全新NVIDIA安培架构和A100 GPU深入解读
2020-08-11徐昌宇
徐昌宇


专为计算设计——NVIDI A正式发布A100Tensor Core GPU
NVIDIA进入计算市场是从G80GPU开始的,当时统一渲染架构的出现带给NVIDIA在计算市场上崭露头角的机会。随后的多代处理器产品包括代号为GT200、费米、开普勒、麦克斯韦等架构都在努力向计算市场迈进,甚至一度称自己为“视觉计算”企业。不过这一切在AI计算、云计算兴起之后发生了改变,包括开普勒、麦克斯韦、帕斯卡架构的GPU都被广泛使用在AI的深度学习计算中,再加上数据中心和云计算对GPU越来越大的需求,NVIDIA在产品路线上开始分裂—一方面要牢牢占据游戏产品市场,另一方面高增长、高利润的数据中心和AI计算市场也绝对不能放弃。
这样一来,NVIDIA的产品路线就分为了计算和图形两个路径。我们看到的第一个更偏向于计算的GPU产品架构是伏打架构,其典型产品为TeslaV100、TITANV等,在民用图形卡方面几乎没有太多建树。同代(或者稍晚一些)推出的更偏向于图形的产品是图灵架构,衍生出了多款民用GPU图形卡,并且带来了RTX品牌和全新的光线追踪技术。值得一提的是,考虑到这款显卡出色的性能和性价比,也有不少专业用户选择它进行计算工作,毕竟TITANV昂贵的价格并不是所有人都可以承受的。从时间上来看,伏打架构和相关产品发布于2017年6月,图灵架构和相关产品发布于2018年8月,根据NVIDIA一代计算产品、一代游戏产品发布的前例来看的话,刚刚发布的Ampere(下文全部称为“安培”)架构极大概率会被定义为计算产品,和游戏玩家关系不大。
虽然这一切看起来顺理成章,图形和计算两条路并行不悖,但是在今年网络发布会后的媒体采访上,NVIDIACEO黄仁勋又提到,安培架构和随后即将推出的图形加速产品在架构上存在“巨大的重叠”,并且将最终替换掉图灵架构和伏打架构,成为NVIDIA在计算和图形市场上的唯一架构。实际上,从现有的安培架构的情况来看,现在发布的产品是彻彻底底针对计算市场的,不但大幅度加强了有关计算方面的内容、加入了大量特殊格式的计算加速、采用了全新设计的张量核心,还加强了双精度计算的功能并且没有提供任何光线追踪加速的内容。这样一来,未来安培架构图形产品的情况就显得颇为扑朔迷离了。
当然,图形和计算,在应用端看起来似乎是两个路径,但是在最终GPU中计算时,都会转化为数据和相应的路径。也有一种可能是安培架构本身大幅度加强了计算效能,这些计算效能的提升也会在图形应用中带来不错的效果,当然最终的情况会怎么样,还得看后续产品发布的相关内容了。
另外值得一提的是,从本代计算产品开始,NVIDIA首发产品没有使用诸如Tesla的商标,而是直接以NVIDIAA100TensorCoreGPU命名。一些消息显示,由于NVIDIA旗下的Tesla计算卡在商标问题上和埃隆马斯克的特斯拉(Tesla)汽车存在一定的重叠和关联,因此NVIDIA彻底停用了Tesla品牌。目前在NVIDIA全球网站上,Tesla品牌已经彻底消失不见,比如之前的TelsaT4加速卡,目前被改成了NVIDIAT4,其余之前冠之以Tesla品牌的产品现在都改成了NVIDIA品牌。中國官网上,Tesla品牌在部分产品中依旧可见,应该是网站信息更新延迟的问题。停用了Tesla品牌之后,新的命名方法显然是凸显了NVIDIA在产品中的地位。另外,新产品的全新的命名突出了TensorCore也就是张量核心,这是NVIDIA在伏打架构上首次推出的、专门用于加速AI深度学习的计算核心。产品命名中对张量核心的突出显示,也表示出这款GPU的用途更偏向于计算加速而不是传统的图形。
架构方面,A100使用了最新的安培架构,NVIDIA宣称新的架构和产品是基于之前的伏打架构的TeslaV100(下简称“V100”)的功能构建,但增加了大量的新功能,并显著提高了包括HPC、AI和数据分析工作负载的性能。新的架构也能够为使用单GPU和多GPU组建的工作站、服务器、群集和云数据中心、边缘计算系统和超级计算机中运行的GPU计算和深度学习应用程序提供强大的扩扎能力,并且A100支持弹性构建、多功能和高吞吐量的数据中心。总的来说,作为NVIDIA“三年磨一剑”的全新产品,A100和安培架构引入了大量的新功能和特性,值得一一道来。
安培架构的具象——GA100芯片的工艺和成本
任何一个产品架构最终都必须依托于某个具体产品才存在现实意义。在这一点上,安培架构的芯片产物是GA100GPU,对应的成品被称为A100TensorCoreGPU。
GA100GPU是现有民用产品中晶体管数量最多、计算能最强大的单个完整芯片。工艺方面,GA100GPU采用的是台积电的7nm工艺。整个GA100GPU中包含了542亿个晶体管,封装面积为826平方毫米,每平方毫米晶体管数量约0.656亿个,即65.6MTr/平方毫米。
从数据来看,7N工艺的晶体管密度数据极为接近台积电7nmHP工艺的65MTr/平方毫米。7nmHP工艺的其他的参数还包括金属层76nm、鳍片高度为30nm、栅极间距为64nm、采用了7.5T库等。从台积电的相关信息来看,7nmHP工艺是专门面向高性能计算、高频率处理器的工艺,其优势在于出色的电气性能和能达到较高的频率,劣势则在于,相比同期推出的、采用6T库的台积电7nmHD工艺,7nmHP工艺密度比较低。7nmHD工艺密度可达91.2Mtr/平方毫米,相比7nmHP大了约50%,属于成本优先的选择。使用7nmHD工艺制造的产品就有大名鼎鼎的AMDZen2架构的计算核心,目前来看其性能和成本得到了很好的平衡。NVIDIA在这里选择了7nmHP工艺,应该是综合考虑了GA100GPU的目标市场对成本不敏感、大型计算设备的采购预算往往比较高等原因,简单来说就是市场优先。
A100GPU的首个亮点就是全新的第三代张量核心,相比V100,新的张量核心大幅度提升了数据吞吐量,还增加了全新的多种专用于深度学习和HPC数据类型的支持,以及加强的稀疏计算增强功能。
根据NVIDIA给出的示意图,一个完整的SM单元包含了一个共享的L1指令缓存和四个计算模块。每个计算模块的都拥有自己的L0指令缓存、每周期可以发送32个线程的Warp排序单元、每周期32个线程的调度单元、16384x32bit的寄存器以及后端的LD/ST单元、特殊功能单元(SpecialFunctionUnit,简称SFU)。除了这些功能单元外,每个计算模块中最重要的部分自然是计算单元了。每个计算模块拥有16个INT32单元、16个FP32单元、8个FP64单元以及1个第三代张量核心。最终1个完整的SM单元包含了64个INT32单元、16个FP32单元(也就是CUDA核心)以及32个FP64单元、4个第三代张量核心。在整个SM单元的后端,NVIDIA还布置了192KB的L1数据缓存或者共享缓存,4个Tex单元。值得注意的是,相比之前伏打架构的SM单元,安培架构的SM单元中,张量核心的数量只有4个,但是前代伏打架构和图灵架构的每SM均有8个。不过由于新的第三代张量核心使用了全新的设计,其计算能力反而大幅度提升。
安培架构SM单元的特性总结
1.全新的第三代张量核心
★ 全新的第三代张量核心现在可以加速所有类型的数据,无论是FP16、BF16、TF32、FP64、INT8、INT4还是二进制数据,都能够使用第三代张量核心进行加速。
★ 第三代张量核心新加入可以利用深度学习网络中的细粒度结构稀疏性和新加入的稀疏功能,使得标准张量核心的操作的性能翻倍。
★ 安培架构中的张量核心在计算TF32数据时,可以通过特有的路径来加速深度学习框架和H P C计算中FP32的输入输出数据,这种计算比之前的伏打架构的V100 FP32 FMA操作快10倍,如果原始数据有稀疏性,那么可以快20倍。
★ 在操作混合精度的F P16和FP32的深度学习计算时,安培架构的第三代张量核心运行速度比之前的伏打架构的V100的张量核心快了2.5倍,如果原始数据具有稀疏性那么可以提高至5倍。
★ BF16/FP32混合精度操作和常见的FP16/FP32混合精度速度一样。
★ 第三代张量核心能够进行FP64操作,在HPC计算中比较常见,其速度是伏打架构的V100 FP64 DFMA操作的2.5倍。
★ 第三代张量核心在计算拥有稀疏性的INT8数据时,其速度是伏打架构V100 INT8操作的20倍。
2.加大的L1数据缓存/共享缓存,容量是伏打架构的1.5倍。
3.新的异步复制指令支持将数据直接从全局存储器加载至共享存储器中,可以绕过L1高速缓存且不需要使用中间寄存器文件。
4 .和异步复制指令一起使用的、基于共享内存的新的异步屏障单元。
5.L2缓存管理和驻留控制得到了改善。
6.CUDA组支持新的warp-level降低指令。
7.可编程性的改进。
NVIDIA还给出了一些对比用于比较新的第三代张量核心和安培架构在数据处理方面相比之前的伏打架构的优势。比如FP16、FP32、FP64和INT8稀疏操作等。其中,A100 GPU相比V100在上述操作中获得了5倍、20倍、2.5倍和20倍的性能优势。
在FT32数据格式方面,NVIDIA进一步解释道,目前AI训练方面默认的数据格式是FP32,并且不能进行张量核心加速。NVIDIA在安培架构上引入了TF32架构,这样一来AI训练在默认状态下就可以使用张量核心加速了,并且不需要用户手动配置,当然非张量的操作继续使用FP32数据路径进行计算。TF32张量内核将读取FP32数据并且使用和FP32相同的范围,但是内部会处理自动降低精度,然后生成标准的IEEEFP32输出。TF32包含一个8位指数(和FP32)相同,10位尾数(和FP16相同)以及1个符号位。NVIDIA反复强调,张量核心有关TF32的加速方面,不需要用户额外付出劳动成本,一切都是自动的。
在传统的INT32和FP32操作方面,安培架构和A100GPU和之前發伏打、图灵架构类似,都采用了独立的FP32和INT32内核,支持以全吞吐量同时执行FP32和INT32操作,并且还提高了指令的吞吐量。另外,对一些有内部循环的应用程序而言,这些循环可以同时执行指针算术(整数存储器地址计算)并结合浮点计算,这也是FP32和INT32独立计算带来的优势之一。在这种计算中,循环的每个迭代都可以更新地址并为下一个迭代加载数据,同时在FP32中计算现有的数据,效率显著提升。
除了有关深度学习计算加速的内容外,在HPC所需要的高精度计算方面,安培架构的第三代张量核心也带来了出色的效果。目前安培架构的第三代张量核心支持符合IEEE标准的FP64计算,其FP64张量核心计算性能是之前伏打架构V100GPU的2.5倍。在架构改进上,安培架构采用了新的双精度矩阵乘加指令取代了之前V100上的8条DFMA指令,从而减少了指令提取、调度的开销以及寄存器的读取、数据路径功率和共享存储器的读取带宽等。现在,安培架构A100GPU中每个SM每时钟周期可以计算64个FP64FMA操作,或者128个FP64操作,这两个数据都是V100的2倍。具有108个SM的A100GPU的双精度数据吞吐量是19.5TFLOPS,这个数值达到了V100的2.5倍。
说道吞吐量,就不得不提及计算能力了。NVIDIA给出了一张表用于展示不同数据格式下新的A100GPU的计算能力。表中所有的计算数据均基于GPU的峰值频率。此外,在除了FP64TensorCore计算之外的所有TensorCore计算力方面,NVIDIA还分别给出了传统计算和加入稀疏性优化后的两种性能数据,比如INT4TensorCore计算方面,在不启用/启用稀疏性优化的情况下,计算能力分别是1248TOPS和2496TOPS,后者带来了翻倍的计算性能。
无论是吞吐量的增加,还是新的数据加速格式的支持,都可以用于加速HPC的工作负载,包括迭代求解器和各种新的AI算法等。
架构优化:全新引入的细粒度的结构稀疏性
安培架构为AI计算做出了多样化的优化,在这里,全新引入的细粒度结构稀疏性就能够将深度神经网络的吞吐量提高一倍。
在深度学习计算中,稀疏性是可能存在的,因为在深度学习的计算过程中,个体的权重在不断地变化,在最终网络训练结束的时候,只有一部分权重能够体现有意义的价值,剩余的权重则失去了意义不再需要。
细粒度的结构化稀疏性则是对允许的稀疏性模式增加了约束条件,使得硬件可以更有效对输入操作数进行必要的对齐。由于深度学习网络能够根据训练过程反馈调整权重,因此NVIDIA的工程师们发现,一般而言,结构的约束并不会影响深度学习网络的准确性。因此,这使得利用稀疏性对推理计算进行加速成为可能。
在具体的执行中,NVIDIA通过新的2:4稀疏矩阵定义强制性的执行结构,该定义在每个四项向量中允许2个非零的值,A100GPU支持行上2:4的结构化稀疏性。由于矩阵的定义非常明确,因此可以对其进行压缩,并将内存存储量和带宽要求减少2倍。
在计算方面,NVIDIA也开发了一种简单而通用的方法,使用这种2:4的结构稀疏模式对深层次的神经网络进行稀疏化处理。比如首先使用密集的权重值对网络进行训练,然后用细粒度的结构化“修剪”数据,最终使用其他训练步骤对剩余的非零权重进行微调。在NVIDIA的评估中,这种方法通过了跨视觉、对象检测、分割、自然语言建模、翻译等数十个深度学习网络的评估,这种计算方法几乎不会导致推理准确性的损失。
在硬件架构方面,A100GPU也引入了新的稀疏张量核心指令,该指令会跳过具有零值的条目的计算,从而使得张量核心的计算、吞吐量翻倍。
存储系统:缓存的改进和40GB的HBM2内存
由于芯片规模越来越庞大,因此NVIDIA需要改善整个架构体系的存储系统。現在,安培架构和A100芯片的L1、L2以及内存体系(或者显存体系,本文统一称之为内存)都得到了加强。
先来看L1缓存。在之前伏打架构的V100上,NVIDIA首次引入了L1数据高速缓存和共享内存子体系结构,这带来了性能的显著提高,并且简化了编程,减少了达到或者接近峰值应用程序性能所需要的调整。将数据缓存和共享内存功能组合在一起,可以为两种类型的内存访问都提供最佳的性能。在安培架构和A100GPU上,NVIDIA大幅度提升了L1缓存的容量至每个SM单元192KB,使其达到了前代伏打架构的1.5倍,容量更充裕了。
接下来再看L2。A100GPU目前包含40MB的L2缓存,这个容量是之前V100的6.7倍。A100的L2分为两个分区,以实现更高的带宽和更低的延迟。每个L2分区都会进行本地化并且缓存数据,以方便直接连接到该分区的GPC中的SM进行数据访问。这种结构使得A100的缓存带宽相比V100增加了2.3倍。硬件的缓存一致性将在整个GPU范围内维护CUDA编程环境,并且应用程序会自动更新以利用L2缓存的带宽和延迟优势。
L2缓存属于GPC和SM的共享资源,本身被放置在GPC之外。现有情况可以看出,安培架构和A100GPU的L2缓存容量大幅度增加显著改善了很多HPC和AI工作负载的性能。这是因为那些需要被充分个访问的数据集和模型,都不用频繁地去HBM2内存中读取和写入了,现在直接可以在L2中存取。另外,受到DRAM带宽限制的部分工作负载,比如使用较小的batch尺寸的深度神经网络,将充分受益于更大的L2。
在L2数据控制和优化方面,安培架构带来了L2缓存驻留控件,借助于这个控件,用户可以在L2缓存中永久保留一部分数据,也可以自定义哪些数据需要进入L2保存、哪些不需要。举例来说,对于深度学习推理的工作负载,一种被称为“乒乓”的缓冲区可以持久驻留在L2缓存中,不但可以实现更快的数据访问,同时还避免了回写到DRAM浪费时间和功耗。另外,在深度学习培训中心发现的一些“生产者-消费者”链路,L2缓存的控制可以跨越读写关系来对其进行优化。在LSTM网络中,L2缓存中可以重点考虑启用循环权重以提高效能。
L2部分最后再来了解一下有关安培架构的计算数据压缩功能,这个功能可以用于加速非结构化稀疏性和其他可压缩数据模式。L2中的压缩使得DRAM读/写带宽相对提高了4倍,L2读带宽相对提高了4倍,L2容量相对提高了2倍。
最后再来看看40GB的HBM2缓存。由于现代计算任务的数据量越来越庞大、对数据传输的要求也越来越高,再加上GPU吞吐量也日渐上升,为了满足这些需求,传统的GDDR内存逐渐显得力不从心,而更强大的HBM2内存能更好地适应计算任务的需求,因此,A100GPU使用了HBM2内存,其容量为40GB,带宽高达1555GB/s,相比V100计算卡增加了73%。
第三代NVLink总线
NVIDIA在安培架构的A100GPU中启用了第三代NVLink总线。初代NVLink总线使用在NVIDIAP100计算卡上,带宽水平大约在100GB/s的级别。第二代NVLink总线使用在V100GPU上时总性能达到了300GB/s,也就是PCIe3.0总线的大约10倍。在A100GPU上,NVIDIA又引入了第三代NVLink总线,新总线每个信号对的数据速率达到了50Gb/s,几乎达到了V100中25.78Gbit/s速率的两倍。并且新总线的每个链路在每个方向上使用4个(差分)信号对(4个通道),而Volta中则使用8个信号对(8个通道)。与VoltaGPU相似,新的NVLink单个链路在每个方向上提供25GB/秒的带宽,但与Volta相比仅使用一半的信号。NVLink链接的总数在A100中增加到12条,而在V100中仅为6条,最终整个A100的总带宽高达600GB/秒。
目前在多GPU系统的构建中,NVIDIA通过NVLink总线和NVSWITCH切换器来进行数据的传输和切换,更大带宽的NVLink总线和NVSwitch有助于多芯片协同工作和任务分配传输的高效率。目前,每一个A100GPU支持最多12条NVLink总线启用,这样一来搭配6个NVSwitch芯片,能够实现最多16个GPU互联,大幅度提高了单个设备的计算能力。
另外,安培架构的GPU正式支持了PCIe4.0总线规范,未来NVIDIA所有新的GPU都将全面支持PCIe4.0总线规范。
专为云计算设计:多实例GPU功能(Multi-InstanceGPU)
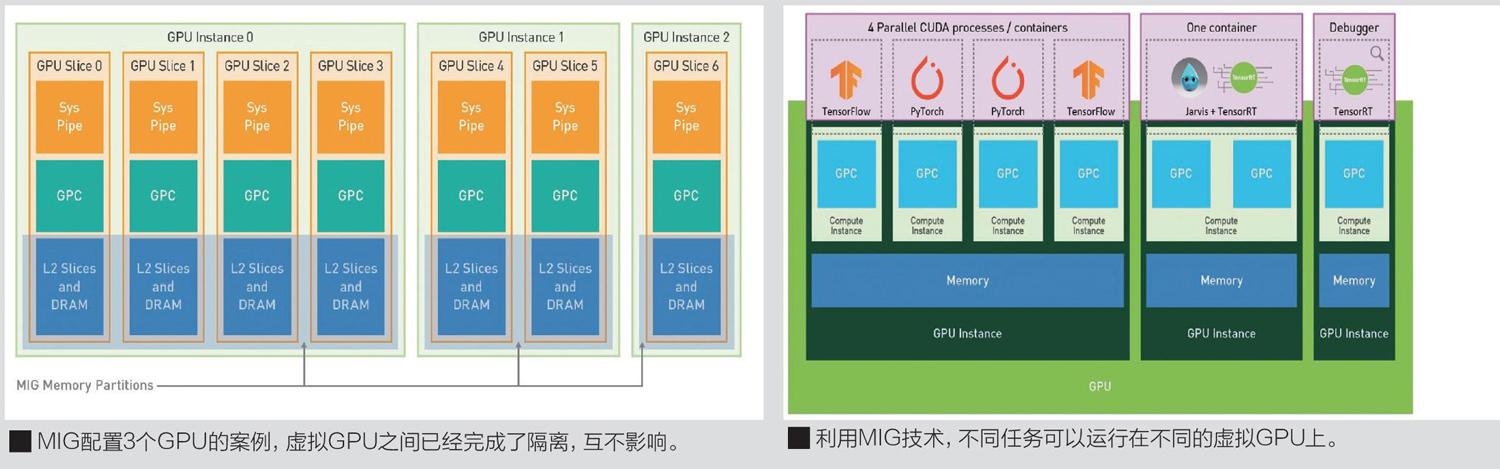
新的多实例GPU功能简称MIG,这是一项针对云服务提供商的功能。当配置为MIG时,系统中GPU的利用率可以得到很大的提升,包括无须任何额外成本就可以执行多达7倍的GPU实例。单个GPU还可以进行分区使用并支持故障隔离。
从实际应用来看,进关许多数据中心的工作量在规模和复杂程度上都持续提升,但是依旧存在一些任务并不需要太多计算资源就可以完成,比如早期开发或者一些小批量的训练的简单模型。对于一个数据中心来说,最好的状态是所有设备都满载,保持高的资源利用率,因此数据中心一方面需要越来越大,另一方面也要很好的运行这些较小的工作负载。
但是,在传统的不支持虚拟化的GPU上,一个较小的工作负载就会占据整个GPU资源。这对整个系统来说是极为浪费的。部分GPU可以实现虚拟化,并提供2个虚拟实例,但是对于A100这样的拥有极高算力的GPU来说,2个虚拟实例依旧不能很好地解决这类问题。因此,NVIDIA带来了新的多实例GPU功能,简称为MIG,这个功能能够将每个A100GPU加速设备划分为7个虚拟的GPU实例,从而进一步提高资源利用率,并有效的扩展每个用户和应用程序的访问权限。
NVIDIA提供了一些对比图,用于对比没有MIG配置和拥有MIG配置的设备运行应用程序的差异。在诸如伏打架构的V100GPU上,多个应用程序在單独的GPU执行资源也就是SM上同时执行,但是由于内存系统资源是在所有应用程序中共享的,因此如果一个应用程序对DRAM带宽有很高的要求或者其请求超出了L2缓存的容量,那么可能会干扰其他应用程序的运行。
在安培架构的A100GPU中,运行的情况发生了变化。A100GPU可以通过MIG功能将单个GPU划分为多个GPU分区,这种划分出来的分区被称作GPU实例。每个实例的SM具有贯穿整个内存系统的单独且隔离的路径,包括片上交叉开关的端口、L2缓存库、内存控制器和DRAM地址总线,都可以唯一分配给单个实例。这样可以确保单个用户的工作负载能够以可预测的吞吐量和延迟运行,并且具有相同的二级缓存分配和一样的DRAM带宽,即使其他任务需要更高的缓存或者DRAM带宽也不会产生负面影响。
不仅如此,在使用MIG功能经过对可用的GPU计算资源的分区后,系统可以为不同的客户端(或者虚拟机、容器、进程等)提供故障鼓励,从而提供定义的服务质量QoS。MIG使得多个GPU实例可以在只拥有单个GPU的A100GPU设备上运行,并且用户无须对现有的CUDA编程模型进行更改,以最大限度地减少编程工作。
对于云服务商(CSP)而言,MIG功能提高GPU了利用率并且无须任何成本。MIG支持CSP所需的必要QoS和隔离保证,以确保一个客户端不会影响到另一个客户端的工作或者调度。在这里,CSP通常会根据客户使用模式对硬件进行分区,当且仅当系统硬件资源提供了一致的带宽、适当的隔离和良好的性能是,分区才有效的运行。
在管理方面,借助安培架构和A100GPU,用户可以在虚拟的GPU上查看工作任务并进行相关调度,甚至可以直接视作其为物理GPU。MIG功能现在可以和Linux系统以及其管理程序一起使用,用户可以使用诸如DockerEngine软件,并且很快支持使用Kubernetes进行虚拟GPU的容器管理。
除了上述内容外,安培架构和A100GPU还带来了包括错误和故障检测、控制和隔离等功能。比如远程GPU的错误会通过NVLink回传至源GPU。此外,CUDA11在安培架构的适配上也做出了很多新的工作,比如对第三代张量核心的应用适配等。这些更详细的内容,NVIDIA将会发布在随后推出的A100TensorCoreGPU体系结构白皮书中。有需要的读者可以自行下载阅读。
性能:A100相比V100大幅度提升
在现有的相关资料中,NVIDIA还展示了一些A100对比V100的计算能力的提升,同时加入对比的还有NVIDIA首个专门为AI计算和HPC加速而生的产品TeslaT4。从NVIDIA的数据来看,在综合HPC加速计算中,A100大约性能是V100的1.78倍左右,其中性能倍数最高的部分是物理模拟,大约为2.0~2.1倍,最少的分子动力学模拟也能带来至少50%的速度提升,其余的包括工程计算、地球科学计算的性能倍数大约在1.7~1.9倍之间。
单芯片并行计算的巅峰
本文对安培架构和A100GPU的介绍就到此为止了。受限于篇幅,本文只介绍了一部分特色的新功能,实际上这款史上最大的GPU产品还有大量的内容值得探索,目前NVIDIA也在官网上放出了A100GPU和安培架构的白皮书,有兴趣的读者可以自行搜索下载。
在本文的最后,我们还是惊讶于这款GPU的强大,高达540亿晶体管,全新的第三代张量核心、新的MIG特性以及40GBHBM2内存。略有遗憾的是,如果不是功耗和芯片制造的限制,它还可能更为强大。当然,硬件的规格是一方面,从目前的情况来看,NVIDIA还在不断地通过软件的改进,充分释放这540亿晶体管蕴藏的强大算力。无论怎样,安培架构和A100GPU,堪称单芯片算力的巅峰,也是迄今为止人类设计的最复杂的芯片(可以没有之一),这也是并行计算登峰造极的一刻,值得铭记和赞叹。
