行人再识别中的多尺度特征融合网络
2020-08-14贾熹滨SiluyeleNtazanaMazimbaWindi
贾熹滨,鲁 臣,Siluyele Ntazana,Mazimba Windi
(北京工业大学信息学部,北京 100124)
行人再识别,也被称作是行人检索,简称re-id. 目的是在给定的行人图像库中寻找一个特定行人,这个图像库是由几个没有重叠区域的摄像头所拍摄形成的[1]. 近年来,行人再识别由于其重要的研究意义和广泛的应用前景得到越来越多的学者的关注和研究. 但是由于不同摄像头采集数据时的角度差异、光照的变化以及遮挡物等影响,行人再识别的研究仍然是一个难点问题.
早期视觉的行人再识别方法,主要利用手工设计的算法提取特征:Karanam等[2]采用在颜色空间建立基于不同颜色通道的纹理和颜色直方图特征的方法,然而利用颜色特征虽然能够快速匹配到外貌相似的行人,但是当多个行人的衣服颜色相似时却无法准确识别;Yi等[3]则关注了行人的形状和纹理信息,建立基于行人本身的独有特征,但是当行人样本量达到一定规模时,该方法同样会因为相似特征太多而失去有效性. 随着深度学习在图像识别、图像理解领域的广泛应用,特别是对复杂对象良好的学习能力,其逐渐被应用到行人再识别领域. 近年来,基于卷积神经网络的行人再识别模型取得了突破性的进展,使得机器在行人再识别问题上的能力已经超过了人类水平[4].
行人再识别的主要研究方向可以分为特征提取和度量学习2类. 在特征提取方面,同时提取局部特征和全局特征已经成为一种常见且通用的方法,并且被证明是有效的[5]. 其中一些研究工作明确地考虑了卷积神经网络中只使用高层特征带来的细节信息丢失的问题,因此,采用了提取局部特征和多尺度融合特征的方法. Zhao等[6]提出的Spindle Net技术实现了以人体区域为导向的人体特征分解与融合,提取了人体不同部位的局部特征后再进行融合,然而这样的特征提取方式很大程度上依赖于划分人体部位模型的精确度,如果人体定位模型不准确,那么将直接影响到最终的识别准确率;Zhao等[7]针对行人再识别过程中的身体部位错位匹配导致识别精度有限的问题进行研究,提取出全局特征和局部特征相结合的融合特征,同样的,这样的做法也会受到人体定位模型的影响;Wang等[8]则将卷积神经网络的不同阶段的特征进行全局平均池化后,将多个卷积层的特征加权求和后进行训练,然而利用全局平均池化操作会带来不同程度的细节信息的丢失,无法提取出基于细节信息区分的特征,同时在卷积神经网络中的每个阶段的特征并不一定都是有用的,因此,会带来额外的计算量,在训练网络时势必会带来网络收敛慢等问题.
从国内外研究现状来看,大部分研究只使用卷积神经网络的最高层语义特征,然而最高层特征往往经过了多次卷积和池化等操作,导致图像上的很多细节信息在网络的高层被丢失,因此,在面对某种案例时往往得不到理想的效果. 例如,当2个行人的体态和衣服的颜色等特征很相似时,只使用最高层特征的方法更多地关注行人的整体特征,往往不能准确区分2个行人的身份. 本文提出了一个基于残差网络ResNet50改进的多尺度特征融合网络,利用最后一层特征协同多个中间层特征,通过特征层融合以建模行人图像特征. 为保证有效利用具有一定语义表达的同时不丢失细节信息的多尺度特征,本文在提取全局特征的同时,采用不同特征层之间降低通道后元素相加的融合方法,确保模型在总体特征表述基础上提高了对行人细节信息的表征能力,从而提升模型的识别准确度.
1 问题的提出
虽然行人再识别的研究随着深度学习的发展而变得迅速,但是仍然无法有效识别具有相似外貌特征的不同行人的身份;因此,如何提取出更加具有区分度的特征成为了提高模型准确率的研究热点[9]. 然而,常见的行人再识别数据集,如Market-1501[10]、CUHK03[11]、DukeMTMC-reID[12]等,所包含的行人图片都是低分辨率的,难以利用像人脸这样可以直接区别2个人身份的特征,并且由于遮挡物和行人姿态的影响,人脸并不是一个可以利用的可靠特征. 因此,行人本身的细节特征,如背包、鞋子等私人物品,成为区分外貌相似的2个人身份最好的信息.
图1中的2张图片都来自Market-1501数据集. 对比后可以发现,2个行人体态相似,而且都身着白色的短袖和牛仔短裤,但是仔细对比可以发现,2个行人约有3处较为明显的不同点:
1) 行人a的白色短袖上有明显的logo;
2) 行人b背着背包,并且有明显的一根背带;
3) 2个行人的鞋子颜色稍有不同.
图上的这3处细节信息足以让模型识别出这是2个不同身份的行人.
在常见的特征提取的方法上,深度学习因其良好的对复杂对象的表征能力被用于图像理解识别方向,在行人再识别领域也被广泛应用[13]. 与多数图像理解识别的深度特征学习方法相同,其也是将待识别图片送入卷积神经网络中,计算深度特征. 行人再识别模型也采用相似的深度网络结构,提取揭示其高层表征语义的特征,用于进一步分类计算. 但是仅使用最高层抽象特征作为整张图片的特征表示并不能获得很好的识别效果,原因在于卷积神经网络在不同阶段编码生成的特征具有不同的信息,高层特征包含的更多的是语义信息,因此,导致当2个不同身份的行人穿的衣服颜色相近时,模型无法准确识别. 同样在目标检测领域,仅使用网络的最高层特征导致检测小目标时出现漏检的现象,研究者为了提升小目标的检测精确度,通过提取多尺度的特征信息进行融合,进而提高小目标检测的精度. 考虑到常见的行人再识别模型同样存在上述问题,当2个不同身份的行人穿的衣服颜色相近时,其高层语义相似,用于准确区分不同行人的信息通常存在于小目标中,仅从卷积神经网络最后一层提取出的高层特征往往丢失了很多细节信息,如行人有无背包等,导致模型将衣服颜色相近的不同行人分类错误. 基于以上分析,本文采用多尺度特征融合模型,提出有效的融合方案,旨在提取反映细节信息的有效特征,从而提升行人再识别的精度.
基于此,本文借鉴了特征金字塔网络(feature pyramid network,FPN)[14]的思想,设计了一个多尺度特征融合网络,在提取行人图片的高层语义特征的同时,亦可以利用中间层提取细微细节的抽象特征. 整个模型采用了多尺度特征融合的方法,提取全局语义信息特征的同时,加强网络对小目标的关注,使得网络更多地关注细节信息. 不同于FPN网络,本文并未融合所有卷积层的特征,而是通过实验选取中间层包含细节信息更多的特征,从而提取出更加具有区分度的特征.
2 网络结构及多尺度特征融合机制
本文设计了一个多尺度卷积神经网络来解决只使用高层特征带来的缺点,整个网络结构如图2所示. 在众多分类网络中,ResNet50通过引入残差模块,在加深网络结构的同时,有效地解决了梯度消失问题,得到了很好的识别和分类效果. 因此,本文采用的网络结构在ResNet50[15]的基础上进行改进,首先将ResNet50中4个阶段的最后一个残差结构的特征激活图输出,这里每一个阶段的输出分别命名{C1,C2,C3,C4},并且将网络最后一个残差块的卷积操作的步长改为1,保证特征图的分辨率不会太低. 为保证有效表示行人的总体特征和小目标的细节特征,本文设计采用自顶层向下渐进式加和融合计算机制,具体特征融合操作描述如下:对于高维特征C4,使用卷积核大小为1的卷积核降低通道的数量得到P4;将同样经过降维后的C3与P4进行元素相加的操作,得到融合后的特征P3;同理,得到P2. 考虑到由于池化操作,每一个阶段得到的特征图的分辨率并不相等,在加和操作前,将高层特征图进行上采样,本文采用2倍上采样得到与低层特征图相等的分辨率. 利用该渐进式特征融合计算机制得到多个包含不同尺度的融合特征,即反映不同粒度的小目标细节特征. 本文考虑到建模细节信息的目的在于提取如配饰等小目标对象的语义特征表示,而非低层特征,因此,本文设计采用选择中间层与高层特征协同的特征融合计算方案,而未采用最低层的特征图. 这里选用第2、第3和第4阶段特征.
利用上述方法,对所提取的融合特征{P4,P3,P2}和全局特征X使用共享权值的全连接层对其进行分类. 本文使用分类损失(cross entropy loss)[16]L,总的损失函数表示为
Ltotal=LP4+LP3+LP2+Lx
(1)
在训练过程中,为找到有效的中间层建立组合特征,本文对网络不同阶段输出的特征图采用多种组合方案,分别进行训练以确定识别准确率最好的特征组合,避免使用冗余的特征,减小网络的参数量. 为了和同类型的模型进行对比,当整个网络训练完毕后,本文同样只采用全局特征X进行测试.
3 实验分析
3.1 实验数据库介绍
本文对3个主流的行人再识别数据集分别进行了测试,包括Market-1501、CUHK03和DukeMTMC-reID. 其中,Market-1501数据集在2015年构建并且公开,它包括由6个摄像头拍摄到的1 501个行人和32 668个检测到的行人矩形框,每个行人至少由2个摄像头捕获,在图像库gallery image中的行人检测框是使用可变形组件模型(deformable parts model,DPM)检测算法检测得到的,其中,训练集有751人,包含12 936张图像,测试集有750人,包含19 732张图像;CUHK03数据集在2014年公开,共包含13 164张图片(来自1 467个人),随机挑选其中767个行人的图像作为训练集,将其余的700个行人的图像作为测试集;DukeMTMC-reID数据集包含了16 522张训练数据集(来自702个人)、2 228个查询图像(来自另外的702个人)以及17 661张图像的搜索图库(gallery).
3.2 实验结果分析
本文在Market-1501、CUHK03(D)和DukeMTMC-reID数据集上对所提出的多尺度特征融合方法的有效性加以验证,使用随机裁剪的方法增加样本的多样性,同时所有实验均在单张1080ti显卡上完成,结果如表1~3所示. 首先利用ResNet50最后一层卷积层输出的特征X(global)进行测试,接下来利用不同的特征组合方式进行了一系列实验. 通过实验发现,不同层之间的特征融合有效地提高了模型的识别精度. 在全局特征X的基础上,{X,P4}和{X,P3}特征组合均提高了实验的识别精度,并且在3个数据集上,{P4,P3,X}这样的特征组合方式都达到了最好的识别精度,但是随着实验的深入,{P4,P3,P2,X}的特征组合反而出现了实验精度下降的现象,说明将所有的融合特征叠加并不是都有效果,P2阶段的融合特征所包含的可以有效区分行人身份的信息更少,甚至会降低整个特征的识别精度. 实验结果如表1~3所示.
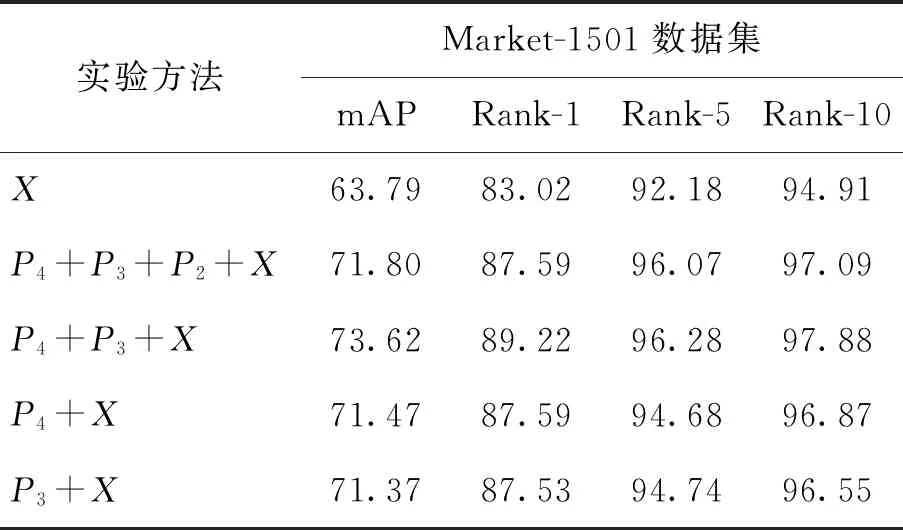
表1 不同的特征组合方式在Market-1501(Market)数据集的实验结果
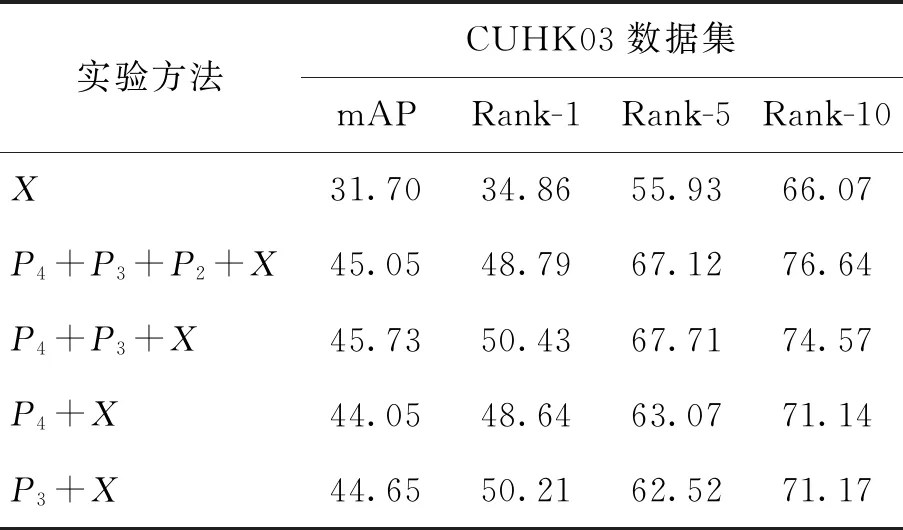
表2 不同的特征组合方式在CUHK03数据集的实验结果
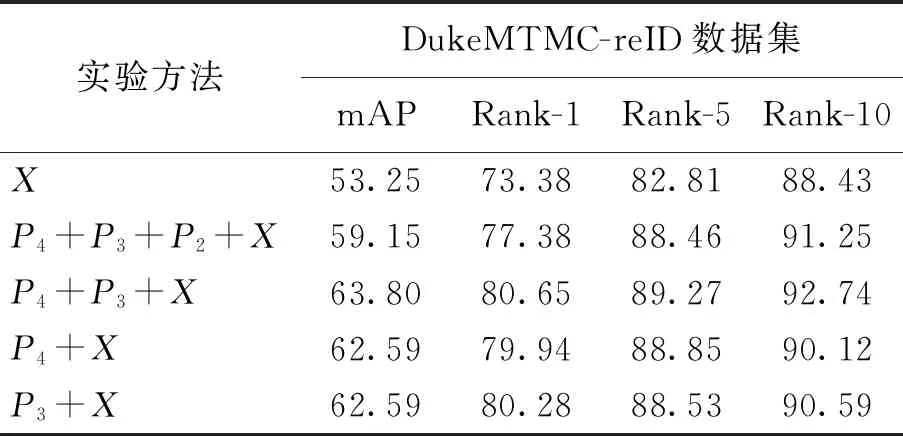
表3 不同的特征组合方式在DukeMTMC-reID数据集的实验结果
与2018年提出的DaRe[8]网络相比,本文提出的方法在Market-1501数据集的Rank-1[17]指标提升了2.82%,mAP[18]指标提升了4.32%;DukeMTMC-reID数据集的Rank-1指标提升了5.45%,mAP指标提升了6.40%. 实验结果(见表4)充分说明了本文设计的多尺度特征融合网络的有效性,在提取了高层语义特征的同时,充分提取了融合特征P3和P4中的细节信息,加强了对图片上细节信息的关注,提高了模型的准确率.
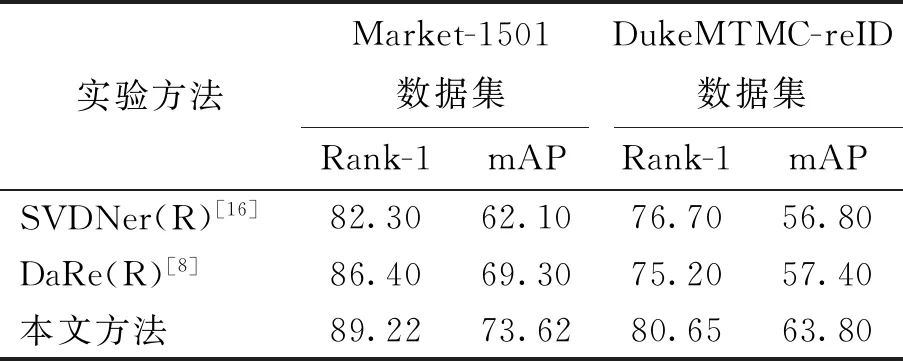
表4 本文提出的融合算法与现有融合算法的比较
3.3 特征图可视化结果分析
为了验证所提出的模型在保留全局特征的同时有效提升了对行人身上的细节特征的注意力,本文利用Grad-cam[19]可视化技术展示了不同的特征组合方式所形成的可视化图像[20]. Grad-cam是一种类别判别的定位技术,可以从任何基于卷积神经网络生成视觉解释,而不需要架构变更或重新训练. Grad-cam使用进入网络最后一层卷积层的梯度信息来理解每个神经元对目标决定的重要性.
如图3所示,由可视化图像中颜色越深的部位表示模型在此部位学习到的特征越重要可以发现,采用本文所提出的模型,即利用全局特征X及融合特征P4、P3所派生的{P4,P3,X}特征组合,关注到了行人衣服上的logo、背包等细节信息. 实验结果充分说明了所提出的特征模型对小目标等细节信息具有更好的表示能力,在分类时起到重要的作用,从而有效提升了行人再识别的识别效果.
为进一步分析不同特征组合对细节信息的表征能力,本文对比了不同特征组合的可视化图像,如图4所示. 其中3个行人图像采用不同特征组合的heatmap图像,从左至右依次为原始图像、X、{P3,X}、{P4,X}、{P3,P4,X}、{P2,P3,P4,X}的特征可视化. 如图4(a)所示,可以发现采用{P4,P3,X}、{P4,P3,P2,X}组合特征,更精确地注意到了行人裤子上的logo,同时{P4,P3,X}组合特征对该细节赋予了更大的权重,即在分类过程中将起到更重要作用;与之相对的是,若采用全局特征X,其重要区域,即红色部分,明显与行人裤子上的logo区域有一定偏离,未获得足够关注,而仅组合其中一层的特征,即特征组合{P4,X}和{P3,X}虽有一定改善,但还是未获得足够关注,同样的在图4(b)(c)中也有类似的现象. 因此,采用{P4,P3,X}组合特征,更精确地注意到了行人衣服上的logo、鞋子以及裤子信息,特别是相对于只采用全局特征的实验,组合中间特征后,对局部细节具有一定的表征能力,从而利用细节信息提高行人再识别精度.
总之,利用特征层可视化手段,其结果证明本文所提出的模型在识别对象具有较高相似度时不仅可以保留全局特征,并且可以注意到图片上的细节信息,利用细节进行辅助识别,提升了模型的识别精度.
4 结论
1) 本文针对行人再识别中不同目标对象的体态、外貌非常相似时模型不易辨识等问题,提出了一个基于ResNet50的多尺度特征融合网络,通过利用微小细节信息,特别是不同粒度的小目标对象信息,在提取全局特征的同时将网络中间层的特征图组合后共同训练,实现了高分辨率特征和低分辨率特征的互补,使得提取出的特征既包含了高层语义特征又包含低层的细节信息. 在面对行人的外貌特征相似的案例时,模型可以利用关注到行人对象的细节特征,如行人的背包、衣服上的logo等,足以表明行人身份的信息,提升再识别能力.
2) 实验结果表明,本文所提出的模型在3个主流行人再识别数据集上,获得了比同类型的主流行人再识别方法更高的精确度,同时通过对比分析全局特征与中间层的不同特征组合,确定了采用最高层全局特征与次高层中间特征的特征组合方式. 通过Grad-cam将实验结果可视化,结果显示融合后的特征包含了更多的细节信息,提升了不同行人特征的可辨别性,进一步验证了组合高层全局特征和中间特征,特别是所确定的特征组合,对细节具有更好的表征能力,证明了本文所提出的多尺度特征融合网络在行人再识别应用中的有效性.
