利用激光光谱SVM识别算法对煤种识别的研究
2020-08-19李旭升
张 建,滕 耀,李旭升
(丹东东方测控技术股份有限公司,辽宁 丹东 118000)
目前,我国工业领域中的主要能源煤炭占比超过50%.根据目前煤炭的产量及需求来看,已经处于供大于求的现状,同时由于能源行业的经济形势下滑及人力匮乏,工业领域对于自动化和信息化的需求日益增加。焦化、煤炭等工业领域对于煤炭煤种的识别,提高煤炭堆放效率有着迫切的需求。激光元素分析技术是现阶段最佳的煤炭检测及分析技术,其特点是无放射性、非接触式快速测量,可以通过激光激发煤炭中不同元素的光谱,并通过光谱中的元素峰位及峰值强度识别不同产地的煤炭。
煤炭种类识别大致有两种方法,一类是基于定量分析的煤种鉴定方法,此方法通过化验或其他检测手段,对煤炭进行定量分析,得出样品的化学组成成分及准确含量,再通过与标准煤样进行对比,确定对应的煤种信息。此方法时间长,工作量大,要求高,不符合现场对于快速检测的需求。第二类方法是采用SVM(支持向量机)分类算法[1-3],对已知煤种进行数据采集,通过提取特征点,建立数学模型,再对模型进行优化,通过分类算法建立的模型,验证未知煤样的数据。此分类方法结合激光元素分析技术,能够快速识别煤种信息并分类。
1 工作原理
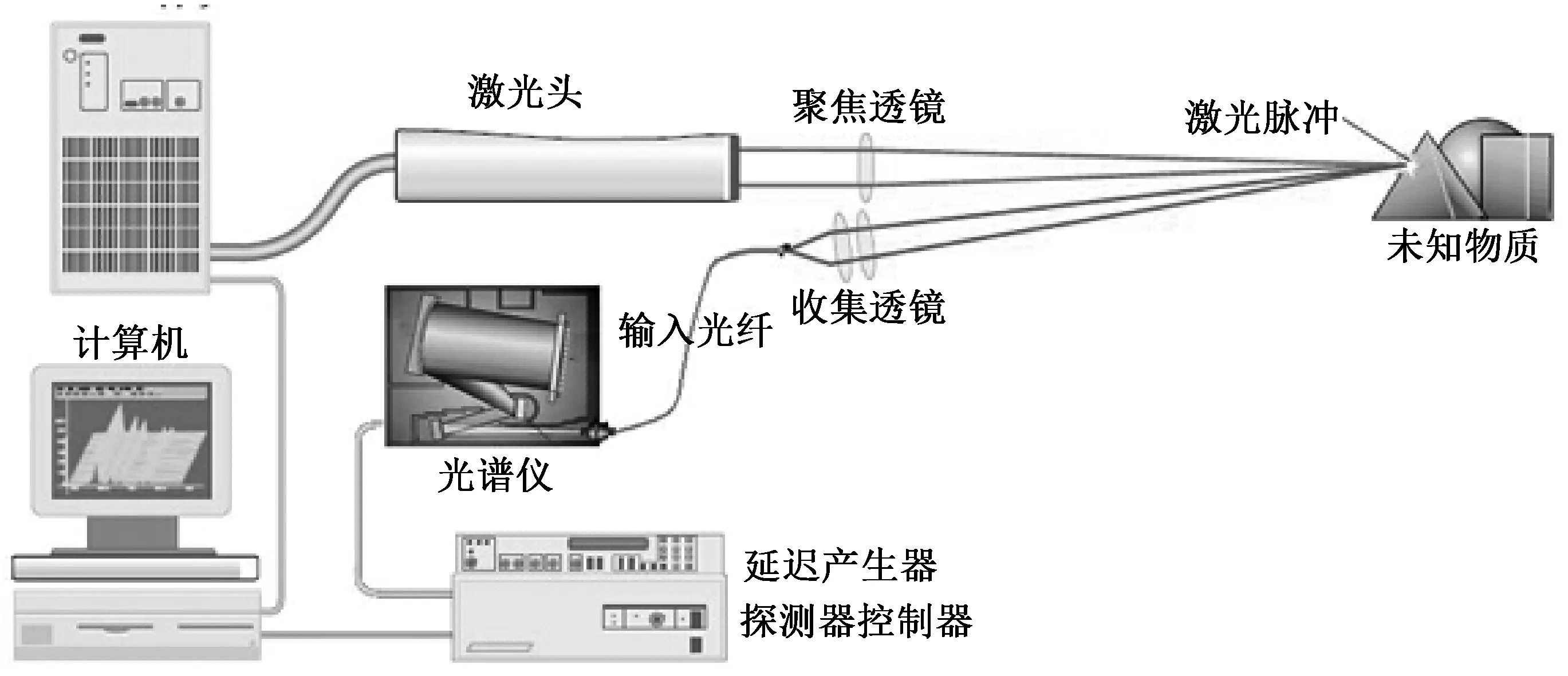
图1 激光元素分析工作原理图
2 实验原料准备
2.1 原始样品说明
对某焦化厂提供的多个产地的煤炭样品,采用激光光谱分析和SVM识别方法分析其产地来源,并依照对应的煤炭产地进行识别,将不同产地的煤炭放置于相对应的料仓中。
根据激光光谱分析原理,可以准确分析煤炭样品中的元素种类及含量,利用光谱定性分析元素成分,并利用SVM识别算法,对煤炭样品进行分类,同时煤炭中的灰分、水分是由C、H、O、Si、Al、Fe、Ca、K、Na、Ti元素组成,因此对于激光光谱和识别分类处理没有影响。
另外在识别煤种的同时,可以通过激光光谱对煤炭进行静态标定,并建立数据模型,测量煤炭中灰分、水分、热值、全硫等技术指标。本文主要对煤炭种类识别进行分析,不对煤质工业指标的测量方法做进一步介绍。
2.2 原始样品预处理
测试样品是某焦化厂提供的21组、11个产地的煤炭样品。由于煤样粒度较大,为保证测试样品的均匀性及准确性,采用人工方法对现场煤炭进行破碎缩分至6 mm.21组煤样样品产地及品种见表1.
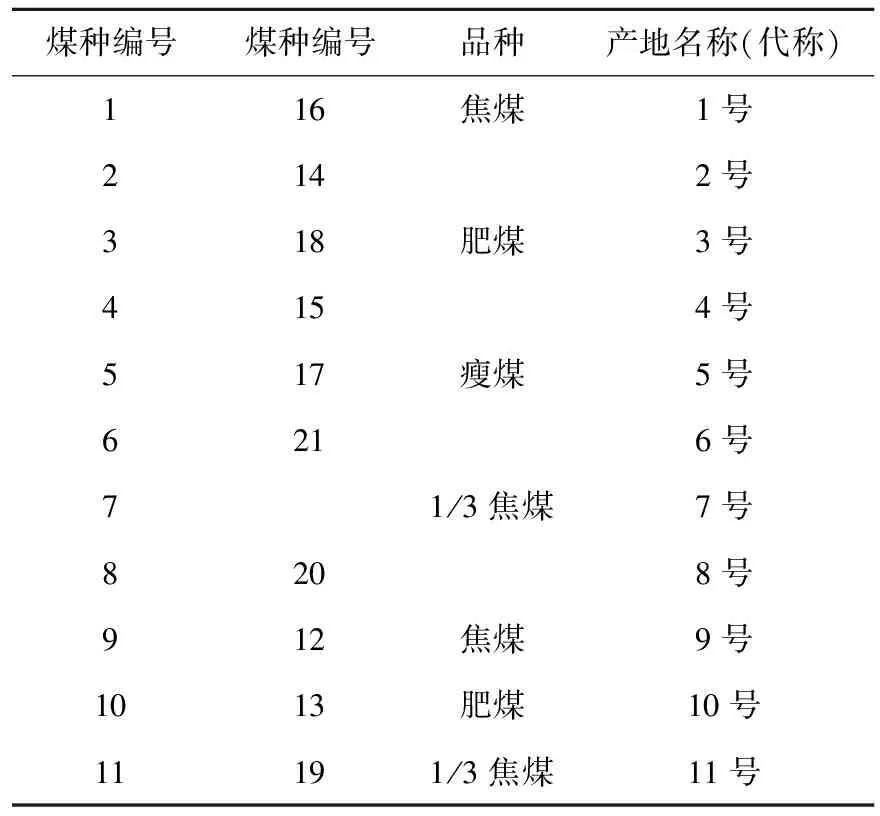
表1 煤样样品产地及特性表
2.3 混合样品处理
为保证检测数据分类识别的准确性,在原始煤炭样品的基础上,将相同产地的煤样进行混配。21组煤样混配结果见表2.
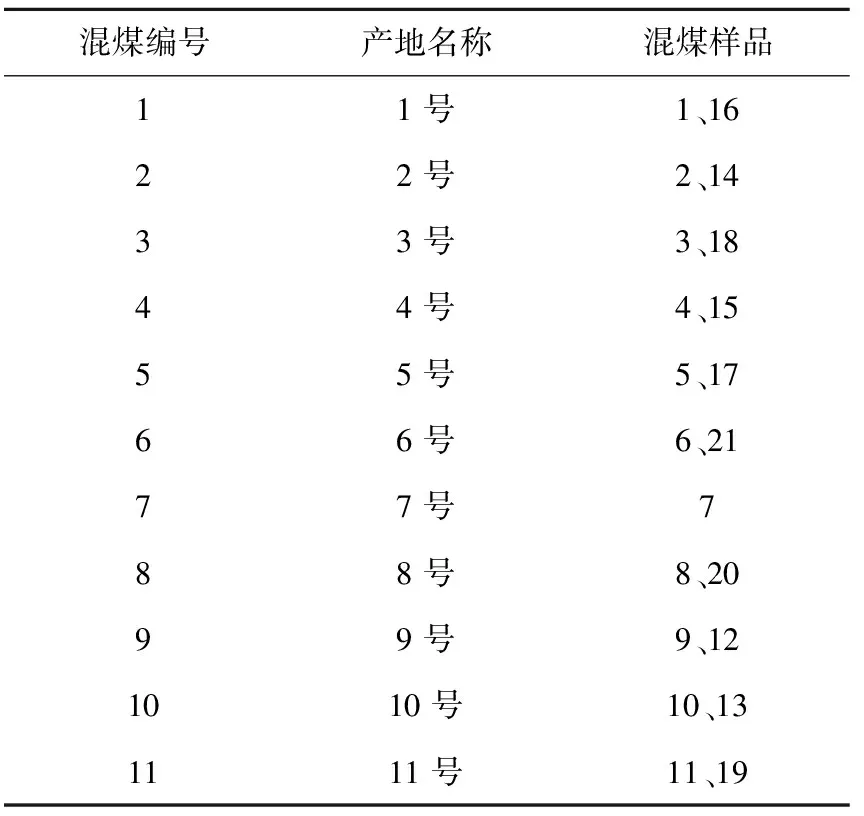
表2 混配样品表
3 检测方法
3.1 实验参数
1)激光器能量112 mJ,波长1 064 nm.2)光谱仪检测180~850 nm.
3.2 检测方法
将每份样品放置在平行皮带上,通过物料平整器,将物料刮平,保证检测装置相对一致。对物料进行激光打点,每个样品打点100次,每次打点可以获取一张完整的光谱数据。为保证数据重复性,每组样品测量两次。
3.3 数据预处理
1)对应煤种识别谱线,进行去基底、谱线对照、自动寻峰等预处理。
尹军平表示,虽然物流市场的并购渐成风气和趋势,但是并购所面临的挑战和风险仍然很大,而且并购的玩家依然要只属于少数的物流企业。物流企业依然从修炼内功做起,战略重心应该围绕性价比、扩流量、业务综合化、国际化四个方面展开,而且优先顺序不能颠倒。否则不仅并购无法达到预期,而且会拖累整个企业的发展进程。
2)针对煤种识别数据,通过人工寻峰找到对应的C、H、O、N、Si、Al、Fe、Ca、K、Na、Ti等122个峰位。
3)将通过人工寻峰找到的峰位对应的峰值计算出来。
4)对每张谱线的特征峰位进行整体归一化处理。
5)将每种样本取不同区间的平均值进行演算,得到最终的分类结果。
4 分析结果
4.1 原始煤种测量结果
1)将数据结果分成两类,一类是第一次测量结果,第二类是第二次的重复性数据。用第一次的测量结果作为训练集,第二次的重复性数据做预测集。
2)每个煤种100张光谱,取每1张的平均值计算,通过11组训练样迭代运算得到模型,再利用模型计算验证样本,匹配率79%,测量结果见图2.
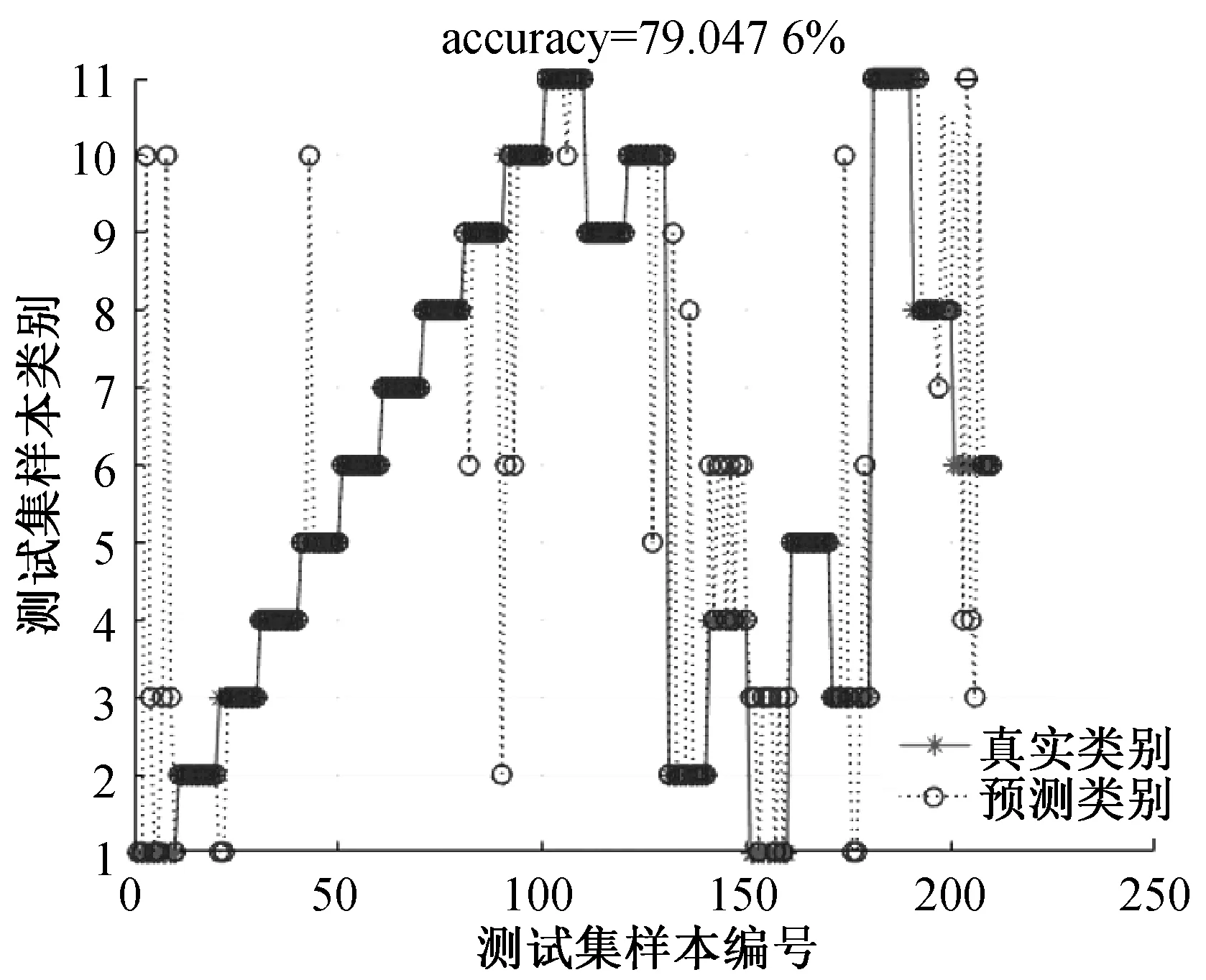
图2 原始煤种分类结果图
4.2 混合煤种测量结果
1)将混合煤种第一次测量结果计算当做1号预测集,将第二次的混合煤种重复性数据当做2号预测集。
2)使用原始煤种的数学模型计算的79%的模型对1号、2号预测集进行计算。
3)每个煤种100张光谱,取每10张的平均值计算,通过11组训练样迭代运算得到模型,再利用模型计算验证样本,测量结果见图3,图4.
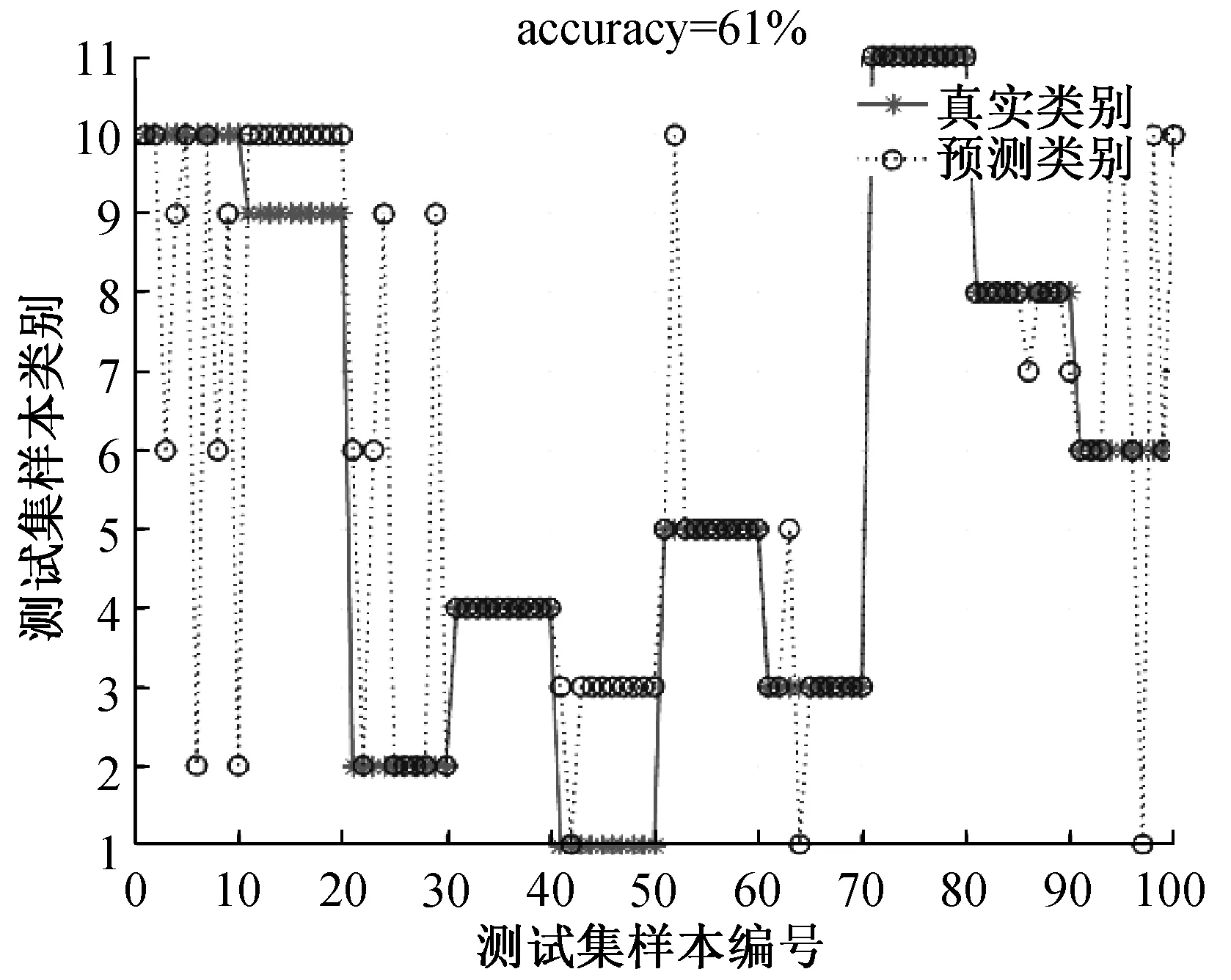
图3 1号预测集计算结果图
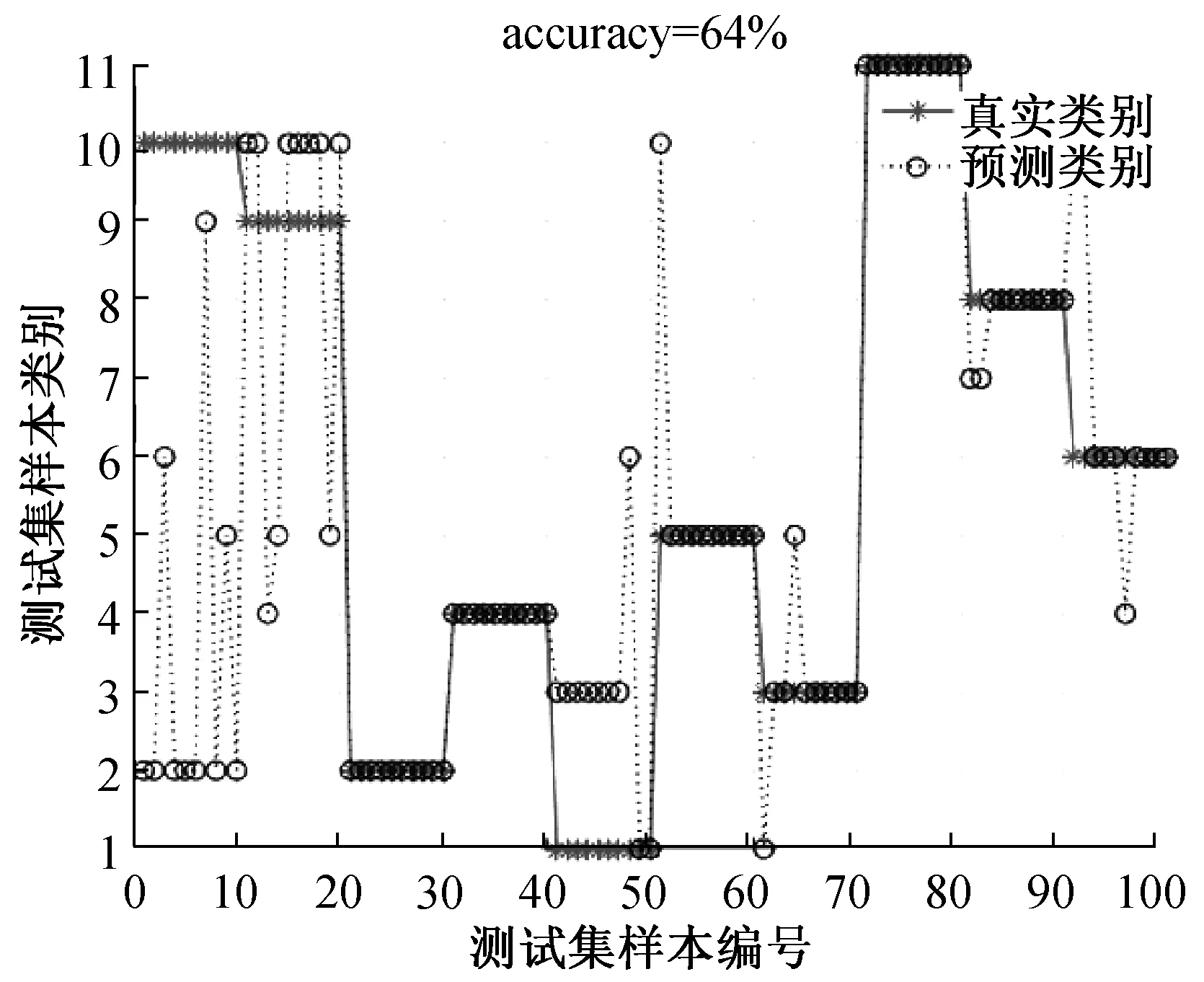
图4 2号预测集计算结果图
5 实验结论
1)通过观察不同煤种的激光光谱数据(图5)可以看出,21组煤样的测量结果的元素种类分布是一致的。由此可以判定,原始煤样的产地虽然不同,但是煤种一致。对于此类样品分类,如果采用化学和定量分析方法确定元素种类的区别或者元素含量,实现煤种识别是非常困难的。采用识别算法分析光谱特征,建立数学模型预测结果,是比较准确的。
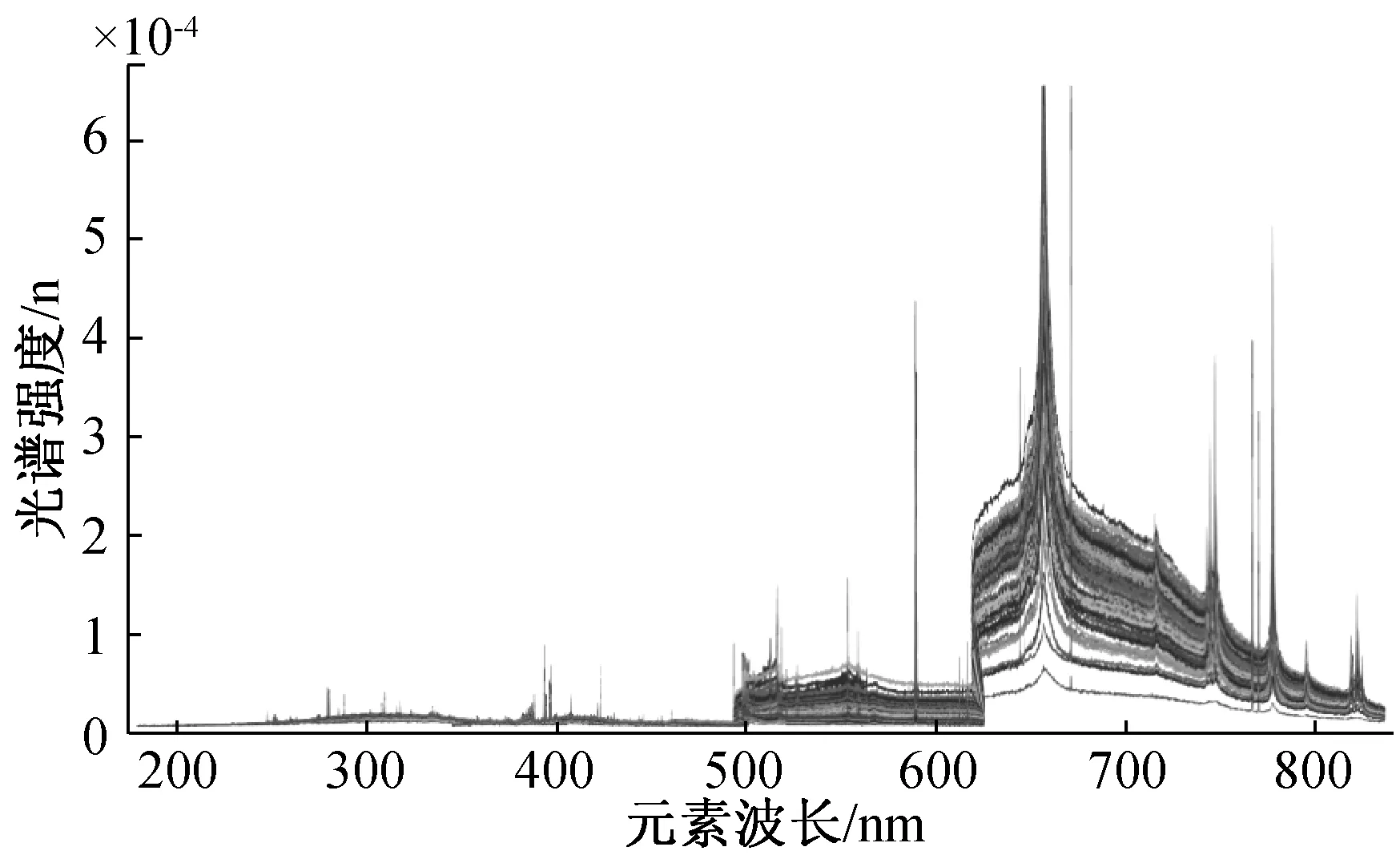
图5 煤炭样品光谱图
2)从图2可知,煤种总体识别率为79%,但是针对每一个煤样的识别分析,10个平均数据分类结果一般超过5个就可以认定此次的测量结果分类准确。因此从识别率来看,相对识别率可以达到90%以上。
3)从混料测量结果来看,煤种识别率有所下降,这是因为建立数学模型的数据没有覆盖到混合煤种,根据现场需求,如果进一步提高数据量,识别算法的模型将更加完善。
