图形、AI“两开花”走近ARM Mali-G78、Ethos-N78
2020-08-11张平
张平

对于像ARM这样能影响整个行业发展方向的上游企业,其一年一度的技术更新《微型计算机》都会持续关注,并进行详细的报道。在上一期,我们为读者带来了CPU端Cortex-A78和Cortex-X1架构的详细介绍。在本期,让我们将视线转向GPU和AI计算,来看看ARMMali-G78和Ethos-N78这两个全新核心有哪些新进化。
ARMMali-G78:基于Valhall架构的改进
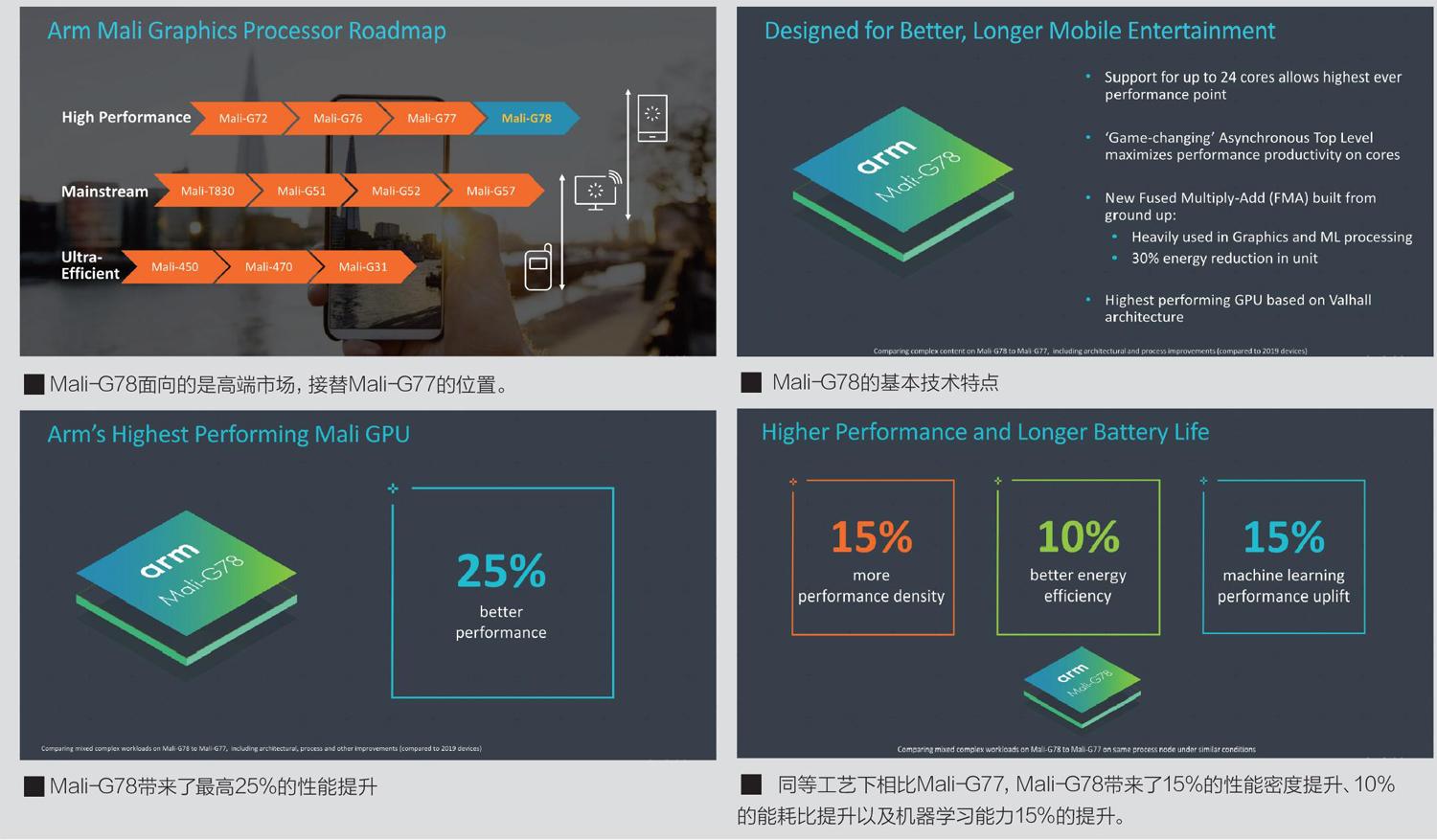
去年MC曾经介绍过ARM当时最新的Mali-G77GPU以及其使用的、全新研发的Valhall架构。这个新架构有着ARM近几年在GPU设计上最大的改进,它改善了之前ARM在移动GPU架构上的缺陷,整体设计更接近桌面处理器产品,而且它能够更好地适应如今移动设备日益增长的工作负载。本刊之前的文章曾详细介绍过Valhall架构的内容。简单来说,Valhall架構的变化主要有新的ISA和计算核心设计,其中包括采用了16宽度的波前阵列,在指令调度和编译性能上进行了改进,加强了纹理性能和几何性能的新ISA,新的缓存设计,新的执行核心尤其是FMA设计等。性能上,Valhall在可比条件下相比前代产品Mali-G76,其能效比提升30%,面积密度提升30%,机器学习性能提升60%。综合性能增加40%。
在可扩展性方面,ARM宣称Valhall架构最大可以扩展至32核心,但是最终我们看到Mali-G77最多只能扩展至16核心。在之后面世的终端处理器产品上,三星在Exynos990中采用了MP11的方案,联发科天玑1000则采用的是MP9的方案。鉴于此,ARM在Mali-G78上进一步扩充核心数量最大可配置24核心,也就是MP24。当然,更多的核心虽然对性能提升有帮助,但是依旧要考虑面积、成本、功耗等问题,厂商也不一定会在终端产品上使用这么多的GPU核心。但是在性能提升的硬指标上,ARM计划将Mali-G78的性能在Mali-G77的基础上提高25%,其中包括对Valhall架构和工艺节点进一步改进。
一般来说,这样的性能增长幅度对一个全新IP来说是合乎常理的,但其数据往往强烈依赖于制程工艺的改进,并且随着工艺提升,频率、晶体管密度等关键数据都会有比较明显的改善,因此厂商在宣传中往往会跳过工艺不谈,只强调效能。但是在这次的性能提升中,ARM直接给出了在相同工艺下,Mali-G78相比Mali-G77在性能、能耗比等方面的变化情况,其中包括性能密度提升15%、能耗比提升10%以及机器学习能力提升15%。这一成绩对于一个几乎没有大幅度改进的架构来说,在性能、能耗比等方面的提升是非常令人惊讶的。这样一来,我们就多了一些好奇,究竟ARM采用了怎样的“魔法”,使得Mali-G78能够在工艺不变的情况下,在各个方面都能带来如此幅度的提升呢?
Mali-G78的“魔法之变”
对本文的读者来说,如果你没有读过之前本刊介绍Valhall架构的文章,那么我们建议大家先回头去阅读一下那篇文章,这样有助于你更好地理解Mali-G78在设计上的变革之处。
在Mali-G78上,最显而易见的变化在于ARM将它的GPU规模扩展到了24核心。在最近的几代Mali架构中,ARM一直在努力扩大GPU中所包含的核心数量,从而得到具备更大规模以及拥有更高性能的产品。另外,ARM也在试图为GPU内核整合更大的功能区块,以实现核心性能的演进,而不是仅仅简单地增加更多的内核。
在之前发布Mali-G77的时候,ARM增大了Mali-G77的内核,其功能几乎等于2个Mali-G76内核。随之而来的就是诸如三星Exynos990和联发科天玑1000这样分别拥有11个GPU和9个GPU内核的处理器产品。和过去类似定位的SoC相比,它们的数量有所减少。但是和其他移动GPU微架构相比,比如高通目前使用的2个核心的Adreno或者苹果使用4个核心的GPU设计,ARM的相关GPU核心依旧偏小。较小的核心更为灵活,用户可以自行选择扩展的规模。但是随之而来的问题就是,由于每个小核心都拥有完备的功能,因此重复功能较多,大量的晶体管都使用在了重复功能上。相对而言,相比较大的内核,较小核心的功率效率较低。
因此,目前看起来行业内的趋势是使用较大的核心和“较小”的扩展。但是在Mali-G78上,它的扩展能力变得更强了,它可以扩展至24个内核的设计似乎是在倒退。实际上有一种合理的忧虑是Mali-G77或者Valhall架构所代表的核心依旧太小了,因此ARM必须进一步增加核心数量来提高性能。
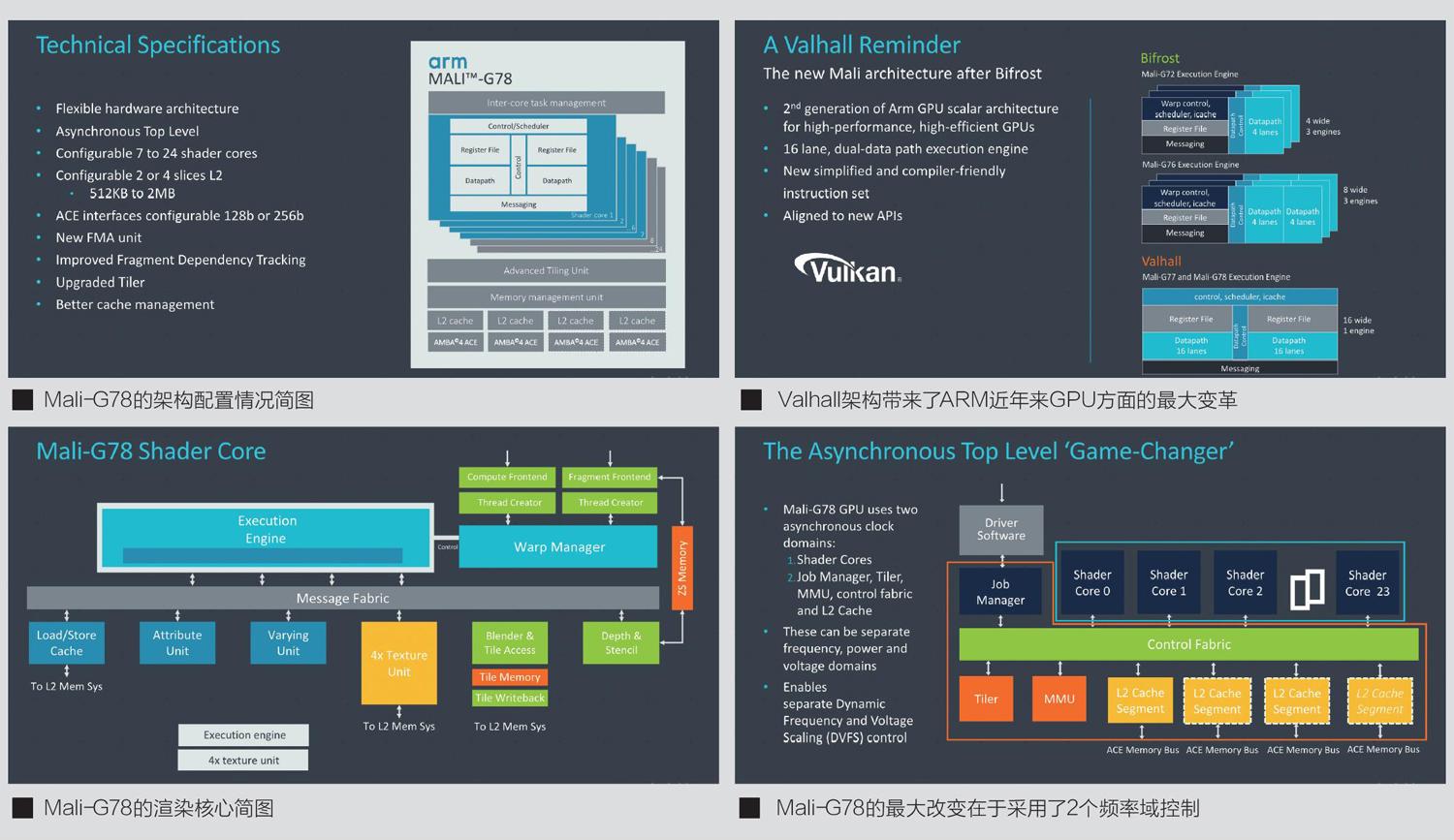
在配置方面,ARM放弃了4MBL2缓存作为可选项。尽管ARM宣称这项功能依旧会得到保留,但是从未有厂商选择在自家产品上应用该方案。迄今为止,所有应用MaliGPU的SoC都选择的是2MBL2缓存。
在执行核心方面,Mali-G78和Mali-G77基本相同。Mali-G77的特点在于将多个执行引擎合并为一个更宽的单元,正如前文所提到的,增加了SIMD执行通道宽度和波前阵列宽度。从它整体的渲染核心架构图可以看到,Mali-G78和之前的产品相比并没有太大变化,其中比较显著的改动在于单执行引擎和4倍的纹理单元,在每个时钟周期中,纹理过滤功能最多支持4个像素,渲染输出功能支持2个像素。
Mali-G78的最大变化来自于全局结构,现在新的架构下GPU从之前的全局频域更改成2级体系结构,包括上级的共享GPU块之间频率和下层渲染核心之间频域的解耦。换句话来说,ARM在Mali-G78上引入了异步时钟域,允许渲染核心和GPU其他部分以不同的频率运行。值得一提的是,Mali-G78的异步时钟域是双向的,也就是渲染核心频率相比GPU其他部分的频率可以更高或者更低,这样可以在必要的时候提高性能或者节约功耗,这也是ARM宣称Mali-G78能够带来大幅度性能和能耗比方面改善的核心原因。
从技术的角度来看,进行异步时钟域更改主要是为了解决在不同工作负载下,几何吞吐量和内存吞吐量之间的平衡问题。ARM的GPU架构一直以来都存在一个“痼疾”,那就是要让GPU在屏幕上显示更多的多边形的话,当前架构除了提高工作频率之外就没有其他更好的方法了。现有架构的几何引擎和图块(tiler)引擎依旧只能在每个时钟周期处理一个三角形,并且该指标在GPU中被设定为固定且不可扩展。
近年来,其他厂商的移动GPU架构出现了一些新变化,诸如《堡垒之夜》和《PUBG》这样从桌面游戏衍生而来的移动游戏已经在智能手机中掀起了热潮。这些新游戏的特点是比传统的移动游戏占据更多几何空间,这刚好击中了MaliGPU的软肋,使得MaliGPU和相关移动SoC变得难以适应新游戏的发展方向。
为此,ARM才引入了不同的频率域,这能够在一定程度上解决现有架构几何资源不足的问题。如果用户能够在图块引擎、几何引擎以及GPU核心频率之间使用不同的频率,那么就有可能在一定程度上解决几何吞吐量(并不能在数据宽度上伸缩)和计算、纹理以及渲染引擎之间的吞吐量不平衡的问题。
此外,这种异步时钟域还允许GPU运行在两个域也就是两个不同的电压下,较慢的域能够在较低的频率和电压下工作,从而获得不错的功率效率,并且这样的设计在理论上不会影响性能。问题在于,异步时钟域会使得终端SoC厂商采用附加电压域或者附加电源轨的方式实现,这都会增加芯片的成本,因此还需要结合性能提升幅度来综合衡量。
目前这种异步时钟域的设计方式,在一定程度上解决了ValhallGPU架构几何资源不足的问题。不过这个方案更像是一个“临时补丁”,因为ARM在GPU上的根本问题依旧是Valhall架构一个时钟周期只能支持几何引擎和图块(tiler)引擎处理一个三角形,这样就算加入了异步时钟域,也存在着频率限制和功耗等问题,毕竟频率不可能无限制提升。在台式设备上,类似问题大约在十年前也曾出现过,最终解决方案是转向多几何引擎,在移动设备上这样的转向也肯定会出现,只是时间问题而已。
在计算能力方面,Mali-G78彻底重写了FMA架构,据说这个变化是ARMGPU小组和CPU小组共同努力的结果。新的FMA架构能够使得能耗降低30%,改进的关键点在于使得FP32和FP16存在计算路径的物理隔离,这确实需要耗费更多的晶体管和面积来实现,但是带来的是更少的实际晶体管开关占用时间以及相应的能耗比提升。根据ARM的计算,在Mali-G77上仅仅FMA单元就占用了整个GPU动态切换能耗的19%,这部分能耗降低30%意味着带来了整个GPU能源效率大约5%~6%的提升,这是非常惊人的变化。
Mali-G78最后一个改进亮点在于对图块(tiler)机制的改进,使其性能可以根据内核数量的增减进行合理的缩放。缓存方面,内核缓存设计改善了缓存维护算法,并通过更好的依赖性跟踪设计提高了性能,从而使得内核可以更为智能的处理缓存数据,避免不必要的数据移动,降低了GPU内部的能耗、增加了带宽,从而提高了整体性能表现。
小改进但可期待的性能
这一部分依旧是惯例的性能改进情况展示。ARM带来了一些Mali-G78性能改进方面的内容,我们一起来看一下。
由于Mali-G78加入了异步频率域,因此在几何性能和渲染性能方面都有不错的提升。对于这一点,ARM专门进行了对比测试,数据显示在开启异步频率域后,基准性能能够提升8%,某些游戏表现将提高14%。从数据上看这个进步并不大,但是要知道SoC厂商只需额外增加一个PLL或者分频器就能获得这样的性能提升,算起来还是划算的。
在和Mali-G77的比较中,ARM给出的是数据可比条件下,Mali-G78的能耗降低了10%,这可能是来自于内核、FMA改进等综合影响。在异步功能方面,ARM宣称这能够带来6%~13%的能耗降低,具体数据则取决于工作负载。实际上这是一个比较笼统的估计,因为要实现这样的数据,需要SoC厂商为GPU添加第二个电压轨道以最大限度地利用异步频率域的优势。但是这里又出现一个问题,那就是实际上SoC厂商可以考虑增加一个额外的内核并将其设定为较低的频率,而不是设定一个额外的PMIC轨道以及相应的电感、电容等。对于旗舰SoC来说,采用ARM的推荐设计并添加第二条电压轨是可以期待的,但是对中低端定位的GPU来说,可能成本上并不是很划得来。
总的来看,目前Mali-G78的改进比较小,因此最终的性能提升也不算很大,并且其性能的提升和改变需要额外的配合,这对厂商来说可能存在成本和收益的衡量,再加上如果在售价方面比较贵的话,可能会影响厂商选择Mali-G78的积极性。在这里,ARM需要谨慎地平衡Mali-G78的价格和性能,并且参考市场上包括imaginationA系列的售价和相关性能情况等因素。另外,考虑到IP和实际产品之间存在大约半年左右的时差,因此我們真正看到Mali-G78的产品上市可能还需要等待一段时间了。
核心最大数量为6个的Mali-G68
ARM在本次发布会上还一并发布了Mali-G68,从产品型号来看,Mali-G68像Mali-G78的上一代产品。但实际上这两款产品采用了完全相同的内核。但是,Mali-G68的扩展数量被限制为最大6个核心。也就是说大家都是一样的核心“Valhall”的改进版本,但是采用MP6以及以下的配置时,只能被称之为Mali-G68MP6,但是如果使用7个或者更多的内核,就可以被称为Mali-G78家族。
这样的命名方式无疑带来了市场的混淆。ARM希望中低端SoC在使用较少的核心配置时,不会使用Mali-G78的名称并对其产生市场和定位上的影响,但是采用Mali-G68的这样的命名方式,会让人迷惑这是否是上一代产品。我们知道英伟达和AMD在同代架构GPU上的区分命名方式是采用从大到小的数字,但是其根本问题在于总有一些数据看起来是不变的,比如GeForceRTX2060和RTX2080,架构一样,特性类似,但是产品命名方面通过RTX、20代次等做到了很好的区分,并且也不会混淆之前的“10”代次产品,ARM在这里可能需要借鉴一下。
当然,这并不是ARM第一次这样做。在之前Mali-G57架构和衍生SoC上,ARM就使用过这一“套路”。实际上Mali-G57和高端的Mali-G77来自完全一样的核心架构,联发科天玑800采用了Mail-G57MP4的方案,采用了4个GPU核心,因此只能被称之为Mali-G57。这显然带来了品牌和技术上的一些混淆。
本文将Mali-G68单独放在一段中讲述,正是为了特别提到有关GPU产品命名的问题。虽然消费者在很大程度上并不会关心到底使用的是什么GPU、CPU,但是起码不要带来产品型号和技术代次上的混淆。
ARM Ethos-N78:更大、更强的AI加速核心
在过去几年,由于移动计算市场对AI计算需求增加,SoC厂商对相关知识产权和核心架构设计的需求也在逐渐增多,比如高通、华为、联发科等厂商都在自己的SoC中加入了AI加速核心设计,各家在核心名称和实现方式上有所不同,但总的来说,都是为了加速手机端的AI计算。
在这种情况下,ARM也提出了自己的机器学习加速核心的发展计划。第一代产品被称为“ProjectTrillium”,最终商品名称为Ethos,首个产品型号是Ethos-N77。本刊也在之前的文章中介绍过有关Ethos-N77的内容。这款产品发布时间距离现在已经有一年多了,因此ARM推出了第二代机器学习架构和相关产品,也就是今天被称为“Scylla”的架构以及Ethos-N78NPU。
在Ethos-N78的性能展示环节。ARM宣称它的规模大大超过了Ethos-N77,能够提供最高10TOPS的计算吞吐量和超过之前产品2倍的峰值性能,其他数据还包括25%能耗比提升、40%的存储器带宽提升和超过90种独特的配置方案。
在技术改进方面,Ethos-N78使用了全新的压缩技术,包括NPU内部的计算数据压缩和外部的带宽的压缩,比如Ethos-N78通过优化设计和数据压缩带来了外部存储器40%的带宽提升。新的数据压缩和数据处理可以显著提高计算效率、降低系统带宽占用等,使得平均工作负载也降低了40%,并最终带来了更高的能耗比和更出色的功率表现。
在配置上,Ethos-N78能够在4种不同的配置间选择,并对应了不同的MAC单元,这四种配置分别是1TOPS、2TOPS、5TOPS和10TOPS,分别包含了512、1024、2048和4096个MAC单元。这里有一个比较有趣的现象,那就是随着配置规模的提升,Ethos-N78的面积效率也会增加,这是由于唯一的固定共享功能的模块面积比例随着配置规模提升、计算单元面积大增而相对缩小所致。换句话来说那就是对厂商而言,更大规模的Ethos-N78会更有利于实现更高的每平毫米性能或者每单位价格性能。
由于更出色的性能密度,25%的能耗比提升,以及翻倍的峰值计算能力,最终我们可能看到在使用Ethos-N78后,终端SoC的计算能力得到巨大提升。对于这一点,ARM给出了相当乐观的估计。具体到产品上来说,由于推出时间较晚,目前使用Ethos-N77的相关产品还没有上市,因此暂时无法评估Ethos架构的实际应用情况。不过ARM对这一点倒是很坦然,他们认为,在AI计算上,没有什么比软件更重要,优秀的软件设计才能充分发挥AI硬件的性能,ARM在软件上投入了大量资源且取得了明显的竞争优势,已经吸引了一些合作伙伴开始使用Ethos相关产品。具体到Ethos-N78的话,可能到2021年才会有产品面世了。
除了Ethos-N78这样应用在高端移动SoC上的大规模NPU产品外,根据ARM推动的“ARMEnablesAIEverywhere,OnAnyDevice”计划,ARM还在今年2月份推出了新的超小型AI加速核心Ethos-U55。相比Ethos-N78起步就是512个MAC单元而言,Ethos-U55的规模要小得多,只有32个MAC到256个MAC,并且它需要和Cortex-M系列处理器配合使用。在技术方面,ARM并没有给出Ethos-U55更多的细节信息,只是宣称其使用了一种非常精简的设计,侧重于面积与能耗比的表現,同时具有较小的内存占用,另外还加入了N系列上的一些基本功能。在应用范围上,Ethos-U55将搭配Cortex-M系列处理器,专门面向超低功耗、超小核心等终端对象,比如智能耳机、智能家居等。在搭配了Ethos-U55系列的AI加速核心之后,这类产品有望获得基础的AI计算能力,从而在一定程度上扩展它们的适用范围,或是增强其使用体验。
写在最后
在2020年,ARM的升级重点似乎放在了CPU端,从产品技术角度来看,Cortex-X1的变革力度无疑是最大的,Cortex-A78的重点则和Mali-G78一样,都是改进和优化。尤其是GPU,考虑到去年ARM才推出了全新的GPU架构,今年只做小改进也是合理的。NPU方面目前尚未有厂商采用,并且相关产品和市场发展阶段应该还处在早期,ARM依旧有大量时间对其进行深入研发和定制。总的来看,今年应该可以被看做是ARM产品发展的“小年”,ARM将重点都放在了架构的优化和改进上,这也为厂商进一步调校产品、带来更好的使用体验留下了充足的空间。
