫情为例,基于政策文本和新闻文本探究突发公共事件下中小企业扶持政策供需匹配问题。研究首先识别出,新冠肺炎疫情发生以来,为了帮助中小企业应对疫情的冲击,中央与地方、部门与部门迅速联动协作出台了若干扶持政策,主要涉及信息化征管、税费优惠、政务服务、物资保供和金融支持5类主题。而后,本文基于主题挖掘、文本分类和共现分析的政策文本计算方法,通过主题分布分析和关键词共现分析,从宏观和微观的视角解析了当前中小企业扶持政策供给和需求之间的关系。研究得到如下结论及建议:
信息化征管是数字化战“疫”的重要手段。国家卫生健康委发布《关于加强信息化支撑新型冠状病毒感染的肺炎疫情防控工作的通知》,要求以“远距离、不接触”最大限度隔绝病毒的传播途径。为了给中小企业纳税人提供安全高效的办税环境,财税部门纷纷推出信息化征管方案。如引导纳税人优先选择电子税务局办理涉税业务,推广基于实名信息采集验证的网络办税方式等。尽管信息化征管方面的政策供给力度较大,但目前该主题的新闻报道热度偏低。为了促进中小企业尽快了解并使用信息化办税手段,有必要加强相关话题的新闻引导。
税费优惠是中央及地方政府扶持中小企业的直接措施之一。税费优惠的政策方案形式多样,包括多种措施(如延期申報、缓缴、减免)和多种对象(如增值税、房产税、社保、租金等),政策覆盖范围较广(包括直接从事疫情物资生产及流通的企业和由于疫情造成经营困难的企业等)。相较而言,税费优惠的“组合拳”尚未得到舆论的足够关注。税费问题切实关系到中小企业的基本利益,相关优惠信息不应只停留在政策文本中,还应加大向需求端的流入。增加相关舆论宣传,使纳税人准确掌握和及时享受各项税费优惠政策。
通过提升政务服务效能,帮助企业复工复产,是政策供给的另一主题。本次突发公共事件中的政务服务创新主要体现在两个方面:一是开展网络服务,解决疫情期间企业办理业务的限制,如依托在线政务服务平台,推行“不见面审批”“不见面服务”;二是提高行政审批效率,开通一站式、全链条的“绿色通道”。从相关新闻报道来看,上述举措获得了舆论较高的关注,受到了政策需求端的积极认可。因此,尚未部署政务服务支持的政策制定者可考虑推出和完善相关政策。
物资保供类政策旨在为企业释放产能提供政策支持。通过帮助解决企业生产面临的资金、资质、生产场地、设备购置和原材料采购等实际困难,推动全产业链协调联动,保证疫情期间的防疫物资和生活物资供给。物资保供主题的舆论热度较高,反映出市场对于复工复产的极大关注。随着疫情逐渐得到控制,需要加大此类政策供给,助力中小企业渡过难关,早日恢复生产。
金融支持类政策主要通过激励金融机构加强对中小企业的金融服务和资金支持,缓解企业抗击疫情和复工复产中面临的资金流压力。目前各级政府已密集出台了一批金融支持政策,涉及信贷增量支持、信贷结构优化、还款期限和方式调整等内容。特别是针对受疫情影响较大的行业,采取多种金融手段精准施策。政策需求端也表现出对金融支持较高的关注度,一定程度上反映出此类政策比较契合中小企业的需求,政策供需较为平衡。
参考文献
[1]裴雷,孙建军,周兆韬.政策文本计算:一种新的政策文本解读方式[J].图书与情报,2016,(6):47-55.
[2]丁煌.发展中的中国政策科学——我国公共政策学科发展的回眸与展望[J].管理世界,2003,(2):23-38,58.
[3]马海群,张斌.我国政策计量研究:方法与模型[J].数字图书馆论坛,2019,(5):2-8.
[4]徐德英,韩伯棠.政策供需匹配模型构建及实证研究——以北京市创新创业政策为例[J].科学学研究,2015,33(12):29-38,135.
[5]中华人民共和国中央人民政府.中共中央关于坚持和完善中国特色社会主义制度 推进国家治理体系和治理能力现代化若干重大问题的决定[EB/OL].http://www.gov.cn/zhengce/2019-11/05/content_5449023.htm,2020-03-05.
[6]Laver M,Benoit K,Garry J.Extracting Policy Positions from Political Texts Using Words as Data[J].American Political Science Review,2003,97(2):311-331.
[7]杨慧,杨建林.融合LDA模型的政策文本量化分析——基于国际气候领域的实证[J].现代情报,2016,36(5):73-83.
[8]黄如花,温芳芳.我国政府数据开放共享的政策框架与内容:国家层面政策文本的内容分析[J].图书情报工作,2017,61(20):12-25.
[9]裴雷,周兆韬,孙建军.政策计量视角的中国智慧城市建设实践与应用[J].图书与情报,2016,(6):41-46.
[10]李江,刘源浩,黄萃,等.用文献计量研究重塑政策文本数据分析——政策文献计量的起源、迁移与方法创新[J].公共管理学报,2015,12(2):143-149,164.
[11]王芳,纪雪梅,田红.中国农村信息化政策计量研究与内容分析[J].图书情报知识,2013,(1):38-48,79.
[12]郝冰冰,黄燕玲,罗盛锋.扶贫政策变迁文本计量分析与演变规律探讨[J].统计与决策,2019,35(19):103-107.
[13]Mirjana N D.Politics as Text and Talk:Analytic Approaches to Political Discourse[J].International Politics,2004,41(2):286-287.
[14]Quinn K M,Monroe B L,Colaresi M,et al.How to Analyze Political Attention with Minimal Assumptions and Costs[J].American Journal of Political Science,2010,54(1):209-228.
[15]Loren C,John W.Tradeoffs in Accuracy and Efficiency in Supervised Learning Methods[J].Journal of Information Technology & Politics,2012,9(3):298-318.
[16]張涛,蔡庆平,马海群.一种基于政策文本计算的政策内容分析方法实证研究——以互联网租赁自行车为例[J].信息资源管理学报,2019,(1):68-78.
[17]Yu B,Kaufmann S,Diermeier D.Classifying Party Affiliation from Political Speech[J].Journal of Information Technology & Politics,2008,5(1):33-48.
[18]Barbera P.Birds of the Same Feather Tweet Together:Bayesian Ideal Point Estimation Using Twitter Data[J].Political Analysis,2015,23(1):76-91.
[19]Blei D M,Ng A Y,Jordan M I,et al.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,(3):993-1022.
[20]刘婷婷,朱文东,刘广一.基于深度学习的文本分类研究进展[J].电力信息与通信技术,2018,16(3):1-7.
[21]冯璐,冷伏海.共词分析方法理论进展[J].中国图书馆学报,2006,(2):90-94.
[22]白秋产,金春霞,章慧,等.词共现文本主题聚类算法[J].计算机工程与科学,2013,35(7):164-168.
(责任编辑:陈 媛)
