基于学科特性的高校图书馆读者借阅行为实证研究
2020-08-12陈添源
陈添源
(闽南师范大学图书馆,福建 漳州 363000)
1 引 言
当前高校图书馆纸质图书借阅量逐年下滑,加之图书购置经费不足和馆藏空间转型等外在因素影响,馆藏资源在教学和科研的文献保障能力和形态正在悄然发生改变。提振借阅率、优化馆藏建设结构和提高精准化的图书借阅服务,逐渐成为高校图书馆发展转型中不得不面对的实践问题之一。为此,准确把握高校图书馆读者的用户行为,建立用户驱动的馆藏建设与服务体系日益迫切。然而,由于高校图书馆自动化系统从用户视角的固定化报表与统计数据较少,随需而变的用户行为数据存在难以获取、历史数据积累较少和系统孤岛等技术因素,直接导致了基于数据驱动的业务决策模式无从谈起。为此,文章试图探索构建一套挖掘高校图书馆用户借阅行为的实证研究体系,并抽样选取不同学科类型读者的借阅行为作为实证研究对象,实证获取的结论可以丰富和完善图书采访人员的采购策略,优化图书馆馆藏建设体系,提高基于不同学科特征的精准化图书借阅服务能力,以期逐步建立起基于读者真实需求的馆藏建设新模式。
2 相关研究述评
国内高校图书馆从业务实践出发,结合自身图书馆业务实际和读者需求不断优化图书借阅服务和创新读者服务模式。较多的研究集中于图书借阅关联分析,例如,南昌航空大学图书馆结合借阅服务特征,使用改进的L-Apriori关联算法实现图书的个性化推荐[1]。任武[2]通过构建读者偏好的本体模型分析了读者借阅行为,从而获取读者阅读偏好值实现个性化推荐服务。张炜[3]通过关联挖掘技术对读者借阅数据隐含的知识展开分析,从而缩短读者需求与图书馆服务之间的差距。一些研究从提升图书借阅率的视角切入,钱玲飞等[4]采用h指数对OPAC数据统计分析,获取不同图书集合的“核心读者”以及不同读者群的“核—Ca”图书,从而实现馆藏的合理分布和图书使用率。孟德泉等[5]利用主成分分析得出影响读者借阅行为的关键因素,并根据研究结果提出提升图书外借率的具体建议。许毅等[6]将读者图书借阅册数、进馆人次与本科生成绩等字段联合回归分析,指出图书馆资源利用率与学业成绩存在极强的正相关关系。而在读者借阅行为分析的研究方面,刘春霞[7]从提升图书借阅率的角度出发,采用方差分析、相关分析和回归分析等统计方法挖掘,从而为图书采访建设与借阅管理提供决策支持。吕远等[8]借助关联和分类分析等数据挖掘方法实证分析了在校读者的借阅行为模式,并提出建立以用户需求驱动的主动服务方式。邢荣华等[9]基于流通借阅日志分析了各时段读者借阅的行为差异。严贝妮等[10]从抽样调查的10所高校图书馆2016年的借阅排行入手分析了读者阅读行为,指出读者阅读有较强的偏向性和功利性,倡导多元阅读和提升读者阅读修养。
陈凤[11]所指出,将读者图书借阅行为可视化分析并直观地支持采购决策已成为当前实践研究常态。蒋小峰[12]在对近10年高校图书馆流通借阅服务的总结与分析基础上,明确提出在读者需求产生的原因、演变规律以及满足需求的途径等方面应深入研究。从前述研究不难发现,诸多文献未能融入诸如学科背景、专业特征、学习需求和借阅次数等外在因素一同作用户行为分析,所采用的分析数据也仅能分析单独一个年度的借阅数据,未能形成基于历史数据的规律挖掘。这一方面源于图书馆自动化系统软件都未集成图书流通的关联分析模块;另一方面是可视化的用户行为分析工具尚未得到广泛应用,图书馆及时挖掘和分析读者借阅行为的时效性明显滞后。
故此,文章将基于大数据思维理念,通过相关数理分析工具和模型算法,从自动化系统中抽取我校读者6年以来的读者借阅行为数据,探寻读者借阅行为,系统全面地掌握基于学科特性的读者借阅行为特征,不断积累读者的借阅行为规律、热门图书、主题词分布和图书关联,从而实现更为精准的纸质文献保障。建立和优化基于读者行为驱动的馆藏建设服务体系,提升馆藏纸质图书建设经费的效益,也为图书馆馆藏空间让位空间服务提供有益的业务决策。
3 实证研究设计与相关模型方法
3.1 实证思路与框架
以学科特性为视角,选取高校图书馆某个学院历年的读者借阅数据,以此数据集为实证对象,结合高校读者学科专业学习的阶段特性,借助大数据分析Tableau平台、R语言关联分析和主题词分词技术等定量分析方法,探索与分析基于学科特性的借阅规律和主题词演变规律,从而更为精准地为高校图书馆的新书采编、典藏优化和学科服务提供决策支撑,力求形成系统性把握图书馆在教学与科研的纸质资源保障特征。
确立以上实证思想后,本文重点分析:1)图书借阅的潜在联系。读者在借阅图书时,是否与其学科和学习阶段相关联,能否根据当前所学的专业进行特定分类号内的图书选择,这些图书之间是否存在一定的关联;2)根据已借阅图书的主题词和图书题名分词后的汇聚分布情况。详细的实证分析框架如图1所示。

图1 基于学科特性的高校图书馆借阅行为分析框架
3.2 关联分析
无论是馆藏纸质图书,还是电子图书,图书的流通和检索获取都存在着与商品销售相似的关联特性,图书馆的管理者都期望从内外在因素探索图书在流通时的关联,从而挖掘出图书之间的前后借阅关系,积累读者借阅行为的规则库和知识库,提升图书馆个性化服务的精确度。关联分析一般被用于挖掘隐藏在大型数据集中的有意义联系,所获取的结果采用关联规则或者频繁项集表示。图书借阅前后时序的关联挖掘与分析,目前较为典型的是Apriori算法。最为经典的应用当属沃尔玛公司的“啤酒、尿布”购物篮分析,目前广泛应用于商品购物篮数据、生物信息学、医学诊断和网站挖掘等科学数据分析领域。通过数据集挖掘获取的关联规则是否有效,一般采用它的支持度、置信度和提升度三个指标度量。
支持度是关联规则的重要度量指标,因为支持度很低的规则可能只是偶然出现,低支持度的规则多半也是无意义的。因此,支持度通常用来删去那些无意义的规则。置信度是通过规则进行推理具有可靠性。对于给定的规则X→Y,置信度越高,Y在包含X的事物中出现的可能性就越大。即Y在给定X下的条件概率P(Y|X)越大。借鉴Apriori算法思想对于支持度和置信度的定义,本文根据图书馆实际借阅情况作出相应的定义:支持度是指读者借阅的图书集合中,某个项集出现的百分比;与商品关联分析不同的是,商品领域的“副本量”较大,而高校图书馆则存在图书复本较少的情况。因此,图书借阅关联分析时将读者该年度的所有图书借阅记录合并视为一个集合。置信度是指获取的关联规则X→Y中,项集{X,Y}同时出现的次数占项集{X}出现次数的比例。可理解为读者借阅图书X的情况下,后续借阅Y的概率。为有效衡量项集{X}和项集{Y}的独立性,关联分析中设立了提升度(lift)指标。提升度就是在借阅图书X这个条件下借阅图书Y的可能性与没有这个条件下借阅图书B的可能性之比。
考虑实际的图书借阅情境,一方面,图书借阅无法类似于货架上的商品售卖,“复本量”保障供应充足。另一方面,读者借阅图书基于学科专业学习需要、复习迎考、各类专业资质认证和阅读畅销图书等因素,存在集中借阅复本量不足的某种分类号图书,这将无法获取读者实际的图书需求,进而导致关联分析无法采用商业领域的购物篮分析方式。本文将采用基于时序的关联分析方法,借助R语言里的arules数据包合理调整算法中的支持度(support)、置信度(confidence)和提高度(lift)指标,挖掘适宜于图书馆业务实践需求的关联规则。
3.3 主题词文本挖掘方法
为更详细地掌握基于学科特性的读者借阅行为,透过图书主题词分类与题名信息掌握和挖掘读者借阅图书的主题词分布情况,除了统计被借阅图书的分类主题词,还采用文本挖掘技术对图书借阅历史中的图书题名分词处理,可以更为精细地汇聚产生某一个时段集中借阅的图书种类和借阅热点,从而有利于新书采购策略调整和馆藏借阅服务的精准化。当前文本分词工具有很多种,Jieba分词是中文自然语言分词较为常用的一种。它采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,分词准确度高[13]。支持精确、全模式和搜索引擎三种分词模式。Jieba在R语言平台上有专门的软件包JiebaR,可采用自定义字典和函数调用方式对图书主题词分词,从而实现主题词集中汇聚展示。
4 实证分析
4.1 数据集获取及行为数据概览
借助Tableau平台,通过数据库接口从馆藏自动化系统选取采集计算机学院等6年来所有有效读者的借阅历史记录,字段涵盖读者证号、借阅日期、借阅图书题名、索书号、借阅次数等字段。基于前述,以计算机学院为例阐述本文实证分析过程,获取的计算机学院借阅记录共包含 125 180 条。删除字段缺失数据792条,有效数据为 124 388 条。按照自然年在Tableau平台绘制借阅历史曲线,如图2所示。

图2 计算机学院读者2012—2017年每月借阅图书统计
从图2可以看出,计算机学院读者的年度借阅数量呈现逐年下降趋势,每年的借阅行为曲线呈现出明显的季节性变化,这与该专业读者的高校专业学习阶段特征较为符合。通过Tableau平台的数据透视功能,以每年3月的借阅高点进行对比发现,该月都是年度借阅高峰,从汇聚的主题词来看,这与高校计算机专业读者的学习阶段相匹配:毕业论文、专业方向学习和考级准备息息相关。
2012—2017年,计算机学院的读者共借阅 23 236 种图书,生均借阅19.6本,最高为263本。从性别差异对比看,男性读者比女性读者多借阅了 7 000 多次。统计每个借阅时段的借阅次数,该学院读者倾向于在早上9点—11点借阅图书。从分位数分布情况可以看出,计算机学院读者的借阅图书记录中,25%的借阅包含了4本或者更少的图书,大约50%为12本,详见表1。

表1 计算机学院读者借阅记录的分位数特征
在Tableau平台上汇聚图书分类号,如图3所示。计算机学院借阅图书依次排序的前10种是I267/SM(三毛小说系列)、TP312C/WX11(C#语言类)、TP312C/TH17(C语言类)、TP312C/MR11(C、C++和C#等编程类)、TP312JA/WG8(各类软件开发案例类)、TP312JA/LZ23(JAVA编程系列)、I313.45/DY7(东野圭吾著作系列)、I313.45/CS3(村上春树著作系列)、O13/TJ4(高等数学系列)和TP312C/ZL(C++语言类)。此10种集中反映了计算机学院读者偏向于借阅编程类图书、流行小说和软件项目案例等,也说明纸质图书依然保障了高校读者在专业课程学习的文献需求。高校图书馆可以增加此类图书的复本数、推广相关的专题数据库资源和做好经典图书的阅读推广活动。
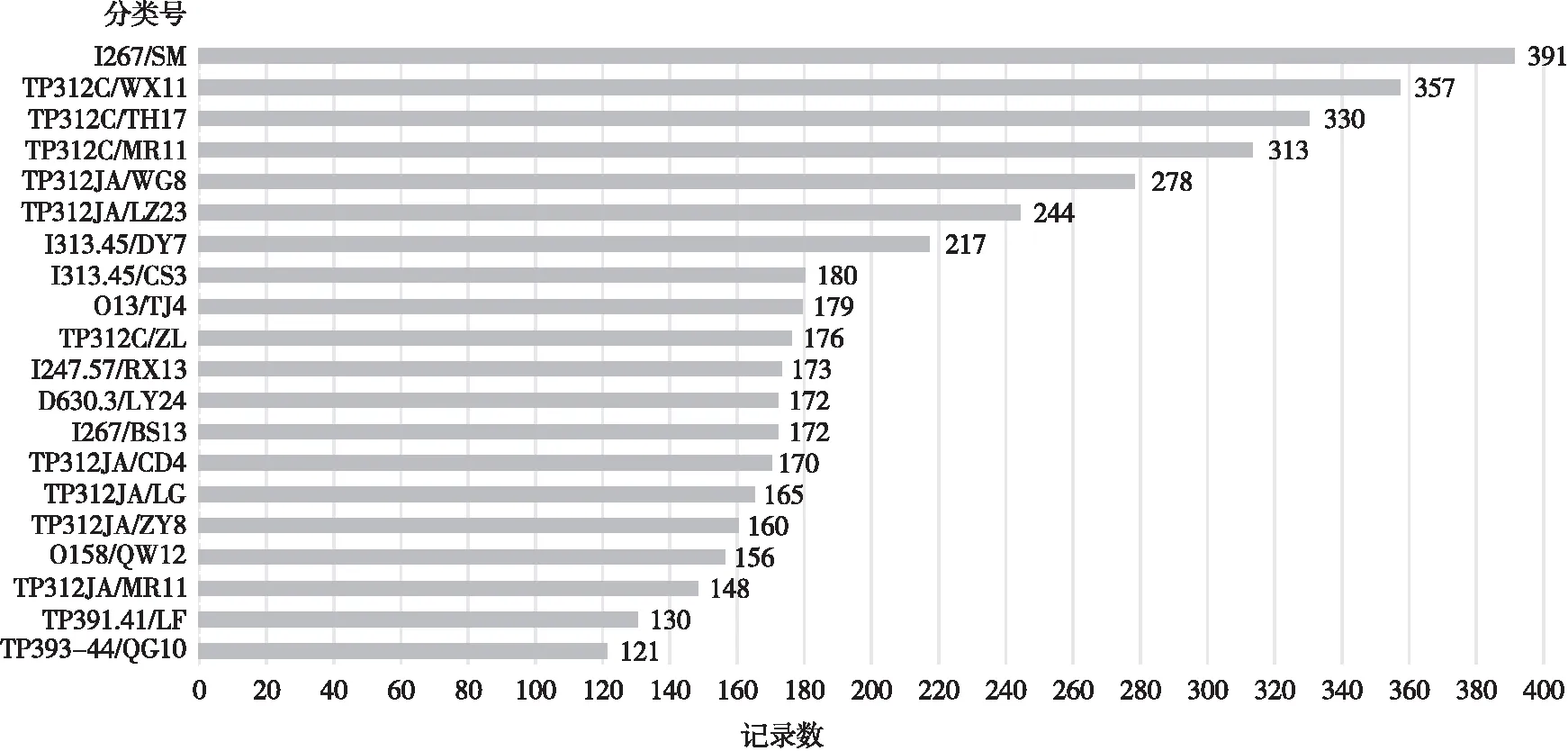
图3 计算机学院读者借阅图书分类号统计(2012—2017)
4.2 Apriori关联分析
4.2.1 数据转换。基于项集间的借阅时序关系,在R语言平台对获取的数据按照读者借阅时间进行排列。部分数据样式见图4。
图4 基于时间序列的部分读者借阅数据
因每行借阅记录记载读者一次借阅图书时,读者的ID、图书题名、分类号和借阅时间等字段。按照关联分析的数据格式要求,需要转换为项集,如项集{TP393.11,TP397.12}表示某位读者的图书借阅集合。为此,本文按照读者ID、借阅时间对数据集重新排序,然后通过函数转换为Apriori算法可处理的0-1稀疏矩阵。去除借阅时间的字段后,将读者的ID转换为因子型变量,采用R语言split函数进行数值处理,共获取计算机学院 2 797 位读者按照时序关系排列的图书借阅路径。此时调用as函数将其转换为transactions形式的稀疏矩阵。通过上述数据处理方式分别对其余学院借阅数据进行数据清洗,得到汇总数据如图5所示。

图5 部分读者图书借阅路径数据集
4.2.2 关联分析参数讨论与调优。关联规则获取是否有效取决于Apriori算法的支持度、置信度和提升度等参数值。考虑到商业领域的购物篮关联分析,其分析对象取值的数据粒度为商品种类。而对于图书而言,高校馆藏自动化系统的分类号的数据粒度更为精细。例如,以I267/SM为例,其表示当代作品三毛著作系列,馆藏查询对应100多本图书,这说明此粒度的图书类别已能明确表示读者的借阅行为。故此,本文对分类号不作合并归类处理。
关联分析算法中参数默认值设定支持度为0.1,置信度为0.8。首次运行算法无法获取有效关联规则。以前述获取的计算机学院读者借阅数据来看,每位读者平均年借阅2种分类号图书,图书借阅关联度显然不及购物篮分析中的商品关联结果。结合图5所示的读者借阅图书分类号集合,由于学科、专业和课程等因素影响着读者的借阅行为和倾向,导致分类号分布集中在计算机相关学科领域,而其他学科分类号的分布极为稀疏。故此,采用arules模型运算和分析图书借阅关联时,需要多次动态调整支持度和置信度的参数。
4.2.3 关联结果获取与分析。在R语言分析平台采用arules函数分析包对转换后的借阅记录数据进行多次参数调整后,支持度确立为0.0025,置信度为0.5,项集设置为至少2种,从而获取了13条关联规则。如图6所示,获取的关联规则支持度区间为[0.025,0.004],提升度区间为[11.8,195.8]。

对于关联规则的识别与区分,一般可将其归纳为可操作规则、平凡规则和费解规则等三类[14]。
规则1和规则2属于可操作性规则,借阅了TP393.08/XY分类号的读者,因专业课程的技术实战需要,也将借阅TP393.08/CX2,这两个分类号无前后优先关系。规则3与规则4的关联规律也与此相同,其中的分类号对应计算机专业考研书目。因此,从学科的文献保障角度出发,图书馆可增加此分类号的复本数,并调整此类馆藏比例,提升图书借阅量。
规则5和规则8以分类号TP393/SJ14为左关联点,规则5属于丛书上下册关系,规则8属于辅导解析的图书关联,两者均属于平凡规则类别,也同属于高校读者认证考试的必备书目。从高校图书馆文献保障的需求出发,可以通过在图书采编业务上增加复本来加强馆藏建设,满足高校读者在专业技术认证备考的图书借阅需求。
规则6、规则7、规则9和规则13属于有前后顺序的关联,4个规则涉及了计算机专业的网络工程师与软件设计师的认证考试、公务员招考和毕业设计课程。从数据集抽取查看,此类图书借阅群体集中于高校大四阶段读者,而且规则13涉及的毕业设计课程图书关联的支持度最高。结合规则的可信度和提升度,图书馆可在保障一定比例的图书复本前提下,从数据库资源、视频课程和电子图书等引入相应的数字资源予以保障,提高此类文献资源的可获得性与可用性,以及针对高年级本科教学的文献保障能力。
规则10、规则11和规则12属于费解规则,规则10和规则11反映了读者在阅读渡边淳一类著作以后,其后续0.3%的单次借阅中,各有50%的概率借阅了村上春树或者东野圭吾的著作。规则12则反映了读者先借阅王小波的著作后也同时会借阅村上春树的著作。这说明该学院读者倾向于阅读人性、侦探和悬疑类系列小说。
4.3 主题词分析
在Tableau平台上汇总借阅图书的主题词,连接图书馆自动化系统关联获取本地化主题词表作为待分析的图书主题词。为更精准地揭示这些主题词是否反映了周期性的借阅规律,按照自然年依次统计每个主题词的频次。通过R语言的wordcloud2词云工具,依次按照自然年读入主题词和频次字段,并按照频次降序排列,调用wordcloud2函数依次汇聚,最终结果如图7、表2所示。“长篇小说”“英语”“C语言”“散文”“JAVA语言”“短篇小说”和“程序设计”等主题词的图书一直保持前列,但从图5词云的字体相对大小,结合相邻频次计算百分比差异可以看出,上述高频的主题词图书借阅率经历2013年、2014年的增长后一直下滑。故此,这些借阅频次较高的主题词,并非读者不再借阅,而是全媒体图书资源的便捷让读者有更多渠道阅读,这足以反映纸质馆藏和电子馆藏优化调整的重点。与此同时,对2017年的百分比差异数据排序,持续增长的主题词为“叔本华”“python”“JBUILDER”“古典文学”“古典小说”“章回小说”“软件工程”“职业选择”和“讲史小说”等。这些主题词可以作为新书采访、馆藏调整优化和学科服务的决策依据。
将题名和图书被借阅时间两个字段抽取并导入R语言平台上,调用jiebaR软件包,导入学科相关领域的细胞词库和默认的停止词作为分词引擎参数对2012年的题名进行分词切割,共获取图书主题词 8 809 个。通过对停止词的多次筛选和调整,增加自定义词典和停用词,重新获取有效主题词 5 543 个。挑选前200个主题词通过wordcloud2模型包进行汇聚,按照此方法依次对后续5个学年的图书借阅记录进行文本挖掘,挖掘结果中,字体大小与主题词出现频次成正比,如图8所示。

图7 计算机学院读者历年借阅图书的主题词汇聚
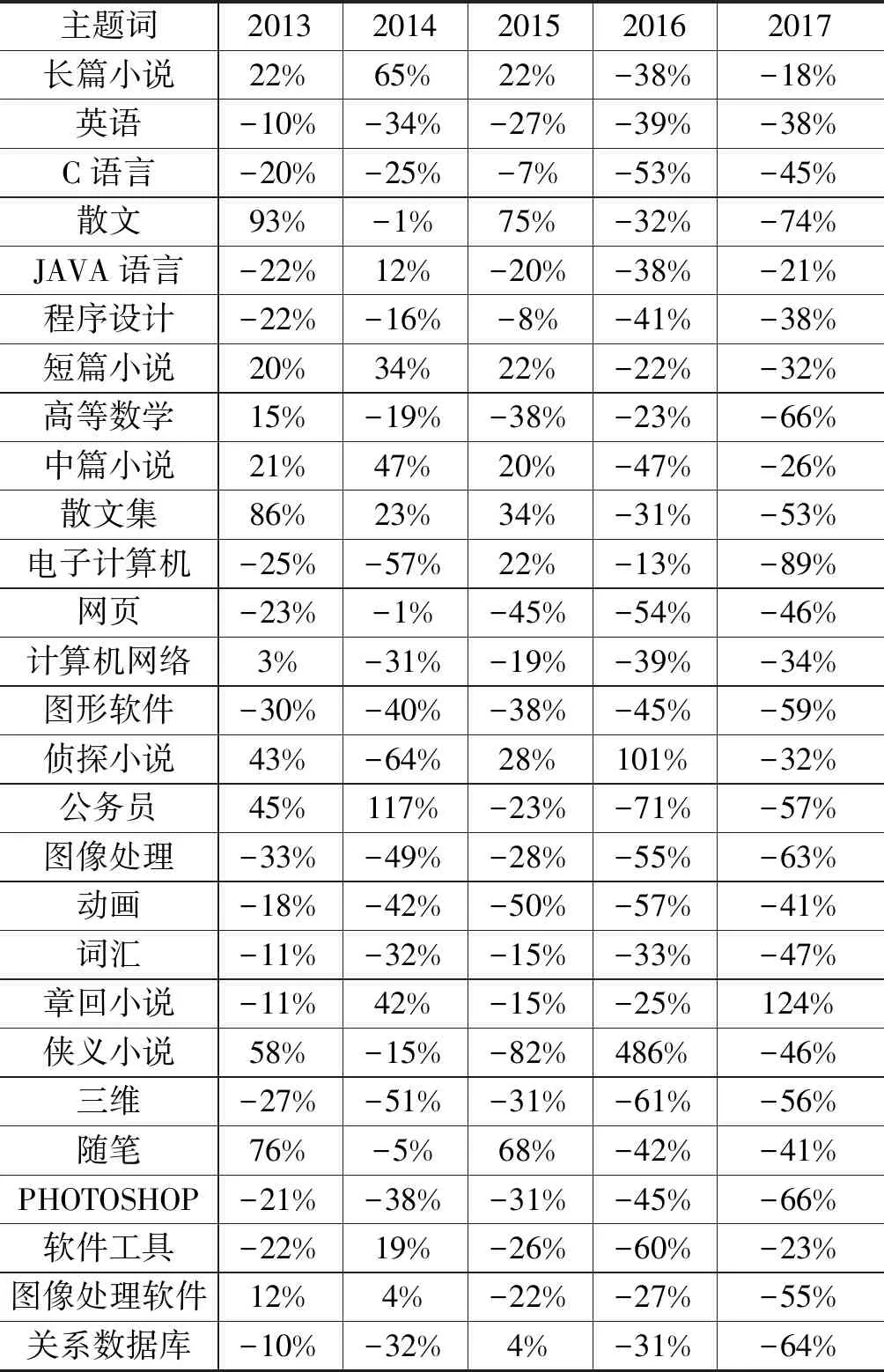
表2 计算机学院读者历年借阅图书的频次统计

图8 计算机学院2012—2017年图书借阅
观察分析图8的标签云,字体逐步变化到最大的关键词“JAVA”,说明该编程语言是我校计算机学院读者最常借阅的图书书籍主题。
其次,出现字体较大且保持稳定的主题词是“教程”“程序设计”“开发”“案例”和“入门”等。通过查询与这些主题词共现的图书名,基本涵盖的是编程开发类(如“C”“C++”“JAVA”“PHP”“ANDROID”)、图形图像类(如“PHOTOSHOP”“FLASH”“3DS MAX”“CORELDRAW”“ILLUSTRATOR”)和专业软件类(如“MATLAB”“AUTOCAD”“MYSQL”“SQL SERVER”)等。同时,也涵盖了英语、数学、物理、计算机网络和数据结构等基础学科专业。
部分主题词如“PHP”“HTML5”“MYSQL”“PYTHON”“CSS3”等当前技术发展热点相关图书的借阅量已经逐步上升,基于闽南师范大学计算机学科专业培养方向调整和学生对于未来岗位技能的知识需求,与此类相关的主题图书是今后该校图书馆馆藏采访与文献保障建设需要补充的方向。
将以上部分标签主题词进行内部连接,出现频率保持高位的“应用”“精通”和“设计”等主题词,侧面说明了计算机学院的读者在专业学习的定位明确,众多计算机领域专业技能学习的图书借阅率所占比例较高。图书馆较好地匹配了高校读者大学四年专业学习的需求和技能层次发展。
5 结语与展望
基于读者借阅行为的用户行为分析,是通过Tableau平台、R语言Apriori函数包、Jieba分词包和wordcloud2词云汇聚等挖掘方法从读者借阅行为数据的分类号、频次、主题词、题名和借阅时间等字段入手,较为全面地掌握高校图书馆计算机专业读者借阅行为的季节性变化,并根据图书馆藏结构和读者借阅图书的实际情境,调整关联规则置信度、支持度和提升度的参数,从而获取匹配业务实践且具有时序模式的关联规则,结合读者的学科特性和专业方向详细阐述3类关联规则,以期更为精准化的辅助图书馆决策。从规范化的图书主题词按照借阅频次排序和汇聚词云结果来看,揭示的主题词分布结果有效反映了读者借阅的变化趋势和今后的借阅上升区域,可以将其作为新书采访、馆藏调整优化和学科服务的决策依据。基于图书题名的自然语言分词和标签云汇聚,从较为细粒度的角度挖掘出基于学科特性的读者借阅行为,以数据可视化展示计算机读者的图书借阅热点变化。这些分析能够为高校图书馆调整馆藏结构、提升新书采访精准化和拓展有针对性的阅读推广提供非常有益的参考依据。
(1)以点带面,分析与挖掘其他院系专业的读者借阅行为数据,可以精准化推动大众化阅读推广工作。文章获取的数据显示,计算机学院读者借阅“长篇小说”常年排列首位,在主题词汇聚中还发现“古典小说”“章回小说”“短篇小说”和“散文”均为该学科特性读者借阅,但在关联规则挖掘中也发现倾向于某一类系列小说,因此,需要图书馆员加强阅读多样化引导、经典文学宣传推广等工作,拓宽读者的阅读视野。
(2)进一步加强热门图书以及技能认证和经典文学类图书的推介。加强纸质馆藏元数据与电子资源的元数据匹配,提高电子图书、专业辅导视频和技能认证考试的使用频率,实现更为快速的文献保障效率,完善高校图书馆全媒体资源的文献资源保障机制。
(3)更为精准地拓展有针对性的嵌入式学科服务。以文章分析的计算机专业为例,编程语言学习、项目案例开发和毕业设计等阶段的文献保障是每年较为稳定的读者借阅行为,面对借阅率下滑,高校图书馆应深化“纸电同步”的一体化馆藏体系,探索数字阅读和专业阅读的读者行为数据积累,不断绘制和完善高校学科专业视角的读者借阅行为用户画像,从而更为精准地提升在教学与科研中的文献保障能力。
