基于随机森林与人工免疫的入侵检测算法
2020-08-19张建伟桑永宣侯泽翔
张 玲,张建伟,桑永宣,王 博,侯泽翔
(郑州轻工业大学 软件学院,郑州 450002)
0 概述
入侵检测系统[1]被证明是一种有效的网络安全防御方式。研究人员将深度学习、支持向量机[2-3]、模糊集[4]、隐马尔可夫[5]、随机森林[6-8]、离群点算法[9]、人工免疫原理[10-12]等人工智能技术引入入侵检测进行研究,取得了较大的进展[13-15]。
文献[3]提出了一种多层次的混合入侵检测模型,该模型利用支持向量机和极限学习机来提高检测已知和未知攻击的效率,采用K-means算法来构建高质量的训练数据集,提高了分类器的性能。文献[4]提出了一种采用修正密度峰值聚类算法和深度信念网络的入侵检测系统(MDPCA-DBN),该系统采用改进的密度峰值模糊聚类算法减少训练集的大小,利用深度信念子网络对数据进行分类,解决样本的不平衡问题。文献[5]设计并实现了基于网络的反对抗隐马尔可夫模型(AA-HMM),定义了一个模式熵的概念,使用动态窗口和阈值技术提高系统的自适应、抗竞争和在线学习能力。
文献[6]受bagging算法和随机分割选择算法的启发提出随机森林(Random Forest,RF)分类算法。文献[7]设计并实现了基于条件式自编码、生成式对抗网络和随机森林的入侵检测系统(AE-CGAN-RF),该系统采用自编码技术对高维特征数据进行降维,利用生成式对抗网络进行数据采样,运用随机森林的方法进行分类,解决了在大型网络环境中出现的高维特征和数据不平衡问题。文献[8]利用不同决策树之间的相似度,约简决策树中的冗余值,用分类性能指标值作为随机森林的权重值,提高网络流量分类的可扩展性和检测率。文献[9]提出了一种混合多层次入侵检测模型,利用离群点检测算法对冗余数据进行约简删除,根据攻击行为网络流量的相似性,构建多层次随机森林模型检测网络异常行为,提高网络攻击的检测性能。文献[10]提出一种动态克隆选择算法。人工免疫系统通过一个类似于生物免疫系统的功能构建了动态、自适应的信息防御系统。为了抵抗外部无用和有害信息的入侵,并确保有效性和接收到无害信息,文献[11]提出一种改进的克隆选择算法,选择较好的个体并进行克隆,提高入侵检测的准确率,降低误报率。
支持向量机、模糊集、离群点、随机森林检测算法需要对大量的样本进行学习,获得有效的决策规则,并且系统自适应能力较弱,因此针对小样本数据进行学习的效果较差,导致入侵行为的误检和漏检。人工免疫原理在自适应能力方面优于其他算法,但是存在过早收敛的现象。
本文提出一种基于随机森林和人工免疫的入侵检测算法(RFAIID),并构建抗体森林模型。针对样本集中的小样本,采用克隆选择算法获得优良的大样本抗体集提高入侵检测的自适应性,运用随机森林算法提高入侵检测率,降低误报率。在KDD99数据集上对RFAIID算法的参数进行设置,并在小样本集上验证算法的自适应性和检测性能。
1 RFAIID算法
RFAIID算法主要包括4个阶段:
1)对训练数据和测试数据进行预处理,将两种数据集处理成统一格式的抗体集和抗原集。
2)数据选择阶段,对不同类型的抗体总数分别进行统计,对样本数量较少的抗体集采用人工免疫算法提高抗体质量和数量。
3)对新的抗体集采用多代理随机森林分类器。
4)对抗原进行检测得到检测结果,并将新的抗体加入抗体集。
RFAIID算法的功能结构如图1所示。

图1 RFAIID算法功能结构Fig.1 RFAIID algorithm function structure
抗体的数量和质量决定抗原的检测性能指标的好坏。随机森林算法对于决策树数量较少时,分类能力较弱,只有当决策树数量较大时,才能够得到有效的分类结果。因此,针对小样本的数据集采用基于人工免疫的抗体优化算法能获得更优的抗体集。RFAIID算法的实现步骤如算法1所示。
算法1RFAIID算法
输入数据集、参数KNormal、KDos、KProbe、KU2R、KR2L、激活阈值γ
输出网络异常行为检测结果
1.用式(1)将数据集进行归一化处理;
2.归一化后的数据集划分成训练数据集和测试数据集;
3.用抗原定义对测试数据集进行预处理,用抗体定义对训练数据集进行预处理;
4.将抗体分成不同的种类;
5.判断抗体的数量,抗体优化得到新的抗体集;
6.将新的抗体集训练成随机抗体森林;
7.利用随机抗体森林对抗原进行检测,得到检测结果;
8.将获得的新的抗体用于更新随机抗体森林。
1.1 数据集预处理
RFAIID算法的第一个步骤是对数据集进行预处理,训练数据集归一化处理成抗体集,待检测数据处理成抗原。
设x为日志的属性值,x∈[m1,m2],对RFAIID算法中的抗原和抗体的处理方法采用式(1)归一化处理[12]。
(1)
其中,m和n分别取该数据域内的最小值和最大值。
根据抗原、抗体的定义对数据集进行预处理:
定义1a∈A,A⊂D,D={0,1}l,(l∈N,l>0),A为待检测日志抗原集,D是由0和1代码组成的长度为l的二进制字符串,抗原a为待检测日志属性的二进制字符串[12]。
定义2抗体b∈B,B{
1.2 基于人工免疫的抗体优化方法
抗体的数量和质量决定抗原的检测性能指标的好坏。随机森林算法对于决策树数量较少时,分类能力较弱,只有当决策树数量较大时能够得到有效的分类结果。因此,针对小样本的数据集采用基于人工免疫的抗体优化算法获得更优的抗体集。基于人工免疫的抗体优化算法的实现步骤如算法2所示。
算法2基于人工免疫的抗体优化算法
输入训练抗体、参数KNormal、KDos、KProbe、KU2R、KR2L
输出新的抗体集
1.BNormal=BProbe=BDos=BU2R=…=BR2L=∅;/*存储不同抗体的抗体集*/
for each b in抗体集
将网络日志转换为抗体;
判断b.s的值,根据b.s的值分别将抗体加入不同的类型的抗体集,并进行计数;
end for
/*if (b.s==0000) then BNormal.add(b)数据取0时,表示该抗体的类别是Normal
else if(b.s==0001) then BProbe.add(b)数据类型值取1时,表示该抗体的类别是Probe
else if(b.s==0010) then BDos.add(b)数据取2时,表示该抗体的类别是DoS,等*/
2.for each 抗体集
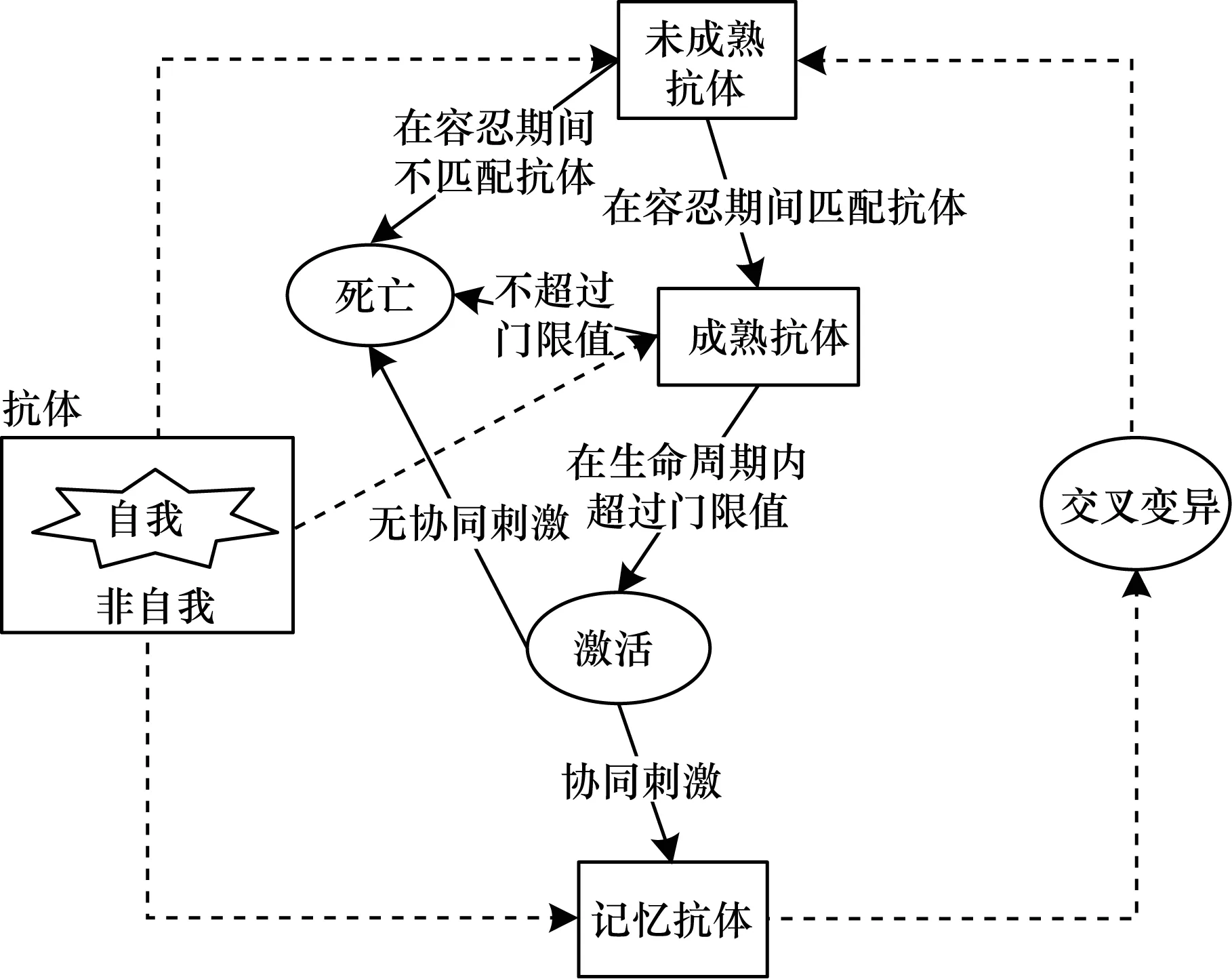
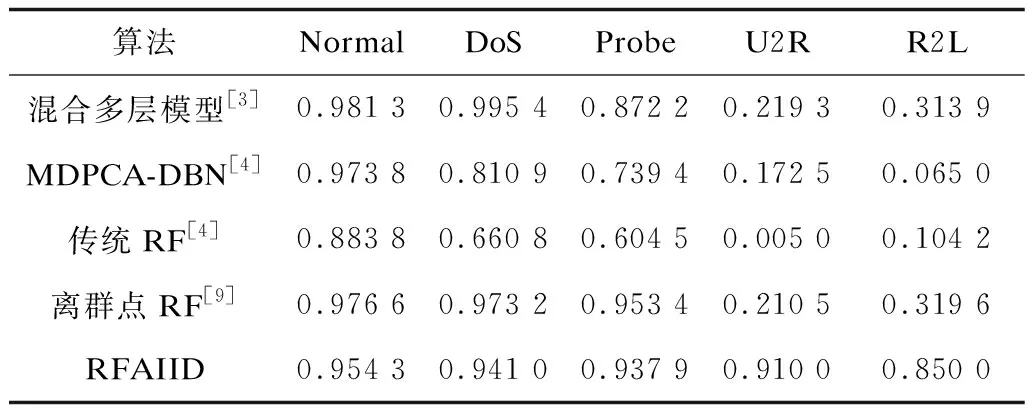
if (计数值 抗体生成算法; end for 本文用三元组Ω=(A,B,Θ)表示免疫进化操作,A={S,N}表示抗原集合,S为自体集合,N为非自体集合,S∩N=φ,B=BI∪BT∪BM为抗体集,Θ表示抗体交叉、变异。在抗体的生命周期内,抗体不断变化。RFAIID中采集到的日志信息是动态变化的,A随着动态变化。新抗体生成演化过程如图2所示。 图2 抗体演化示意图Fig.2 Schematic diagram of antibody evolution a与b之间的亲和度计算采用欧拉(Euclidean)形态空间的欧拉距离计算方法[12]。 抗体优化算法如算法3所示。 算法3抗体优化算法 输入选择抗体,参数T1、T2、γ 输出新的抗体 1.选择适应度高的记忆抗体进行高斯变异; 2.将变异后的抗体注入BI; 3.随机生成未成熟抗体,注入BI; 4.未成熟抗体在生存时间T1内,如果大于T1,则删除该未成熟抗体,否则计算抗体与抗原适应度; 5.抗体匹配到任何一个抗原,则删除抗体,否则注入BT; 6.成熟抗体T2内,判断是否大于激活阈值,大于则删除成熟抗体,小于则激活; 7.将激活的成熟抗体注入BM,转步骤1。 RF是包含多个相同分布的决策树集合,每个决策树依赖于一个独立的随机向量[16]。RF的基本思想如下:在包含N个训练样本的数据集X中,通过有放回地随机的方式获取k个样本(0 为弥补因抗体样本数量的不足导致的较高的检测错误率,并获得优良的抗体提高检出率,降低误检率,本文借鉴随机森林和人工免疫理论对抗体决策树设计了随机抗体森林检测策略。随机抗体森林检测策略模型如图3所示。 图3 随机抗体森林检测模型Fig.3 Random antibody forest detection model 提高抗体森林分类模型的外推预测能力对入侵检测至关重要,因此需要生成不同的抗体集来增加抗体森林分类模型之间的差异,通过k轮的训练,得到一个抗体决策树集合{h1(b),h2(b),…,hk(b)},再经过少数服从多数的投票法,得到最终的抗体森林: (2) 其中,H(b)是抗体森林分类模型,hi(b)是单个决策抗体树的分类结果,Y表示抗体检测抗原的输出目标变量,I(·)是抗体森林代表的示性函数,运用抗体决策树对抗原进行检测,检测结果为ai.lable,例如检测结果为Probe,用式(3)计算I(·): (3) 随机抗体森林检测算法如算法4所示。 算法4随机抗体森林检测算法 输入抗体集 输出抗原的检测结果 1.对于每种类型的抗体集生成不剪枝的抗体决策树集合,用式(2)生成抗体森林H(b); 2.用抗体森林H(b)对抗原进行检测; 3.如果检测结果为正常,转步骤1; 4.如果检测结果为一种类型的攻击行为,将抗原转化为抗体,将抗体加入抗体集,转步骤1。 采用美国林肯实验室提供的KDD数据集[19]进行实验仿真,研究RFAIID算法的性能。实验中采取数据集中的kddcup.data_10_percent作为数据源。数据集中包含Normal、Dos、Probe、U2R和R2L 5种样本。 实验仿真中抽取50 000条数据,根据文献[12]将训练数据集转化成抗体,测试数据集预处理成抗原,抗原的长度为92,检测器(记忆抗体)的长度取值95、耐受期未成熟抗体的生命周期取值40、成熟抗体的生命周期取值50、激活阈值γ=5[20]。非记忆抗体的数量设置为100,抗体与抗原的匹配半径在2.2节给出。 RFAIID算法用C编码,所有的实验在Linux平台下运行(Intel Pentium Dual CPU E2180,16 GB RAM)。 IDS的检测结果包括TP、TN、FP和FN4种[12]。TN和TP对应IDS的正确预测的总数,即样本被正确分类为正常行为的数量或攻击的数量;FP和FN则对应IDS的错误分类的总数,FP指正常样本被误分类为攻击行为的数量,FN指攻击样本被错误识别为正常的总数。 RFAIID算法的性能评估指标主要包括以下5种: 1)抗体检测率DR是指抗原集中攻击行为被正确分类的比例,用式(4)计算抗体检测率。 (4) 2)抗体误报率FAR是指抗原集中所有被误识别为攻击的正常抗原个数与测试集中正常抗原总数的比值,用式(5)计算抗体误报率。 (5) 3)抗体精确率Pre是指抗原集中所有被IDS识别为攻击抗原中真正为攻击抗原的比值,用式(6)计算抗体精确率。 (6) 4)抗体分类准确率Acc是指抗原集中被正确分类的抗原个数与抗原集样本总数的比值,是一个反映IDS对正常抗原和攻击抗原区分能力大小的总体评价指标,用式(7)计算抗体准确率。 (7) 5)F1-score是综合评价IDS对抗原检测率和精确率的一个指标,用式(8)计算抗体F1-score指标。 (8) 为了确定算法3中抗体和抗原的匹配半径的值,对训练数据集中所有异常抗体标记为异常,生成抗体森林,对测试集进行异常检测,分别设置匹配半径值为30~50的21个整数值,取10%的数据进行交叉实验,运行10次,取平均值。检测结果如图4所示。 图4 不同半径下的检测结果Fig.4 Detection results under different radius 图4给出了在不同的匹配半径下抗原的检测率和误报率。由检测结果得出随着检测半径的增大,检测率增大,误报率降低。当检测半径长度为41时,检测率为94.8%,误报率为6.2%。当检测半径大于41时,检测率和误报率趋于稳定。在后面的实验中,取检测半径值为41。 样本集中不同类型的样本数量差别较大,当样本数量较少时,在分类效果上处于劣势。针对不同的训练样本集,数据集抽样原则如下: 1)DoS攻击:Dos攻击的训练集包含391 458条样本,属于大样本数据集。实验中取10组训练样本集,每组随机取训练数据集中2%、5%、10%、15%、20%、21%、22%、23%、24%和25%的样本集进行训练得到抗体森林,采用测试集进行检测,每组数据运行10次取平均值。 2)Normal:KDD99数据集中包含97 278条正常样本,虽然属于大样本数据集,为了计算KDos值,将Normal样本转化成正常抗体,进行克隆选择得到新抗体集、新抗体集和Dos攻击数值相同的数据集。在计算Probe和R2L攻击的检出率时,取相同的样本集。 3)Probe:Probe攻击训练样本数为4 107条,为小样本集。前3组分别取样本集中的样本,启动克隆选择算法获得后7组抗体集。每组数据运行10次得到抗体森林,并对测试集进行检测。 4)R2L:R2L攻击训练样本数为1 126条,属于小样本集。前2组分别取样本集中的样本,启动克隆选择算法获得后8组抗体集。每组数据运行10次得到抗体森林,并对测试集进行检测。 5)U2R:U2R攻击训练样本数为52条,属于极小样本集。第1组取全部样本,启动克隆选择算法获得后9组抗体集。每组数据运行10次得到抗体森林,并对测试集进行检测。不同样本集的抽样数量如表1所示,实验仿真结果如图5所示。 表1 实验样本数Table 1 Nunber of experimental samples 图5 不同攻击识别结果Fig.5 Recognition results of different attacks 从图5检测结果可以得出,随着抗体样本数量的增加,抗原检测率随之增加,当样本集增大到一定数量时,检测率趋于稳定,检测率稳定的拐点设置为样本数值K。 1)随着DoS攻击抗体样本数量的增加,检测率随之增加。当抗体样本数量为40 000条时,DR值趋于稳定,KDos值为40 000,对应的正常样本数为40 000条。 2)随着抗体Probe攻击样本数量的增加,检测率随之增加。当抗原Probe攻击样本数量为8 000条时,DR值趋于稳定。因此,取KProbe值为8 000,对应的正常样本数为88 000条 。 3)随着R2L攻击抗体样本数量的增加,检测率随之增加。当抗原R2L攻击样本数量为3 500条时,DR值趋于稳定。因此,取KR2L值为3 500,对应的正常样本数为88 000条。 4)从识别结果可以得出,随着抗原U2R攻击样本数量的增加,检测率随之增加。当抗原U2R攻击样本数量为200条时,DR值趋于稳定。因此,取KR2L值为200,对应的正常样本数为60 000条。 综合以上4种情况,随着样本集数量的增多,检测率随之增加,证明本文提出的RFAIID算法具有可扩展性,通过实验得到KNormal=88 000,KDoS=40 000,KProbe=8 000,KR2L=200。 为了更好地验证本文提出的算法,在KDD99数据集上运行RFAIID算法,算法的参数详见2.1节~2.3节。将RFAIID与概述部分的算法进行对比,将所有攻击行为作为异常样本进行检测。由于异常样本属于大样本数据集,因此参照Dos攻击,每组随机取训练数据集中10%、15%、20%、21%、22%、23%、24%和25%的样本集进行训练得到抗体森林,采用测试集进行检测,每组数据运行10次得到平均值。不同算法异常检测性能对比结果如表2所示,N/A表示结果不明确。 表2 不同算法异常检测性能比较Table 2 Comparison of abnormal detection performances of different algorithms 从表2结果可以看出,本文提出的RFAIID算法检测率比文献[3]低0.010 7,准确率高0.007 2,误报率低0.007 1,性能相近;比文献[11]提出的改进克隆选择算法的性能差;检测性能比其他算法要高。 为测试RFAIID算法的分类性能,尤其是对小样本数据集的检测,将RFAIID算法和表2中算法进行比较,不同攻击类型下的算法检测率比较如表3所示。 表3 不同算法分类性能比较Table 3 Comparison of classification performance of different algorithms 从表3可以看出,本文提出的RFAIID算法对小样本数据Probe、U2R和R2L攻击的检测性能优于其他算法。因此,得出RFAIID算法对各种攻击的检测率都较高,可提高算法的自适应能力,对小样本的检测性能较高。 在网络异常检测中,训练集样本的数量和质量决定了检测的性能。目前较多入侵检测系统的自适应能力较差,小样本数据检测率较低。针对该问题,本文提出一种基于随机森林和人工免疫的入侵检测算法(RFAIID),并构建了抗体森林的模型。通过人工免疫算法提高系统的自适应能力,针对小样本数据提取较优良的抗体,提高检测性能,并结合人工免疫算法给出抗体森林检测的分类方法。实验结果表明,该算法具有较好的自适应能力,且检测率较高。由于算法中的冗余属性影响检测速度,因此下一步将对冗余属性进行降维。1.3 新抗体生成方法
1.4 随机抗体森林检测策略

2 仿真结果与分析
2.1 测试数据和性能指标
2.2 匹配半径
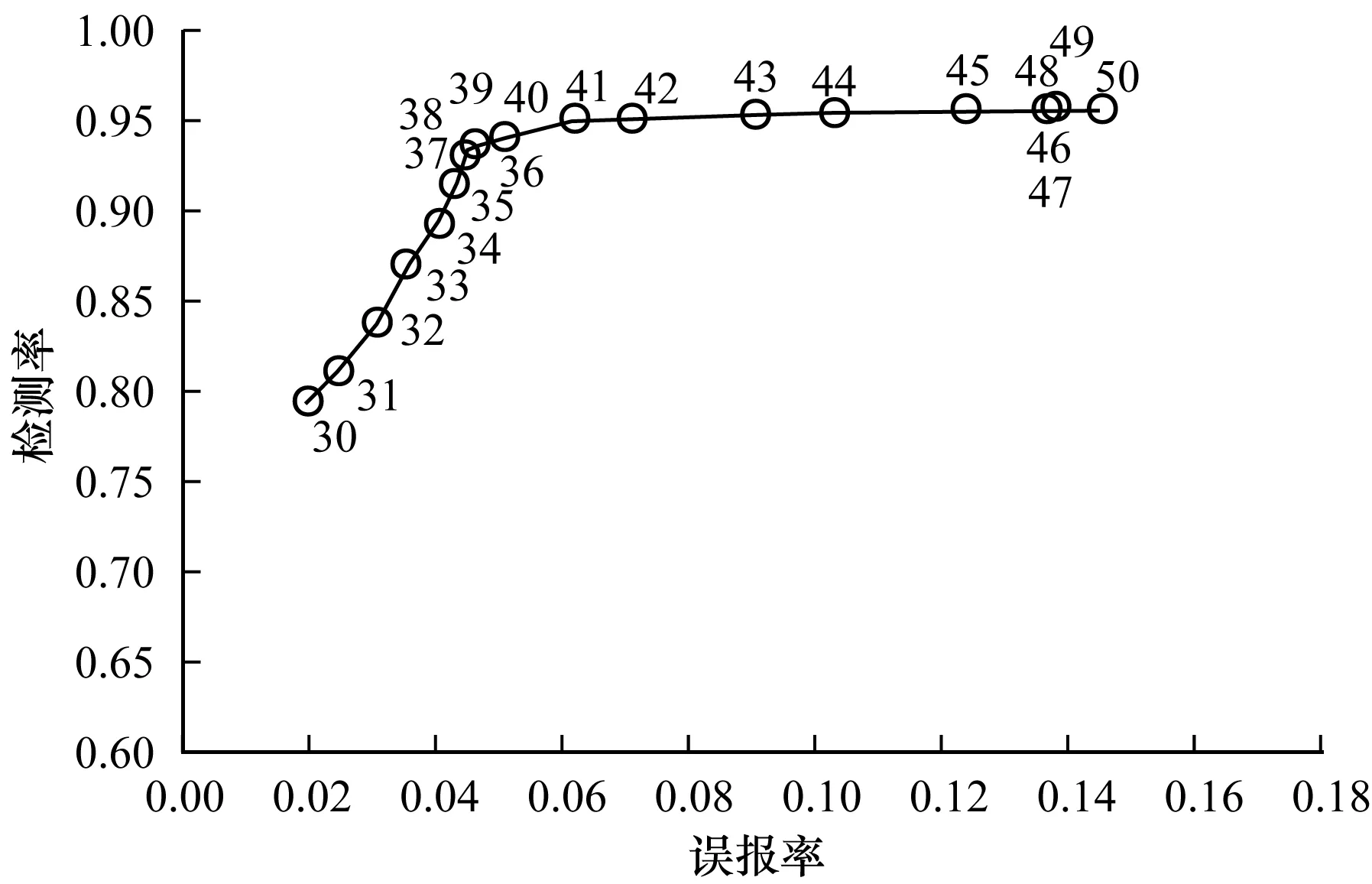
2.3 参数K的设置

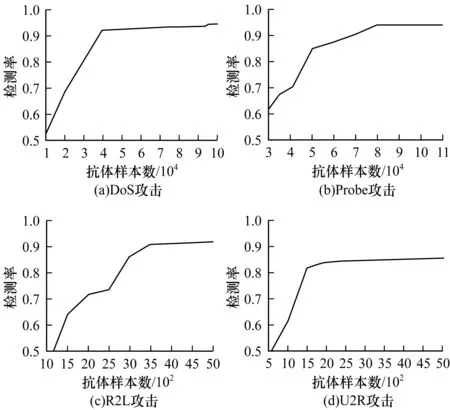
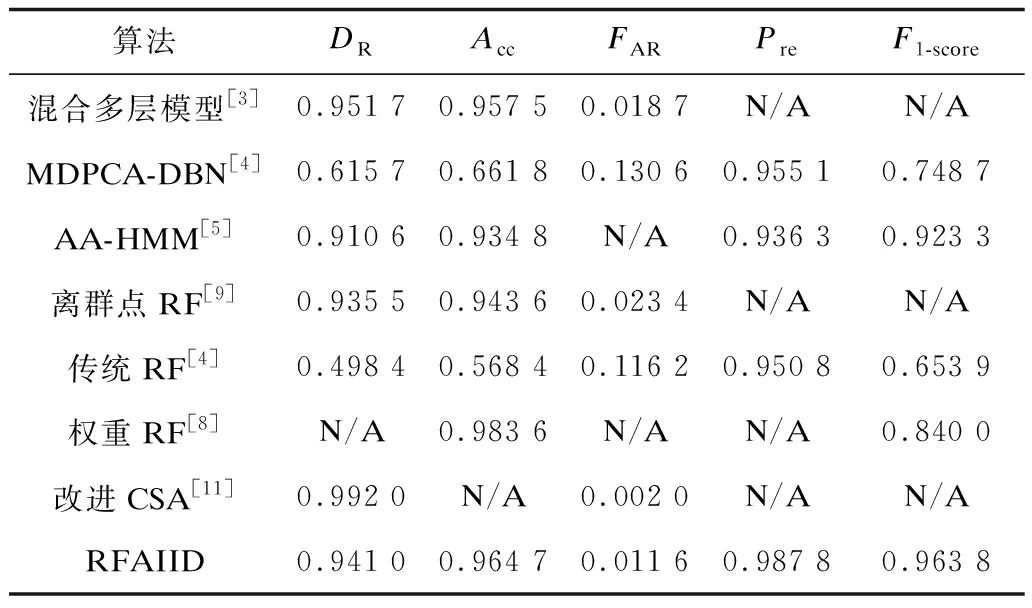
2.4 RFAIID算法的分类性能和其他算法的比较
3 结束语
