基于图像处理的网页篡改检测*
2020-08-11颜于凤
颜于凤 沈 勇
(江苏科技大学计算机学院 镇江 212003)
1 引言
进入21世纪以来,随着计算机和互联网的飞速发展,人们对于网络的依赖性也不断增强,虽然网络给人们的生活和工作带来了巨大的便利,但随之而来的网络安全问题也会造成不可估量的损失。网页被篡改是一种常见的网站安全问题,尤其是政府或高校等具有公信力的单位,一旦网页被篡改并发表一些损坏国家和人们利益的言论将会对社会造成极其恶劣的影响。鉴于网站安全对于人民生活影响之大,范围之广,针对网站页面保护的技术也是层出不穷,一些企业也开发出专门的网页防篡改系统[1]。但即便如此,据 CNCERT(国家互联网应急中心)监测发现,今年我国境内仍有上万个网站被篡改[2]。因此高效、准确的篡改检测方法是能够应对此类问题的有效途径。
在之前的网页篡改检测的研究中,主要的检测技术有人工比对检测、HASH函数比对、数字水印、网页相似度比对、关键字比对等方法[3]。这些方法虽然能够检测出网页是否被改动,但大多是对网页源代码进行处理,有的是计算源代码的HASH值,有的是嵌入水印,这对于源代码固定的静态网页是奏效的[4]。而对于以数据库为基础的动态网页来说,源代码中几乎不包含太多信息,以处理网页源代码的方式来处理动态网页往往无法达到预期的效果,所以此类算法对于动态网页的作用还有待研究[5]。本文以虚拟用户的形式通过模拟浏览器行为加载网页并获取网页截图,再借用图像特征点提取算法对截取的图像进行特征识别,从而快速地检测出网页是否被篡改,因为并非直接处理网页源代码,所以该模型对于静态网页和动态网页同样有效。
2 检测模型设计
2.1 网页抓取模型
在通常的网页抓取过程中需要借用网络爬虫作为工具。目前,网络爬虫的框架种类众多,不同的框架下包含了不同的爬取算法,有的以网站深度为爬取标准,有的以网站广度为标准,而选取标准则以实际应用的需求为准[6]。虽然方法很多但其基本原理都是给定一个初始的url地址链接,作为一个站点,读取该站点的页面,然后再通过页面源码中的链接爬取链接所指向的页面,直到所有页面都被读取完[7]。基本流程分为三步:建立链接队列、DSN解析链接并保存、分析下载的文件[8]。
本文的网页抓取模型在利用网络爬虫的基础上,创建一个虚拟的用户端,通过模拟浏览器的行为来访问首站点,然后编译执行站点中的JavaS-cript代码,最终保存模拟浏览器中的网页界面。具体流程如图1所示。
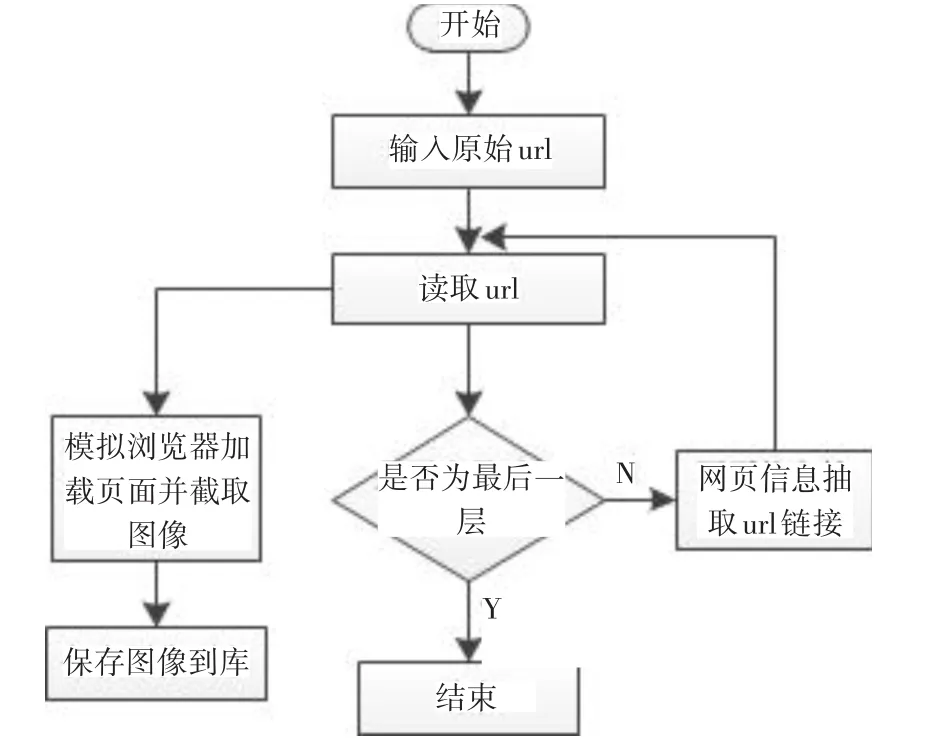
图1 抓取模型
2.2 图像处理算法
图像处理一直以来都是学者们比较感兴趣的一个研究方向。能够代表一幅图像的要素有很多种,特征点便是其中之一。针对二维图像的特征点检测的研究也已经持续了很长的一段时间,到目前为止已有上百种不同类型的检测算法[9~10]。本文在众多的特征点检测算法中选用两种最常见的角点检测算法:Harris角点检测和SIFT角点检测算法作为本文图像处理的方法,在充分理解这两种角点检测算法的基础上,创建角点检测模型对网页抓取模型中得到的图像进行处理,并且对处理过的图像进行比较。
2.2.1 Harris角点检测算法
传统的角点检测算法首先会固定一个窗口,然后以各个像素点作为窗口的中心,沿八个基本方向分别滑动,计算滑动窗口前后对应位置像素点灰度值之差的平方和,并取最小值作为该点的角点检测,最后经非极大值移植和阈值判断过程抽取角点[11]。若某个像素点是角点,则窗口移动的过程中各个方向的灰度变化都比较大。
Harris角点检测算法通过高斯算子计算水平和垂直方向上的微分并创建局部微分自相关矩阵来描述灰度变化的情况:


2.2.2 SIFT角点检测算法
SIFT(Scale Invariant Feature Transformantion),尺度不变特征变换,是一种对图像放缩、旋转等保持不变性的局部特征提取和描述算法[14]。该算法是继Harris角点检测算法后又一经典算法,是由Lowe利用高斯差分算子在尺度空间中检测特征点,并且结合相应的梯度描述子共同构成的[15]。其基本流程大致分为四步:输入图像并转化、尺度空间极值点检测、关键点精确定位及方向赋值和描述、得到目标的特征点集[16]。

图2 Harris角点检测流程

图3 SIFT角点检测流程
2.2.3 特征匹配算法
在对图像进行特征提取后,就可以对特征点进行匹配。通常使用相似度来评判两个图像的特征点的匹配程度,若相似度越高则说明两个图像越匹配,进而说明网页被篡改的几率较小。
本文采用欧几里得度量(euclidean metric,欧氏距离)来表示相似度:
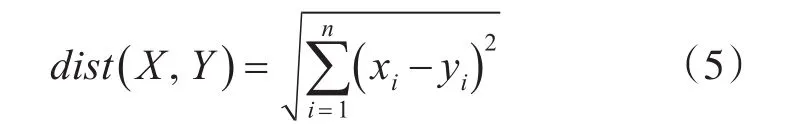
其中X,Y为两个待匹配图像的特征点向量[17]。在二维空间中其表示的是两个点之间的真实距离,欧式距离越小两个用户的相似度就越大,欧式距离越大,两个用户的相似度就越小。
3 实验结果
为了验证本设计能够快速有效检测出静态网页及动态网页的篡改情况,本文以python作为主要工具,以个人网站的作为被测试对象,首先输入初始站点的url链接,利用网页抓取模型获取该站点下所有页面并建成图像库;接着对个人网站作出细微的修改,再次利用抓取模型获取网页图像并作为图像处理模型的输入端,对前后两次图像进行特征匹配。
图4为原网页界面,然后对网页进行细微的修改,用以模拟网页被篡改,形成图5,与图4相比,图5将“World”修改为“World_magic”。然后分别对两幅图像进行特征点提取。

图4 原网页

图5 修改后网页

图6 原网页特征检测
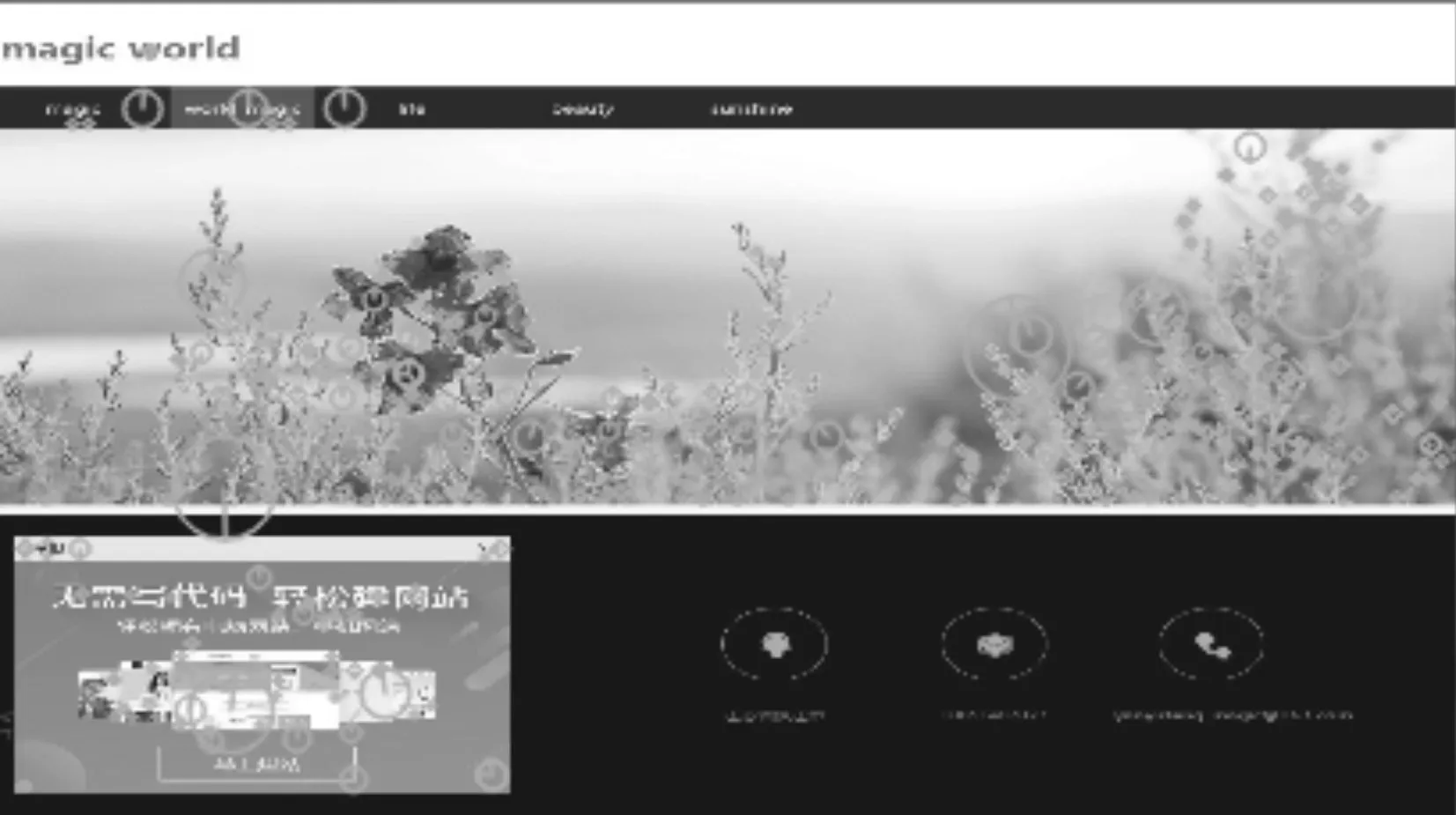
图7 修改后网页特征检测
经过对比两幅图像的特征点发现,除了被修改过的外,其余部分的特征点参数一致。最后通过匹配,可有效找出被篡改的位置并标记。
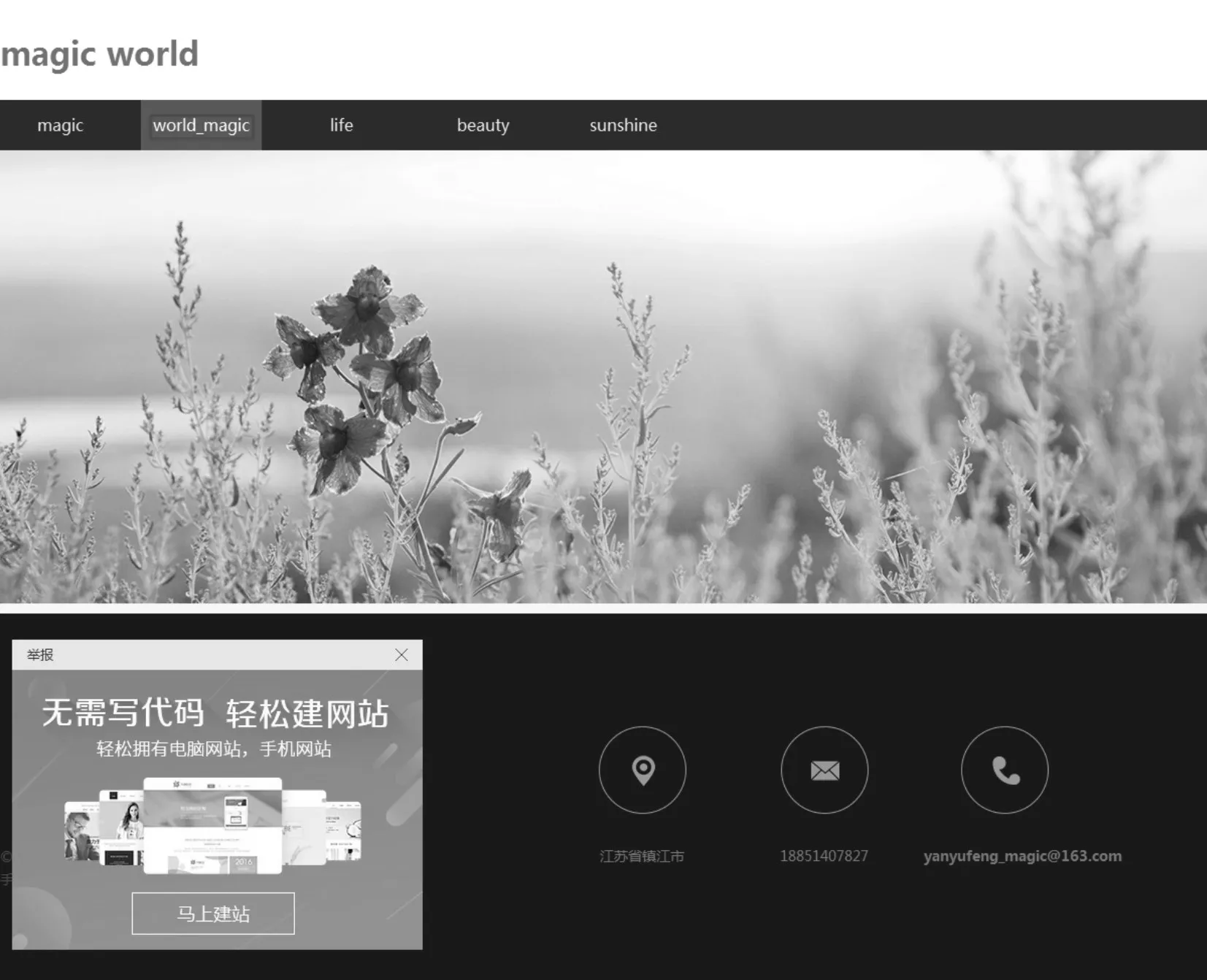
图8 匹配定位
4 结语
本文针对传统网页篡改检测技术无法兼顾静态网页和动态网页的问题,设计网页抓取模型,利用图像处理的方法对抓取的网页界面进行特征点检测,通过对比图像来达到检测网页是否被篡改的目的。实验证明,本文的研究方法确实可以达到检测网页是否被篡改的目的,并且能够找出被篡改的位置信息。
