基于CSPPNet与集成学习的人类蛋白质图像分类方法
2020-08-19李培媛
李培媛,黄 迟
(1.太原理工大学 数学学院,太原 030024; 2.西南财经大学 信息与工程学院,成都 611130)
0 概述
图像分类的应用极其广泛,其在信息学、生物医学、交通网络分析、城市计算等领域均随处可见。在医学领域,蛋白质亚细胞定位是指确定某种蛋白质在细胞内的具体存在部位,如核内、细胞质内或细胞膜上等,这是一项重大挑战,同时也是一个极具意义的课题。人类蛋白细胞图谱描绘了人类不同组织和器官中的蛋白质表达情况。由于不同的细胞器有着自身独特的环境,这些环境决定了细胞器的生理条件和相互作用情况,且蛋白质处于特定的细胞器中时才可正常参与人体的生命活动,因此在不同细胞器中,同一种蛋白质发挥的功能是存在差异的。蛋白质分类旨在确定蛋白质所处的细胞器,这样有助于定义蛋白质的功能,且具有重要的意义[1]。例如正常细胞和肿瘤细胞中的分泌蛋白、膜蛋白在不同器官中的表达情况不同,蛋白质的错误定位通常与细胞功能障碍和疾病有关。然而,对蛋白质进行定位研究不仅耗时、耗力,且代价高昂。根据已有的显微图像数据,采用算法预测蛋白质所在细胞器名称、实现信息自动化处理[2]是解决以上问题的关键。
双线性卷积神经网络(Bilinear Convolutional Neural Network,BCNN)[3]引入外积融合图像整体及局部特征信息,端对端地实现了细粒度图像分类,且提升了分类精度。文献[4]提出空间金字塔池化(Spatial Pyramid Pooling,SPP)能将不同大小的特征图转化为固定维度,同时保留多维度信息。本文结合BCNN与SPP 2种结构的优点,搭建一个粗细结合的CSPPNet网络模型,在模型部分卷积层上生成特征图后加入SPP层,与模型后期卷积生成的特征图相结合,能够同时提取图片的整体特征和局部特征,且可以动检测图片差异,对蛋白质分类的分类精度有较大提升,再利用集成学习的方法进一步提升准确率。
1 相关工作
1.1 蛋白质亚细胞定位
蛋白质亚细胞定位研究的方法普遍分为2类:一类是一维层面上基于蛋白质的氨基酸序列的定位方法;另一类是二维层面上基于图像特征图提取进行分类的方法。第一类将蛋白质序列中字母序列转化为数值来表示蛋白质的序列,提取特征信息后使用数据挖掘算法定位蛋白质亚细胞[5],常见的使用机器学习方法的模型有SVM[6]、K阶最近邻[7]和隐马尔科夫模型[8]等。第二类蛋白质预测算法称为蛋白质亚细胞定位,其研究和实现需构建合适的深度学习模型来实现图像分类任务。这项工作对细粒度要求高,且成果少。传统的蛋白质定位使用氨基酸序列数据信息,很难确定蛋白质的转移方向,而利用二维图像中的视觉信息则能够克服传统方法中存在的不足[5]。
随着高通量显微镜技术的进步,图像生成的速度加快,且远高于人工评估的速度。人类蛋白细胞图谱收集的图片不断增加,为加速对人类细胞和疾病的理解,自动化分析生物医学图像的需求更为迫切。蛋白质的可视化图像在生物医学研究中被广泛应用,蛋白质影像分析可能成为下一个医学突破的关键。
瑞典提供的人类蛋白图谱(Human Protein Atlas,HPA)数据库致力于绘制细胞、组织和器官中所有的人类蛋白,有助于利用图像探索感兴趣的蛋白质,在更广泛的背景下系统地分析转录组和蛋白质组,以增进对人类细胞的了解。随着卷积神经网络(Convolutional Neural Network,CNN)的发展,人类蛋白图谱小组已经展示了科学和人工智能方法用于人类蛋白定位图像的应用前景,但是目前的结果还没有专业级的注释[9]。
1.2 细粒度识别
深度学习网络模型通过多层非线性变换从像素级的数据中逐层提取特征信息,具有强大的学习能力,为解决传统的计算机视觉问题开拓了新的思路。随着计算机视觉技术的不断进步,基于图像的蛋白质分类作为细粒度分类任务开始被人们关注。AlexNet[10]、VGGNet[11]和GoogLeNet[12]在ILSVRC[13]分类挑战比赛中能够大幅提升分类性能,成功应用于大规模计算机视觉任务中,如目标识别、定位、检测以及图像分割等。VGGNet将加深网络结构,GoogLeNet创新性地拓宽网络宽度,改进了CNN模型结构。传统的CNN通过不断增加卷积层和池化层来加深网络,然而信息在层与层之间的传递过程中或多或少会丢失,造成信息损耗等情况,层与层的叠加还会导致梯度消失,使得较深的网络无法训练。文献[14]提出ResNet模型,该模型设计了特有的残差学习模块,在一定程度上解决了梯度消失的问题。CNN的特征表达功能十分强大,网络模型的改进提升了粗粒度图像分类的精度,但在对细微差异的区分上存在一定局限性,细粒度的图像分类满足了人们进一步的需求,且其研究领域已经取得了很多研究成果[15-17]。
蛋白质分类属于细粒度分类,细胞图像的复杂性要求网络能够提取更加细致的信息,已有的多数成果都基于单标签,存在很大的局限性,且许多工作严重依赖手工标注,无法包含全部细胞器位置,然而搭建端对端的粗细结合[18]的网络能避开标注框,有效提升细粒度分类效果。
2 数据集描述与分析
本文利用HPA数据集对蛋白质实现任务分类,预测标签为蛋白质所在的细胞器。本节详细分析数据集及其特点,其为数据集处理和模型搭建的依据。
1)分析图像数据。HPA数据集包含多数人类蛋白质的四通道共聚焦图像,数据集有31 072个蛋白图谱样本,每个样本由4张像素为512×512灰度图(如图1)以及1个或多个标签组成。数据集标签为28种不同的亚细胞器,表示蛋白质所在位置。图1中四通道图像表示4种染色方式,感兴趣的蛋白质(绿色),加上其他3个重要细胞器表示:细胞核(蓝色),微管(红色),内质网(黄色)。图2是细胞图谱的说明性数据[9]。其中,1为2、3、4、5四通道合成图像,2为感兴趣的目标蛋白,用绿色标记,3为DAPI染色的细胞核,显示为蓝色,4为用抗微管蛋白抗体染色的微管,显示为红色,5为内质网,显示为黄色。

图1 HPA数据集原始图像数据Fig.1 Original image data of HPA dataset

图2 HPA中说明性图像数据Fig.2 Illustrative image data in HPA
对原始图片进行染色处理,如图3所示,上面4张图为属于核质类的一个蛋白图谱样本染色情况,下面4张图为细胞液类的染色情况。蛋白质分类任务难点一是图像中没有针对标签细胞器的标注框,非专业人士难以辨别不同类蛋白质所在细胞器的不同位置及其区别,且难以对图片分析进行人工干预,精细级识别使分类任务不能取得很好的效果。

图3 训练集中2组样本染色后的对比图
2)分析标签数据。图4统计了数据集标签文件中各类别的数量,核质数量最多有12 885个。细胞质膜、细胞液和细胞核仁较为常见,过氧化物酶体、核内体、溶酶体和微管末端在训练集中较为少见,而棒和环最少,只有11个。蛋白质分类难点二是样本数据不平衡。由于细胞类型多样性与不同细胞中蛋白质所在亚细胞器的差异性,蛋白质在核质等细胞器中出现次数较多,在棒和环等细胞器中出现次数少,导致标签数量极度不均匀,稀少标签类难以实现高精度预测。
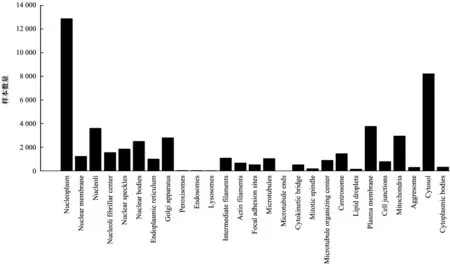
图4 训练集中28种标签数量的柱状图
图5统计了每个样本所含标签的数量,每个样本标签量是不确定的,单标签、2标签、3标签、4标签、5标签的细胞图样本分别占总样本量的48.68%、40.18%、10.17%、0.96%、0.01%,这说明3个以上标签的数量极少但仍存在。蛋白质分类难点三是样本所含标签量不同,无法设置固定的类数及阈值,需对不同类标签设定不同阈值使得预测精度最高。
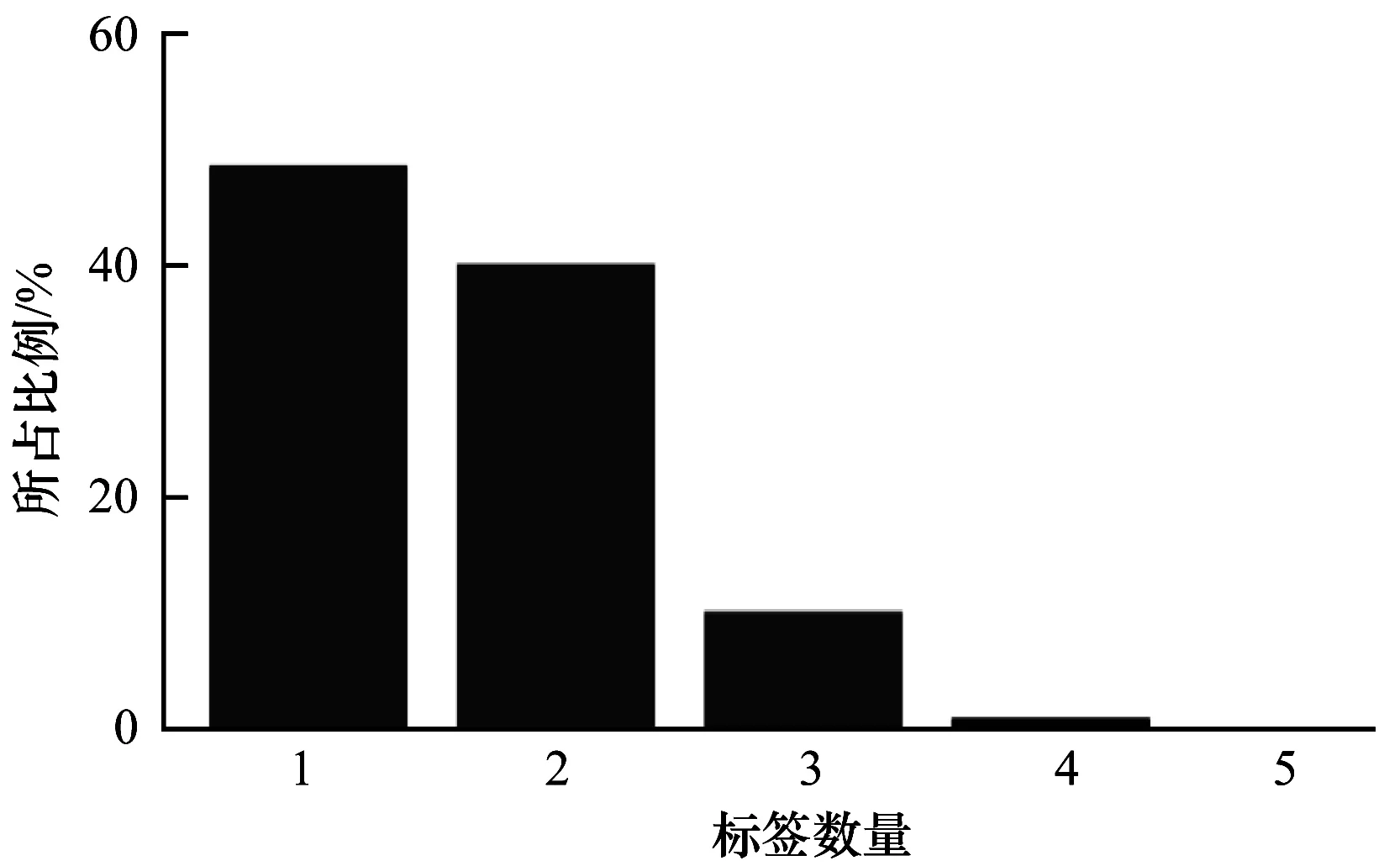
图5 样本中所含标签数量统计Fig.5 Statistics on the number of tags contained in the sample
3 本文方法
3.1 图像预处理
图像识别的第一步是对图像数据进行统计分析和预处理。数据分析有助于了解图像的实际情况,更好地理解与改进图像预处理方法。
实验中每个样本都有4种染色模式,为方便训练,把4张图片合成四通道(RGBY)图像作为输入。对图片进行简单地旋转、水平镜面翻转、随机剪裁、加高斯噪声、对图像的像素点进行加亮或减暗、图像对比度改变、平移等图像增强操作,以加强训练鲁棒性。蛋白质分类属于细粒度分类,由于最常见的蛋白质细胞器成分属于粗级特征,如细胞质膜、核仁、细胞液等,相比之下,核内体、溶酶体、微管末端、棒和环等细致成分非常少见。对此稀少类问题,需另外进行一些处理,如对少见标签的所在图片进行复制翻转等操作,同时加入训练集使其比例增加。对于多标签而言,实验采用二值化法对28个标签进行one-hot编码。
3.2 网络结构设计
本文借鉴BCNN的双线性汇合,利用空间金字塔池化搭建一个更为细化的网络结构。BCNN是一个细粒度图像识别的经典模型,该模型能够同时提取局部和全局特征并进行融合,提取并结合网络前期与后期的特征图,通过外积融合可以达成相同的效果。将结合后的特征信息与全连接层相连并进行分类。
3.2.1 双线性卷积神经网络
BCNN的具体流程为:图像首先经过CNN结构提取特征,然后通过双线性层和池化层与固定长度的神经元连接产生输出。将2个独立的CNN(VGGNet与ResNet)提取的特征采用外积结合构成最简单的双线性层。外积包含了特征通道之间成对的关系,但BCNN由2个深度卷积神经网络(DCNN)组成,模型复杂且计算量多,存在一定的局限性。
3.2.2 空间金字塔池化
从输入的不同大小的图片中提取信息,使其变为固定大小的特征向量。SPP层有以下优点:
1)SPP层将不同大小的输入图像进行一致化处理。
2)将一个特征图从不同的维度进行特征提取再聚合,显示了算法的稳定特性。
3)空间金字塔采用最大值池化函数对局部噪声有较强鲁棒性[19-20],提升目标识别的准确率。简单来说,由于对特征图进行了不同维度的特征提取,使提取特征多样化,模型精度大幅提升。
图6为SPP层结构,将任意大小的特征图分别池化为4×4、2×2、1×1的表示,其中,4×4的特征拉伸成为16×x维。
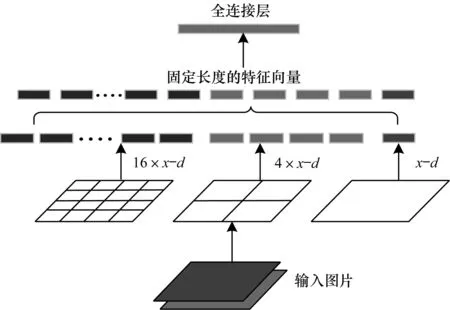
图6 SPP层结构Fig.6 Structure of the SPP layer
3.2.3 网络结构搭建
创建一个分类精度高且可以根据细胞图像自动分析预测蛋白质所在细胞器的系统,需要搭建一个适合的网络结构。BCNN模型的特点是同时用到图片局部特征信息和全局特征信息并将两者相融合,以降低信息损耗。在该过程中,利用BCNN特征累加的特性,同时设计减少模型复杂度与计算量的方法,即基于经典CNN,本文设计了CSPPNet模型。CSPPNet提取并结合网络前期与后期卷积层产生的特征图,连接3层全连接层并进行分类。利用此方法,可构建端对端的网络模型,不用人为干预就可以学习到图像的细节特征差异。特征学习过程是利用一种粗细结合的方法抓取图形的整体信息,并检测出更多、更微小的细节部分。前期特征图提取全局特征,用来表明整体线索,后期特征图提取局部特征,用来描述细致差异。
SPP层具有将一个特征图从不同的维度进行特征提取再聚合的特点,且从多角度来表达图片纹理,描述不同细粒度的特征图信息。SPP将任意大小的特征图转换成固定维度的特征向量,网络输入任意大小的图像而不需要缩放或裁减,更好地保留了图像的特征信息,最后融合各个分支网络的特征作为最后的特征表达并输入全连接层,本文称这种结构为CSPPNet。VGG16-CSPPNet是在VGG16网络结构的基础上进行改进,在block2(第4层卷积层)、block4(第10层卷积层)、block5(第13层卷积层)提取的特征后加入SPP层,之后将SPP层提取的特征图进行结合并连接3层全连接层,最后一层为28个输出节点。ResNet34-CSPPNet是在ResNet34的基础上进行改进,在128、32、16大小的特征图后加入SPP层,然后同样将SPP层提出的特征图进行结合并连接3层全连接层。该模型兼具全局和局部模型高效性,局部高效性与其物体的位置及姿态无关。同样,不同的连接方式将图像特征无序组合,获得平移无关性。另外,本文在模型中加入了dropout层,使得模型泛化能力增强。CSPPNet模型的参数可以被端对端的学习,结构如图7所示。

图7 CSPPNet网络结构Fig.7 CSPPNet network structure
先将模型的全部可训练参数训练25次,之后对CSPPNet模型后7层参数进行微调,得到结果后进行阈值选择,合理的阈值选择会大幅提升预测精度。
阈值选择算法的步骤如下:
步骤1预测得分valscore记录验证集预测的概率得分,预测值valpred记录验证集预测标签,真实值vallabel记录验证集的真实标签。阈值向量I记录最终阈值,均为28维向量。阈值i从0到1(不包含1)变化,每次变化步长为0.001,即i=0+0.001×m,m=0,1,…,1 000。
步骤2将验证集数据输入保存的模型,得到valscore。
步骤3对阈值i,记录valscore中大于i的元素所在坐标,valpred相同位置为1,其他为0。
步骤4定义f为维数为(1 000,28)的矩阵,f中元素(i,c)表示阈值为i时,第c(c=1,2,…,28)类的f1值。
步骤5计算f1值并列入矩阵f中。
步骤6观察f的28个列向量,每列中的最大值对应的阈值i记录为此类的最终阈值,得到28维阈值向量I。
3.2.4 集成算法
由于蛋白质分类是一个较为复杂的图像分类任务,单个分类器的学习能力不足,而集成学习具有提高整体泛化能力的特性,因此本文除了网络结构改进外,还结合几个不同CNN、不同采样法学习到的分类器组成一个强学习器。
集成学习需要解决2个问题:一是学习若干个分类器;二是选择结合策略。实验用5个不同的CNN(inceptionv3、vggnet、ResNet34、bninception、CSPPNet)训练得到5个分类器,选择的结合策略为投票法,该样本5个分类器中某类别标签数量过半(大于等于3)的为预测类。
3.3 评价指标
分类问题通常以准确率、召回率、F1值等多种评价指标进行评价,本文采用F1值为评价指标。预测值与真实值均为28维向量,每个点为0或1,有该细胞器记为1,无则记为0。对无边界框的多标签图像分类而言,如果产生错误标签则有以下2种情况:一是缺失的标签(FN),二是额外的标签(FP)。因此F1值更适用于多标签情况,被用来描述分类效果。以第一类标签细胞核为例:
TP(True Positive):在真实标签中有细胞核,且被预测为有细胞核的样本数量。
FP(False Positive):在真实标签中没有细胞核,但被预测为有细胞核的样本数量。
FN(False Negative):在真实标签中有细胞核,但被预测为没有细胞核的样本数量。
精确率(Precision)、召回率(Recall)和F1值的计算方法如下:
(1)
此外,多标签的准确率(Accuracy)与单标签计算方式不同,计算方法如下:
(2)
其中,ti为第i类预测正确的数量,ni为第i类总数,N为类数28。对28个标签分别计算精度,然后对所有精度取平均值,即为准确率。
3.4 实验结果与分析
图8是验证集的精度、损失值与F1值折线图,实线显示ResNet34-CSPPNet训练过程,虚线显示ResNet34训练过程。由此可见,ResNet34-CSPPNet的训练结果更好。
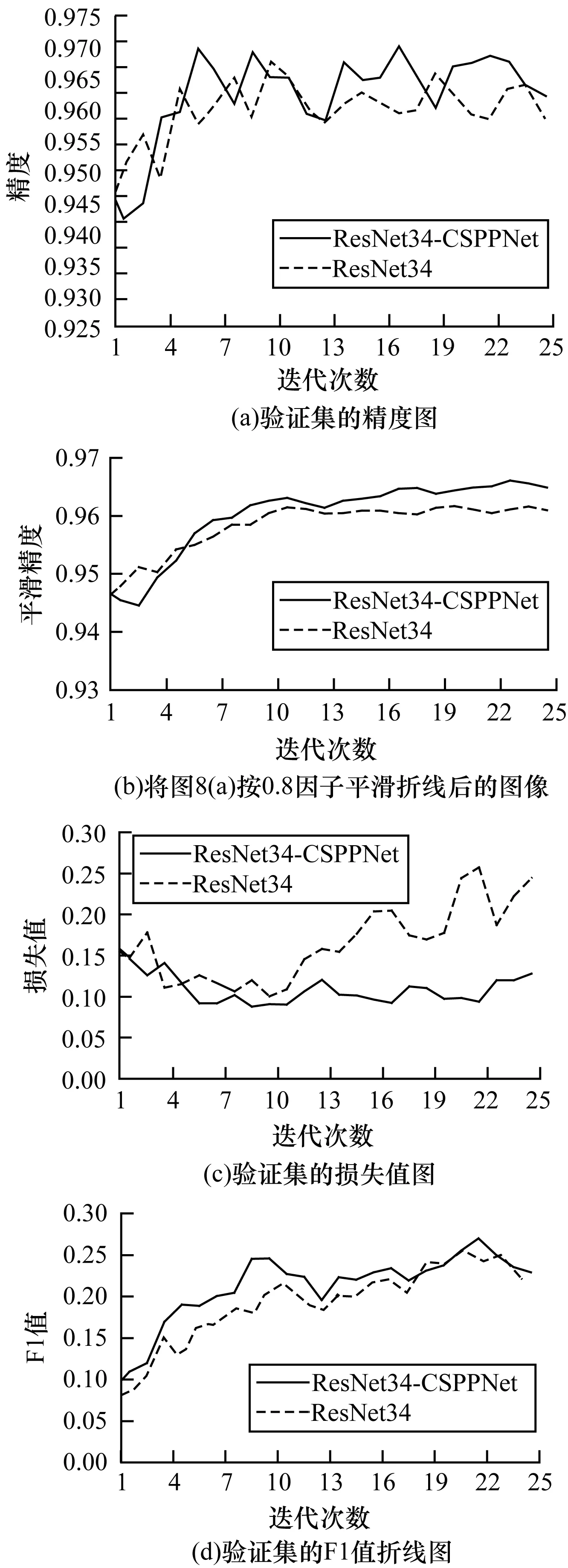
图8 ResNet34与ResNet34-CSPPNet的训练结果对比Fig.8 Comparison of training results of ResNet34 and ResNet34-CSPPNet
经过25次迭代后,部分模型的准确率与F1值对比结果如表1所示。从表1可以看出,相较于VGG16模型,VGG16-CSPPNet模型的F1值提高了0.227,准确率提高了0.016。ResNet的残差模块直接将输入信息绕过卷积层映射到输出,为了保护信息的完整性,整个网络只需要学习输入、输出差别的部分,简化了学习目标和难度,因此ResNet34的分类效果较好,且用时较短。相较于ResNet34模型,ResNet34-CSPPNet模型的F1值提高了0.031,准确率提升了0.003。由此可以看出,加入SPP层进行粗细结合考虑,对识别蛋白质问题有效。本文方法对CSPPNet进行微调并与其他分类器结果集成得分,表明本文粗细结合的CSPPNet与集成方法可以评估非均匀的数据集。

表1 5种模型的准确率和F1值的比较Table 1 Comparison of accuracy and F1 value of the five models
4 结束语
本文构建一个粗细结合的CSPPNet模型,端对端地实现蛋白质分类,在结合整体特征和局部特征自动检测类内差异的同时降低了模型复杂度,并通过阈值选择算法和集成学习方法得到更优的分类效果。下一步将从数据集和模型2个方向提升分类效果,在数据集方面考虑引入外部数据,增加稀少类样本量,而在模型改进上引入注意力机制和压缩双线性池化,进一步提升模型对细节信息的提取能力。
