中国英语新词语料库构建技术研究
2020-08-19刘永芳郝晓燕
刘永芳,郝晓燕,刘 荣
1.太原理工大学 信息与计算机学院,太原 030000
2.太原理工大学 外国语学院,太原 030000
1 引言
中国英语作为英语使用型变体,在词汇层面具有显著的中国特色,已成为全球英语新词最大供给方。随着中国国际影响力日益增强,大量中国英语新词被国际社会接受并使用。中国英语词汇的出现和发展反映着中国语言、社会及国际地位的变化,因此,研究中国英语词汇具有重要的现实意义。
中国英语最先引起人们注意的是词汇层面的表现[1]。国内对于中国英语新词语的研究大多是对中国英语词汇使用情况的研究[2],对于真实数据的考察多限于举例[3-4]。国外对中国英语的研究较为薄弱,一些研究[5-7]借助少量数据试图说明中国英语词汇层面特征,但是这些研究大多缺乏系统性及客观性。这些研究所呈现的新词数据稀少,为了更好地开展中国英语新词研究工作,中国英语新词语料库是必不可少的工具,而新词识别是建设新词语料库基础且主要的手段之一。本文主要介绍构建中国英语新词语料库的新词识别技术。
目前新词识别研究方法主要有三种:基于统计方法,基于规则方法,基于统计和规则相结合方法。基于统计方法是通过各种统计量的计算来筛选新词。李文坤等人[8]基于从COAE2014 主办方提供的1 000 万条大规模微博语料数据集中自动识别出不在给定的字典以内的新词,提出了基于词内部结合度和边界自由度的新词发现方法。Su 等人[9]分析对比适合微博文本特点的统计量后,利用加权计算改进了邻接熵算法,提高了新词抽取准确率。该方法灵活性高,适应性强,可移植性好,但需要训练大规模语料,并且存在数据稀疏等问题。基于规则方法是通过对新词的词形、词义、词性等构建规则、匹配规则来识别新词。段宇锋等人[10]选取总样本字数超过7 万字的描述植物物种样本的数据集作为语料,应用N-Gram算法对专业领域的新词自动化识别进行探索。Sasano 等人[11]基于日语词语规则与其拟声词模式,提出在句子的格框架中添加新节点以发现最优路径,识别日语中的未登录新词。该方法针对特定领域准确性很高,但可移植性较差,且规则构建过程需要大量人力、物力的消耗。结合统计和规则方法可以在一定程度上发挥各自优点,有效提高新词识别效果。夭荣朋等人[12]提出一种MBN-Gram算法,利用统计特征互信息和邻接熵对新词串扩展并筛选,最后利用词典进行过滤得到新词集,但是其N-Gram 算法产生了大量词串,导致实验效率降低。Mei等人[13]提出一种非监督的新词识别方法,利用词频、词凝聚度、词自由度及三个自定义参数组合形成的公式,结合少量过滤规则,从四个大规模的语料库中识别出新词,但该方法参数值的自适应性未确定,对于计算机自动抽取有一定局限性。
综上所述,本文采用统计和规则结合方法,提出了基于传统互信息、邻接熵等统计特征的改进算法来识别中国英语新词。首先利用N-Gram 算法对语料进行分词,再通过多字点互信息计算词内部凝聚度,通过邻接熵计算词外部自由度,最后设置双点互信息阈值和邻接熵阈值筛选,结合相应词典过滤,从而得到中国英语新词,取得了较为理想的实验结果。
2 中国英语新词语料库构建
构建中国英语新词语料库包括语料选定工作和语料加工工作。
语料选定工作主要考虑了以下内容:语料数据量要足够大;分布领域要广泛;来源不可单一;获取语料的技术手段有效可行。本文主要针对媒体正式语言中的词汇进行考察,因而语料需考虑媒体的代表性。目前,中国英语报刊和互联网站点有很多家,综合考虑发行量和影响力,选取期刊China Daily和Shanghai Daily。该期刊创刊时间较早,新闻更新及时,覆盖了经济、文化、社会、体育、历史等多个领域,提供新闻电子版,方便获取语料。
中国英语语料库建设前期,已通过购买正版新闻语料,利用Python 爬虫技术获取了2012 年至2018 年两大网站全部英语语料。
语料加工工作包含以下内容:对获取的语料进行预处理,对处理后的语料进行新词识别。首先,过滤垃圾串,使用规则方法将语料中的中文、Url 链接、无效字符去除。其次,结合英文单词特点,用一个空格作为单词之间的分隔符,便于语料库存储以及新词识别。语料预处理已在语料库建设前期完成。中国英语新词识别在下文详细介绍。
3 中国英语新词识别研究
3.1 新词识别相关技术
3.1.1 点互信息
判断一个词组是否可以构成一个意义完整的词组,词内部凝聚度可以作为度量标准。点互信息是常用的较稳定的表示词内凝聚度的统计量。点互信息的计算公式为:

其中,p(x)、p(y)分别表示词x和词y单独出现在语料中的概率,p(xy)表示词x和词y同时出现在语料中的概率。当PMI(x,y)<0 时,表示词x和词y的出现是互不相关的;当PMI(x,y)=0 时,表示词x和词y是相互独立出现的;当PMI(x,y)>0 且其值越大时,表示词x和词y同时出现可能性越高,越有可能成为新词。
互信息判断二元词其成词概率效果很好,而应用于多元词就需要考虑将词组划分为两部分。
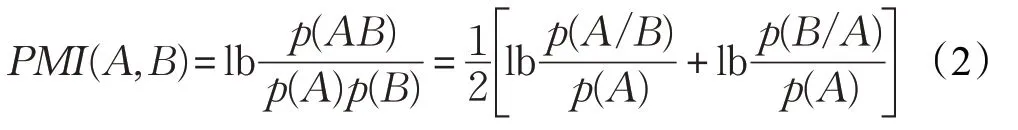
式(2)是互信息的变形公式,多元词可以划分为A、B两部分,而A、B划分又有多种形式,如“BRICS Leaders Xiamen Declaration(金砖国家领导人厦门宣言)”,可分为“BRICS”和“Leaders Xiamen Declaration”、“BRICS Leaders”和“Xiamen Declaration”及“BRICS Leaders Xiamen”和“Declaration”这三种组合形式,那么取不同形式概率均值显然是有效的方法。

其中,w1…wn为多元词串,p(w1…wn)是词串w1…wn出现在语料中的概率,avg(w1…wn)是多元词串不同组合的平均概率。
此外,分析式(2),当词AB频率和词A频率显著大于词B频率,那么PMI值会较小。设置单一正常阈值,无法识别到符合此特征的新词;设置单一较低阈值,无效低频词会大量出现,都会降低新词识别准确率[14]。
因此,本文算法采用改进后的多元点互信息式(3),并设置双阈值对新词进行过滤筛选。
3.1.2 邻接熵
判断两个词是否可以构成一个意义完整的词组,除了词内凝聚度外,词外部自由度也是一个衡量标准。邻接熵是常用的准确率较高的表示成词概率的外部统计量。邻接熵的计算公式为:
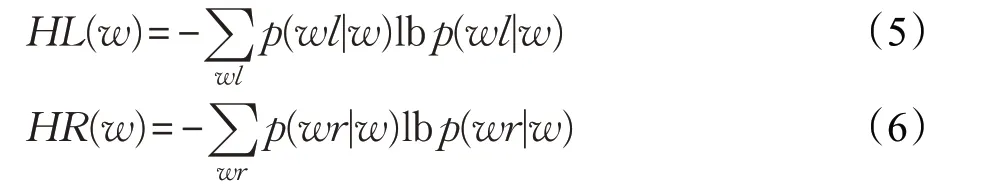
其中,p(wl|w)表示词w出现的情况下左邻接词是wl的条件概率,p(wr|w)表示词w出现的情况下右邻接词是wr的条件概率。HL(w)和HR(w)值越大,说明w候选词组左边相邻的词的种类越多,那么w成词可能性越大;反之,HL(w)和HR(w)值越小,说明w候选词组左边相邻的词的种类越少,那么w成词可能性越小。如在语料中“Xiongan New Area(雄安新区)”,它的前后往往连接是“from”“the”“that”这样多种多样的单词,而“Xiongan New”它的后面连接很固定的是“Area”,“New Area”它的前面基本都是“Xiongan”,这样就证明“Xiongan New Area”这三个单词是一个新词词组的概率远远大于像“from Xiongan New Area”“Xiongan New Area that”等相关其他组合。
3.1.3 N-Gram算法
对词组内部凝聚度和词外部自由度的判断需要候选词集。N-Gram算法可以用于对语料的切分,具有语种无关性,无需对研究语料进行语言学处理,不需要词典和规则。以英文语料为例,设置滑动窗口的大小为N,每次滑动一个窗口,直至文本结束,对文本语料进行切分,切分后每个大小为N的字符串为一个gram,统计所有gram 的频率,并且按照事先设定好的阈值进行过滤,形成符合条件的gram 词表。N-Gram 算法简便易实现,但是对于不设置N大小的大规模语料进行处理,效率会很低。目前计算gram频率的二元递增Bigram算法和三元递增Trigram 算法准确率较好,但是基于中国英语新闻新词单词不只局限于三个及三个以下。文献[15]通过分析大规模语料,发现中文每个词条对应2.33个英文单词和英语每个词条对应2.25 个汉字。文献[16]研究发现,汉语新词主要是2 个到4 个汉字。因此本文对语料利用N-Gram算法处理文本,设置1 ≤N≤5。
3.2 新词识别改进算法
目前,用于识别新词的统计和规则相结合的方法中,基于点互信息和邻接熵的结合方法是一种有效地识别新词的方法。常用的新词识别算法流程如图1所示。

图1 常用的新词识别算法流程图
传统结合方法只针对两个单词的点互信息进行判断,并未扩展到多词判断,存在词内部凝聚度不高的问题。此外,互信息在识别中国英语新词时存在不利固有特性,设置单一的互信息阈值,实验会保留大量低频无意义词组,导致准确率降低。
针对以上不足之处,本文对传统算法进行了改进,加入多字点互信息的判断,并且设置双阈值对处理好的语料进行新词识别。首先使用N-Gram 算法对预处理过的语料切分,并得到1-gram~5-gram包含词频的gram表,过滤小于阈值的词;利用筛选后在阈值区间点互信息的计算值再次筛选;接着利用邻接熵计算值对词的左右边界进行判定并筛选;最后利用多字点互信息计算值筛选出候选新词集,因为新词不包含在已有常用词典中,所以使用相应词典对已存在词进行过滤,得到新词集。改进后的算法流程如图2所示。

图2 改进后的新词识别算法流程图
4 实验与分析
4.1 实验语料
针对语料库建设中需要年度英语新词的需要,本文从前期获取的语料中抽取了2017年全部的英语语料作为实验数据,约137.2 MB,约4.9 万篇新闻,约229 万个单词。本文通过改进后的点互信息和邻接熵算法,对语料进行新词候选词识别,利用词典过滤已存在词,最终得到新词。
4.2 评价指标
本文对新词识别用准确率(Precision,P)、召回率(Recall,R)和F值(F-measure)来评价实验结果。计算公式如下:

其中,CN表示算法正确识别的新词数,DN表示算法识别到的新词数,M表示语料的新词总数。
4.3 对比实验
本文使用传统基于单阈值点互信息和邻接熵的算法[8]、基于单阈值多字点互信息和邻接熵算法、基于双阈值点互信息和邻接熵算法和基于双阈值多字点互信息和邻接熵算法(本文算法)进行对比实验。实验结果如表1所示。

表1 新词识别实验结果
由表1中的实验结果可以看出,本文提出的算法在准确率、召回率和F值上都有了一定的提高。本文在传统融合统计和规则方法上,对候选词集计算多字互信息并设置双阈值和N-Gram 算法N的大小进行筛选。改进后的算法不仅可以获得具有更高词内部凝聚度的词,增加了正确识别到的新词数量,而且去除了大量无意义词串,减少了无效新词的识别数量,进而更准确地识别新词。综合来看,本文在中国英语新词识别上取得了较好的效果,可用于中国英语语料库的建设。
5 结束语
本文主要介绍了中国英语新词语料库建设中的新词识别技术,为语料库建设提供了有效的技术支持。传统统计和规则结合算法缺少对词的内部凝聚度的判定,以及N-Gram 算法不限制N的长度,会产生大量无效词串,耗费时间,降低实验效率。本文采用改进后的算法识别中国英语新词,取得了不错的效果。但综合来看,本文方法还有一些需要改进之处,可以考虑错误识别的词,分析总结其特点,找出通用过滤规则,进而提高新词识别的准确率。
综合来看,中国英语新词语料库还需要考虑诸多方面,如语料来源的多样性、语料库的动态更新以及语料库的设计合理性,都需要进一步分析和研究。
