基于特征选择与随机森林混合模型的社区恶意评论检测研究
2020-08-19唐洵汤娟周安民
唐洵,汤娟,周安民
(四川大学网络空间安全学院,成都 610225)
0 引言
当今,网络社交平台上的每个用户都可以阅读、发布和分享信息,网络传播特性使得信息能够以前所未有的速度向大量受众传播,数十亿人的生活因此产生革命性的影响。伴随着移动互联网的普及,人们在社交网络上所花费的时间与精力也日益增多,安全问题也日益严重。大多数人都在试图保持网络的安全性和可用性,这类用户属于良性的、正常的用户,与之相对,有部分用户试图发表影响网络平台可用性的反社会行为,如仇恨言论,人身攻击和网络欺凌[1-3],这些被网络平台所禁止的评论通常由钓鱼者或喷子(Troll)发表,而且近些年的研究表明,普通人在特定情况下,也会发表恶意评论。
针对恶意评论的早期研究是定性的,学者通常对少数人工识别出的恶意评论的典型案例进行深入研究。在这一阶段的工作中,一般认为这是一种具有反社会行为的特殊言论。Buckels[4]在2014 年的研究中提到,恶意评论利用“热点问题”让用户在某种程度上变得过于情绪化、偏激乃至失去理智。故而,恶意言论可以被视为“网络社区负面行为”。Dlala[5]认为恶意言论故意对讨论的主题进行隐晦的误导,以挑起争议,扰乱讨论,达到让普通用户偏离讨论主题的目的。Cheng[6]等人在这之后研究了发帖、评论、点赞行为与社区不良行为的关系,他们对被社区禁言的用户进行异常行为分析,发现其异常行为倾向于集中在少数几个主题上,能够吸引更多用户的关注响应。他们以时间为轴,对用户行为按照从加入社区到被禁止的演变过程进行分析,恶意言论发布者的语言水平会持续降低,且社区对其容忍程度也呈下降趋势。同时随着社区对其管控严格化,不良行为反而会因此加剧,所以Cheng 等人提到对恶意用户的识别应该放在其行为初期,避免后期的不可控行为。他们另一项研究[7]表明,社区中的负面情绪会给社区带来持续性的负面影响,而积极情绪并不具备类似效应,因为大多数社区并不会对发表积极内容的用户采取奖励行为,所以用户也不会有进一步提高文章质量的积极性。
在检测言论中恶意行为这一方面,Kumar[8]对Slashdot 社区中的恶意评论进行研究,其恶意行为对社区的信息完整性进行了破坏,由此他们针对Slashdot社区开发了一种通用算法TIA(Troll Identification Algo⁃rithm),将在线注册用户分为恶意或良性,进而对恶意评论进行检测。在Hardaker[9]的研究中,分析了不同类型恶意评论的特征。Kim[12]通过分析用户的属性和代表性行为,如注册日期、重复转发和行为跟踪等来检测恶意用户。Risch[10]组合多个常用特征,其实验表明组合特征的检测效果明显优于单一特征。Cambria[11]等人使用帖子中的语义和情感分析进行恶意行为检测。而Chen[13]等人使用词汇句法特征分析并检测恶意行为,包括用户行文风格、结构和特定网络欺凌等内容。而在最近的研究中,Cheng,Justin[7]的文章中认为,用户的前置情绪和帖子的讨论情景是用户是否会产生恶意评论的重要预测因素,用户近期的发布历史表明情绪会从先前的讨论中延续过来,过去的恶意评论可以预测未来的恶意言论行为。
本文使用爬虫收集了一组中文社区中用户的历史发言数据。在Cheng,Justin[7]的研究基础上,提取出实验数据中有关不良情绪和上下文环境的相关特征。本文使用LASSO 回归,发现部分特征的相关系数较小,因此结合主成分分析法(PCA)对特征进行降维,并采用随机森林算法建立模型,发现在线讨论社区中的恶意评论,得到了87.0%的准确度。实验结果表明,本文采用的模型对恶意评论具有良好的检测效果,为净化社区环境提供了技术支持。
1 恶意评论检测模型
1.1 检测模型框架
本文的恶意评论检测模型如图1 所示,该模型主要包括三部分:数据特征提取模块、PCA 特征降维模块、随机森林检测模块。本文使用Python 爬虫获取到原始数据集,经过人工分析后,对数据进行清洗及预处理。根据过去的研究,模型从评论数据中提取出每个评论的特征向量,使用PCA 降维,提取出测试使用的特征集向量。原始数据将被随机分为70%的训练数据集和30%的测试数据集,最后使用随机森林算法进行训练,将评论数据分类为正常评论以及恶意评论。
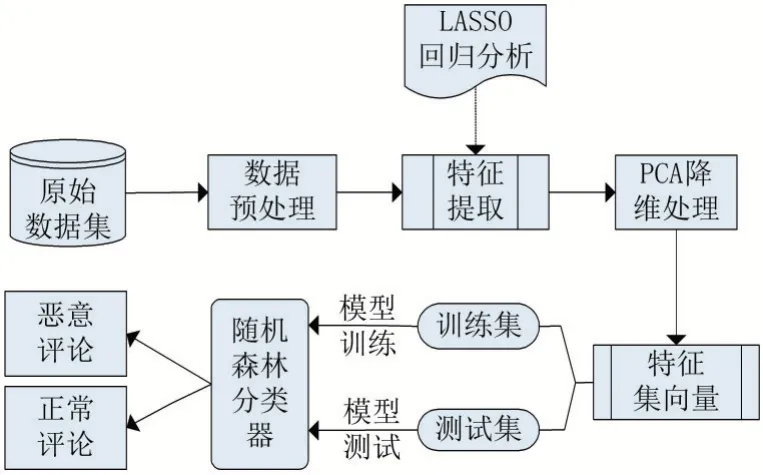
图1 恶意评论混合检测模型
1.2 检测模型特征
经过分析,本文采用的数据集中的46,036 条被删除的评论多数由未被禁用用户所发表的。在最新的研究中,Cheng、Justin[7]指出:恶意评论更多可能是由于情景而导致的,并非天生。研究者认为对于普通用户而言,负面情绪和讨论背景都会增加用户发布恶意评论的可能性。因此,本文根据数据集的特征,选用了以下8 个特征作为基础特征集,对恶意评论进行检测。
●情绪特征:
Cheng、Justin 基于情绪做了三个方向的特征研究。认为用户的恶意评论会随着早晚,工作日和周末的转换而变化;愤怒的情绪会带来更多的恶意评论;而随着时间的增加,用户的负面情绪会逐渐降低。
根据上述研究,本文提取出以下四个特征值:
(1)周时间:评论一周内所处的发布时间点;
(2)天时间:评论一天内所处的发布时间点;
(3)前置被标记时间:用户上一条帖子的标记情况;
(4)治愈时间:用户上一条被标记帖子与当前帖子的发布时间差。
●讨论环境特征
Cheng、Justin 基于讨论环境做了三个方向的特征研究。认为如果新闻下的第一条评论被标记,会对后续的讨论产生一定影响;如果评论所在的子讨论中的首条评论被标记,会对后续的子讨论产生影响;在一个子讨论中,被标记评论的数量和位置,会对整体子讨论产生影响。
根据上述研究,本文提取出以下四个特征值:
(1)首标记:评论所处的新闻中,新闻下首条评论的被标记情况;
(2)根标记:评论所处的新闻中,评论所在的子讨论中,根评论的被标记情况;
(3)评论位置:当前评论所处的位置;
(4)被标记数量:在这之前被标记的评论数量。
1.3 PCA降维处理原理概述
PCA(Principal Components Analysis)即主成分分析技术,旨在利用降维的思想,把多指标转化为少数几个综合指标,是一种非监督的机器学习方法。PCA 可以降低算法开销,通过降维发现更容易理解的特征,增加训练过程中对有效信息的提取处理,使数据集更容易被使用。
设周时间为W,天时间为D,前置被标记时间为Pt,治愈时间为 Ht,首标记为 Ff,根标记为 Rf,评论位置为P,被标记数量为N。则本文所采用的特征数据集I 为[W,D,Pt,Ht,Ff,Rf]。
LASSO(The Least Absolute Shrinkage and Selection Operator)回归也称之为线性回归的L1 正则化,该回归可以使常量系数变小直至为0 值,因此特别适用于参数数目缩减和参数的选择。本文采用LASSO 回归对特征集的变量进行筛选。通过对特征数据集进行LASSO 回归处理,得出其对应相关度为[-0.32,-0.69,17.07,0.10,31.81,-2.10,3.01,2.77],并由此观察到该特征数据集中有三项特征的相关度低于1。于是采用PCA 算法,设置k 值为5,对原有的八个特征进行降维处理,以保证其特征信息的有效性。
算法流程如下:
步骤1 计算对应特征值的平均值并减去。
步骤2 求出特征协方差矩阵。
步骤3 求出协方差矩阵的特征值和特征向量。
步骤4 将特征值按照由大到小的顺序排列,保留其中最大的k 个特征值,生成新的特征矩阵。
步骤5 将实验数据转换至上述k 个新特征构建的向量空间。
1.4 随机森林算法概述
随机森林算法是以集成学习思想为基础,由多棵决策树整合而来的分类算法,其每棵决策树都是一个分类器,随机森林集合所有分类投票结果,故其表现要优于单一的决策树。其算法流程如下:
步骤 1 特征数据集 I=[W,D,Pt,Ht,Ff,Rf]由PCA 降维得到的实验特征集 Ip=[i1,i2,i3,i4,i5]。
步骤2 以随机选取5 个特征中的2 个特征作为分裂点,其度量标准为基尼系数度量,以备选点的最小值作为最优分裂点的评判标准,公式如下:

步骤3 根据上一步骤的计算方式,逐个计算每一个属性的最优分裂点,对比不同分裂点的基尼系数,以最小属性并发生成多棵决策树。
步骤4 对多棵决策树的值进行投票并选出最终结果。
2 实验结果与分析
2.1 实验数据
本文通过Python 爬虫,采集并清洗了来自社区chouti.com 的公开数据,包含来自8,869 名用户的3,450,059 条历史发言记录。之后对采集到的原始数据进行了细致的检查和分析,发现原始数据中存在部分无效内容及数据重复等问题。因此本文对原始数据进行了清洗和预处理,以保证数据的准确性,最终获得46,036 条被标记为“该评论已被删除”的数据。实验将未被删除的数据标记为0,被删除的数据标记为1,使用Sklearn 实现PCA 降维和随机森林算法。
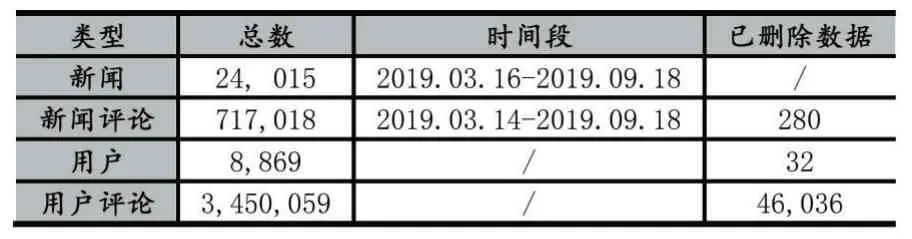
表1 数据集概述
2.2 评估指标
本次实验的评估指标采用以下四种:
TP:真阳性(True Positive),将正常评论预测为正常评论的数量;
FP:假阳性(False Positive),将恶意评论预测为正常评论的数量;
TN:真阴性(True Negative),将恶意评论预测为恶意评论的数量;
FN:假阴性(False Negative),将正常评论预测为恶意评论的数量。
性能评估使用准确率(A),召回率(R),精确率(P)和召回精确率调和平均数(F1)。
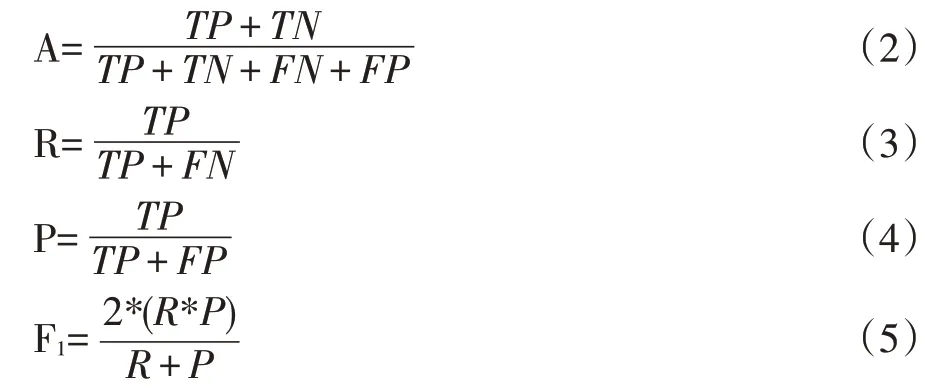
2.3 实验结果分析
根据上述特征,本文使用了三种不同的机器学习算法(支持向量机、KNN、随机森林)对恶意评论进行检测,实验结果如表2、图2 所示。
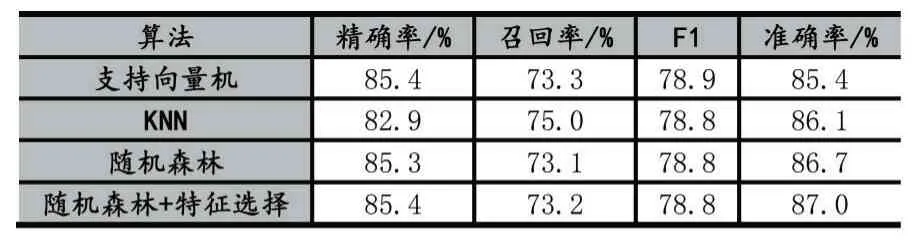
表2 算法性能对比
对比支持向量机、KNN 和随机森林算法的实验结果,可以观察到三种算法的精确率和召回率各有高低,但随机森林在准确率上要高于其他两种算法,故随机森林算法的检测性能最佳,准确率为86.7%。所以本文选择随机森林与特征选择相结合的混合模型,实现进一步的性能提升。从表中可以看到,随机森林和特征选择相结合,可以得到85.4%的精确率、73.2%的召回率以及87.0%的准确率,三项指标较之单一的随机森林均有提升效果。
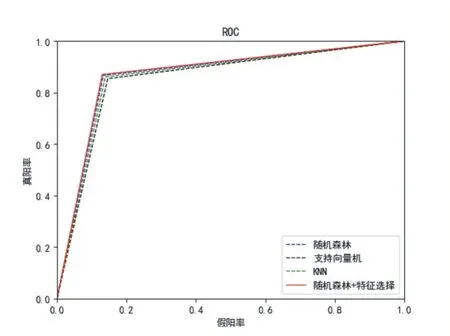
图2 ROC曲线
3 结语
中文社区评论中的恶意行为相当丰富,且屡禁不止。在大多数网站的评论区中,可以观测到用户不友善的沟通与交流。因此,本文希望借由此项研究去发现如何检测中文社区中的恶意评论。根据最新的研究,本文提取出数据集中被标记数据的8 个特征,在进行LASSO 回归分析后,发现其中三项特征属于弱特征。基于以上研究结果,论文采用PCA 对特征进行降维处理,最终结合随机森林算法对恶意行为进行了检测。检测结果表明,结合了PCA 的随机森林算法模型要比单独采用随机森林算法的准确度高,本文提出的模型可提高恶意评论的检测准确度。
