考虑评级信息的音乐评论文本自动生成*
2020-08-12刘红岩杜小勇
严 丹,何 军+,刘红岩,杜小勇
1.数据工程与知识工程教育部重点实验室(中国人民大学 信息学院),北京 100872
2.清华大学 经济管理学院,北京 100084
1 引言
在线唱歌平台提供了一种随时随地演唱歌曲、发布演唱的音乐作品以及与他人交流的新型娱乐方式,近年来吸引了大量的用户。用户演唱的音乐作品发布到平台上之后,其他用户播放音乐作品并提供反馈,如写下评论或者点赞。发布的作品被其他用户评论是平台用户之间分享和交流的方式之一,也可以激励用户发布更多的作品。但是对于一些新用户的作品或者新发布的作品,由于播放次数很少或者没有,因此没有用户发表评论。对音乐作品自动生成评论可以在一定程度上解决此问题。如何自动生成准确且多样化的评论是此类研究的关键。对于用户发表的每一个音乐作品,平台都会给出一个评级信息,体现音乐作品的演唱水平。本文发现对于具有不同表现等级的音乐作品,用户提供的评论文本存在差异,等级越高的音乐作品,其评论文本的多样性越高。因此,本文研究考虑音乐作品评级信息的评论文本自动生成的方法。
生成式对抗网络(generative adversarial net,GAN)[1]是近年来提出的一种深度学习网络模型,在文本生成领域[2]也有较好的表现。它使用判别器来指导生成器的文本生成过程。但是用GAN自动生成的文本缺乏多样性,已有研究在解决生成文本缺乏多样性的问题的同时,忽略了生成文本的质量,即句子的准确性和流畅性。
为了解决这些问题,本文提出了基于生成式对抗网络的文本自动生成模型——GradeGAN。该模型引入等级判别器,使其与文本判别器共同学习来指导生成器的文本生成,使用文本判别器是指导生成器生成质量更高的文本,使用等级判别器是指导生成器生成更加符合音乐等级的文本。
本文的主要贡献如下:
(1)提出了一种新的文本自动生成模型Grade-GAN,用于为音乐作品自动生成评论文本,使生成的评论符合音乐等级信息。
(2)在实际在线唱歌平台数据集中对所提模型进行了性能评估,验证了所提方法的有效性。
2 相关工作
文本生成是自然语言处理的一个重要研究领域。一个标准的Seq2Seq(sequence-to-sequence)[3]网络语言模型在自然语言生成领域表现良好,但是存在两个主要缺点:首先,基于循环神经网络(recurrent neural network,RNN)的模型通过最大似然方法进行训练,该方法在训练阶段存在暴露偏差[4]。其次,用于训练的损失函数是单词级的,但是性能通常是在句子级评估的。为了解决这些问题,提出了利用生成式对抗网络(GAN)实现文本自动生成的模型。
生成式对抗网络(GAN)是近年来新兴的一类深度生成模型。虽然GAN在计算机视觉应用方面取得了巨大的成功[5],由于离散序列不可微的特性[6],GAN应用于自然语言生成的研究相对很少。一些工作试图解决这个问题,其中用强化学习的策略来处理不可微问题最为常见[2,7-8],其中SeqGAN[2]是这类问题的代表,但是这类方法不能生成具有不同属性的文本。
针对生成不同属性的文本,SentiGAN[9]取得了比较好的结果,它是由多个极性生成器和一个多类文本判别器组成,可以根据不同的情感值生成相应的情感文本,但是该模型在提升多样性的同时降低了生成文本的准确性。因此本文的研究旨在提出一种生成具有不同属性的文本的方法,如针对不同评论等级的文本生成的方法,在提升多样性的同时提升准确度。
3 GradeGAN模型
给定一组音乐作品集S和评论等级集合G,假设每个作品i∈S的评级为gi∈G,其发布用户的以往作品评论集为singeri,与i的歌曲相同的其他发布作品的评论集为songi,将这两个评论集合并作为作品i的相关评论集SCi。本文的研究问题为:当一个新作品i发布时,根据其评级gi和相关评论集SCi生成评论文本Ci={c1,c2,…,ct,…,cT}。ct∈C,C是候选词的词汇表。评级反映了音乐作品的演唱水平,分为3个等级,即G={1,2,3}。为了描述的简洁性,下文的描述中省略上标中的作品编号i。
3.1 GradeGAN模型结构
GradeGAN 模型基于SeqGAN 的架构,引入等级判别器,其基本结构如图1所示。这个模型包括编码器、生成器、文本判别器和等级判别器4个主要模块。
给定一个音乐作品的相关评论集和评级的具体等级,模型输出为由T个词构成的文本C={c1,c2,…,ct,…,cT}。其中编码器主要是提取输入文本的信息,生成器基于该提取的信息生成评论文本的每个词,其生成过程利用强化学习的过程实现。具体来说,假设当前已经生成了t-1 个词:C1:t-1=(c1,c2,…,ct-1),则在t-1 时刻,状态(state)st-1由这已经生成的t-1个词表示,生成器生成下一个词的动作(action)就是在候选词表中选择概率最大的词,动作确定之后,下一时刻的状态就确定了。为了确定每个状态下的动作,以选取合适的词,对于可能的候选词(即动作),借助文本判别器和等级判别器来度量该动作的反馈(reward),根据策略梯度(policy gradient)学习策略来学习动作的选择策略。
生成器生成的评论文本用来训练文本判别器和等级判别器,由二者共同作用得到反馈用于训练生成器的生成过程,由此交替训练生成器、文本判别器和等级生成器。下面对各个模块进行详细解释。
3.2 编码器和生成器
长短期记忆网络(long short-term memory,LSTM)[10]和门控循环单元(gated recurrent unit,GRU)[11]等门控循环神经网络在文本生成相关任务中相比于简单的RNN性能表现更好[12-13],本文使用LSTM作为编码器结构和生成器结构。
LSTM中时间步t单元的计算过程为:

其中,[ht-1,ct]为时间步t时上一个隐藏层向量ht-1和当前输入ct的向量级联,⊙表示元素积。
3.2.1 生成器预训练
在生成器的预训练阶段,文本利用编码器从音乐作品的相关评论集中提取有效信息作为生成器的输入。给定音乐作品的相关评论集SC={sc1,sc2,…,sct,…,scL},将SC输入到编码层,经过编码层编码输出最后一个隐藏层的状态hL,将hL作为生成器隐藏层的初始状态输入到生成器中。
使用最大似然估计(maximum likelihood estima-tion,MLE)来预训练编码器和参数为θ的生成器Gθ,也就是使生成的评论文本与真实评论文本x={x1,x2,…,xt-1,xt,…,xT}的负对数似然函数最小化,即损失函数为:

Fig.1 Framework of GradeGAN图1 GradeGAN的模型结构
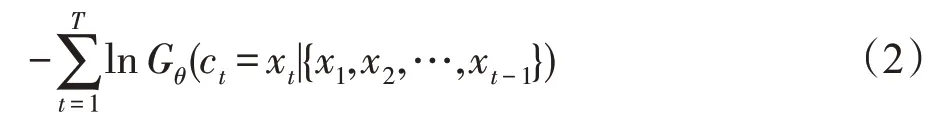
3.2.2 策略梯度学习
在生成器策略梯度学习阶段,生成器Gθ在生成文本的过程中,使用文本判别器和等级判别器共同作用来调整生成器的生成过程。文本判别器记作Dϕ,训练参数为ϕ;等级判别器记作gradeφ,训练参数为φ。
在时间步t,状态st-1是当前已经生成的评论序列C1:t-1=(c1,c2,…,ct-1),要选择下一个词ct。用Gθ(ct|C1:t-1)表示选择下一个词的概率分布。用文本判别器Dϕ判断生成文本为真时的概率,记作Q;用等级判别器gradeφ判断生成文本的等级,其中与真实评级相同的等级的概率,记作M。用Q和M共同作为生成器生成过程中每个动作的反馈(reward)。
在策略梯度学习阶段,使用蒙特卡洛搜索在每一步都通过搜索得到完整句子,在文本判别器和等级判别器的共同作用下,生成器的优化目标就是令从初始状态开始的反馈最大化。

其中,RT是评论文本由文本判别器判断为真的反馈,WT是评论文本由等级判别器判断为真实评论等级的反馈。表示在状态s0下选择下一个词c1时,由文本判别器得到的反馈。表示在状态s0下选择下一个词c1时,由等级判别器得到的反馈。
3.3 文本判别器和等级判别器
因为文本判别器和等级判别器都属于文本分类任务,且卷积神经网络(convolutional neural network,CNN)[14]在文本分类任务中性能突出,所以本文选择CNN作为文本判别器模型和等级判别器模型。
在CNN 分类模型中,假设输入的词序列为(a1,a2,…,aT),要对其进行分类,首先需要将离散的词编码级联成向量矩阵:

其中,at∈Rk是k维的词向量,⊕是建立矩阵ε的垂直级联运算符,ε∈RT×k。
然后对矩阵ε进行卷积、池化操作,卷积核的大小为ω∈Rl×k,对l个词大小的窗口进行卷积操作,生成一个新的特征图:

其中,⊗是卷积操作,b是偏置向量,ρ是一个非线性函数,本文使用Relu 函数。在实验中使用了不同大小的卷积核来提取特征。通过卷积操作后,得到新的特征图为:
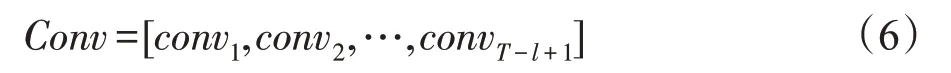

其中,Wo、bo是输出层的权重和偏置。σ依据类别的个数不同,选择sigmoid或者softmax函数。
3.3.1 判别器预训练
在生成器预训练收敛后,利用生成器生成的评论文本来预训练文本判别器和等级判别器。
在文本判别器Dϕ模型中,输入的序列是真实评论文本和生成的评论文本,有真假两个类别。通过CNN 网络分类,在输出层就可以得到生成的评论文本为真的概率。在优化文本判别器时,利用最小化交叉熵作为目标函数:

在等级判别器gradeφ模型中,输入的序列是生成的评论文本,分类的类别个数是音乐评级的等级个数,在本文中,有3 个等级。通过CNN 网络分类,在输出层利用softmax得到生成的评论文本在评级的各等级下的概率分布。
在优化等级判别器时,因为各个等级之间有顺序关系,采用最小均方差(mean-square error,MSE)作为目标函数:

其中,gi是第i个评论文本对应作品的真实评级,是评论文本被等级判别器最大概率预测的等级。
3.3.2 策略梯度学习
在策略梯度学习阶段,当前状态为st-1,生成下一个词ct时,文本判别器判断为真时得到的反馈记为等级判别器判断其等级为真实等级对应的反馈记为
在时刻t时,为了衡量下一个词ct的反馈,采用蒙特卡洛搜索方法,基于当前已经生成的词和下一个词ct搜索得到N个完整句子,由文本判别器和等级判别器对这些完整句子进行判别。将这N个句子分别输入到文本判别器和等级判别器中,将其判断为真实文本的概率N)求平均,将其判断为真实评级的概率1,2,…,N)求平均。这两个值分别作为反馈和
3.4 目标函数
生成器生成的评论文本用来训练文本判别器和等级判别器,由二者共同作用得到反馈用于训练生成器。因此在文本判别器Dϕ和等级判别器gradeφ参数更新后,就可以用来更新生成器Gθ。生成器Gθ是通过策略梯度学习的方法来训练,目标函数为Jθ,使目标函数最大化,就可以更新参数θ。Jθ的梯度公式为:

在式(10)的基础上,可以去掉期望项,构造一个无偏估计再继续推导:

其中,C1:t-1是生成器生成评论文本过程中的中间值,期望值在生成器生成过程中通过采样方法近似得到,则生成器Gθ的参数θ更新为:

其中,αh表示学习率。
4 实验
4.1 实验设置
4.1.1 实验数据
实验数据集是来自StarMaker 在线唱歌平台上2017年12月60 000个作品的评论文本信息和作品的音乐等级。音乐等级是根据作品中歌手的音准系统自动打分,并将分数分为3 个等级,这3 个等级就是本文所指的音乐评级的等级。候选词表中每个词的词向量利用这些评论文本基于word2vec 模型训练。相关评论文本包括作品中歌手其他作品的评论文本和与作品中所唱歌曲名相同的其他音乐作品的评论文本,这些选取的相关评论文本的音乐作品的音乐等级都与要生成评论的作品相同。在3 个等级中分别选取15 000 个作品作为训练集,每个音乐作品中选取5条词数小于25的相关评论文本作为输入。剩下的作品作为测试集V。
4.1.2 训练设置
在实验中,文本判别器的训练集由类别为0的生成评论文本和类别为1 的来自训练集的真实评论文本组成,卷积核的大小分别为3、5、10、15,卷积核的数量分别为100、200、100、160。等级判别器是由生成的评论文本和来自训练集的真实音乐等级组成,卷积核的大小分别为3、5、10、15,卷积核的数量分别为100、200、100、160。使用Dropout[15]和L2正则化来避免过拟合。
为了评估GradeGAN模型生成评论文本的性能,将此模型与以下方法进行比较:
(1)Seq2Seq 模型[3]:使用相关评论作为输入,生成评论文本。
(2)SeqGAN 模型[2]:在Seq2Seq 模型的基础上,加入判别结构。
(3)SentiGAN 模型[9]:不同等级作品文本信息输入到不同的生成器中,文本判别器是一个类别为不同等级数的多类别文本判别器。
4.2 实验结果
4.2.1 生成评论文本的准确度
使用Rouge[16]中评估指标计算生成的评论文本和真实评论文本之间重叠单元的数量,用于评价生成评论文本的准确性。
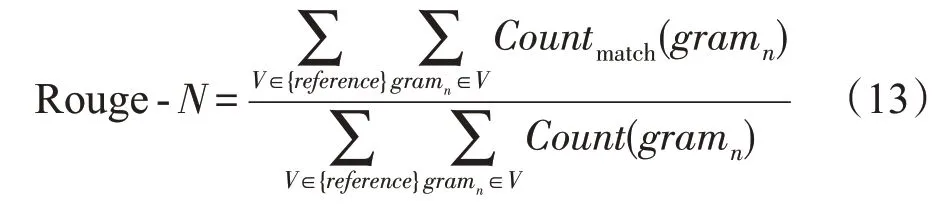
其中,gramn表示长度为n的n-gram,{Reference}表示真实评论文本,Countmatch(gramn)表示生成文本和真实文本中同时出现gramn的个数。Count(gramn)表示真实文本中gramn的个数。Rouge-N是基于召回率的方法,因此分母是真实文本集合中所有n-gram的个数。
在实验中,分别用Rouge-1、Rouge-2 和Rouge-L这3个指标来评估生成评论文本的准确性,实验结果如表1所示。从中可以看出,GradeGAN模型生成评论文本的准确性最高,相比于SeqGAN模型,GradeGAN模型在加入等级判别器后,使得生成文本的准确性提高了很多。

Table 1 Comparison of accuracy of generated comment texts表1 生成评论文本的准确性对比
4.2.2 生成评论文本的流畅度
使用语言建模训练工具SRILM(SRI language model)[17]来评测生成文本的流畅度。SRILM 使用训练的语言模型计算生成句子的困惑度(perplexity)。困惑度越低,说明生成文本的流畅度越高。实验结果如图2所示,从图2中可以看出,GradeGAN模型生成评论文本的流畅度明显高于其他模型。
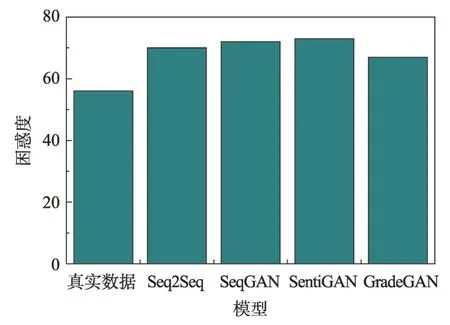
Fig.2 Comparison of fluency of generated comment texts图2 生成评论文本的流畅度对比
4.2.3 生成评论文本的多样性
希望生成的评论文本具有多样性,且在不同的音乐等级下,生成的评论文本具有差异。计算评论文本多样性的方法如下:
在测试数据V中,测量生成评论两两之间的Rouge 值,再求平均,得到整个生成评论数据集的相似性,1减去这个相似性,就得到生成评论的多样性。

首先,基于3 个不同的指标Diversity-Rouge-1、Diversity-Rouge-2、Diversity-Rouge-L来评估生成评论文本的整体多样性,结果如表2所示。从表2中可以看出,GradeGAN 模型的整体多样性要比Seq2Seq和SeqGAN 模型高,说明模型在加入等级判别器后,生成评论文本的多样性提高了很多。
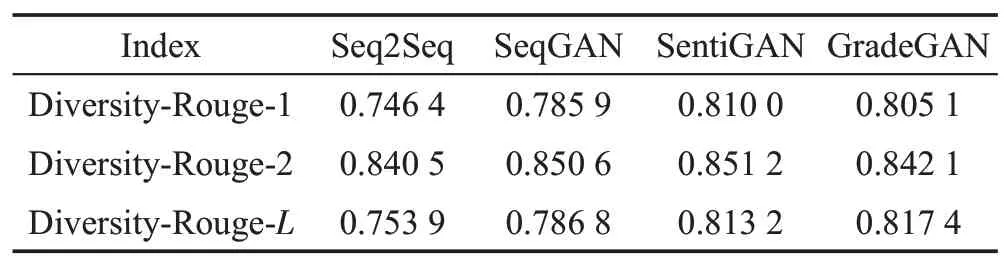
Table 2 Comparison of overall diversity of generated comment texts表2 生成评论文本的整体多样性对比
与SentiGAN 模型相比,本文所提模型多样性在两个指标上略低,在一个指标上略高,但准确度高出很多。因为SentiGAN模型主要是通过不同的生成器来生成不同类别的文本,生成器在生成文本的过程中通过最小化生成期望来达到生成文本多样性的目的,这样导致生成的文本的准确性降低。而本文认为相比多样性的提升不应该以牺牲准确性为代价,因此所提模型在准确度和多样性两方面进行平衡。
其次,基于Diversity-Rouge-L这个指标来评估在不同音乐等级下生成评论文本的多样性,结果如表3所示。从表3中可以看出,当音乐等级越高时,GradeGAN模型生成评论文本的多样性越高,这与真实数据是吻合的。在StarMaker 在线唱歌平台中,当音乐等级是1时,评论文本大都是It's ok或thank you这类重复文本,当音乐等级是3 时,评论文本则更加多样,如You have a beautiful voice 或Looking forward to more music works from you等带有个人情感和想法的这类文本。从表3中可以看出,其他模型无法做到当音乐等级越高时,多样性越高。
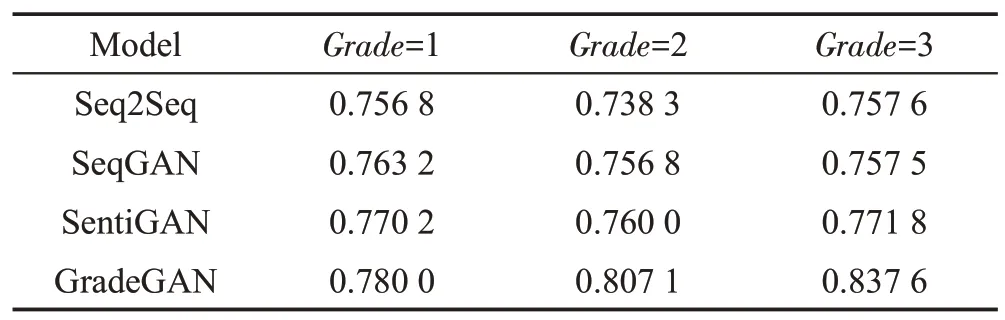
Table 3 Diversity comparison of generated comment texts under different performance grades表3 不同音乐等级下生成评论文本的多样性对比
5 结论
本文研究在线唱歌平台上为音乐作品自动生成评论文本的方法,提出了考虑作品的歌唱表现评级信息的文本生成模型——GradeGAN,利用文本判别器和等级判别器共同指导生成器生成文本。在真实数据集上的实验表明,GradeGAN模型相比已有的相关模型具有更高的准确性,同时具有良好的多样性,同时可以针对不同等级的作品生成不同的文本。本文所提方法不仅适用于音乐作品的评论文本生成,也适用于其他应用场景,例如生成电影评论。在电影没有评论或者评论较少的情况下,利用GradeGAN模型根据电影评分和电影相关文本信息自动生成电影评论文本。
