基于负载均衡的CPU- GPU异构计算平台任务调度策略
2020-08-14章佳兴
方 娟,章佳兴
(1.北京工业大学信息学部,北京 100124; 2.北京工业大学北京智慧城市研究院,北京 100124)
随着制造工艺的升级,计算机体系结构发生了巨大的变革. 单核处理器结构被物理设计极限和能耗等因素制约,必然导致摩尔定律[1]的重点由单纯的晶体管数量转移到可以被集成在芯片上的核心数量[2].
在中央处理单元- 图形处理单元(central processing unit-graphics processing unit,CPU- GPU)结构中,CPU具有较大的缓存和大量逻辑运算单元,被设计用于处理复杂的任务. 大缓存和逻辑运算单元可以保证数据运算的低延迟,在较少时钟周期内完成计算任务. CPU还有很多的加速分支判断和复杂的逻辑判断硬件用来提高分支预测能力,降低延迟. GPU是基于大吞吐量的设计,具有大量的算术逻辑单元和很少的缓存,擅长大规模并行计算. 在2003年以后,数学家和经济学家注意到多核心的GPU非常适合并行任务的处理,逐步将GPU用于通用计算领域. 英伟达(NVIDIA)、超威半导体(AMD)和苹果(Apple)等公司分别提出了GPU通用并行计算技术Cuda、ATI Stream和OpenCL,GPU开始被广泛应用在数学、金融等各类通用计算领域.
异构计算系统指使用不同类型指令集和体系架构的计算单元组成的计算系统. 目前,异构计算系统已经延伸到CPU、GPU、数字信号处理(digital signal processing,DSP)、现场可编程门阵列(field programmable gate array,FPGA)、专用集成电路(application specific integrated circuit,ASIC)和其他固定加速器等,不同的计算单元相互协作共同完成计算任务. 其中CPU- GPU是目前最为主流、应用最广的异构系统架构.
1 CPU- GPU处理器调度
传统的CPU- GPU异构计算平台的任务调度策略中CPU负责串行计算部分,GPU管理并提供GPU运算所需数据以及接收GPU计算完成的结果[3-5]. Iturriaga等[6]在CPU- GPU异构平台上使用改进的随机搜索方法gPALS来实现异构计算系统中的调度问题. 王彦华等[7]使用支持向量机(support vector machine,SVM)的分类方法将计算任务区分为CPU型和GPU型,然后按照任务类型派发给适合的处理器.
此类调度策略容易实施,但CPU等待GPU计算结果的时间对于高效的计算单元来说无疑是一种严重的性能浪费.
鉴于上述情况,研究者将并行任务分割成不同的部分,CPU和GPU同时处理并行任务的不同部分,平衡CPU与GPU的负载[8-12]. 这能够避免计算单元空闲,缩短任务计算时间,提升系统性能. 虽然CPU和GPU对于任务的处理具有偏好性,但使用2种处理器共同处理计算任务,仍然能够提升性能.
CPU- GPU异构计算系统静态调度策略指在系统运行之前就已经确定好调度方案. Alsubaihi等[8]提出了一种面向高性能和能耗的多目标资源分配方案,使用粒子群算法(partical swarm optimization,PSO)求解高效的负载分配比例,但是该方案在计算小规模任务时,PSO求解调度方案的时间相比任务处理的时间过长. Shulga等[9]使用机器学习(machine-learning,ML)的方法处理调度问题. 文中指出在一定场景中,某类型的处理器负载过高,限制了系统性能,将一些任务加载到另一类型的处理器上能提升系统性能.
静态调度策略[10]调度开销较小,容易实施,但是易造成负载不均. 对于一些CPU与GPU计算速度相差较大的应用,负载不均带来的性能浪费尤为明显. 静态调度只能针对特定的CPU- GPU结构,当计算单元型号(计算能力)改变后,静态调度确定的划分比例不再适用. 对于CPU与GPU区分明显的应用,可能会降低系统性能表现.
CPU- GPU异构计算系统动态调度策略[10]是指在操作环境与计算任务不确定情况下进行的调度. 调度过程中根据CPU和GPU的负载情况调节分配的数据量,确保不同类型计算单元负载均衡. 动态调度基本解决了静态调度只针对固定CPU- GPU结构和负载不均较大的问题,但是动态调度带来的内存和时间开销较大,对整体系统性能的影响较明显.
Ma等[11]设计了一个分步调度方案,根据上一周期处理器计算能力动态调整下一周期计算量的分配,使CPU和GPU计算任务的完成时间差较小,保证不同类型处理器负载均衡. Shen等[12]通过负载预测调度(load-prediction scheduling,LPS)技术平衡不同类型处理器的工作负载. Vilches等[13]提出了一种新的自适应分区(adaptive partitioning)调度策略,特别是针对运行在CPU- GPU异构芯片上的不规则应用而设计的. 这项工作的创新在于,分配给CPU和GPU的工作负载的大小可以动态地进行调整,以最大限度地平衡设备之间的工作负载,提高异构计算单元利用率.
2 调度策略
2.1 负载均衡
CPU- GPU异构计算平台负载均衡指加载到CPU与GPU的计算任务在同一时间完成.
定义:T表示当计算量为X时的计算时间,则处理器计算该任务的计算速度为
(1)
设计算任务的数据量总和为S,CPU与GPU计算该任务的速度分别为VCPU和VGPU,CPU与GPU共同参与计算所用的时间分别为TCPU和TGPU,则S可表示为
S=VCPUTCPU+VGPUTGPU
(2)
设δ(δ>0)为系统的负载不均程度,δ越小表明系统负载不均越小.δ可表示为
(3)
理想状态下δ=0,即当TCPU=TGPU时负载均衡,设此时CPU和GPU分配的数据量比值为P,可推出
(4)
由式(4)可得,负载均衡状态CPU与GPU所分配的数据量为
(5)
2.2 基于队列的混合调度策略
影响系统性能稳定性的因素众多且动态调度过程的资源分配和时间消耗开销过大[14],因此,本文提出基于队列的混合调度策略,在并行任务处理前将计算任务存入双向队列,在派发计算任务给不同类型处理器时,CPU从队首派发,GPU从队尾派发. 该策略核心是预测和分配,由式(4)(5)可知,SCPU和SGPU由VCPU和VGPU求解.VCPU和VGPU是策略的预测的关键.该策略按照以下4个步骤完成.
第1步 首先检测该系统是否第一次运行该程序,若是,则将CPU与GPU的计算量按照
sCPU=sGPU=0.05S
(6)
分别派发给CPU与GPU,探测异构计算系统对该类任务的计算能力;否则读取系统存储的分配比值P,按照
(7)
计算量派发,验证当前分配比例是否适合此时系统状态.
第2步 根据系统第一阶段的CPU计算时间tCPU和GPU计算时间tGPU推导系统当前状态,计算该任务的性能比值p,当系统第一次运行该程序时,比值p由
(8)
求解,否则由
(9)
求解.
探测阶段的负载不均程度δ′公式为
(10)
当δ′>μ时,更新计算量分配比例P=p;当δ′≤μ时,计算量分配比例P不需改变. 其中μ为系统设置阈值.
第3步 混合调度阶段,将全部数据量的80%按照上一步确定的比例派发给CPU和GPU. 剩余的10%进行动态调度,先完成计算任务的处理器不需等待后完成的处理器,直接进入队列动态调度阶段,后完成的处理器在完成分配的数据量之后也进入队列动态调度阶段,直至队列首尾相遇,计算任务全部完成.
第4步 统计混合调度阶段中静态调度计算任务的CPU与GPU的计算时间t′CPU和t′GPU. 通过计算时间求得系统当前计算任务的最优分配比例
(11)
设P与P′离散程度为Δ,Δ用
(12)
表示.
当Δ>ν时,更新异构计算系统CPU与GPU负载比为P′,其中ν为系统设置阈值.
基于队列的混合调度策略流程图如图1所示.
3 性能测试
3.1 实验环境
实验采用的计算平台为曙光W580- G20,运行Linux系统,CPU为Intel Xeon(R) CPU E5- 2620;GPU为NVIDIA Tesla P100;内存128GB、硬盘2TB. CPU和GPU拥有各自独立的内存空间,通过PCIE总线互联.
本文选用4组基准测试程序,其中MatMul是并行计算领域经典的测试程序;Pathfinder和Kmeans来自最新版本的Rodinia测试集;Nbody为NVIDIA官方测试用例.
3.2 实验结果
实验选取的4组基准测试程序均在CPU- GPU异构计算平台调试通过,根据数据计算时间衡量系统性能.
本文对所提出的调度策略进行了广泛的评估,将其与传统调度算法、静态调度算法和动态与静态相结合的调度算法进行对比测试.
3.2.1 基准测试程序MatMul
MatMul属于微矩阵测试程序,是并行计算领域经典测试用例. 实验在并行数据计算部分设有大量微矩阵. 微矩阵选用长宽均为100的方阵. 本实验异构计算平台中的Intel Xeon(R) CPU E5- 2620和Tesla P100计算单个微矩阵的时间分别为6~7 ms和3~4 ms,在当前CPU- GPU异构计算平台上GPU处理MatMul测试程序能力强于CPU.
经过优化后的调度算法与传统调度算法的具体性能数据对比如表1所示. 静态调度策略对4组不同数据量的性能提升分别为12.87%、9.92%、6.54%和12.87%;静态与动态相结合的调度策略对4组不同数据量的性能提升分别为18.37%、15.92%、14.79%和18.14%. 虽然2种调度策略对系统性能有明显提升,但波动较明显. 基于队列的混合调度策略对4组数据量的性能提升分别为31.74%、29.79%、28.20%和30.14%.
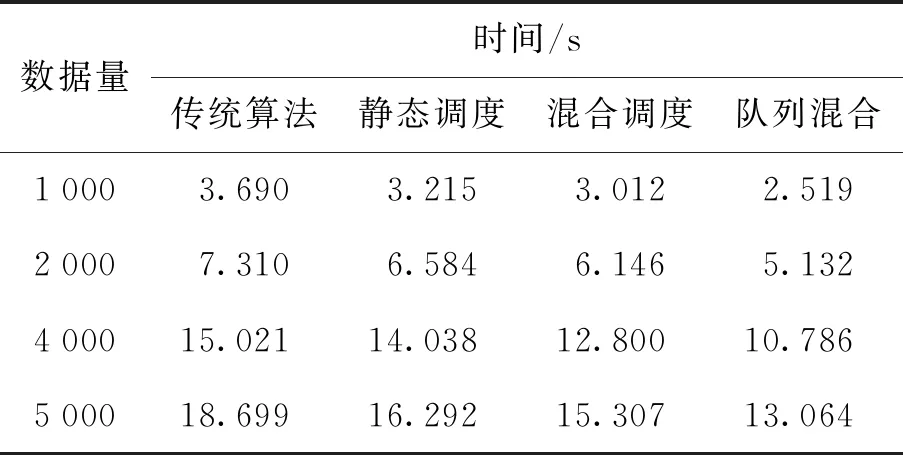
表1 MatMul性能
如图2所示,经过优化的3种调度策略相对于传统调度算法都有明显的性能提升,静态调度策略平均有10.55%的提升;静态与动态相结合的调度策略平均有16.80%的提升;基于队列的混合调度策略平均有29.98%的提升,基于队列的混合调度策略在性能提升效果上明显优于其他2种策略.
3.2.2 基准测试程序PathFinder
PathFinder是路径寻找测试程序,按照金字塔路径寻找从矩阵顶部到底部的最短距离. 实验选用长10 000、宽100的矩阵作为PathFinder数据实例. 使用本系统CPU与GPU计算单个矩阵金字塔距离的时间分别为0.60~0.67 ms和1.11~1.12 ms. 该测试用例的CPU计算性能优于GPU,这也是选取本实例的主要原因.
当数据量分别为5 000、10 000、40 000和50 000时,传统任务调度算法与其他3种调度算法的性能差距如表2所示. 与传统调度算法相比,静态调度策略在4组测试实例中性能分别提升了15.02%、13.70%、11.11%和7.37%;静态与动态相结合的调度策略性能分别提升了18.44%、20.01%、13.65%和22.03%;基于队列的混合调度策略性能分别提升28.64%、27.13%、26.94%和27.77%.
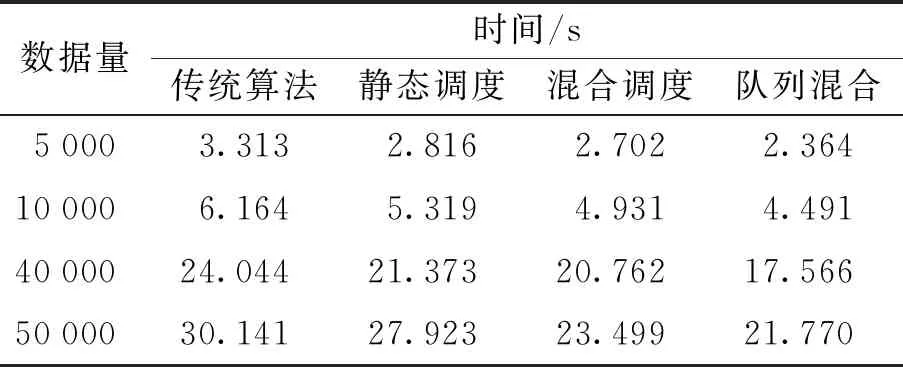
表2 PathFinder性能
如图3所示,静态调度策略、静态与动态相结合的调度策略和基于队列的混合调度策略与传统调度算法相比在性能上平均有11.80%、18.53%和27.62%的提升.
3.2.3 基准测试程序Kmeans
Kmeans算法是基于迭代求解的聚类算法,单次迭代过程需计算每个点到K个聚类中心点的距离. 使用本系统计算单个Kmeans实例的CPU和GPU耗时范围分别约为0.27~0.32 ms和0.15~0.20 ms. 该程序的GPU计算速度优于CPU计算速度.
当样本数据量为2 000、4 000、10 000和20 000时,不同调度算法耗时如表3所示. 计算易得,与传统调度方案性能相比,静态调度策略和静态与动态相结合的调度策略对4组数据量分别有21.17%、14.79%、18.17%、12.05%、16.76%、16.97%、18.95%和13.57%的性能提升;基于队列的混合调度策略对4组数据量分别有25.38%、28.27%、27.18%和25.72%的性能提升.
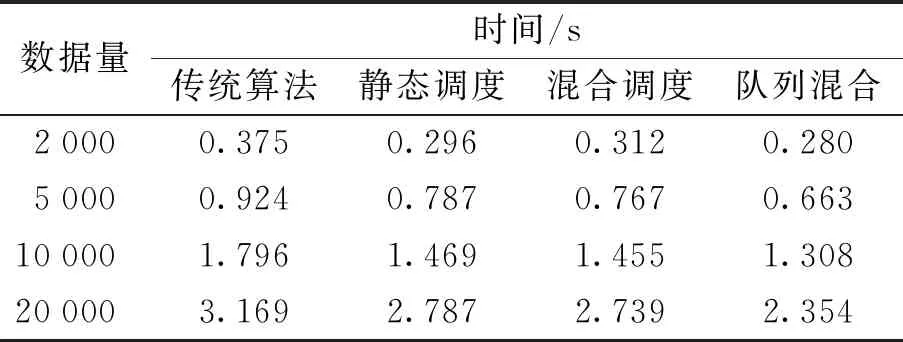
表3 Kmeans性能展示
3种调度算法的优化效果如图4所示. 静态调度策略、静态与动态相结合的调度策略和基于队列的混合调度策略的平均性能提升为16.54%、16.56%和26.64%.
3.2.4 基准测试程序Nbody
多体问题(Nbody)是一个非常著名的物理问题. 该问题研究N个星体间作用力问题,这类程序属于CPU与GPU计算能力相差悬殊的应用类型. 当将星体数量设为8 192时,GPU处理时间为6.99 ms,CPU处理时间为17.330 97 s. CPU和GPU在处理该实例的计算速度差距非常悬殊,理论的性能提升可以忽略不计. 系统内部计算时间的误差大于基于负载均衡的性能提升空间. 实际调度在执行过程中因为添加算法的开销导致结果更差.
通过对比发现,本文设计的任务调度策略对于CPU与GPU计算差距在同数量级类型的程序有明显的性能提升. 其中基于队列的混合调度策略在性能表现上明显优于其他2种,对本文选用的MatMul、Pathfinder和Kmeans三个基准测试程序系统性能分别提升了29.97%、27.62%和26.63%,平均提升了28.08%. 其他2种调度方案相比于传统调度方案平均分别提升了12.96%和17.30%. 具体性能提升对比见图5.
对于CPU与GPU计算差距悬殊的应用,理论上负载均衡不再是此类应用提升性能的方法,应该更多地考虑单CPU/GPU的优化方案.
4 结论
1) 文中设计的任务调度策略对于大部分应用性能提升明显,该策略在任务处理前将计算任务存入双向队列,并结合了动态调度策略,平衡负载能力更强. 从不同数据量的同组实例可得出结论,系统运行的实时性能并不稳定,导致静态调度策略和静态与动态相结合的调度策略对于性能提升实际值与理论值差距较大且性能波动较为明显,2种策略在相同实验环境下最大分别有9%和8%的波动,而基于队列的混合调度策略只有不到4%.
2) 本文设计的任务调度策略能够有效平衡异构计算平台CPU与GPU负载,同时构建任务队列和10%动态调度所造成的时间开销不会对系统性能产生明显影响.
3) 文中设计的任务调度策略均适合CPU与GPU计算性能处于同一数量级应用. 对于CPU与GPU性能相差巨大的应用,提升效果不明显. 例如文中采用的Nbody实例,该实例GPU计算速度是CPU的近2 500倍,理论的性能提升可以忽略不计. 此类型实例的局限性决定了优化方法,与算法无关.
4) 本文设计的任务调度策略对系统性能提升明显,不需修改即可适应不同计算单元型号(计算能力)的CPU与GPU. 值得指出的是,异构平台的负载受CPU和GPU计算能力影响较大,对于不同型号CPU与GPU,实际划分比例可能区别较大,产生的性能提升效果会有明显差异.
