基于分组映射的防碰撞查询树算法
2020-08-19董轩江李世宝蔡丽萍
董轩江,李世宝,蔡丽萍,袁 静
(中国石油大学(华东) 计算机与通信工程学院,山东 青岛 266580)
0 概述
物联网是遵循既定规定使用射频识别(Radio Frequency Identification,RFID)等信息传感仪器,在任意物品与互联网之间建立联系进行信息传输,以完成对所关联物品识别定位等操作的网络。随着物联网技术的快速发展,射频识别技术作为物联网的关键技术得到广泛应用并成为研究热点[1]。传统的射频识别系统主要由阅读器、识别标签和处理器构成[2]。如果多个标签同时处于同一阅读器的识别范围,当该阅读器发送识别请求时,会出现多个标签同时响应该阅读器的现象,这种现象称为标签碰撞[3]。
标签碰撞问题通常用标签防碰撞算法进行处理。标签防碰撞算法分为两种:一种是基于ALOHA算法的不确定性算法[4-6],包括ALOHA算法[7]、时隙ALOHA算法等;另一种是基于树的确定性算法[8-9],包括二进制搜索树算法、查询树(Query Tree,QT)算法[10]、碰撞树算法[11]等。基于ALOHA算法的防碰撞算法无法解决某些标签不能被读取的“标签饥饿”现象,特别是当标签数量增加时系统识别效率表现较差[12]。基于树的防碰撞算法由于是确定性算法,不存在“标签饥饿”问题。查询树算法是基于树的防碰撞算法的重要组成部分。目前基于查询树算法的系统效率较低,且通信复杂度较高[13]。
本文提出一种基于双重分组和对位映射的防碰撞查询树算法(DGMQT算法)。根据标签识别码特征进行双重分组操作和识别码对位映射操作,对碰撞信息分组解码并准确定位查询信息,以消除空闲时隙和减少碰撞时隙,提升系统识别效率。
1 相关工作
1.1 比特追踪技术
在RFID防碰撞算法设计中,为了定位碰撞信息通常会使用比特追踪技术,该技术以曼彻斯特编码为基础[14-16]。曼彻斯特编码将单比特数据编码为电平跳变,即数据“0”被编码为上升沿,数据“1”被编码为下降沿。曼彻斯特编码机制不允许出现“无跳变”现象,这是因为读写器需要借此判断传递的信号是否发生碰撞。采用基于曼彻斯特编码方式的RFID防碰撞算法,可在阅读器端对碰撞情况进行处理。DGMQT算法采用曼彻斯特编码方式对碰撞信息进行跟踪与解析,进而得到准确的查询前缀。例如,Tag1和Tag2两个标签的识别码分别为1010和1100,当两个标签在同一时刻开始传送识别码信息时,阅读器接收到的信息为1XX0(X为碰撞位),这表示碰撞位的位置为第2位和第3位,其中比特追踪技术的响应过程如图1所示。出现标签碰撞后阅读器将无法识别标签,采用有效的防碰撞算法可解决该问题[17]。

图1 比特追踪技术响应过程示意图Fig.1 Schematic diagram of response process of bit tracking technology
1.2 查询树算法
查询树算法的使用较简单,只需由系统记录识别标签自身识别码[18],其查询过程类似于树形结构中寻找二叉树的叶子结点:阅读器对功能区域内全部标签发送查询信号,标签识别码前缀与查询信号一致的标签会产生反馈,把自身的识别码返回传递给阅读器。阅读器接收到反馈后,根据信息碰撞情况进行处理:如果无碰撞,则识别该信号后出栈剩余查询码,发送下一轮查询信号;如果发生碰撞,则在上一轮发送的查询信息后添加一位0或1再次发送查询信息,添加1或0的查询码进行入栈操作。以上操作将循环执行直到完成全部标签的识别。
由上述查询过程可知,随着标签识别码长度和标签数量的增加,查询树算法进行识别所需查询码长度增加,标签碰撞的概率增大,识别标签所需时间增长,系统识别效率降低。
1.3 基于查询树算法研究
针对查询树算法存在的上述问题,研究者们提出许多改进算法。文献[19]在A4PQT算法[20]的空闲时隙问题基础上提出基于分组机制的位仲裁查询树防碰撞算法(GBAQT算法),根据标签识别码自身特征将未识别标签分为两组,分组情况如表1所示。

表1 未识别标签分组情况Table 1 Grouping situation of unrecognized labels
阅读器通过分析返回的碰撞信息发送查询码进行下一轮识别,当标签识别码发生碰撞时,阅读器接收到的同组标签识别码存在以下4种情况:
1)该组有1列识别码,如果为G=0组,则返回识别码000(或者011/101/110);如果为G=1组,则返回识别码001(或者010/100/111)。在该情况下,识别码可直接被识别,不需进行下一步处理。
2)该组有2列识别码,例如G=0组返回的识别码为000和011,阅读器接收的碰撞信息为0XX,阅读器在下一轮发送000和011作为前缀进行查询。
3)该组含有3列识别码,例如G=0组返回的识别码为000、011和101,阅读器接收的碰撞信息为XXX,全碰撞情况下阅读器在下一轮只能选择发送G=0组的全部识别码作为前缀进行查询,从而产生1组空闲时隙。
4)该组含有4列识别码,在该情况下标签返回的为全碰撞信息,阅读器在下一轮将发送全部该组识别码作为前缀,不会产生空闲时隙。
在上述4种情况中,只有第3种情况产生空闲时隙,其发生概率为4/15。GBAQT算法虽然采用分组思想改进A4PQT算法,但是没有避免产生空闲时隙,导致算法效率仍较低。
针对上述问题,本文基于分组思想和映射机制,提出一种双重分组的对位映射防碰撞查询树DGMQT算法。首先根据标签特征进行分组,然后利用对位映射机制将分组后的标签识别码映射为唯一且清晰可辨的映射数据,阅读器根据该映射机制将碰撞后的映射信息直接解码出查询前缀,从而避免在下一轮查询过程中产生空闲时隙。
2 双重分组对位映射防碰撞查询树算法
2.1 设计思想
DGMQT算法是在标签分组的基础上加入对位映射机制,使用映射码代替标签识别码进行信息传输,经过分组映射后的数据在阅读器端可以进行分组解码。由于映射数据具有清晰可识别的特点,因此在解码过程中可以准确定位碰撞信息,不需进行下一轮模糊查询,从而避免产生空闲时隙。
该算法对标签进行双重分组,从横向按标签识别码位数进行分组,每3位归为1组;从纵向每组根据识别码特征再进行分组,同组的3个识别码异或运算(运算符号为⊙)结果为1则归为一个小组,同或运算(运算符号为⊕)结果为1则归为另一个小组,并为该组附加组标签G[G∈(0,1)],具体分组情况如图2所示。TagA与TagB代表两个长度为n的RFID标签,按照识别码编号表示为P1P2…Pn,首先从横向分组:将P1P2P3作为第1组识别码,将P4P5P6作为第2组识别码,以此类推;其次从纵向分组:TagA中第1组识别码有P1⊕P2=P3,则P1P2P3组为G=0组,TagB中第1组P1⊙P2=P3,则该组为G=1组;P4P5P6的情况与之相反。按照双重分组规则不断进行分组直到最后3位识别码分组完毕。

图2 双重分组示意图Fig.2 Schematic diagram of double grouping
在双重分组的基础上,DGMQT算法的映射数据根据组标签和识别码特征按照对位映射规则进行定制。对位映射规则为:3位识别码表示为XXX,对位映射表示为GXXX或者GTTT(其中G为组标签号,TTT是由XXX按位取反得到的识别码)。例如,对于G=0组识别码中含有识别码1的标签(011、101、110),映射数据取首位置组标签号0,后接识别码按位取反(100、010、001),不含1的标签(000)则首位置1接识别码(1000);G=1组识别码中含有0的标签(001、010、100),其映射数据取首位置组标签号1,后接识别码为001、010、100;不含0的标签(111),则首位置1后接的识别码按位取反(1000),具体识别码分组和映射关系如表2所示。例如,有6位标签识别码为000101,则其按对位映射规则后的映射数据为10000010。
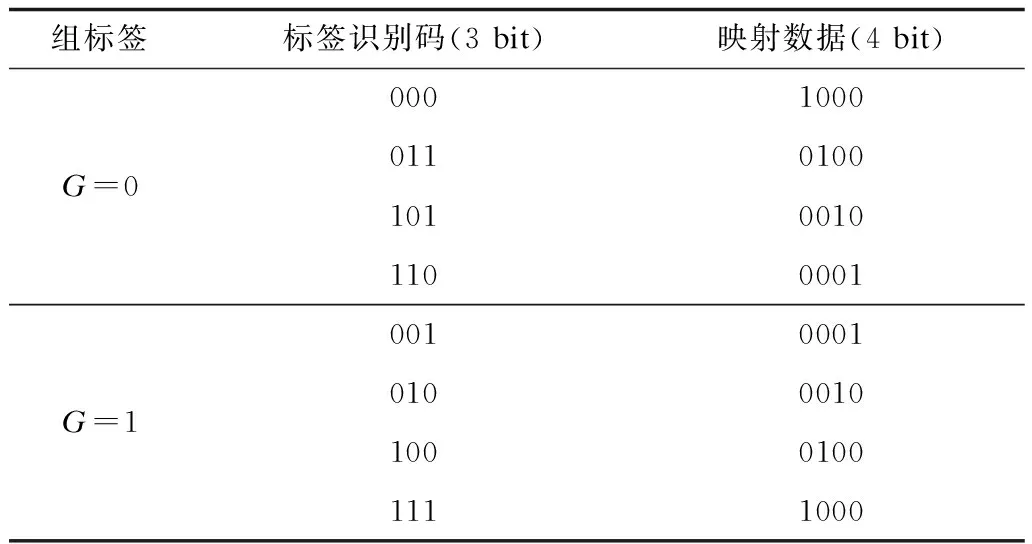
表2 识别码分组和映射关系Table 2 Identification code grouping and mappingrelationship
经过对位映射后,3位识别码对应4位映射数据,在同组内可实现准确识别碰撞信息,不同组间可通过组标签号进行区分,从而完全避免产生空闲时隙,最终传输给阅读器的数据为1位组标签号G加上4位映射数据GXXX或者GTTT。
在阅读器端利用对位映射机制反解出碰撞信息可得到准确的查询码,不同组碰撞信息将分开解码并进入不同堆栈,为下一时隙查询做准备。例如,某时隙响应的识别码有000、011、010和100,则向阅读器返回的数据为0/1000,0/0100,1/0010和1/0100,阅读器中收到的G0组数据为XX00,G1组数据为0XX0,解析后查询码000和011进入G0查询堆栈,查询码010与100进入G1堆栈。
2.2 相关指令
DGMQT算法中使用的具体指令如下:
1)REQ(*):阅读器请求命令,用于在初始阶段完成第1次查询工作,阅读器发送REQ(*)命令,工作范围内的全部标签将第1组的组标签和对位映射码同时发回阅读器。
2)REQ(pre):阅读器请求命令,阅读器发出此指令,待识别标签中与该查询前缀相同的标签被激活,并在同一时隙返回该查询前缀下一组识别码相应的组标签号和对位映射码。
3)Decode:阅读器对标签反馈的映射碰撞信息进行分析,得出该组标签所包含的查询前缀pre。
4)PUSH(pre):阅读器操作命令,pre为当前需要压栈的查询前缀,发出命令后,阅读器将此查询前缀压入堆栈。
5)POP(pre):阅读器操作命令,pre默认为当前查询堆栈栈顶的查询前缀,发出命令后,阅读器将此查询前缀弹出堆栈。
6)READ:阅读器读取命令,处于激活状态的唯一标签收到命令后将识别码发回阅读器。
2.3 算法流程
DGMQT算法流程如图3所示。

图3 DGMQT算法流程Fig.3 DGMQT algorithm flow path
DGMQT算法包括以下4步:
1)阅读器将组标签G0和G1初始化为空并发出命令REQ(*)后,工作范围内全部标签响应并将自身识别码中第1组的组标签和对位映射码发送返回到阅读器。
2)阅读器确认返回标签中映射信息碰撞情况,如果未发生碰撞,则发送READ读取命令完成标签数据读取操作,然后直接执行第4步;如果发生碰撞,则执行第3步。
3)阅读器对组标签G=0的对位映射码进行Decode操作,将碰撞的映射码进行解码,对解码后得到的查询码进行PUSH(pre)操作入G0栈;阅读器对组标签G=1的映射码执行相同操作,对解码后得到的查询码进行PUSH(pre)操作入G1栈。若此时隙没有返回组标签G=0(或G=1)的映射码,则忽略与其对应的操作。
4)判断查询堆栈G0是否为空,如果不为空,执行POP(pre)操作,弹出栈顶查询前缀,阅读器进行REQ(pre)操作,请求相同前缀的标签发送组标签和对位映射码,然后执行第2步;若堆栈G0为空则对堆栈G1进行上述操作;若堆栈G1也为空,则识别完成,识别过程终止。
2.4 算法识别示例
假设有8个待识别标签,其识别码分别为A(000101)、B(000001)、C(101000)、D(101011)、E(101010)、F(001110)、G(111011)、H(111110)。DGMQT算法中标签返回的组标签和对位映射码如表3所示,阅读器查询和标签响应过程如表4所示,对应的查询树结构如图4所示。
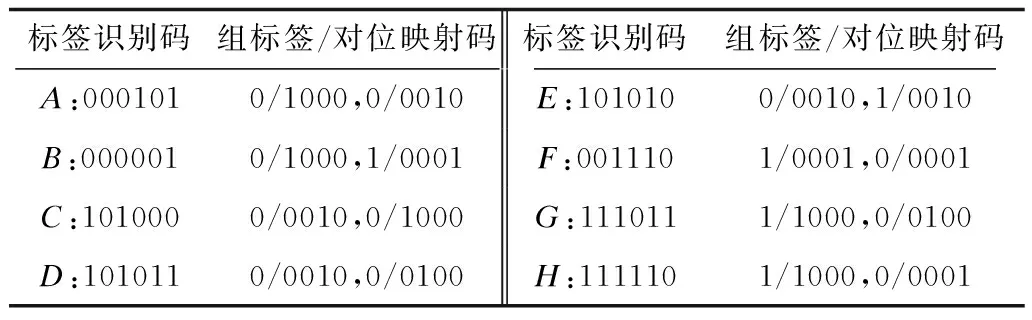
表3 DGMQT算法中标签返回的组标签和对位映射码Table 3 Group labels and pair mapping codes returned by labels in DGMQT algorithm

表4 DGMQT算法中阅读器查询和标签响应过程Table 4 Reader query and tag response process in DGMQT algorithm
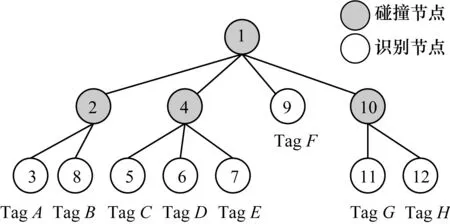
图4 DGMQT算法树结构示意图Fig.4 Schematic diagram of DGMQT algorithm tree structure
3 算法性能分析
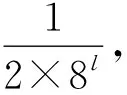
(1)
空闲时隙的概率为:
(2)
非空闲时隙的概率为:
(3)
第l层空闲时隙数为:
(4)
第l层非空闲时隙数为:
(5)
总的空闲时隙数为:
(6)
总的非空闲时隙数为:
(7)
DGMQT算法中对位映射编码使识别过程中避免产生空闲时隙,且分组方式相当于大量减少搜索所用的层数,即在最差情况下(即待识别标签的每一位识别码都进行了碰撞)DGMQT算法识别的时隙数Tn≈Nnc,因而以Nnc作为DGMQT算法的识别时隙数来进行识别时隙数、系统效率、时隙利用率和通信复杂度的分析。
系统识别效率为:
(8)
其中,Tn为总时隙数。
时隙利用率为:
(9)
通信复杂度定义位标签成功被阅读器读取所传输的总比特数为:
(10)
其中,Fn为DGMQT算法成功识别n个标签所需要的通信复杂度,Li为后续识别过程中每次查询的传输位数,L为第1次查询的传输位数。
4 仿真与结果分析
RFID防碰撞系统应用算法的性能指标包括查询时隙数、系统效率、时隙利用率和通信复杂度。使用Matlab_2018b平台对DGMQT算法、QT算法、八叉树算法、A4PQT算法、GBAQT算法进行仿真实验,标签数最大为1 000,标签识别码的位数为96 bit,分别对上述算法的总时隙数、系统效率、时隙利用率和通信复杂度进行对比分析。
由图5可以看出,随着标签数的增加,各种算法所用的总时隙数均逐渐增加;和八叉树算法、QT算法相比,DGMQT算法所用的总时隙数增幅更小;当标签数为1 000时,DGMQT算法所用总时隙数为1 388,比八叉树算法、QT算法所用的总时隙数分别减少64%、50.4%;和A4PQT算法、GBAQT算法相比,DGMQT算法所用的总时隙数增幅较小,随着标签数的增加,GBAQT算法的优势更明显。这是因为GBAQT算法中的双重分组提高了碰撞信息处理效率,而对位映射使该算法可通过避免产生空闲时隙减小总时隙数。

图5 不同算法所用总时隙数Fig.5 Total number of time slots of different algorithms
由图6可以看出,DGMQT算法的系统效率保持在0.7以上,远高于其他算法的系统效率。

图6 不同算法的系统效率Fig.6 System efficiency of different algorithms
由图7可以看出,DGMQT算法的时隙利用率最大达到1.0,其他算法的时隙利用率由大到小依次为GBAQT算法>QT算法>A4PQT算法>八叉树算法。这是因为DGMQT算法避免产生空闲时隙,所以识别过程中产生的时隙均为碰撞时隙,而通过碰撞时隙可有效地得到碰撞位置信息,得到的时隙利用率较高。
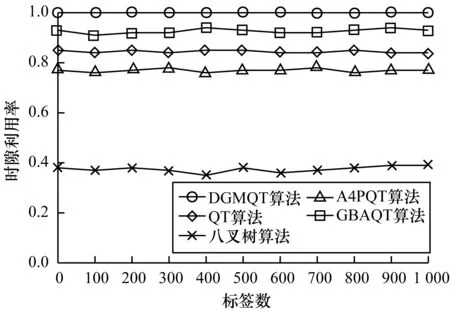
图7 不同算法的时隙利用率Fig.7 Slot utilization of different algorithms
由图8可以看出,QT算法和八叉树算法的通信复杂度较高;A4PQT算法采用了剔除分支策略,因而其通信复杂度有所下降;GBAQT算法和DGMQT算法的分组思想使其通信复杂度较低,其中DGMQT算法的通信复杂度最低,识别1个标签仅需300 bit。
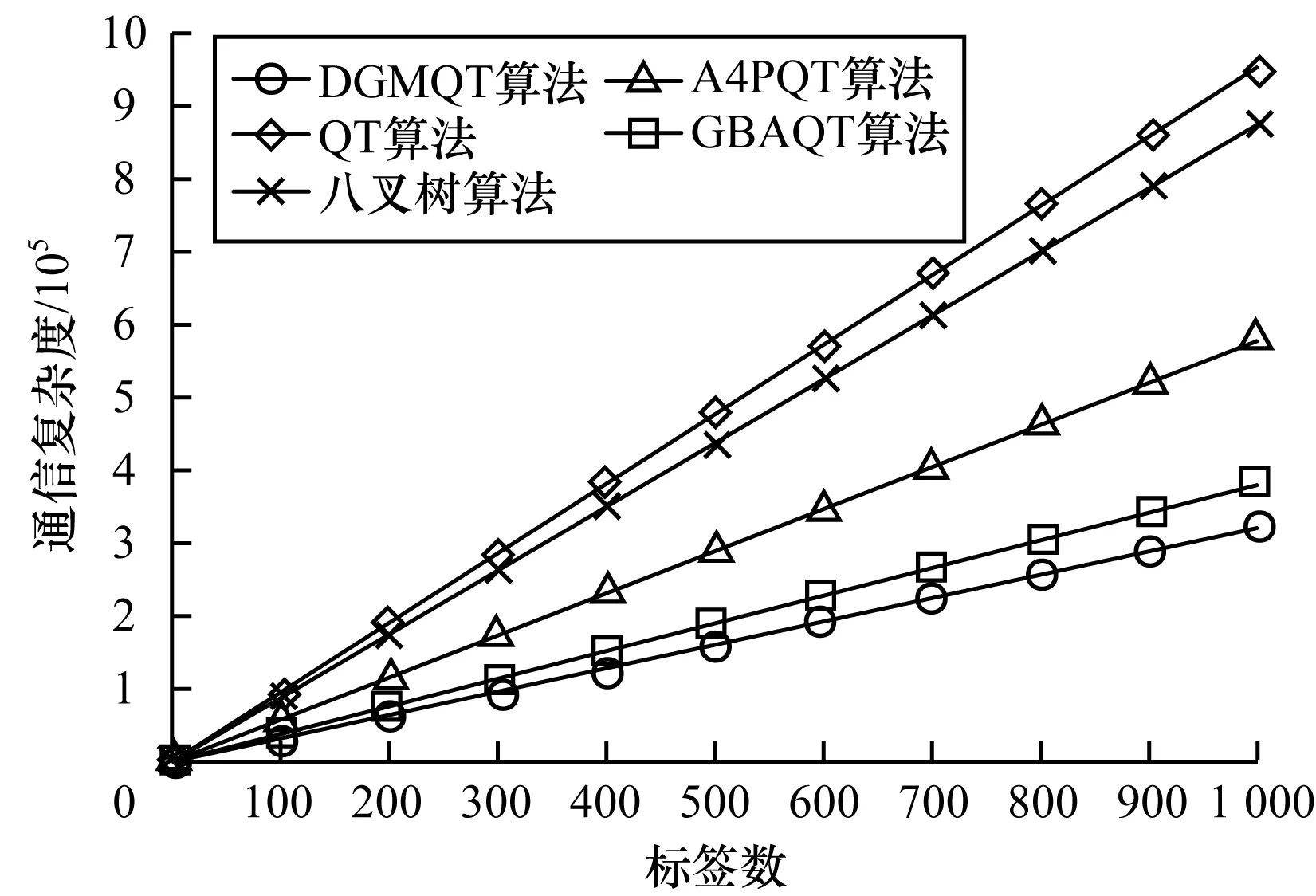
图8 不同算法的通信复杂度Fig.8 Communication complexity of different algorithms
5 结束语
本文基于查询树的树形结构,结合映射机制设计对位映射方案,提出一种基于双重分组和对位映射机制的查询树算法。采用双重分组的方式将标签识别码分为两组,每一组赋予不同的组标签,设计对位映射的规则,将识别码数据映射为识别度极高的映射数据,通过对识别码细粒度的划分消除识别过程中的空闲时隙,从而提升算法识别效率。仿真结果表明,本文算法可以消除查询空闲时隙,具有较好的系统效率、时隙利用率和良好的通信复杂度,在多标签的情况下其各项性能显著优于其他算法。下一步将使用硬件技术对阅读器端与天线端进行更细致地分组,以提升系统的性能。
