基于共现图的混合标签推荐算法
2020-08-19田伟龚磊
田伟,龚磊
(四川大学计算机学院,成都 610065)
0 引言
随着 Web2.0 的发展,国内外涌现出像Quora、StackOverflow、知乎、百度知道等一批用户参与度很高的问答社区[1-2],人们越来越乐于在上面分享知识或寻找答案。问答社区的一个重要特点是可以由用户使用标签关键词[3-5]对资源进行标注,然后将资源按标签进行归类整理,形成一种全新的信息分类方式。在标签的产生过程中,用户可以采用带有主观认知的关键词作为标签,进而对信息内容进行高度的概括,标注的关键词可能没有在信息文本中出现,但却基本能反应信息的内容和含义。因此标签是一种有效的、以人为本的分类方法,在信息检索等领域有着重要的作用。问答社区中允许用户自由地对问题添加自定义标签,从而对网络资源进行组织,但是由于用户在标注标签时具有个人的随意性,而且问答社区在标注的选词范围和选词个数上都没有强制要求,这导致了标签的松散自由、模糊性、多样性等问题,不利于标签系统的进一步发展和应用。
现有的标签推荐系统[6-7]通过考察、分析、挖掘信息资源的内容以及显式或隐式的关系,为待标注信息的资源提供一系列高质量的标签作为候选,从而弱化用户的数据标注过程,提高标签质量。标签推荐技术大致可以分为三类[8]:基于内容(content-based)的标签推荐、协同过滤式(collaborative filtering)的标签推荐、混合(hybrid)推荐方法。基于内容的标签推荐[9-10]方法从被标注的资源自身特征出发,提取资源内容的关键词作为模型的输入;基于协同过滤的推荐方法[11-12]利用历史数据中用户、资源、标签之间的关系,借助集体智慧来为资源生成标签推荐列表;混合模型的标签推荐[13-14]是指结合协同过滤和基于内容的方法,发挥两者的优势,从而可以推荐更加丰富准确的标签。
问答社区中问题的标签推荐是指在用户需要标注问题数据时,及时提供准确地,能够反映用户意愿的标签,从而减少标签数据的无控制性,模糊性,冗余性等问题。本文通过历史数据分析问题标签可能的来源,例如:问题标题的关键词、问题内容的关键词、其他相关性的关键词等,提出了一种基于共现图的混合标签推荐算法。该推荐算法融合TF-IDF、关键词-标签共现图、相似问题集的标签信息,通过投票机制来实现问题的标签推荐。对于一个新的未标注的问题,该算法能从问题的词干、历史数据中关键词和标签的共现关系,以及基于语义分析相近问题集中已标注的标签等方面,综合分析问题文本,进而生成更为准确的标签推荐列表。
1 算法框架与实现
本文所提出的基于共现图的混合标签推荐算法框架如图1 所示,主要由五个部分构成:数据预处理模块、TF-IDF 模块、单词与标签的共现图模块、基于Word2Vec 的协同过滤模块,以及投票融合模块。数据预处理模块对文本数据进行分词、去停用词、提取名词等操作;TF-IDF 模块对文本中的关键词进行提取,并作为潜在标签;单词与标签的共现图模块基于单词与标签在文本中的共现关系构建共现图模型;基于Word2Vec 的协同过滤模块用于发现相似问题集的标签;最后,投票融合模块生成最终的标签推荐列表。
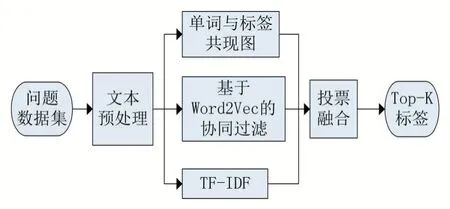
图1 推荐算法框架图
1.1 数据预处理
本文所使用的数据集是通过爬虫的方法从知乎问答社区上获取的半结构化的问答数据集,需要进行一系列的预处理,主要涉及中文分词、去停用词、词性标注、同义词统一。中文分词是自然语言处理(Natural Language Process,NLP)的一项基本技术,主要是将中文句子切割为一个个单词。在切割过程中,用户词典保证了在分词的过程中词典中含有的词不会被分割开。去停用词是指文本中出现的频率很高却没有实际意义的词汇(如:“我们”、“的”、“或者”等),这些词汇区分度较低,因此需要去掉。词性标注是在分词后对词汇的的词性进行标注,由于动词、形容词、副词不能表示句子的主干意思,因此本文仅保留名词词性的关键词。同义词在处理时需要对其统一形式,例如App、app、APP 均为出现频率很高的同义词,因此需要将这些同义词进行统一。最终,爬取到的半结构化的文本数据被转换为了具有意义的词列表数据,为后续研究的开展提供了基础。
1.2 TF-IDF标签生成模块
TF-IDF 利用统计方法来评估单词在语料库中的重要程度,单词的重要性与它在文本中出现的次数成正比,与它在语料库中出现的次数成反比。TF-IDF 实际是TF 与IDF 相乘,如公式(1)所示。TF 表示单词在文本中出现的频率,计算方式如公式(2)所示,IDF 则表示逆文本频率,即包含该单词的文本数越少,该值越大,计算方式如公式(3)所示。在实际计算中,TF 通常需要归一化,来防止结果值偏向长文本。
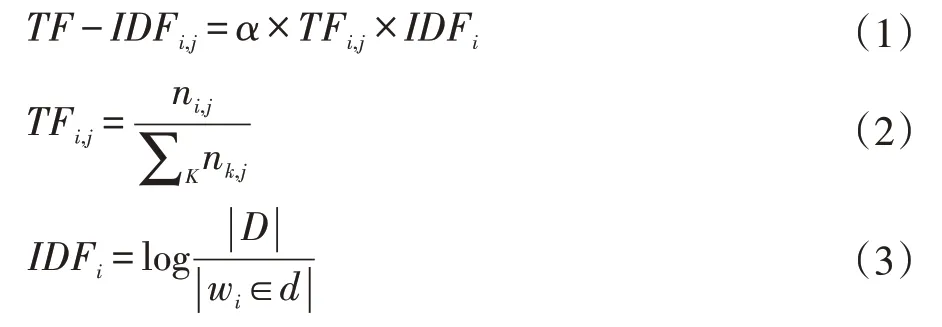
公式(1)中,根据单词出现在标题、正文等不同位置赋予不同的α值权重。公式(2)中,ni,j表示单词i 在文本j 中的出现频次,分母表示文本j 中所有单词出现的次数之和。公式(3)中 |D|表示语料库中的文本总数,分母表示包含该单词的文本数量。
对于预处理过后的每一个单词,使用公式(1)计算其TF-IDF 值,并按照该值以文本为单位对单词按降序排序,从而每一篇问题文本得到了按重要性排序的有序单词集合,排名靠前的单词则为TF-IDF 生成初始的潜在标签列表。
1.3 共现图的构建
在知乎问答数据集中存在着文本与标签的对应关系,本文将其转化为单词与标签的共现关系,可以利用二部图模型来表达单词到标签的共现关系。如图2 所示,图中左边的顶点为文本中出现的单词集合,右边的顶点为标签集合。若在同一个文本中,某个单词和标签共同出现,则该单词和标签之间产生一条边,边的权重取决于单词与标签关系的强弱,其计算方式如公式(4)所示。

式中:weighti,j表示单词i 与标签j 之间边的权重,occi,j表示单词i 与标签j 的共现次数,numi表示单词i的出现次数。
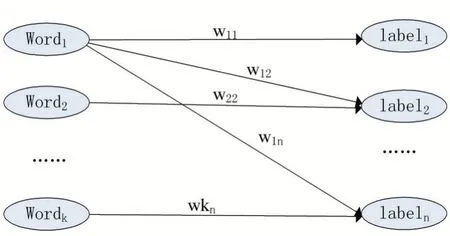
图2 单词与标签的共现图
构建完成单词与标签的共现图模型后,输入的新问题通过TF-IDF 对其关键词进行排序,然后关键词根据公式(5)在共现图中扩散到标签集合,得到与关键词相关的标签集合,按照标签得分降序排列后,排名靠前的标签即为共现图的推荐结果。
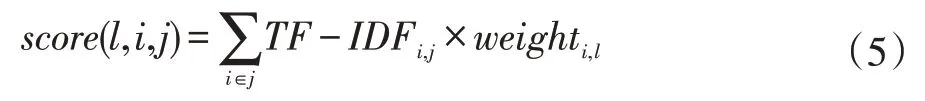
式中:i 表示单词,j 表示文本,l 表示标签。
1.4 基于Word2Vec的协同过滤
传统的文本相似度计算使用向量空间模型(Vector Space Model,VSM),这是因为一般文本中含有大量的单词,由每个单词构成的高维向量可以较好表示文本。但是一个问题文本往往由较少的单词构成,如果仍采用高维空间来表示问题文本,则会存在较大的稀疏性问题。因此,本文使用词向量模型(Word2Vec)将包含较少单词的问题文本映射到相应的语义空间中,然后在该语义空间中计算向量的余弦相似度来求解相似的问题集合。
首先统计文本集中的单词热度,选择热门单词集合来构成语义空间,利用语义空间的向量来表示一个问题,较单单利用问题本身的单词来表示一个问题,能更加准确的表示问题的含义。例如:一个问题只包含10 个单词,如果利用VSM 的方法来表示,包含的信息就很少,也存在词与词之间的语义鸿沟;如果将包含10个单词的问题利用Word2Vec 映射到m 维语义空间上,构造出的空间向量就包含更多有用的信息。公式(6)表示了单词wj通过Word2Vec 模型映射到语义空间Vi中。
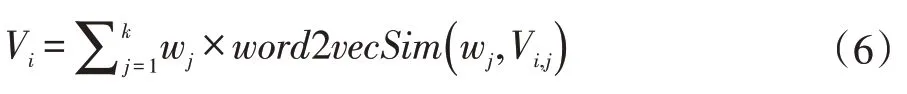
公式(7)表示了由初始的文本向量映射到m 维语义空间向量,再到计算文本相似度的过程。对于一个新到来的问题,先将文本映射为语义空间中的向量,然后计算向量的余弦值,得到相似问题集,取排名靠前的问题标签作为协同过滤的推荐结果。
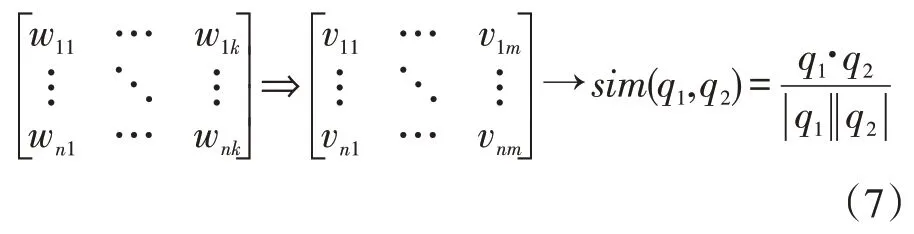
式中:k 为文本包含的单词数,m 为语义空间的维数,n 为文本总数。
1.5 投票融合模块
考虑到标签可能来源于文本本身,也可能来源其他问题的扩展,因此单一模型难以生成高质量的推荐结果,本文采用投票的机制对前述两种方法进行融合。投票的思想是利用少数服从多数的思想来给出结果的排序情况,设方法集合A={ }a1,a2,…,am,结果标签集合L={ }
l1,l2,…,ln,计算方式如公式(8)所示。

式中,vote 为指示函数,定义为:

最后,将标签按score 得分进行降序排序,取Top-K 为最终的标签推荐结果列表。
2 实验结果与分析
为了验证本文所提出方法的有效性,本文在真实的知乎问答数据集上进行了对比实验,将本文方法(Co-Tag)与目前流行的TF-IDF 方法、基于LDA 的标签推荐方法(LDA-Tag)和基于共现图的推荐方法(Co-Graph)进行了对比分析。
2.1 实验数据集
本文使用知乎问答社区互联网话题下的问答数据集来设计对比实验。该数据集是一种半结构化的文本数据集,过滤掉低质数据后,共包含有11786 条问题数据。本文将按照8:2 的比例划分训练集和测试集,每条数据包含3 个字段:问题标题、问题正文和该问题已标注的标签。表1 展示了实验数据集中标签的来源分布情况。
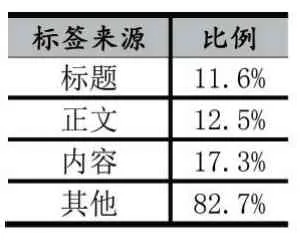
表1 标题分布的统计信息
2.2 评价指标
推荐算法最重要的属性是推荐准确性,常用的度量指标是准确率(Precision)和召回率(Recall),分别衡量了推荐系统的查准率和查全率。标签推荐最常用的评价指标是recall@k,它是在限制推荐结果数量的情况下计算召回率,其计算方式如公式(10)所示。

式中:k 为推荐的结果数量,tp 表示推荐正确的标签数量,fn 表示遗漏的标签数量。
recall@k 是在约束推荐结果数量的情况下比较命中比例,可以较好地反映推荐结果的有效性,因此本文采用recall@k 来评估本文所提出方法的有效性。
2.3 实验结果
本文将所提出的方法(Co-Tag)与目前流行的TFIDF 方法、Label-LDA 模型(L-LDA)、基于共现图的方法(Co-Graph)进行了对比实验。实验结果如表2所示。
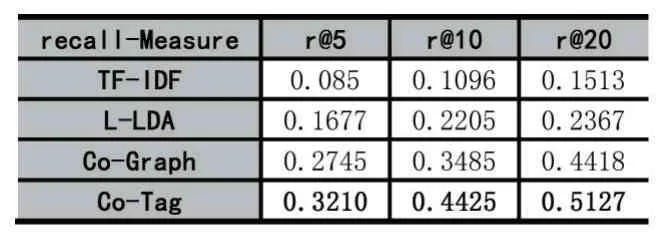
表2 实验对比结果(R@k 指标)
由表2 可知,本文提出的Co-Tag 方法在r@5、r@10 和r@20 中的召回率指标分别为0.3210、0.4425 和0.5127,相对于 TF-IDF、L-LDA 和 Co-Graph 方法都要好。由此可见,本文提出的基于共现图的混合标签推荐算法在问答社区中问题的标签推荐上具有更好的推荐效果。
除此之外,表2 对比结果还表明,基本的TF-IDF和L-LDA 在三种情况下的表现均是较差的,这说明仅基于本身统计信息的推荐方法具有很大的局限性。通过进一步分析实验数据集,发现标签较少来源于问题自身,这也进一步解释了TF-IDF 和L-LDA 效果差的原因。
3 结语
标签推荐算法可以简化用户的标注过程,提高标注质量,为标签系统的进一步应用起到了积极的作用。针对问答社区中问题文本包含的统计信息较少和问题的标签具有多源性的特点,本文从问题文本的关键词抽取、单词与标签的共现图构建、基于Word2Vec的协同过滤三个方面构建了混合推荐模型。实验结果表明,本文所提出的混合标签推荐算法具有更好的推荐效果。下一步研究中,考虑利用分布式计算、内存数据库等方法解决较大规模数据集上协同过滤非常耗时的问题,以提升实时推荐的效率。
