浅谈计算机视觉技术进展及其新兴应用
2020-08-17余京蕾

[摘要]针对人工智能领域的计算机视觉方向,分别从视觉感知和视觉生成两个维度分析计算机视觉技术的最新进展,包含但不限于表示学习、识别分类、目标检测、图像分割、像素级别的图像与视频生成以及视觉与语言等技术。在计算机视觉技术的新兴应用方面,分别论述了内容审核、拍照购物及搭配购物等方面的产品在电商领域的成功落地应用。
[关键词]人工智能;计算机视觉;视觉理解;视觉生成;电商
[中图分类号]TP391.4 [文献标志码]A [文章编号]1005-0310(2020)01-0063-07
0 引言
近年来,随着大数据的发展和深度学习的推进,人工智能逐渐进入大众视野,不管其是否可以如科幻故事中诉说的那般造福人类,它都正在逐步渗透进人们的生活。其中,计算机视觉是人工智能落地的最好的领域之一,由于人眼可以包罗万象,因此计算机视觉的应用也是无处不在。从市政安防、自动驾驶、影视娱乐、时尚设计,到日常生活中触手可及的人机交互、刷脸认证、扫码支付、相册管理,再到目前新兴的电商平台领域应用,等等,计算机视觉技术正持续快速地落地与渗透。
计算机视觉技术与人的肉眼理解图片的方式不同,它以数字矩阵的形式存取图片。若图片是RGB格式,那么每一个像素点颜色便可以用代表RGB(红绿蓝)的3个数值作为3个颜色通道,从而整张图片便可以用一个矩阵表示。如图1[1],人类肉眼观看到的仅是左侧的一只普通的猫,而在计算机眼里每个像素点都是由3个0~255之间的数字组成的矩阵。
2012年是计算机视觉发展历史中的重要节点,深度学习在计算机视觉领域应用越来越广泛,取得的突破性成果也日益增加。传统计算机视觉算法逐步被深度学习方法所替代,新方法及模型如雨后春笋般快速诞生。
1 计算机视觉技术研究进展
计算机视觉技术类别众多,本文将分别从视觉感知和视觉生成两个维度进行分析。其中,视觉感知包含表示学习、识别分类、目标检测和图像分割等重要任务,视觉生成包括图像与视频的生成、视觉与文字结合进行“看图说话”等。
1.1 视觉感知
1.1.1 识别分类
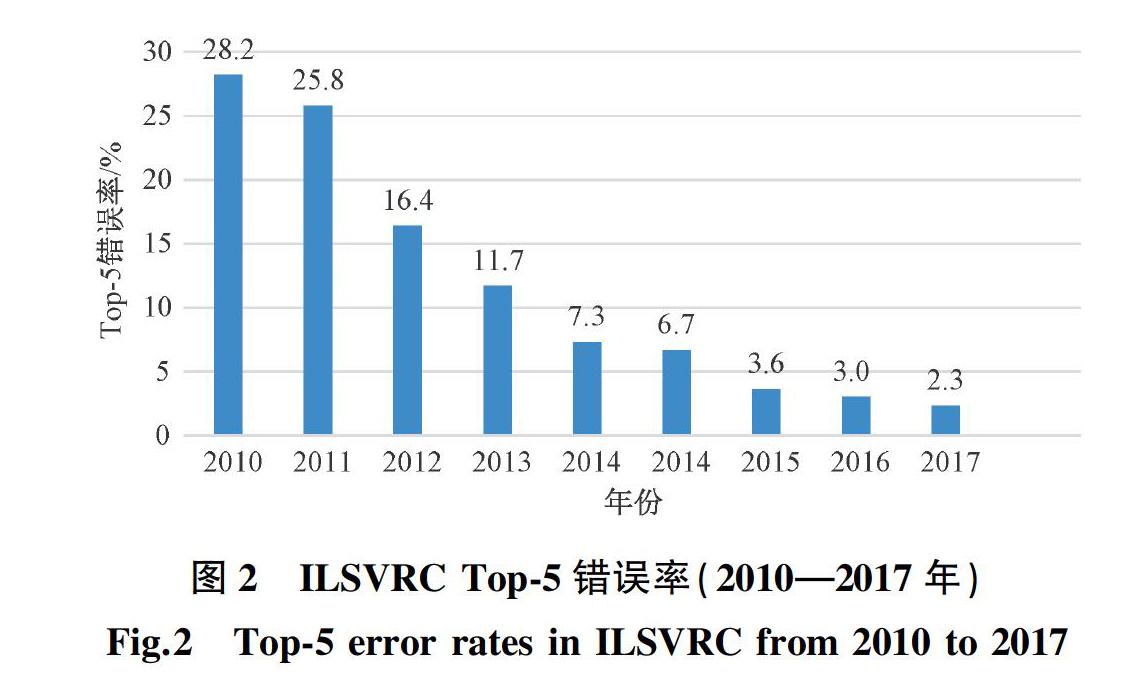
在图像理解的识别与分类方向,ImageNet比赛是一项著名的物体识别赛事,从2010年到2017年举办竞赛的8年间,计算机视觉技术取得了漫长且突破性的进步。因为物体识别是视觉领域的试金石,学者普遍会选择在ImageNet测试集上的效果作为模型效果评判的一个重要指标。ImageNet数据集[2]于2009年发布,其中包括超过1500万张图像、约2.2万类别的物体。ImageNet比赛[3]包含数据集中的分类任务1000类,共1431167张图像。从2010年起,比赛每年举办一场,识别错误率逐年降低,网络结构逐年加深,历年比赛夺冠模型的错误率可见图2[1],其中,2014年有两个不同的模型效果。2012年是取得重大突破的一年,识别错误率从2011年的25.8%骤减到16.4%,这需归功于深度学习的引入,即卷积神经网络(ConvolutionalNeural Network),其效果在当年比赛中脱颖而出[4]。自2012年AIexNet[4]的诞生后,深度学习不断被挖掘,识别错误率记录也一次次被刷新。
除通用物体的大类识别外,细粒度视觉分类(Fine-Grained Visual Categorization)也是识别分类任务中的一个重要问题。通常需要利用图像的整体信息并结合特定区域的特征信息,从而判断图像中的细粒度类别。其动机很直观,例如对于蝴蝶专家来说,仅通过识别蝴蝶翅膀的局部信息便可以作出准确的类别判断,模型同样利用了这个思路。细粒度分类的难点在于相似大类间的差异以及大类内部个体的细微差异。例如菜品、鸟类、蝴蝶、商品等类内的细粒度分类,这些难点都在逐一被挑战。面向不同的场景算法可以分为两种形式:强监督学习与弱监督学习。以文献[5]为例,该比赛数据包括2019种款式的商品,超过一百万张图片,并以弱监督的标注方式提供给参赛者。各个商品大类内部个体间的差异很小,再者又是自然场景拍摄的图片,拍摄的光线和角度也会影响到识别的结果,因此具有较高的识别难度。
分析图片识别的发展趋势不难发现,随着时间的推移,网络深度逐年上升,识别错误率逐年下降。这便会产生一种网络深度越深、网络的识别准确率越高的错觉。然而,在视频识别领域,随着网络加深,识别错误率并没有稳步降低。因此,目前视频领域的识别仍然是一个开放性的问题,相比图像而言,视频识别更加复杂。ActivityNet[6]比赛是与ImageNet大赛齐名的视频领域较为重要的比赛。从2011年支持51类到2019年支持700类复杂动作的识别,视频识别技术在迅速提升。2019年比赛使用Kinetics-700数据集作为大赛数据,要求参赛者从65万段视频中,识别700类复杂动作,类别包括人与物、人与人、人体运动等互动性动作,很多类别连人都很难进行区分。而目前最新算法准确率可达80%以上,相当于几千段视频中只錯几十段。
1.1.2 目标检测
目标检测任务同样是计算机视觉领域一个重要的研究任务,需运用算法定位目标在图中的准确位置,并且给出目标的准确类别信息。目标检测相比识别任务更为复杂,需首先定位到图中的目标区域,进而对目标区域进行分类处理。目标检测的示意效果如图3[7],这是由经典的检测网络Faster R-CNN实现的检测效果,其难点集中在目标的多尺度、多角度及多个目标物的准确检测方面。PASCAL VOC[8]作为国际顶级的计算机视觉竞赛,其中的目标检测任务是权威的检测基准测试比赛。这项挑战赛虽已于2012年停止,但是为评估最新研究的模型性能,学者仍可以提交测试集结果进行评测。该比赛数据集包含20个类别,截至目前,平均精确率(mean Average Precision,mAP)可高达92.9%[9]。
目标检测可作为诸多细粒度分支任务的第一步骤执行。例如在人体相关任務中,首先需检测图像中的人体区域,随后获取骨骼姿态的信息,进而对人体图像的各部分作分割处理,最终建立人体的三维模型。人体相关的检测任务在视频和图像中都有诸多应用,包括自动驾驶、智能监控(客流量的统计)、人机交互、智能结算等。目前前沿的人体检测模型,当前向速度在每秒传输帧数(Frame PerSecond,FPS)为25时,准确率可达到90%以上。
另外,人脸检测是人脸相关任务中重要的一个环节。人脸识别系统的整个流程,需首先从图像中检测到包含人脸的区域,随后对框内的人脸进行关键点定位。通过定位可以对人脸进行矫正和归一化处理,进而执行随后的系列人脸识别任务。落地应用包括防伪识别、人脸属性识别、表情识别等。
在视频任务中,动作检测与跟踪也是富有挑战性的工作。目前,视频动作检测可以支持100多个动作类别,mAP可达50%以上。实际上,当mAP达到30%以上时,便可以应用到实际场景中。另外,在人体的关键点追踪任务中,依据关键点对人体进行跟踪,可以实现给每个人体定义唯一编号,并获取每个姿态的关键点出现位置,即使有遮挡或复杂的动作也可以准确地进行跟踪。
1.1.3 其他任务
除上述两个基础任务外,还有诸多计算机视觉理解的任务。
表示学习旨在更加深入地分析如何理解图像。对于人眼来说很直观的图像,计算机需要将它转换成矩阵、模型等形式进行理解。因此,表示学习需要学习到可以最佳体现图像特征信息的表示方法。利用特征之间的相似度比较,可应用在图像匹配的相关任务上。例如,将手绘图与商品图进行匹配,利用表示学习将不同维度的图片转化到同一空间下进行表示,根据手绘图特征信息,在商品图特征库中搜索用户手绘图对应的商品。相反地,利用特征间的互补性,可将其应用在搭配搜索的相关问题中,将服饰搭配问题转换为搜索与其特征互补的服饰图片而得到解决,可节省聘请专业搭配师的大量成本且具有高扩展性。
图像分割也是计算机视觉中非常重要的一环。依据分割的粒度,可将分割任务分为普通分割、语义分割和实例分割。普通分割指图片像素级别的分割,意在分割图中不同的区域;在此基础上,语义分割可提供每个区域的语义信息;实例分割则是在语义分割基础上给出各个区域唯一的编号。实例分割的示意效果可见图4,这是由Mask R-CNN实现的分割效果[10]。人体部分的分割是其中一项更细粒度的任务,大到人体各个部位的剖析,小到人佩戴的眼镜、皮包、项链等零部件的分割。通过人体分割,可对人体服饰进行解析,进而可用于时尚搭配分析等。在视频领域,分割任务也有诸多有重要价值的应用,例如在自动驾驶领域,举办了国际权威的分割比赛[11],数据集包含来自50个不同城市的街道场景,标注共30类物体。
1.2 视觉生成
1.2.1 图像与视频的像素级生成
计算机视觉在感知理解图像与视频的基础上,还可以完成多维度的生成任务。例如,超分辨率的图像及视频的生成,老照片、老影片的修复;或是对图片进行编辑,实现智能抠图,生成去背景的主体透底图、自拍人像等。同时,生成任务还可辅助设计,例如时尚海报的设计。通过输人模特的图片,利用空间心理学的概念,结合计算机视觉的布局分析、模板设计、颜色心理学的多重关系进行海报的设计。除此之外,结合人体检测技术,通过输人模特的图片生成其他姿势的模特图片,或给模特换装,或手动编辑衣服类别生成所需效果。甚至可以通过学习模特的走步特征,由静态图片生成模特走步的动态视频。再者,图像生成也可实现图像和视频的风格迁移,例如将真实街景变为卡通画、水墨画风格,将自天和黑夜场景进行视频互换等。
1.2.2 视觉与语言
计算机视觉与语言的结合是近些年计算机视觉领域一个新兴的研究方向。通过文本生成图像,从2014年起发展,直到近些年可以实现通过输人描述性的句子,便可生成自然场景中对应的图片。例如通过描述鸟的翅膀颜色,算法可以画出多种不同姿态的鸟类图片,如图5[12]、图6[13]、图7[14],随着技术的不断发展,算法逐渐可以画出更加清晰的鸟类,甚至可以生成更为广泛类别的清晰物体图像。在视频领域也同样可以实现文字到视频的生成。
通过图像生成文字,所谓“看图说话”,即通过一张图片生成一段没有语法错误的文字。如图8所示,目前算法不仅可以识别出图中含有斑马目标,还可生成“彩虹在空中”以及“斑马在吃草”这类目标物体之间的关系描述。而技术不是一朝一夕、一蹴而就的,经历了从2015年到2018年的逐渐演变,研究日益深入,文字描述才逐渐精准且全面。早在2015年“看图说话”初步兴起时,算法仅能给出基本的描述:“a group of zebras standing in afield”[15],但这个描述相对笼统且缺乏细节。2016年和2017年生成的句子可以更精准地描述出“grazing”[16-17]的动作,而非简单的“standing”。直至2018年,算法可描述得更加细致,对物体间关系的细节描述也更加清晰,如“rainbow in thesky”[18-19]已非常接近人类的描述能力,文字描述愈发具体且全面。
同样,算法可通过视频生成描述性的文字。对视频中动作识别的复杂性和对象间的遮挡关系都增大了视频描述的难度。因此2015年和2016年的算法对视频中人类的性别和动作都很难准确判断,直至2017年生成的句子才可以准确地描述人类性别和动作,到2019年甚至可以描述出场景的细节信息。
“看图说话”在实际场景中也有诸多应用,例如在电商领域对商品进行描述,针对不同的用户生成个性化的文字描述;在视频领域,算法可以为网络直播写评论,为球赛作转播等。
2 计算机视觉技术新兴应用
2.1 内容审核
内容审核在互联网内容领域有较大的应用必要性,确保网络平台的运营遵守国家网络内容安全规范,避免监管风险,例如约谈、整改、罚款甚至关停等。可应用在互联网领域的电商、社交、新闻传媒等平台,从而对内容安全进行把控。这类审核产品有效地利用了计算机视觉的识别分类技术、目标检测技术等。
例如智能鑒黄,应用图像的识别分类技术,对人体裸露的敏感部位、敏感涉黄动作的图片与视频进行识别,将海量图片或视频分为正常、低俗、涉黄等不同类别,从而依据其类别与置信度过滤涉黄违禁图。算法审核极大地缩小人力审核的工作量,大幅节约了人力的审核成本,并减少了对审核人员造成的精神伤害。
另外,利用算法对暴恐场景、违禁品进行识别,需应用识别分类技术并结合目标检测技术,将图库中的涉恐及违禁品图片进行分类,包括暴乱、血腥、爆炸火光、管制刀具、违禁枪支、毒品、赌博行为等。同时,可以对图中恐怖组织旗帜的标识进行目标检测与识别。利用算法对大规模数据进行过滤,可以有效地避免给用户带来的不适体验和错误引导,减少危险信息利用网络传播的风险。
2.2 拍照购物及搭配购物
拍照购物是计算机视觉技术在电商领域的一个成功应用。如图9所示,用户仅需要提供所想购买的商品图片,计算机就能在商城海量的图片数据中找到匹配用户需求的商品。拍照购物使用的计算机视觉技术主要有目标检测、分类、特征学习及检索等。
拍照购物有效地打通了所见即所得的购物渠道,省去了用户大量的文字搜索时间,极大地提升了用户的购物体验。离线部分的流程包括:将商品图、晒单图清洗人库,用于训练检测、分类和特征模型,进而将商品的特征人库保存并建立索引。线上流程则包括:用户端输人欲购买商品的拍摄图,计算机将其依次经过已训练完备的分类、检测、特征模型,从而得到欲购买商品的特征,在离线特征库中进行检索,最终对商品顺序合理化重排后,将所有疑似商品信息反馈展示给用户。
此外,搭配购物也是一个新兴的计算机视觉算法的落地方向。例如在用户购买上衣后,算法可以根据上衣类型及用户喜好为用户推荐搭配该上衣的套装,兼具合理性、美观性、多样性及个性化的特点。其流程与拍照购物类似,首先对图中单品进行检测,进而提取商品特征,进行搭配搜索、打分,最终还会生成搭配理由。目前算法的搭配效果与专业搭配师的搭配相比,人类其实很难进行区分。利用算法进行搭配推荐,可以极大地节省聘请专业搭配师的费用,并且具有时效性,其类别拓展性也更强。
3 结束语
计算机视觉技术在视觉理解和内容生成方面都有深度的拓展,其中发展较为成熟的技术已经落地应用到实际工业场景,并得到了有效海量数据的验证与认可。计算机视觉技术应用在诸多新兴领域,例如在电商领域,通过对大规模数据的批量处理,完成人力无法轻易完成的工作量,有效地对大数据质量进行把控。对计算机视觉技术自身而言,由于目前落地产品大多是数据驱动,研究的热点包括小样本学习、迁移学习及无监督信息学习等方面,致力实现通过提供少量的训练样本或是无完备标注信息的样本,得到效果理想的模型。
[参考文献]
[1]JOHNSON J,YEUNG S,LI F F.CS231n:convolutional neural network for visual recognition[EB/OL].(2019-02-04)[2019-11-18].http:/vision.stanford.edu/teaching/es231n/slides/2019/cs231n_2019 lecture01.pdf.
[2]DENG J,DONG W,SOCHER R,et al.ImageNet:a large-scale hierarchical image database[C]// 2009 IEEE ComputerSociety Conference on Computer Vision and Pattern Recognition(CVPR 2009),20-25th June,2009,Miami,Florida,USA.IEEE,2009:248-255.
[3]ImageNet[EB/OL].[2019-11-18].http://www.image-net.org/.
[4] KRIZHEVSKY A,SUTSKEVERI,HINTON G E.ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012:1097-1105.
[5]IMaterialist challenge on product recognition[EB/OL].[2019-11-18].https://www.kaggle.com/c/imaterialist-product-2019/overview/description
[6]Activity-net Competition[EB/OL].[2019-11-18].http://activity-net.org.
[7]REN S Q,HE KM,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2015,39(6):1137-1149.
[8]University of Oxford,Microsoft Research Cambridge,University of Illinois at Urbana-Champaign.Pascal VOC[ER/OL].[2019-11-18].http://http://hots.ox.ac.uk/pascal/VOC/.
[9]PASCAL VOC challenge performance evaluation and download server[EB/OL].[2019-11-18].http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?challengeid=11&compid=4.
[10]HE KM,GKIOXARI G,DOLLAR P,et al.Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision(ICCV).IEEE Computer Society,2017:2961-2969.
[11]Cityscapes dataset[EB/OL].[2019-11-18].https://www.cityscapes-dataset.com.
[12]REED S,AKATA Z,YAN X,et al.Generative adversarial text to image synthesis[C]//2016 International Conference onMachine Learning(ICML 2016),19-24 June,2016,New York,USA.2016:1681-1690.
[13]XU T,ZHANG P C,HUANG Q Y,et al.AttnGAN:fine-grained text to image generation with attentional generativeadversarial networks[C]//2018 IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR2018),19-21st June,2018,Salt Lake City,Utah,USA.IEEE,2018:1316-1324.
[14]BROCK A,DONAHUEJ,SIMONYAN K.Large scale GAN training for high fidelity natural image synthesis[Z/OL].(2019-02-25)[2019-11-18].https://arxiv.org/abs/1809.11096.
[15]VINYALS 0,TOSHEV A,BENGIO S,et al.Show and tell:a neural image caption generator[C]//2015 IEEE ComputerSnciety Conference on Computor Vision and Pattern Recognition(CYPR 2615),8-10th June,2015,Boston,Massachusetts,USA.IEEE,2015:3156-164.
[16]YOU Q,JIN H,WANG Z,et al. Image captioning with semantic attention[C]//2016 IEEE Computer Society Conference onComputer Vision and Pattern Recognition(CVPR 2016),26th June-1 st July,Las Vegas,Nevada,USA,IEEE,2016:4651-4659.[17]YAO T,PAN Y,LI Y,et al.Boosting image captioning with attributes[C]//2017 IEEE International Conforene onComputer Vision(ICCY 2017),22-29th October,Venice,Italy.IEEE,2017:4894-4902.
[18]ANDERSON P,HE X,BUEHLER C,et al.Bottom-up and top-down attention for image captioning and visual questionanswering[C]//2018 IEEE Computer Society Conference on Computer Vision and Pattern Reurlition(CVPR 2018),19-21st June,2018,Salt Lake City,Utah,USA.IEEE,2018:6077-6086.
[19]YAO T,PAN Y,LI Y,et al.Exploring visual relationship for image captioning[C]//2018 European Conference onComputer Vision(ECCV 2019),8-14 th September,2018,Munich,Germany.2018:711-727.
(責任编辑 白丽缓)
[收稿日期]2019-11-20
[作者简介]余京蕾(1994-),女,北京市人,美国宾夕法尼亚大学计算机与信息学院硕士研究生,主要研究方向为计算机视觉。E-mail:yujinglei2015@163.com
